

项目资源
代码 & 语音样例:
https://github.com/SirryChen/SpeechMedAssist
论文链接:
https://arxiv.org/abs/2601.04638v1
Demo:
https://speech.medassist.chat
引言
在现实生活中,真实的医疗咨询是基于语音对话进行的。而语音中除了患者的主诉外,还包含大量副语言信息,例如咳嗽等等重要病症。然而,当前大多数医疗大模型,仍然停留在长文本问答的范式中。
🩺医疗咨询应该以语音交互为主要范式
医疗咨询从来不是一个“信息一次性输入、答案一次性输出”的过程。
在真实场景中,患者往往只能给出模糊、片段化的症状描述,而医生需要通过多轮追问逐步澄清关键信息,最终形成诊断与建议。然而,当前主流的医疗大模型,大多仍沿用文本问答范式,这在交互层面带来了结构性的错位。

图 1:现有基于文本交互的医疗咨询的缺陷和基于语音交互的医疗咨询的优点
如 图1 上侧所示,文本医疗模型通常假设:
患者能够一次性、完整、准确地描述症状(但是患者的描述通常是模糊的)
模型直接根据患者的输入给出冗长的诊断与解释
但在真实医疗咨询中,这一假设往往并不成立。对于老年人、低识字用户或非专业患者而言,打字本身就是一道门槛;更重要的是,文本输入无法自然承载语音中蕴含的节奏、犹豫、停顿,乃至咳嗽等副语言信息。
相比之下,图1 下侧展示的基于语音的医疗咨询范式,在交互形态上更贴近真实诊疗流程:
患者通过自然语音逐步描述症状,模型能够进行主动追问与动态引导
基于语音的交互更友好,适用人群更广,能捕捉副语言信息
咨询过程呈现为连续、多轮的对话
在这一范式下,医疗咨询不再是“填空式输入”,而更像一次真实的门诊交流。
🤔如何实现基于语音交互的医疗咨询呢?
尽管语音交互在形式上更自然,但让模型“会说话”并不等于“会看病”。真正的挑战在于: 如何让模型在语音交互中,同时具备医学知识、临床推理能力和安全意识?
具体而言,直接使用现有的语音大模型用于医疗咨询面临三大挑战:
医学知识不足
现有语音大模型大多训练于通用数据,缺乏系统的医学知识结构。
多轮问诊与主动追问等能力缺失
医疗咨询强调逐步信息获取等专业技巧,这对模型的对话策略提出了更高要求。
高质量医疗语音数据极度稀缺
直接依赖语音数据进行医学能力学习,成本高、效率低,且难以规模化。
正因如此,如何在不依赖大规模真实医疗语音数据的前提下,构建真正可用的语音医疗大模型,仍是一个开放问题。
💡 我们的思路:
将直接从语音数据中学习解耦
基于上述问题,我们提出了 SpeechMedAssist:一个原生支持语音多轮医疗咨询的 SpeechLM。
核心思想很简单,但非常关键:
语音大模型既可以从语音中学习知识,也可以从文本中学习。
因此首先使用文本数据将医学知识和临床能力高效注入LLM core;
再使用少量的语音数据重新对齐语音和文本模态。
由此我们设计了一种 两阶段训练范式。
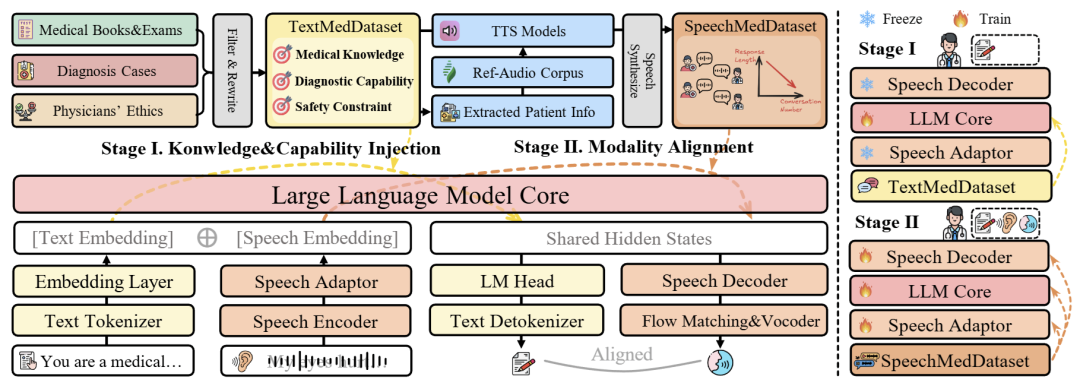
图2 :我们工作的整体概览,包括数据构建流程、模型架构、训练策略。
🔧 两阶段训练:
解耦为“知识注入”和“模态重对齐”
Stage I:
用文本高效注入医学知识与诊疗能力
在第一阶段,我们冻结语音大模型中所有语音相关的模块,仅训练 LLM 核心,让模型通过大规模医学文本学习:
医学知识(疾病、用药、检查)
临床推理能力
医疗安全与伦理边界
多轮问诊结构与主动追问能力
为此,我们构建了 TextMedDataset(405k),涵盖医学考试、百科问答、多轮问诊和安全数据。
Stage II:
用少量语音数据重新对齐模态
文本“学会了”,但模型还需要“说得出来”。
第二阶段,我们只使用极少量医学语音数据,对模型进行模态重对齐:
对齐语音与文本的共享语义空间
学会在语音输入下正确调用已掌握的医学能力
提升语音生成的自然度与一致性
令人惊讶的是:
👉 仅 10k 条合成医学语音,就足以完成有效对齐。这一点在实验中得到了系统验证。
🗂 数据怎么来?
我们构建了完整的“重写 + 合成”流水线
为了支撑两阶段训练,我们设计了一套可扩展的数据构建流程:
文本重写
将冗长、单轮的医学问答,重写为贴近真实问诊流程的多轮对话患者属性建模
自动推断患者的性别、年龄段
条件语音合成
患者属性明确 → 使用 CosyVoice+2000余真实说话人参考音频
患者信息缺失 → 使用 FishSpeech 随机音色
最终,我们构建了 SpeechMedDataset(198k),覆盖多轮、真实风格的医学语音对话。
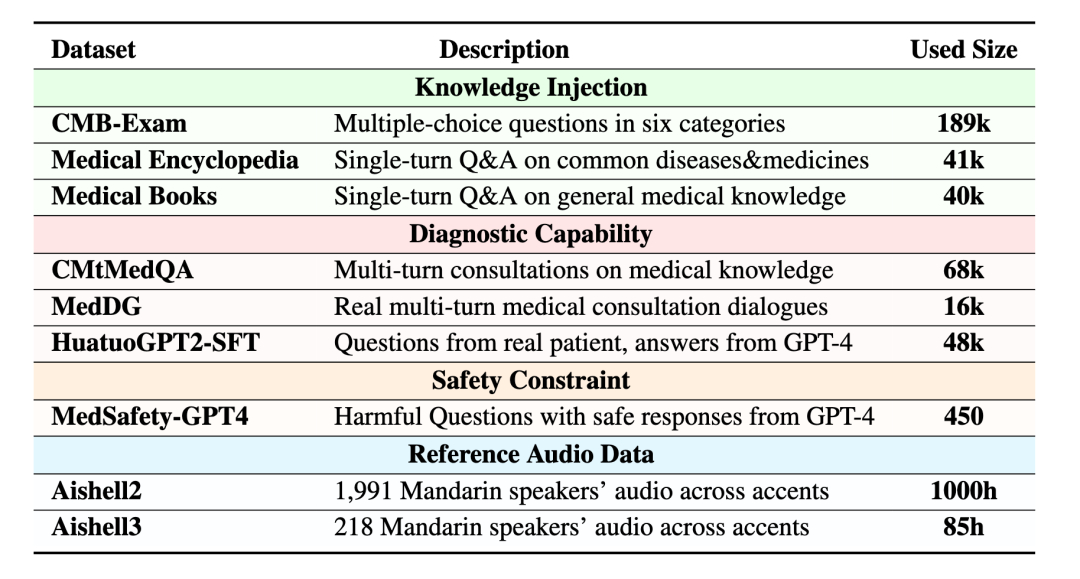
表1: 构建TextMedDataset与SpeechMedDataset使用的数据集。
📊 怎么评测“语音医疗模型”?
我们提出 SpeechMedBench
现有评测要么只看医学问答,要么只看语音质量,但真实医疗咨询两者缺一不可。因此,我们设计了 SpeechMedBench,从四个维度系统评测:
医学知识与安全性(单轮 Q&A)
多轮问诊能力(模拟真实患者)
真实环境鲁棒性
语音质量与延迟
在几乎所有评测设置中,SpeechMedAssist 都显著优于:
级联系统(ASR + 医疗 LLM + TTS)
通用 SpeechLM
多模态 Omni 模型
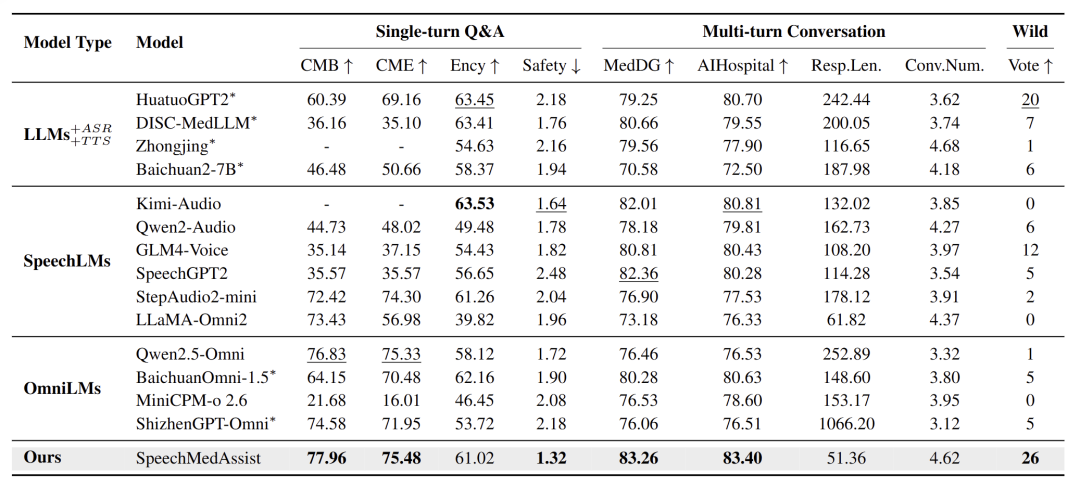
表2 :主实验结果。SpeechMedAsssist在单轮问答、多轮对话和真实场景下都表现出优异的性能。
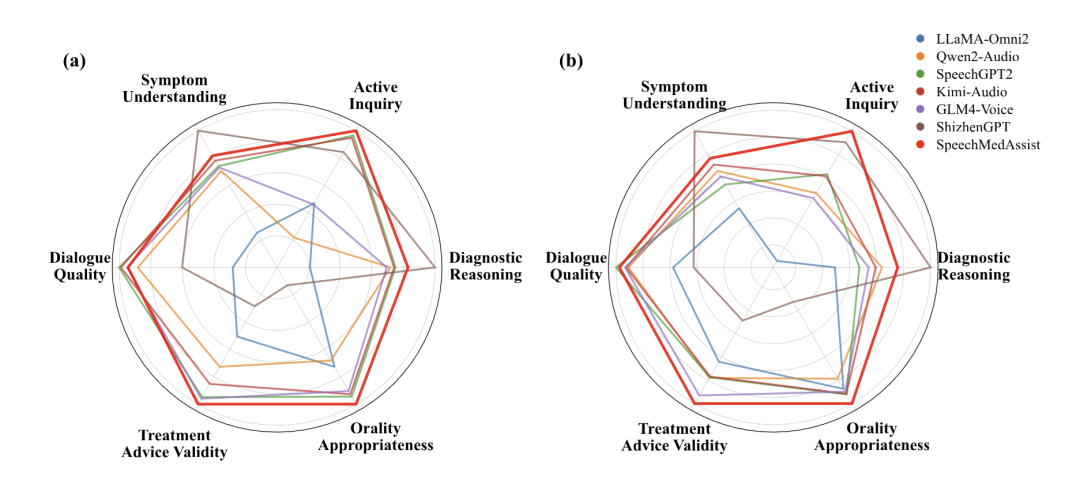
图3 在多轮对话多维度评测指标(a) MedDG,(b) AIHospital上, 除少数偏向长文本回复的维度外,我们的模型在整体上展现出较强的诊断与交流能力。
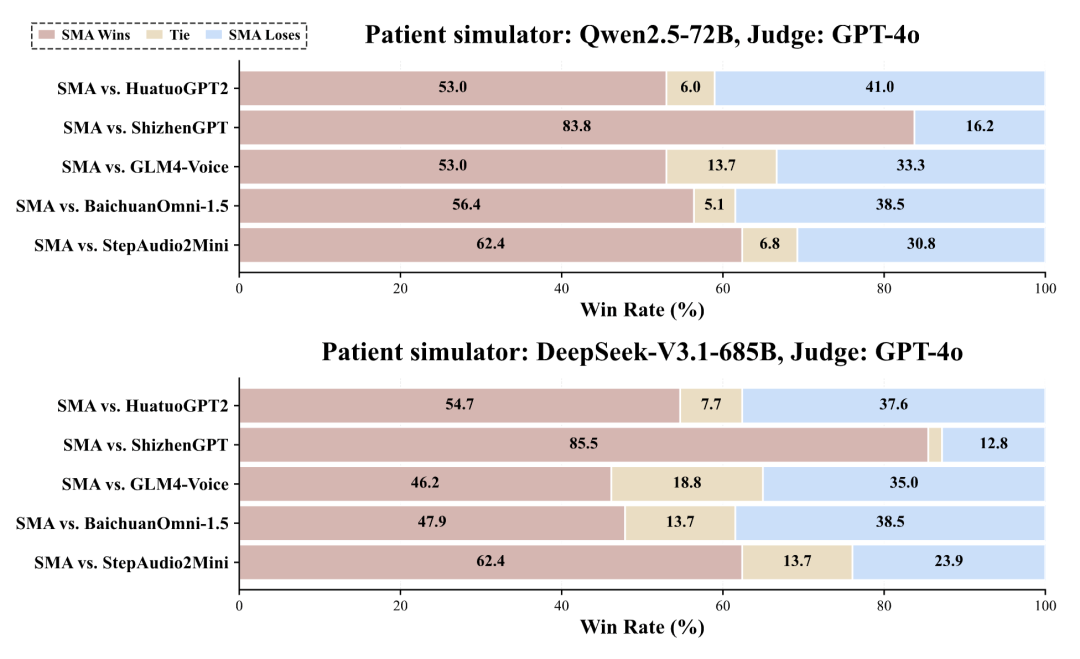
图4 以不同模型作为患者模拟器、GPT-4o 作为评审的设定下,我们的模型相比强基线模型均取得了更高的胜率。
🔍 深入研究:
为什么这种方法有效?
通过系统消融实验,我们发现:
直接用语音学医学,是低效且不稳定的(表3)
两阶段的训练是必要且有效的(表3)
第二阶段的模态重对齐只需要10k量级的少量语音数据(图5)
更重要的是,SpeechMedAssist:
对噪声更鲁棒且能感知咳嗽等副语言信息(表4)
语音输出的自然度接近TTS模型,延迟表现优异(表5)
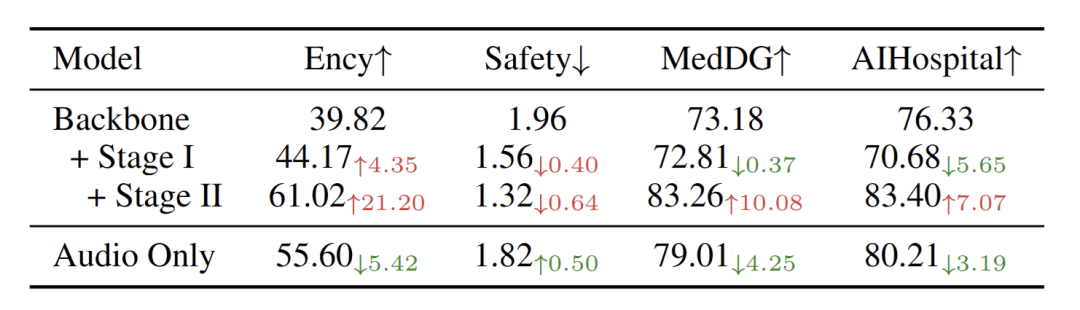
表3 :对比不同训练阶段和仅使用语音数据进行训练的性能。
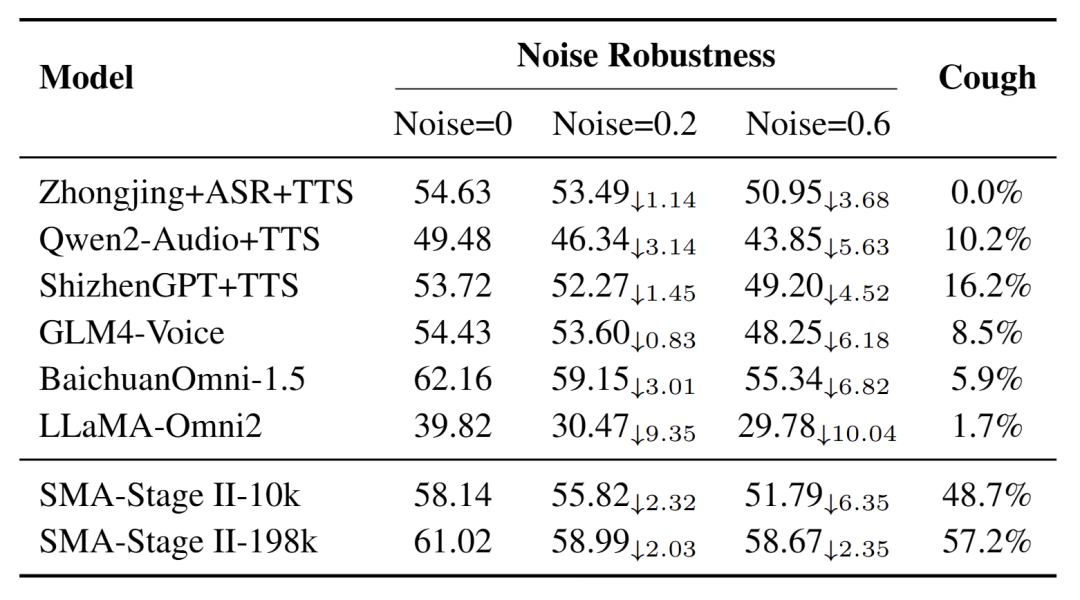
表4 :在不同程度噪音环境下的性能表现和对咳嗽的感知能力。
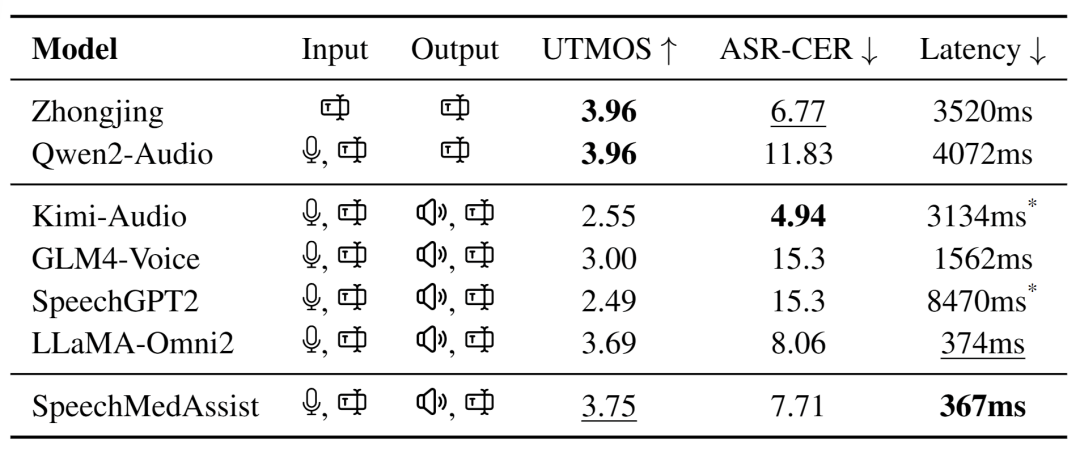
表5 :输入与输出能力以及输出语音的质量。
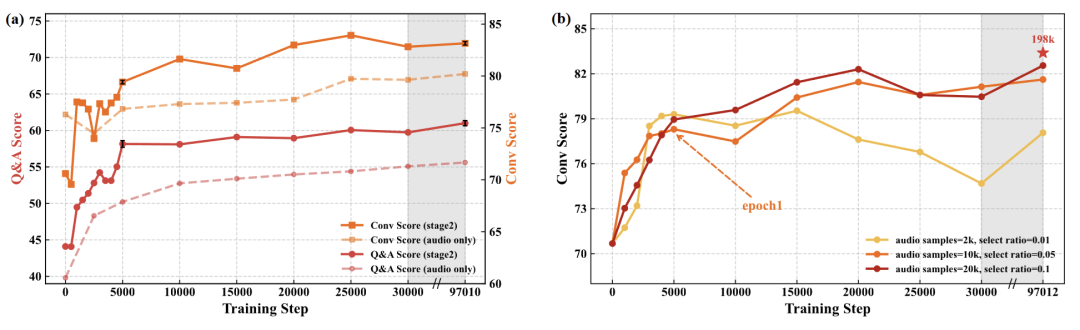
图5:
在不同训练步数下,(a) 对比两阶段训练与仅使用语音数据训练得到的模型在单轮问答和多轮对话评测中的性能表现。
(b) 对比第二阶段使用不同规模语音数据进行训练,10k左右的语音即可获得接近使用 198k 条样本训练模型的性能。
总结
SpeechMedAssist 证明了一件事:
将语音大模型应用到医疗等垂直领域,不需要大量的垂域语音数据,
可以将其解耦为基于大量文本数据的“知识学习”和基于少量语音数据的“模态重对齐”。
我们希望这项工作能为 SpeechLM 在低资源垂直领域的落地 提供一个可复用的范式。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区袁天凡、慧敏校园C栋

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢