
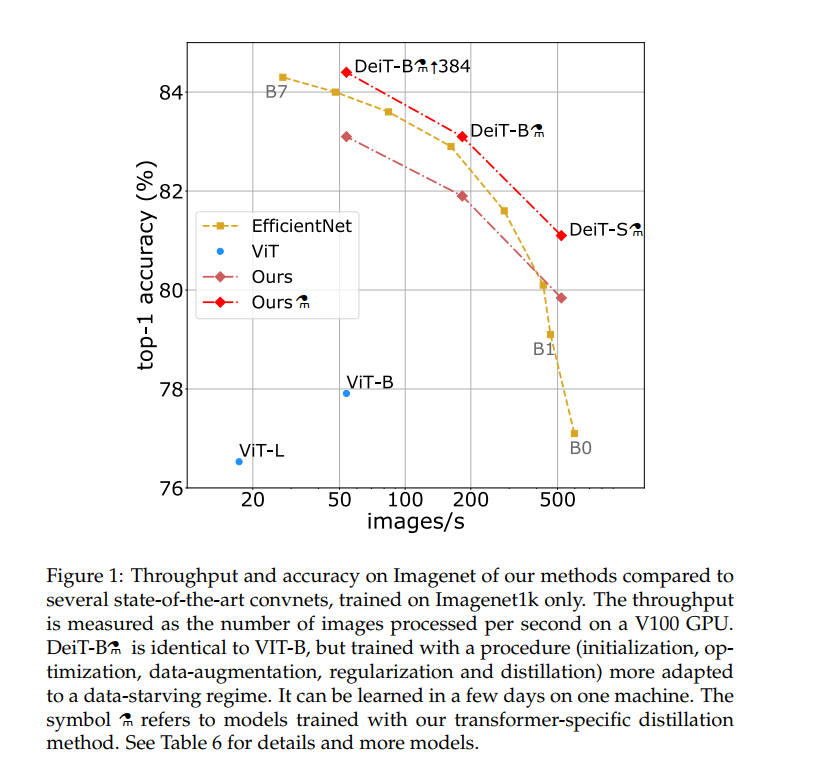
论文标题:Training data-efficient image transformers & distillation through attention 论文链接:https://arxiv.org/abs/2012.12877 代码链接:https://github.com/facebookresearch/deit 作者单位:Facebook AI, 索邦大学 本视觉Transformers(86M参数)在ImageNet上达到83.1%的top-1精度,蒸馏版本高达84.4%!优于ViT、RegNet和ResNet等,代码于8小时前刚刚开源!
最近,显示出纯粹基于注意力的神经网络可解决图像理解任务,例如图像分类。但是,这些视觉transformers使用昂贵的基础架构预先接受了数亿个图像的训练,从而限制了它们在更大的社区中的应用。在这项工作中,通过适当的训练计划,我们仅通过在Imagenet上进行训练即可生产出具有竞争力的无卷积transformers。我们不到三天就在一台计算机上对其进行了训练。我们的视觉transformers(86M参数)在ImageNet上无需外部数据即可达到83.1%的top-1精度(单幅评估)。我们共享我们的代码和模型,以加快社区在这方面的研究进展。此外,我们介绍了特定于transformers的师生策略。它依靠蒸馏令token确保学生通过注意力向老师学习。我们展示了这种基于token的蒸馏的兴趣,尤其是在使用卷积网络作为教师时。这使我们能够报告与卷积网络相比在Imagenet(我们可以获得高达84.4%的准确性)和迁移到其他任务时具有竞争力的结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢