

引言
人们对大模型(LLM)的期待正在发生变化:不再满足于“答得对”,而是希望它懂我。因此,persona、用户记忆等个性化信息被越来越广泛地引入到主流模型里,用来提升长期交互体验与用户满意度。但一个自然的问题随之出现:当个性化信息让模型更了解用户偏好时,会不会也在不经意间影响模型的其他能力——尤其是客观性与事实正确性?
为此,我们做了一个简单的对照实验:在同一组任务上,分别评估模型在三种 persona 设置下的表现——no persona(不提供个性化信息)、aligned persona(persona 与问题领域相关/一致)、unaligned persona(persona 与问题无关/不匹配)。这也更贴近真实使用场景:用户可能询问其领域问题,但有时用户信息也可能只是“存在于上下文里”,与当下问题并不相关。
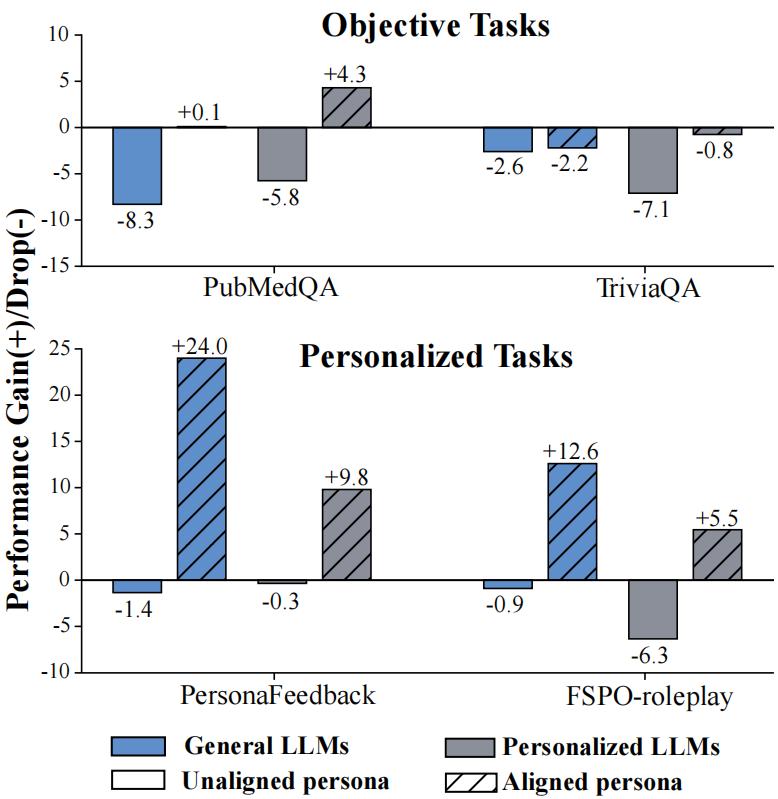
结果表明个性化信息的效用在很大程度上取决于具体任务。虽然人物角色信息有助于实现主观上的个性化,但在不加区分地使用时,它可能会干扰客观的推理过程。那么大模型如何能够自主决定何时融入个性化信息,从而在实现个性化优势的同时保证客观的准确性呢?
为了回答这一问题,来自复旦大学、上海创智学院、OPPO公司的学者构建了用于平衡模型客观问题解决能力和个性化能力的框架PersonaDual,它将客观和个性推理整合于同一模型之中,并根据用户查询及个性化信息自动切换这两种模式。
论文地址:
https://arxiv.org/abs/2601.08679
PersonaDual
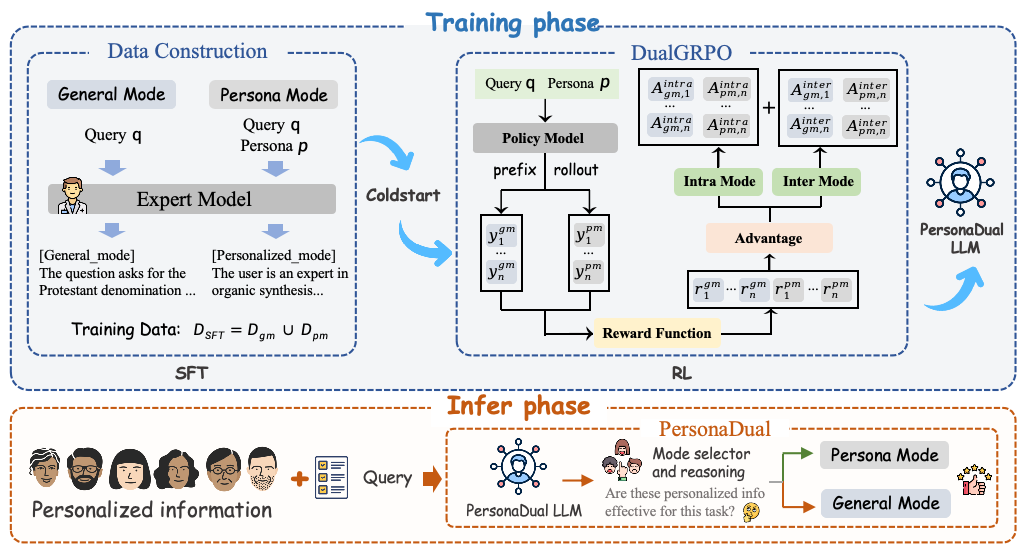
图2 :PersonaDual框架概述图。
框架介绍
研究的目标是让模型自适应决定:在回答一个问题时,什么时候应该利用个性化信息,什么时候应该忽略它以保持客观正确性。为此,PersonaDual把一次回答拆成“先选模式,再推理生成”两步。我们记用户输入问题为q,个性化信息为p,并在系统中内置两种推理模式:通用客观推理模式和个性化推理模式。
在单次回答中,如图2 下方,模型先根据 (q,p) 选择一个推理模式 ,并在推理前加入显式的模式前缀,使用选择的模式进行推理和生成回答。这样的设计把“该不该用 persona”从隐式行为变成显式决策变量,并通过训练让模型学会在不同任务下做出合理的选择。
一阶段:混合模式集成
在监督微调阶段(图2 左上),我们为同一类任务构造两种风格明确的示范数据,让模型学会两套稳定的推理习惯:
客观推理模式(General Mode):只提供问题q,刻意省略用户信息,要求推理“基于事实证据与逻辑演绎”,形成去个性化的思考范式;
个性化推理模式(Persona Mode):提供完整 (q,p),要求显式分析用户属性,如职业、兴趣、偏好等,并把它们真正融入推理链。
通过这种混合模式SFT,模型学会两种模式,并把客观推理与个性化推理的行为边界拉开,为后续学习“何时用哪种”打好地基。
二阶段:自适应模式选择
仅靠 SFT,模型可能“会两种回答模式”,但不一定“选得准”。因此我们用强化学习优化模式选择,提出DualGRPO(图2 右上):
强制前缀采样:对每个 (q,p),在rollout时同时在General和Persona两种模式下都生成一批候选回答,保证模型在训练时能看到同一题两种模式分别会怎么答。
双模式优势分数:优势分数同时包含模式内对比(同模式里谁更好)与模式间对比(两种模式整体上谁更优),让奖励直接指向“这题更该用哪个模式”。
最终,模型学习到的不是“永远更个性化”或“永远更客观”,而是根据问题与persona自适应切换,兼顾个性化收益与客观正确性。
实验
实验设置
PersonaDual实现的基座模型为非思考模式的Qwen3-8B,训练数据PersonaDualData来自通用客观数据UltraMedical、FLAN与个性化数据 AlignX。为了模拟真实场景中persona与问题可能相关也可能无关,客观任务设置两种 persona 条件:Unaligned(从 PersonaHub随机抽取,与问题无关)与 Aligned(由 GPT-4o 基于问题内容生成相关 persona)。
对比基线分三类:通用模型(CoT、G-SFT-RL)、个性化模型(Personal-Prompt、P-SFT-RL、ALIGNXPERT 系列)、以及“用提示词/外部路由器实现双模式”的替代方案(PersonaDual-Prompt / PersonaDual-Router)。
评测方面,研究构建了覆盖“客观能力 + 个性化能力”的基准集合:客观任务包括 MMLU-Pro、SuperGPQA、TriviaQA、PubMedQA、MATH500,个性化任务包括 PersonaFeedback、FSPO-roleplay。指标统一以准确率衡量。
实验结果
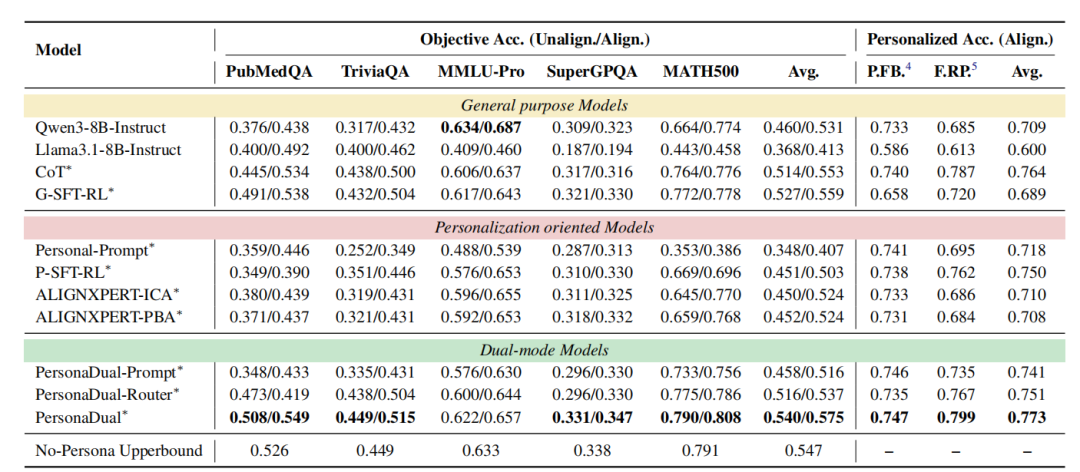
主要实验
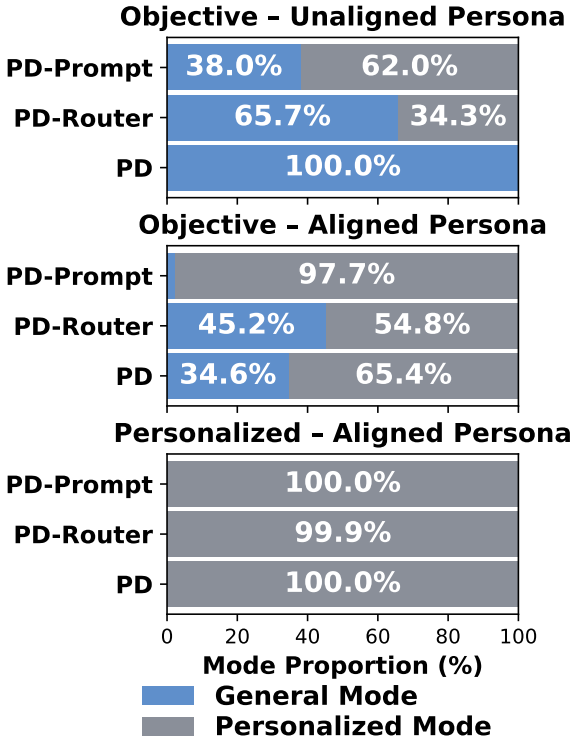
表 1 呈现了主要实验结果,我们发现:(1)PersonaDual 能有效应对个性化信息的“双面”效应。当 persona 与问题不相关时,它会过滤干扰信号,使客观任务平均准确率达到 54.0%,几乎贴近无个性化干扰上限 54.7%。而当 persona 与问题相关时,它又能利用这些有益线索提升事实正确性,整体表现比无个性化上限高 2.8%。(2)通用模型往往客观能力强但个性化弱,个性化导向模型则以牺牲客观性换取迎合用户偏好,而PersonaDual成功平衡了这两类模型的优势和不足,在保持通用客观能力的同时,在个性化任务上超过个性化导向模型。(3)PersonaDual的优势来自于“学会正确切换模式”:prompt-based 与 router-based 的双模式基线在 persona 不相关的客观题上仍会大量误触发个性化推理(如Figure 3),反映手写提示或启发式规则难以区分有益与有害的 persona 信号。相比之下,PersonaDual 通过自适应训练学到了更稳定、更合理的模式选择策略。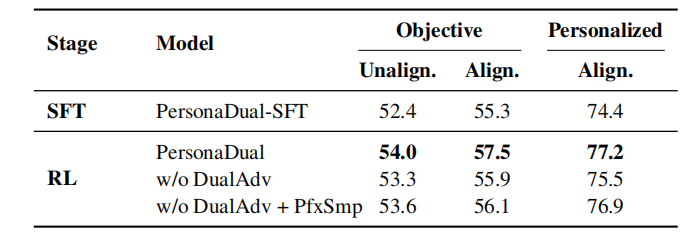
DualGRPO的必要性分析
为验证强化学习阶段的 DualGRPO 是否是 PersonaDual 能稳定工作的关键,我们在表 2 中对比了仅 SFT 与两阶段训练的表现,并进一步做了消融实验。我们发现:(1)两阶段训练必要性:引入 DualGRPO 后,模型在两种 persona 条件下都能继续提升客观表现,且在一致persona时增益更明显。这说明 DualGRPO 强化的核心是让模型更会识别哪些 persona是有益的,并据此选择正确的推理模式,从而把“有用的个性化”转化为客观正确性的提升。(2)组件耦合性:消融结果显示 DualGRPO 始终优于删改版本,其中强制前缀采样(PfxSmp) 与双模式优势(DualAdv) 是强耦合的:移除前缀强制约束会导致塌缩到单一模式,而没有 DualAdv 时,即便强制采样了两种前缀,也缺少跨模式的明确奖励指引。DualGRPO 通过“强制两种模式+提供模式间优势信号”的组合,让模型具备在persona变化时依然能够灵活根据语境切换模式的能力。
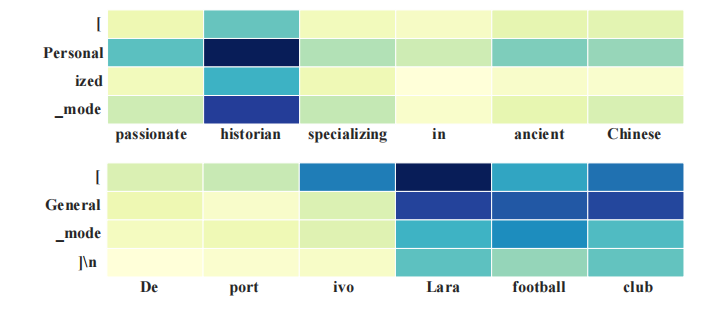

模式选择信号分析
为了回答“模型到底根据个性化信息中的什么关键信息决定用不用persona”,我们从外部可观测信号与内部机制两个层面做了验证。我们发现:(1)词汇层面的可预测信号:研究用逻辑回归拟合“输入 token → 模式选择”,并提取影响最大的 Top-30 预测 token(图 5)。结果显示出现频率最高的往往是职业与专业背景相关词,如 historian、professor、students、mathematician等,这表明“用户的职业/专业描述”是驱动模型自适应切换的重要信息线索。(2)注意力机制的内部验证:我们进一步检查模型在persona token上的注意力分布。对同一个 query,分别提供 aligned persona 与 unaligned persona,并对比不同persona token的注意力权重(图 4)。结果显示模型确实对persona中的职业词 historian、兴趣词 football给予重要关注。
模式选择鲁棒性分析
为评估PersonaDual在真实对话中“问题类型交替出现”时是否依然能稳定选对模式,我们将原测试集重构为两轮对话,模拟用户在同一会话里穿插客观问题与个性化问题,并设置两种顺序:general→personalized 与personalized→general。结果呈现出明显的差异性:当第一轮先走个性化模式时,PersonaDual在第二轮依然保持100%的通用模式一致性;但当第一轮先走通用模式时,一致性下降到84.3%,说明“从客观推理切到个性化推理”是更具挑战的切换场景。
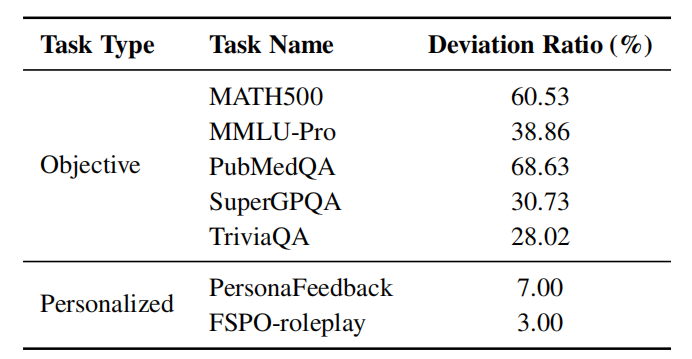
为定位偏移来源,我们按任务类型统计模式偏移比例(表 3),发现偏移主要发生在客观数据集而非个性化数据集。一个可能的解释是:在前一轮客观问题的影响下,模型更容易依赖“表层任务类型”来判断,反而弱化了对“persona 与当前 query是否相关”的判断,从而导致与单轮不同的模式选择。未来可通过加入多轮训练数据来增强混合对话中的灵活切换与整体鲁棒性。
结论与局限性
本研究针对个性化信息可能削弱大模型客观性与事实正确性的风险,提出了PersonaDual:一个让模型在“通用客观推理”和“个性化推理”之间自适应切换的框架。PersonaDual通过监督微调在同一模型中统一两种推理模式,并进一步提出DualGRPO,在强化学习阶段显式提升模型在不同上下文中选择合适推理模式的能力。大量实验表明,PersonaDual能在多种个性化设置与任务场景中保持稳定优势:当persona不相关时,它能显著缓解干扰,使客观表现接近“无干扰”的水平;当 persona 相关时,它又能把有益线索转化为准确率增益,使客观问答整体提升接近 3%。
尽管PersonaDual取得了积极效果,但仍存在局限:由于当前个性化评测基准有限,我们仅在PersonaFeedback与 FSPO-roleplay上对验证了模型的个性化能力,覆盖面仍不够丰富,未来需要扩展到更多类型、更贴近真实场景的个性化基准,以更全面检验方法的泛化性。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区袁天凡、慧敏校园C栋

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢