

ICLR 2026

ICLR 2026, (International Conference on Learning Representations) 国际学习表征会议,是机器学习与深度学习领域的顶级会议,关注有关深度学习各个方面的前沿研究,在人工智能、统计和数据科学领域以及机器视觉、语音识别、文本理解等重要应用领域中发布了众多极其有影响力的论文。会议具有广泛且深远的国际影响力,居谷歌学术人工智能会议影响力排行榜前列,与 NeurIPS、ICML 并称为机器学习领域三大顶会。 ICLR 2026 将于2026年4月23日至4月27日在巴西里约热内卢举办。
近日,ICLR 2026 公布了论文录用结果。复旦大学数据智能与社会计算实验室共 3篇 论文被录用为主会长文。
Mixture-of-Visual-Thoughts: Exploring Context-Adaptive Reasoning Mode Selection for General Visual Reasoning
作者:李泽君,赵英秀,张霁雯,王思远,姚阳,赵润洲,宋俊,郑波,魏忠钰
类别:主会长文
合作单位:阿里巴巴集团
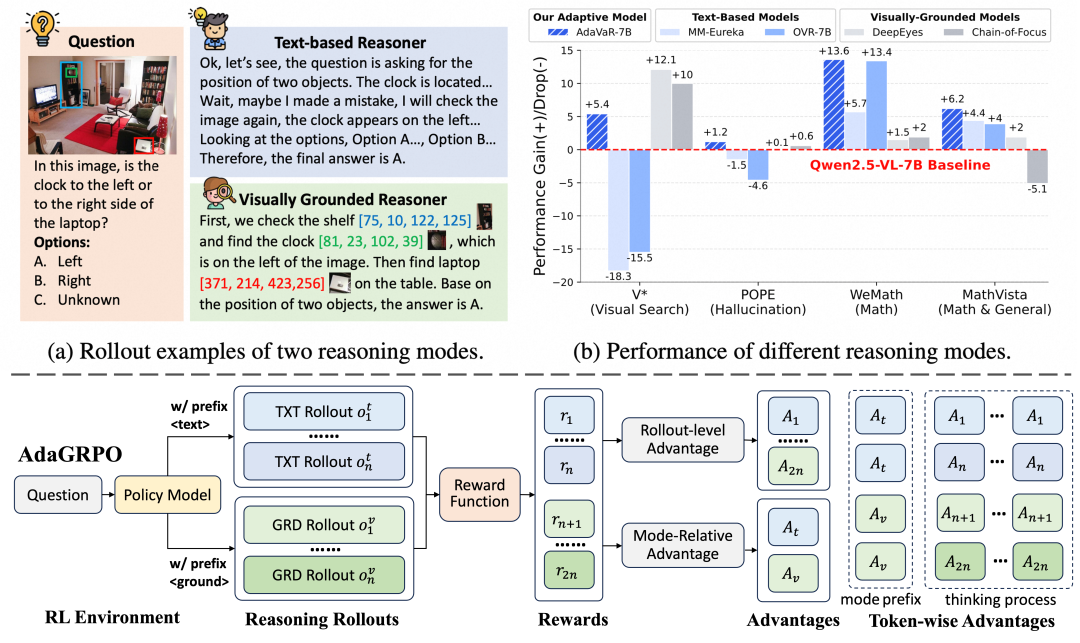
摘要:目前的视觉推理方法主要聚焦于探索特定的推理模式。虽然这些方法在特定领域能取得一定的提升,但难以培养出通用的推理能力。受此启发,我们提出了一种新颖的自适应推理范式——Mixture-of-Visual-Thoughts,简称 MoVT。该范式将不同的推理模式统一在单个模型中,并引导模型根据上下文选择最合适的模式。为了实现这一目标,我们设计了了 AdaVaR:一个两阶段的自适应视觉推理能力学习框架。首先,在有监督的冷启动阶段,模型对不同的推理模式进行统一学习;随后,通过精心设计的 AdaGRPO 算法进行强化学习,从而诱导出模型的模式选择能力。广泛的实验结果表明,AdaVaR 能够有效地引导模型学习并区分多种推理模式,并实现基于上下文的自适应模式选择。该方法在各种场景下均取得了一致性的性能提升,凸显了 MoVT 方案在构建通用视觉推理模型方面的有效性。
Not All Models Suit Expert Offloading: On Local Routing Consistency of Mixture-of-Expert Models
作者:梁敬聪,王思远,田米忍,李一同,唐都钰,魏忠钰
类别:主会长文
合作单位:南加州大学、华为技术有限公司
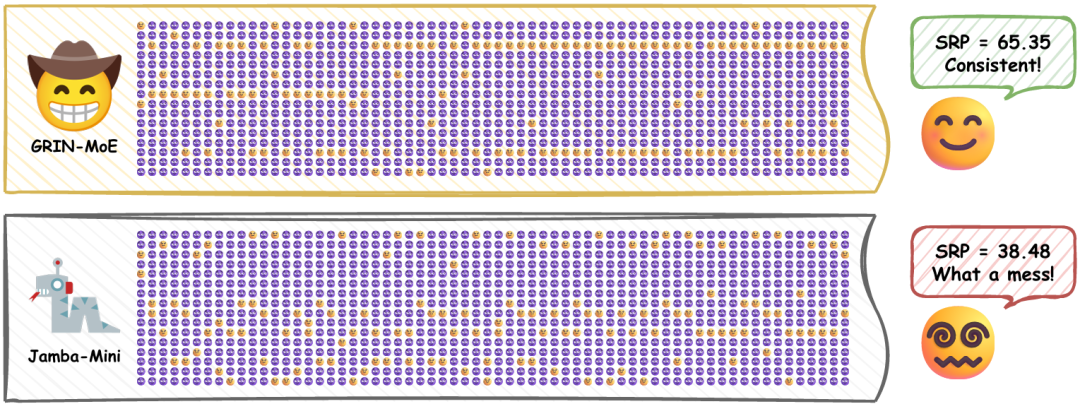
摘要:专家混合模型(Mixture-of-Experts, MoE)通过在推理过程中采用稀疏激活的专家组,实现了大语言模型(LLM)的高效扩展。为在内存受限设备上有效部署大型MoE模型,许多系统引入专家卸载机制:将部分专家缓存至高速内存,其余专家保留在低速内存中,由CPU运行或按需加载。尽管已有研究利用专家激活的局部性(即连续token激活相似专家),但这种局部路由一致性的程度在不同模型中存在差异且尚未深入研究。本文提出两项衡量MoE模型局部路由一致性的指标:(1)分段路由最佳性能(SRP),评估固定专家组覆盖特定token段需求的能力;(2)分段缓存最佳命中率(SCH),衡量专家缓存利用未来信息长度在缓存限制下的命中率。我们分析了20种不同规模和架构的MoE大型语言模型,并通过简化模型验证了影响局部路由一致性的关键因素。研究发现局部路由一致性与局部负载平衡存在显著权衡关系,同时证明全局负载平衡可与局部路由一致性共存。同时发现共享专家等设置会缩减专家组合空间,导致局部路由一致性下降。我们进一步揭示:领域特化专家对路由一致性的贡献大于词汇特化专家,且x通过将缓存规模设定为活跃专家数量的两倍左右,可以在多数模型上实现缓存效能与效率的平衡。这些发现为在不牺牲推理速度的前提下,设计部署内存高效的MoE模型铺平了道路。
HardcoreLogic: Challenging Large Reasoning Models with Long-tail Logic Puzzle Games
作者:梁敬聪,万石君,吴学海,李一同,陈强龙,唐都钰,王思远,魏忠钰
类别:主会长文
合作单位:南加州大学、华为技术有限公司
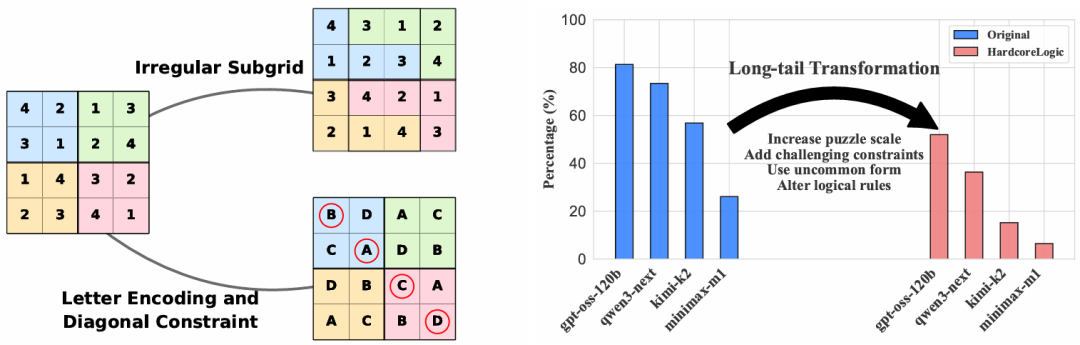
摘要:大型推理模型(Large Reasoning Model, LRM)在复杂任务中展现出卓越性能,包括需要推导出满足所有约束条件的解决方案的逻辑解谜游戏。然而,它们能否灵活地将适当规则应用于不同条件——尤其在面对非标准游戏变体时——仍是一个悬而未决的问题。现有数据集聚焦于9x9数独等流行谜题,存在过度拟合经典格式及死记解题模式的风险,这可能掩盖模型在理解新规则或适应变体策略方面的缺陷。为此我们推出HardcoreLogic——涵盖10款游戏、逾5000道谜题的挑战性基准测试,旨在检验LRMs在“长尾”逻辑游戏中的稳健性。HardcoreLogic通过三大维度系统性改造经典谜题:复杂度提升(IC)、非常规元素(UE)及不可解谜题(UP),从而降低对捷径记忆的依赖。对多个主流推理模型的评估显示,即使在现有基准测试中表现优异的模型也出现显著性能下降,表明其高度依赖记忆化的刻板模式。尽管复杂度提升是主要难点来源,模型在应对规则细微变异时同样表现吃力——这些变异未必增加谜题难度。我们对可解与不可解谜题的系统性错误分析,进一步凸显了模型真实推理能力的缺口。总体而言,HardcoreLogic揭示了当前LRM的局限性,并为提升高级逻辑推理能力建立了基准测试标准。
\ | /
★
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学袁天凡、慧敏校园C栋
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢