
2025年10月28日,波士顿咨询公司BCG X AI Science研究院与默沙东的研究人员在《Drug Discovery Today》期刊上发表题为“Foundation models in drug discovery: Phenomenal growth today, transformative potential tomorrow?”的文章。

该文系统梳理了基础模型在药物发现和制药研发中的整体发展格局,并进一步展示了这类模型在多个关键环节中的应用潜力,包括靶点发现、分子性质优化以及临床前研究等。文章最后还对由基础模型驱动的药物发现流程在未来可能呈现的形态进行了前瞻性讨论。
背景
长期以来,新药分子的发现一直是一个周期漫长、风险高、成本昂贵的过程。过去十年中,随着人工智能技术的快速发展,各类AI方法开始被引入药物发现流程,用于应对其中的一些核心挑战,从而在一定程度上提升了研发效率和成功率。近年来,生成式人工智能的迅猛进展,尤其是大语言模型(LLMs)所展现出的卓越能力,进一步推动了研究范式的变化。科研人员开始探索并构建专门面向药物发现的基础模型。基础模型是一类通用性强、规模庞大的人工智能模型,通常在海量数据上进行预训练,随后通过微调适配到具体的下游任务中。目前,基础模型已在多个方向展现出应用前景,例如疾病生物学研究、靶点发现与生物标志物挖掘,以及分子设计等领域。
基础模型定义与特征
在当前的药物发现研究中,人工智能已广泛应用于多种成熟方法体系。图1对比展示了基础模型与传统人工智能方法之间的主要差异,为理解其独特优势和潜在价值提供了清晰框架。
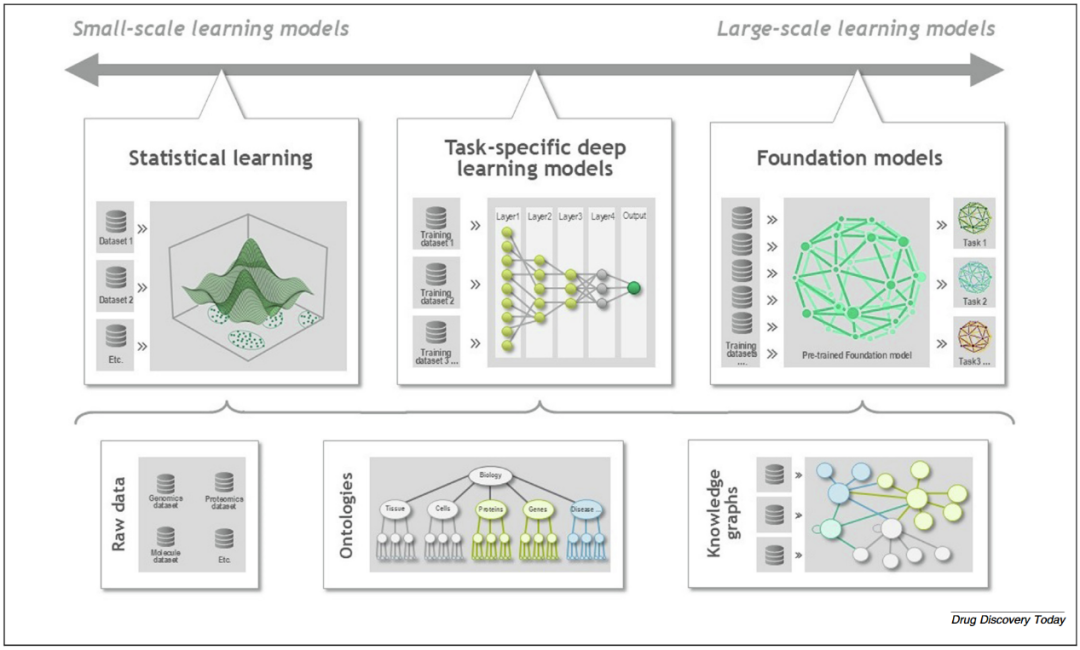
图1 制药研究中常用的人工智能和机器学习方法(上排)以及用于训练模型的输入数据类型及其标注与组织方式(下排)。
知识图谱是对实体及其相互关系的结构化表示,例如基因、蛋白质、疾病与药物分子之间的关系。它们通常通过对单个数据库进行挖掘并加以整合而构建。知识图谱的创建、更新与分析往往是一项繁重的工作,其应用也常常局限于挖掘已有的科学认知,而非发现全新的科学规律。
任务特定深度学习模型(TDLs)是一类从带标注数据中学习模式并据此进行预测的人工智能模型。与人类大脑类似,神经网络由按层组织、相互连接的节点构成,并通过在标注数据的指导下调整节点之间的连接权重,以完成特定的下游任务。然而,深度学习通常需要大量高质量的标注数据,而这往往构成其主要限制因素。
相比之下,基础模型(FMs)是一类更具通用性的神经网络。基础模型通常在极大规模的数据集上进行预训练,从而学习数据中广泛的模式与关系。随后,它们可以通过额外训练或强化学习,被微调以适配多种下游任务。与许多其他神经网络不同,基础模型可以采用自监督方式在无标注数据上进行训练,或在多模态数据上学习生物医学概念的整体表征。这使得基础模型具有高度的灵活性,并能够应用于包括药物发现在内的多种场景。许多基础模型采用了Transformer架构,该架构可将输入数据转换为数值表示,从而高效地分析和挖掘大规模数据集。一些基础模型则使用图神经网络来完成类似任务;而另一些模型,尤其是在医学影像领域,则采用了混合架构(神经网络与Transformer的结合)。
药物发现中基础模型的增长与演化
图 2 展示了作者所评估的基础模型总体概览。分析结果表明,近年来,与药物发现相关的基础模型数量呈现出显著的爆发式增长趋势。自2022年末首批基础模型发表以来,截至2025年初,已累计训练并发布超过200个不同的基础模型。从增长速度来看,这一趋势尤为引人注目:其季度复合增长率约为40%,而年复合增长率更是超过250%。如此迅猛的增幅,充分反映了基础模型在药物发现领域所引发的高度关注。从模型类型分布来看,截至2025年第二季度,已发表的基础模型中略低于30%为多模态模型,其余则为单模态模型。在训练数据来源方面,约20%的基础模型基于蛋白质结构或分子数据进行训练,约15%基于生物影像数据;此外,基于转录组学、表观遗传学、DNA和RNA等数据的基础模型合计约占30%。
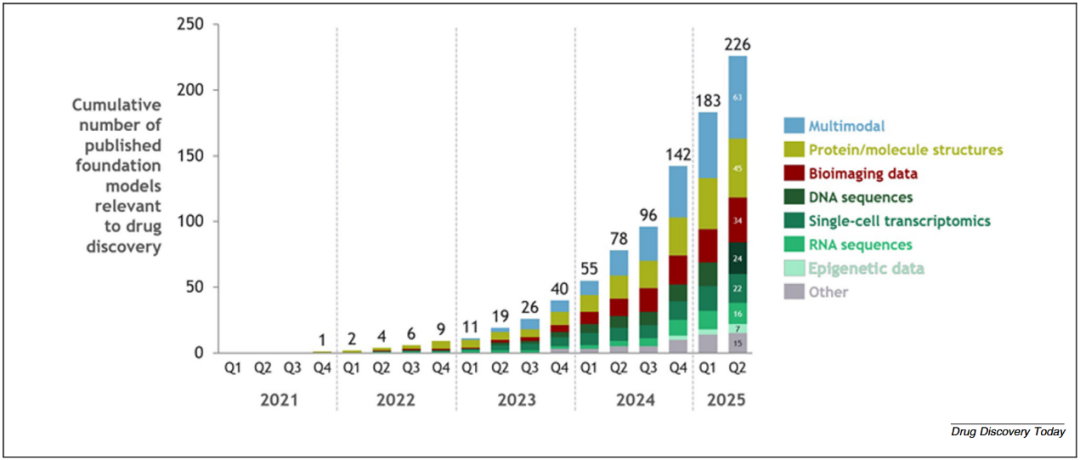
图2 药物发现领域已发表基础模型数量的增长趋势
转录组学
在过去几年中,用于预训练的转录组学数据集在规模和数量上迅速扩张,从最初的数百万细胞,增长到数千万细胞,并进一步超过一亿细胞。目前,这类模型在零样本设置下的性能整体仍然有限,其性能提升主要依赖于任务特定的微调。在典型的转录组学任务中,如细胞类型分类、疾病分类或基因表达重建,这些基础模型在零样本条件下很少超过性能强劲的任务特定模型。相比之下,在小样本场景中,预训练通常能够带来一定程度的性能提升;然而,对于细胞类型和疾病分类任务,经充分微调的任务特定模型往往能够达到或超过基础模型的表现。
蛋白质结构与性质
从早期蛋白质语言模型中使用的数千万至数亿级别数据,扩展到近期模型中的数十亿级别数据,训练数据规模呈现出数量级的增长。同时,数据类型也从仅包含序列信息,扩展为融合序列、结构和配体信息的多模态数据集。这种规模扩展使得在零样本条件下进行稳健的蛋白–配体对接成为可能,并支持零样本或小样本的结合亲和力预测。然而,在定量构效关系(QSAR)和毒性预测等应用中,小样本方法或进一步微调仍然具有明显优势。此外,在最终化合物优先级排序阶段,任务特定深度学习模型和基于物理的方法目前往往仍优于基础模型。近期的重要进展包括蛋白–配体协同折叠方向的研究,该方向旨在克服传统蛋白–配体对接方法的局限性,但要真正适用于药物发现流程,仍然需要通过小样本微调来实现。
病理影像
视觉Transformer(ViT)模型通常在从全切片图像中裁剪得到的固定大小图块上进行训练。与其他图像识别方法相比,ViT对计算资源的需求更低,且其学习到的表示更易迁移到规模较小的下游任务中。与其他类型的基础模型类似,从早期模型中的数万张图像,发展到近期的数百万张图像,其训练数据规模也经历了大幅增长。尽管如此,其零样本和小样本性能仍高度依赖于具体任务类型。目前,在临床环境中应用最为成熟的场景包括切片分类(例如区分良性与恶性肿瘤)以及图像分割。然而,要在性能上超越强大的任务特定深度学习模型,通常仍需要进行大规模的微调。此外,由于当前公开可用的病理影像数据主要集中在肿瘤学领域,基础模型在非肿瘤学应用场景中的性能目前仍相对有限。
未来基于基础模型的药物发现范式
作者进行了一项思想实验:基于当前基础模型的性能,对其进行外推,以勾勒出一个未来可能实现的、由基础模型端到端驱动的药物发现流程。图3对这一范式进行了示意,并将其与传统药物发现流程进行了对比。
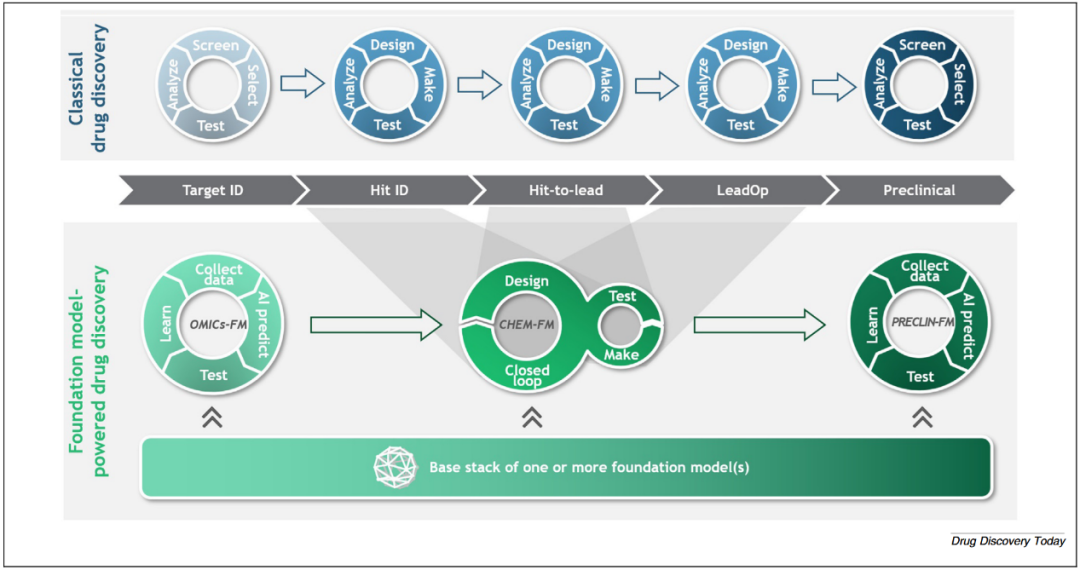
图3 由基础模型驱动的药物发现可能呈现的未来形态(下排),以及其与传统药物发现研究流程(上排)的对比。
靶点识别阶段
当前,靶点的发现与验证仍是一个高度迭代的实验过程,涉及多轮筛选、选择、测试和数据分析。未来,这些任务有望由一个在公共与专有多组学数据集及已发表文献上训练的基础模型来支持(将其称为OMICs-FM)。该模型能够识别靶点-通路-疾病之间的关联,并为新的靶点假设提供置信度评分。为确保其持续反映对疾病机制的最新认知,OMICs-FM需要被频繁地重新训练和微调。
分子设计阶段
对于小分子而言,当前的经典发现流程是一个高度迭代的实验过程,由多轮“设计–合成–测试–分析”(DMTA)循环构成。未来,这一过程有望由一个化学基础模型(CHEM-FM)所驱动。该模型将对SMILES 表示、二维分子图以及由质谱(MS)/核磁共振(NMR)谱学数据驱动的三维构象状态进行联合表征。CHEM-FM将充当通用的编码器/解码器,用于分子生成、对接、药物相似性评估、ADMET分析以及逆合成路径推荐。此外,CHEM-FM还将支持基于蛋白结构的小分子设计,通过生成并评分由全原子协同折叠预测的三维蛋白–配体复合物结构,从而减少对耗时、昂贵的结合亲和力实验及其他方法的依赖。
临床前优化与预测性安全评估
由CHEM-FM产出的先导化合物将交由一个临床前基础模型(PRECLIN-FM)进行分析与优化。该模型通过从人类器官芯片数据中进行迁移学习,在任何体内给药之前预测动物模型中的暴露水平与毒性风险。PRECLIN-FM能够识别与历史研发失败相关的表型特征,并输出排序评分或可转化性指数,该指数综合了对人体疗效窗口、潜在风险的预测,用于指导应优先推进哪些化合物系列。一旦某一系列推进至候选药物阶段,常规的临床前测试(包括毒性、药代动力学、药效学等监管要求的研究)将继续开展,以最终确保分子的安全性与有效性。
前提条件与局限性
首先,在上述思想实验中所描述的许多基础模型目前尚不存在,或其性能尚不足以支撑相应应用。然而,其中一些模型已经开始被构想,并在一定程度上得到实现。因此,所需的关键技术在未来数年内具备可行性。总体而言,无论是技术还是数据,尤其是与生物学模态相关的部分,与自然语言或计算机视觉等相比仍处于相对早期阶段,要实现长期、可持续的成功,仍有大量工作有待完成。
其次,生物学体系的规模与复杂性可能使思想实验中的某些步骤在现实中难以实现。例如,据估计,人类细胞中基因–基因成对相互作用的总数超过2亿,而具有药物相似性的有机小分子的可达化学空间则被估计约为10^60。相比之下,即便是当前规模最大的基础模型,其训练数据集仍小了多个数量级。在缺乏规模大得多、且可能需要极长时间才能收集的数据集的情况下,基于基础模型对生物与化学空间的全面探索仍可能受到显著限制。
第三,基础模型本身仍面临多项技术挑战,这些问题可能对所提出的范式构成制约。这些挑战包括:模型幻觉问题,目前仍普遍存在于许多基础模型中;对某些并非专为药物发现设计的模型架构与训练方法的依赖,例如直接借鉴自大语言模型的Transformer架构;以及对高度动态的生物学过程进行建模的困难,因为许多基础模型更擅长刻画数据的静态快照,而非动态变化过程。
鉴于上述限制,仍有若干现实问题有待解答。具体而言,基础模型的底层技术栈应当如何构建?是否有可能通过单一的基础模型来支撑药物发现的全部环节,即同时涵盖OMICs-FM、CHEM-FM和PRECLIN-FM?抑或需要多个彼此独立、分别训练的基础模型协同工作?答案尚待时间检验,但鉴于该领域进展极为迅速,或许在未来几年内便能获得清晰结论。
参考链接:
https://doi.org/10.1016/j.drudis.2025.104518
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢