

人类幼崽在在牙牙学语前,是通过观察绘本中的世界、探索积木的堆叠、追踪蝴蝶的踪迹,是在视觉探索中逐步建立起对世界的认知的。
然而,一项实证结果和人工评估表明,当撇开依赖的文字推理,领先的多模态大语言模型(MLLM)的视觉推理能力远低于人类基准水平。
评测发现,GPT-5.2 的整体表现甚至不如人类 3 岁儿童,而当前最强模型 Gemini3-Pro-Preview,也未达到 6 岁儿童的平均水平。
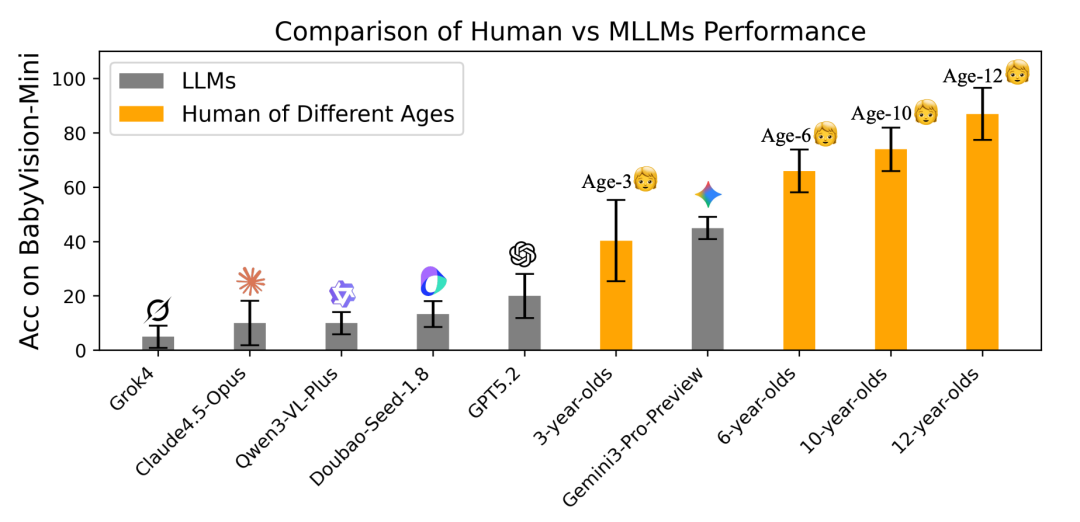
图|不同年龄段人类及 MLLM 在 BabyVision 上的表现对比。
这一结论来自 UniPat AI 团队及其合作者发表的最新研究——他们推出了 BabyVision 评估框架,旨在独立于语言知识评估 MLLM 的核心视觉能力。

论文链接:https://arxiv.org/pdf/2601.06521
这一研究表明,尽管在知识密集型评估中表现优异,但当前的 MLLM 仍缺乏基础视觉原语。BabyVision 的进展标志着人类级视觉感知与推理能力的又一步突破。
研究团队还通过提出 BabyVision-Gen 生成模型及自动评估工具包,探索用生成模型解决视觉推理问题。
为什么失败?
那么问题来了,为什么当前的 AI 能解开复杂的微积分题目,却走不出一个简单的迷宫?
研究团队认为,关键在于 AI 的“语言表达瓶颈”。目前的 MLLM 处理视觉任务的底层逻辑是先将图像转化为语言,再进行逻辑推理。但是,许多视觉信息本质上难以被准确语言化。
例如,曲线的精确弯曲度、复杂的空间拓扑关系、微妙的纹理差异,语言很难精准描述,只能通过视觉观察去感受。当 AI 试图用语言去描述这些视觉信息时,大量关键细节就丢失了。
1.当“翻译”失效时
通过定性分析,当 MLLM 试图强行用语言去“压缩”视觉信息时,研究人员总结了 AI 在视觉推理上的四种典型的失效模式:
AI 只能看个大概。由于语言描述的模糊性,模型无法区分依赖于微小曲率或边缘对齐的候选对象,将“非常相似”误判为“完全相同”;
AI 缺乏空间想象力。它试图用语言逻辑来推导 3D 视图,导致在面对遮挡和视角变换时产生幻觉;
AI 流形身份丢失。在视觉追踪(如连线或迷宫)中,AI 无法像人类一样“锁定”一条曲线。在交叉路口,AI 经常跟丢,错误地切换到另一条线上,因为它无法在脑海中保持对线条连续性的表征。
AI 模式归纳失败。AI 往往关注颜色等表面属性,而忽略了旋转、嵌套等底层的结构化变换规则。
2.为什么“多思考”救不了“视觉追踪”?
为了验证“语言瓶颈”理论,研究团队进行了一项有趣的实验,使用可验证奖励强化学习(RLVR)对 Qwen3-VL-8B-Thinking 进行了微调,鼓励模型生成更长、更详细的“思维链”(CoT)来辅助推理。
结果 RLVR 确实让模型在 BabyVision 上的整体准确率提升了 4.8%。然而,在 “视觉追踪”(Visual Tracking)这一类别上,RLVR 微调几乎没有带来任何提升,甚至出现了负增长。
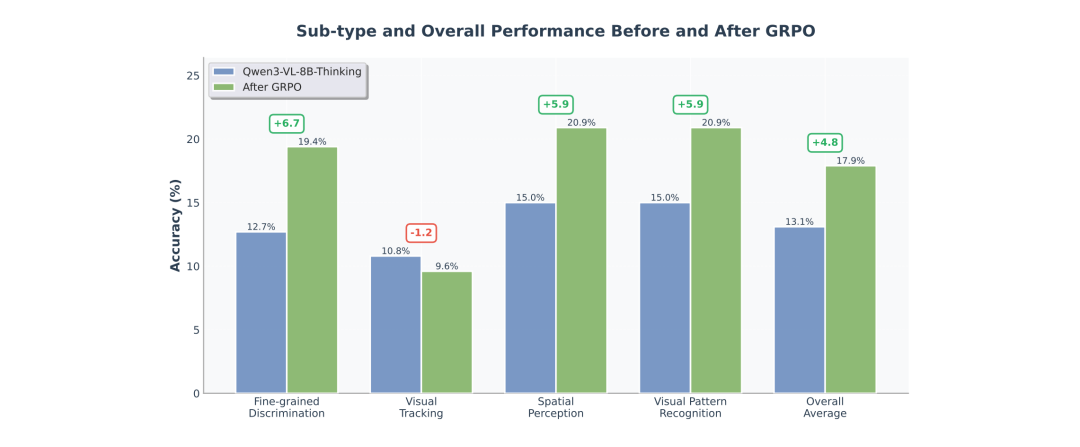
图|RLVR 微调前后 BabyVision 的准确率对比。
这也有力地佐证了“语言瓶颈”的存在。RLVR 的本质是鼓励模型进行更复杂的语言推理。但是,视觉追踪(如描绘迷宫路径)是最难以用语言表达的任务。无法用文字逻辑推导出一口井盖的圆形轨迹,你只能“看”到它。因此,单纯增加语言推理的深度,无法解决这种依赖连续感知而非语言中介的视觉难题 。
这些问题并非偶然,而是共同指向一个事实:当前 MLLM 进行视觉推理,仍受限于语言瓶颈。
BabyVision:一场针对AI“视觉本能”的测试
为了公平地测试 AI 的“视觉本能”,研究团队从发展心理学出发,刻意减少了 BabyVision 对文字知识的依赖,通过严格的数据整理流程,每张候选图像都由经过培训的标注员进⾏⼈⼯标注,最终题目包含 388 个精⼼挑选的问题,每个问题都与⼀张图⽚配对,涵盖以下四大核心视觉能力:
细粒度区分:类似于“大家来找茬”,测试模型能否在相似的图形中找出相同或不同的元素,或者完成图案的修补。
视觉追踪: 测试当物体移动线条交错或被遮挡后,模型是否还能保持对物体身份的连续追踪,例如走迷宫或地铁线路追踪。
空间感知:对 2D/3D 结构、位置关系的理解,例如数被遮挡的积木块、折纸或三维视图变换。
模式识别:测试模型能否从多个视觉实例中抽象出潜在的逻辑或几何规则,如旋转、镜像或逻辑序列。
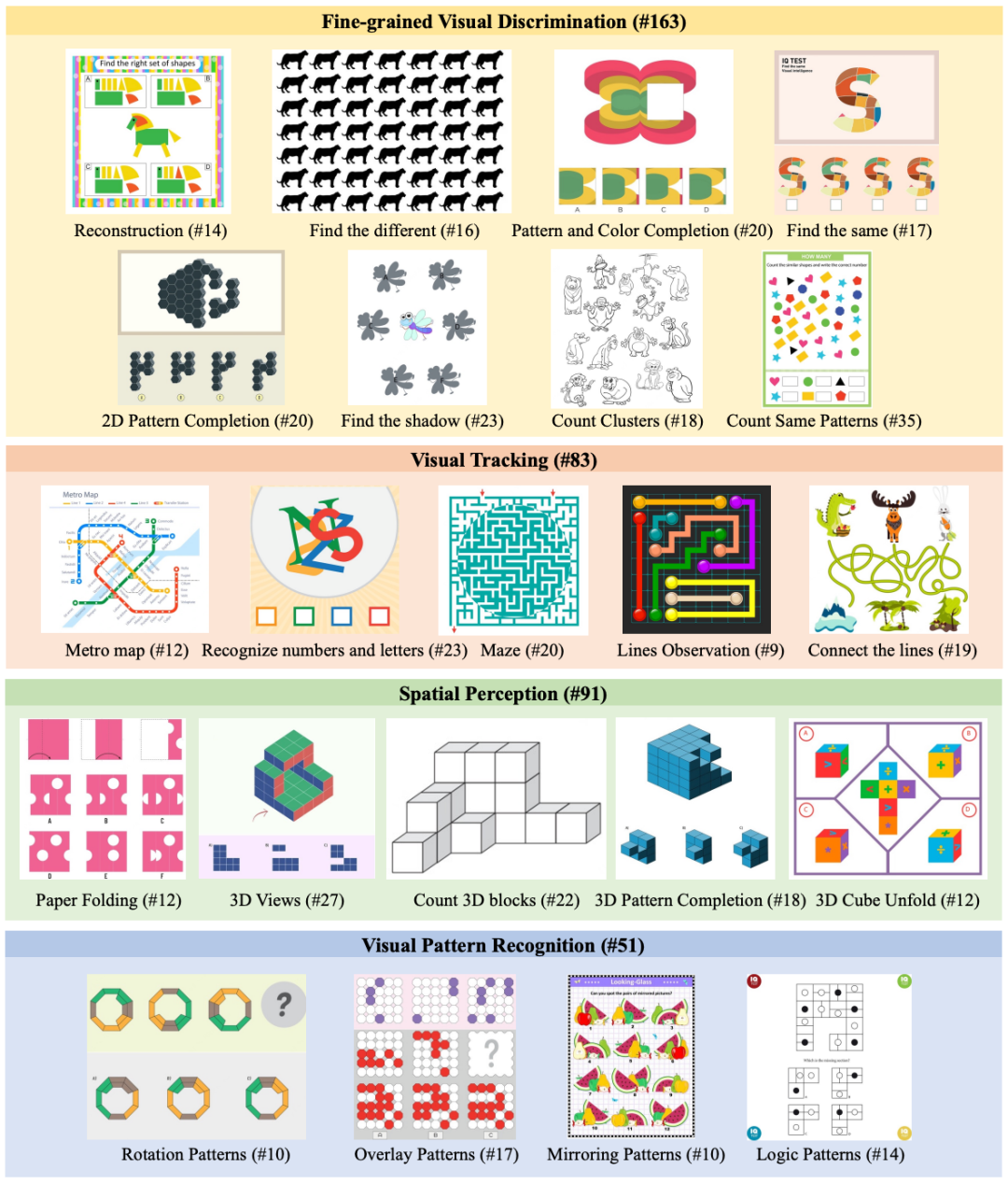
图|BabyVison 中跨越四大核心类别和 22 个类型的示例问题以及示例数量。
在 BabyVision 的测试中,成年人类的平均得分高达 94.1%。相比之下,表现最好的 AI 模型 Gemini3-Pro-Preview 仅获得 49.7%,两者之间存在 44.4% 的差距。大部分前沿模型的表现甚至低于人类 3 岁儿童的平均水平。
最困难的任务往往是最“基础”的任务。视觉追踪与空间感知类问题是模型失误集中的区域。在“数 3D 积木”(Count 3D Blocks)任务中,所有模型的准确率都极低,最佳仅为 20.5% 。在“找相同 / 找不同”这类看似简单的细粒度区分任务,模型也频繁给出错误答案,难以发现细微的像素级差异 。
总的来说,模型表现远远低于学龄前儿童。因此,在某些最基本的视觉推理能力上,当前的 MLLM 甚至尚未达到人类早期认知水平。
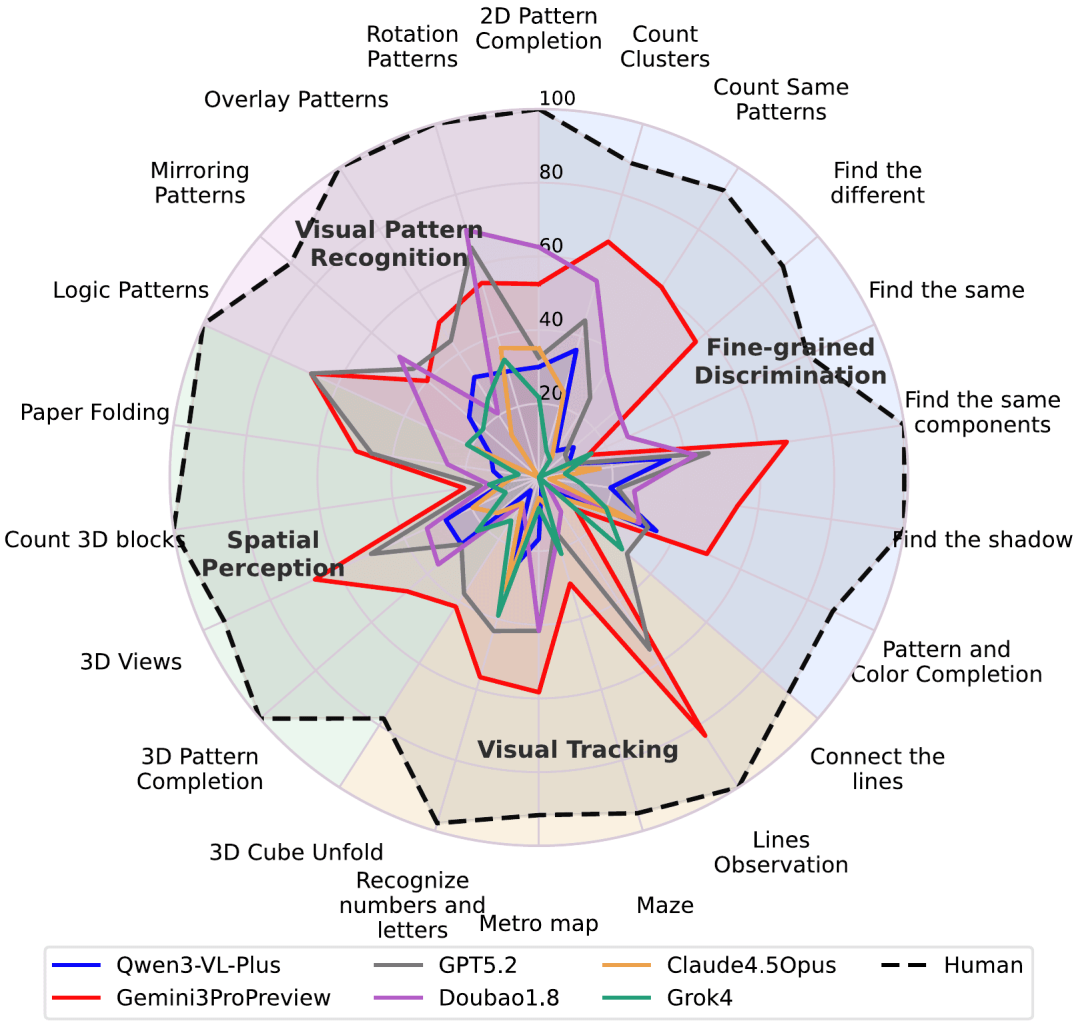
图|基于完整的 BabyVision 基准测试的精细性能分析
BabyVision-GEN:从“对图说话”到“用眼思考”
如果基于文本的推理显得不足,一个自然而然的问题随之产生:视觉生成能否弥补这一差距?与其用文字描述解决方案,模型能否画出答案,从而模仿儿童在进行视觉推理时直觉地指向、追踪或标记解决方案的方式?
基于这一见解,他们推出了 BabyVision-Gen。这是 BabyVision 的生成式扩展版本,用于评估图像和视频生成模型是否可以通过视觉输出来进行视觉推理。BabyVision-Gen 包含 280 个从原始基准测试中重新标注的问题,以支持基于生成的评估。通过将模型生成的输出与人类绘制的标准答案进行对比,可以直接且明确地验证其正确性。
他们在 Nano-Banana-Pro、GPT-1.5-Image、Qwen-Image-Edit-2511、Veo-3 和 Sora-2 等图像和视频生成模型上对 BabyVision-Gen 进行了评估,这些模型展现出了类似人类的视觉思维过程,比如可以明确地描绘出路径轨迹。尽管目前的准确率还不够高,但这证明了在视觉-语言模型(VLM)仍难以完成的任务上,视频生成可以作为多模态推理的一种范式。
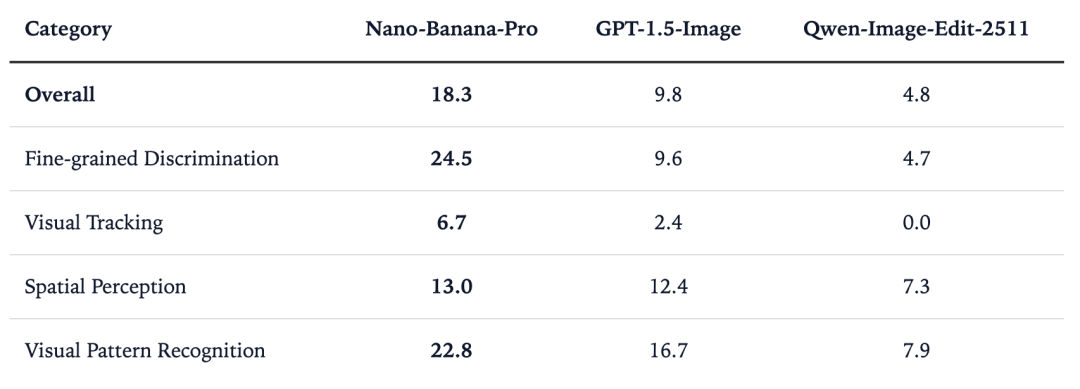
然而,尽管有这些令人鼓舞的表现,如上图所示,目前的生成模型在大多数情况下仍难以稳定地得出完全正确的解决方案。尽管如此,这些发现指向了一个令人信服的方向:类似于“视频模型是零样本学习者和推理者”,视频生成模型具有进化为全面多模态推理者的强大潜力,特别是当视觉推理立足于显式的视觉操作,而非仅仅依靠语言时。
未来的多模态模型,或许应当从目前的“语义对齐”走向“视觉原生”。让 AI 学会像从视觉获取信息,直接操作和变换视觉表征,而不是把一切都翻译成文字。
BabyVision 所揭示的,并不仅仅是模型的短板,也可能是下一阶段 AI 进化的关键入口。
作者:王江珏
如需转载或投稿,请直接在本文章评论区内留言。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢