
【论文标题】Future-Guided Incremental Transformer for Simultaneous Translation
【作者团队】Shaolei Zhang, Yang Feng, Liangyou Li
【发表时间】2020/12/23
【论文链接】https://arxiv.org/pdf/2012.12465.pdf
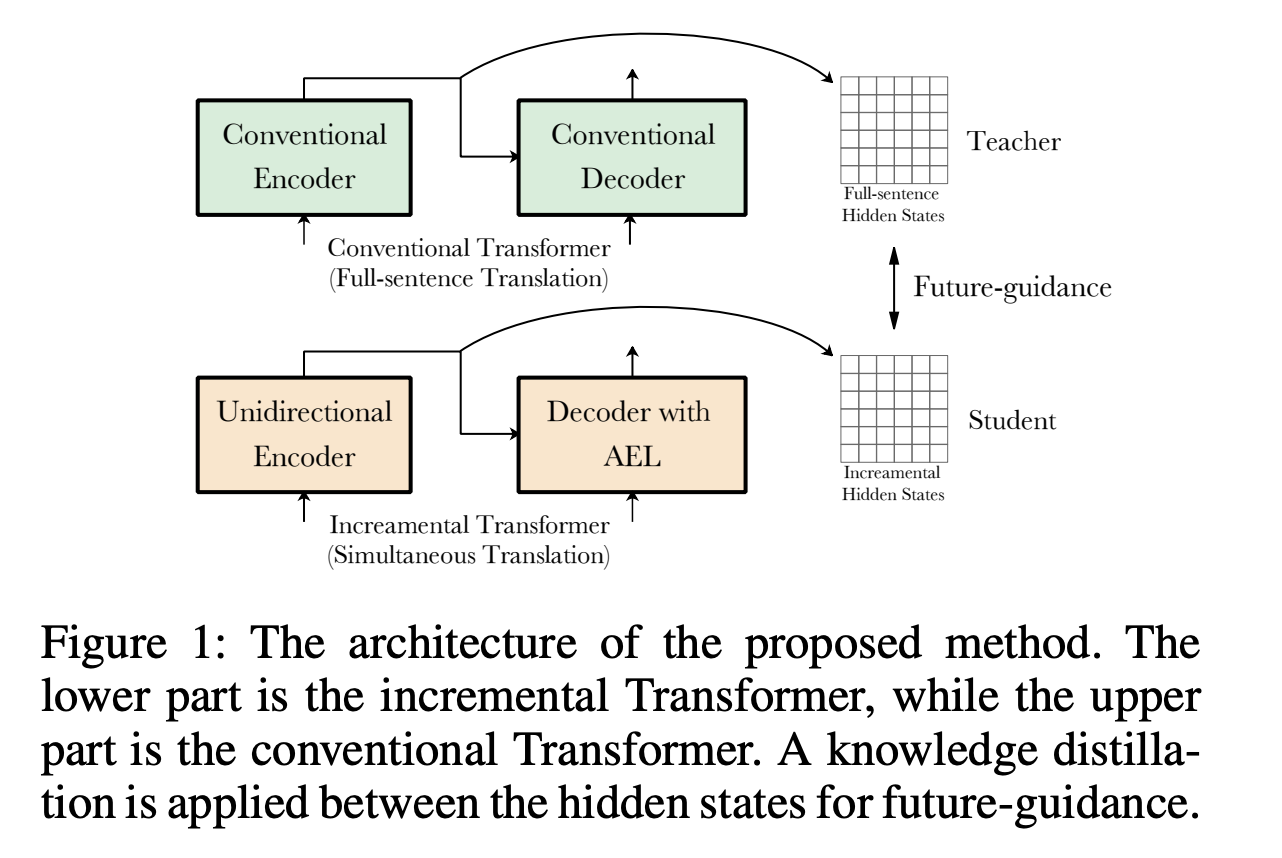
【推荐理由】本文来自中科院和华为诺亚方舟实验室,已被AAAI2021接收。为了加快wait-k策略的训练速度,并能够利用未来信息来指导训练,文章提出了未来指导的增量式同声翻译Transformer。
同时翻译(ST)在阅读原文句子时开始同步翻译,在许多在线场景中使用。之前提出的wait-k策略比较简单,在ST上取得了良好的效果。然而,wait-k策略有两个弱点:第一是重新计算隐藏状态导致的训练速度较慢,第二是缺乏未来的源信息来指导训练。针对训练速度较慢的问题,作者提出了一种带平均嵌入层的增量Transformer,以加快训练过程中隐藏状态的计算速度。对于未来导向训练,作者使用一个传统的Transformer作为增量Transformer的teacher模型,并尝试通过知识蒸馏将一些未来信息无形地嵌入到模型中。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢