

报告主题:AAAI 2026 Outstanding Paper Award|多模态表征模型能力边界LLM2CLIP
报告日期:01月29日(周四) 10:30-11:30
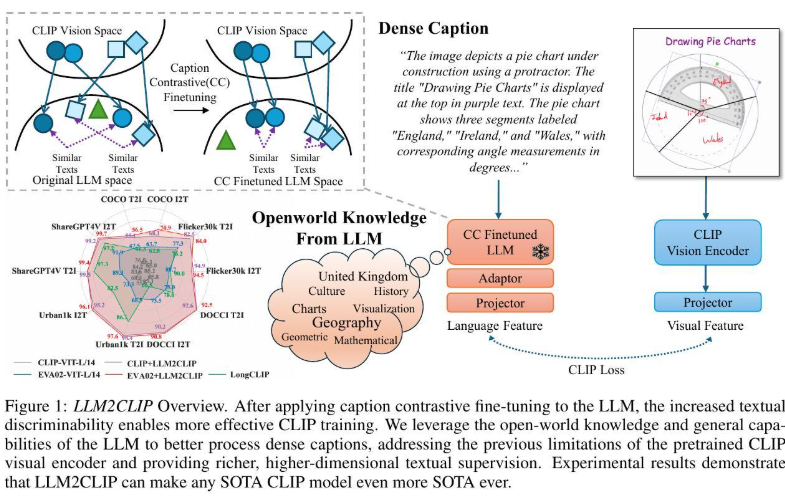
CLIP 是多模态表征学习领域的奠基性工作,通过在海量图文对上进行对比学习,将图像与文本映射到统一的表示空间,在零样本理解与跨模态检索等任务中取得了广泛成功。然而,现有 CLIP 类模型在理解长文本、复杂描述以及蕴含丰富世界知识的语义表达方面仍存在明显瓶颈。
受大语言模型(LLM)在语言理解与知识建模方面快速进展的启发,本报告将介绍 LLM2CLIP:一种将 LLM 高效引入 CLIP 体系、显著扩展其多模态表征能力的通用框架。该方法在几乎不增加训练成本的前提下,将 LLM 的语言理解能力注入预训练 CLIP 模型中,尤其显著提升其对长文本与复杂语义的建模能力。具体而言,LLM2CLIP 首先对 LLM 进行面向 CLIP 场景的“嵌入化”(embedding-ization),随后通过一个轻量级适配器将其与预训练的 CLIP 视觉编码器进行耦合,仅需在数百万规模的图文数据上进行微调即可完成训练,无需大规模重训模型。
在这一高效训练策略下,LLM2CLIP 在多个基准上显著超越 EVA02、SigLIP-2 等当前最强 CLIP 变体。
LLM2CLIP: Powerful Language Model Unlocks Richer Visual Representation


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢