

论文地址:
https://arxiv.org/abs/2505.16056
Github地址:
https://github.com/ljcleo/moe-lrc
引言
混合专家模型(MoE)已经成为大语言模型扩展的主流架构——通过稀疏激活专家,模型可以在保持计算效率的同时大幅扩展参数量。然而,一个巨大的挑战在于,完整的MoE模型需要将所有专家加载到内存中,这在手机等内存受限设备上几乎不可能实现。为此,专家卸载(Expert Offloading) 技术应运而生:将部分专家缓存在快速内存(GPU)中,其余放在慢速内存(CPU/磁盘)上按需加载。
理想情况下,如果连续token总是激活相似的专家,缓存命中率就会很高,推理速度也不会受到影响。 然而,并非所有MoE模型都表现出这种"连续路由模式",而且这种特性的程度在不同模型间差异巨大。
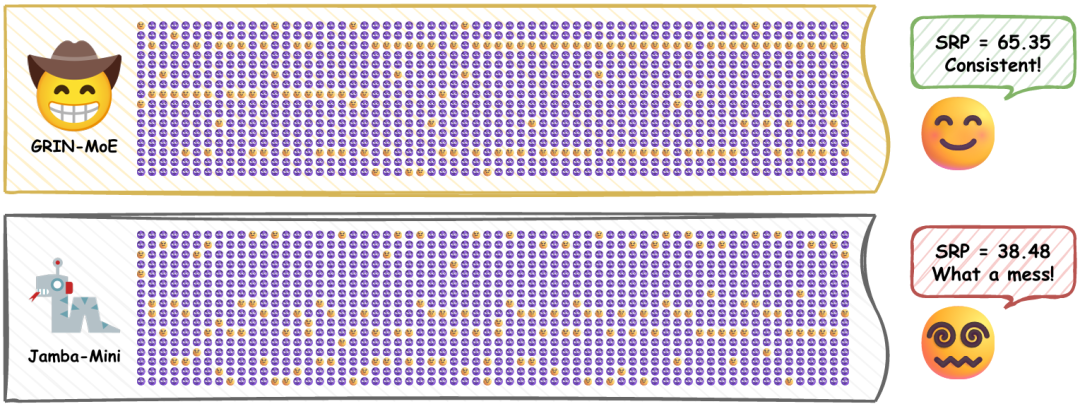
图:GRIN-MoE和Jamba-Mini-1.6在相同Java代码输入下的路由结果。尽管模型规模相近,GRIN-MoE展现出更连续的路由模式,更适合专家缓存。
为了深入探究局部路由一致性的程度在不同模型中的差异及其规律,来自复旦大学、上海创智学院、南加州大学和华为技术有限公司的学者提出了两项衡量MoE模型局部路由一致性的指标。两项指标分别面向细粒度的专家分析以及实际的缓存工作机制,并且在模型实验中高度一致。在不同规模和架构的MoE大型语言模型上的观察实验表明,存在一些影响局部路由一致性的关键因素,它们与模型的架构设计和训练方法密切相关,并且反映在专家的特化模式上;这些因素通过简化模型上的训练实验得到了进一步验证。上述发现为在不牺牲推理速度的前提下,设计部署内存高效的MoE模型铺平了道路。
本论文已经被ICLR 2026接收为主会长文。
两大评估指标:SRP 和 SCH
我们提出了两个量化指标来评估MoE模型的局部路由一致性(Local Routing Consistency):
SRP (Segment Routing Best Performance)
SRP衡量一个简化的"段级路由"能在多大程度上模拟原始token级路由的行为:
核心思想:如果局部路由一致性高,那么为一整段token固定选择一组专家就能覆盖大部分需求;
计算方式:使用F1分数评估段级路由与原路由的相似度;
优势:无需额外参数(除段长度外),可进行细粒度分析。
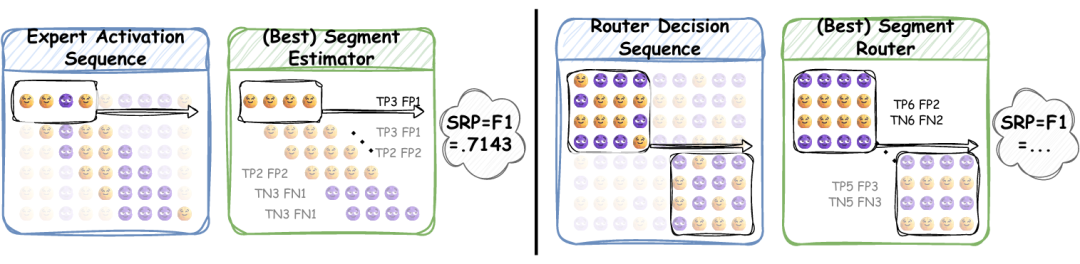
图:SRP计算示意图。左图展示单个专家的SRP计算,右图展示专家组的SRP计算。
SCH (Segment Cache Best Hit Rate)
SCH更贴近实际专家卸载场景,衡量在缓存大小限制下的最佳命中率:
核心思想:模拟一个"先知缓存",根据未来m个token的激活频率决定淘汰哪些专家;
计算方式:缓存命中率(hit rate);
优势:与实际缓存算法(LRU、LFU)高度相关,可直接指导系统设计。
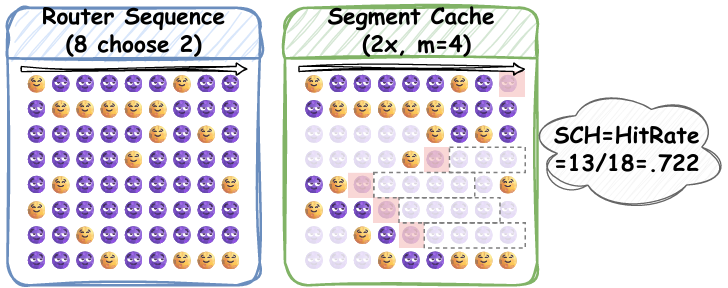
图:SCH计算示意图。红色阴影表示被淘汰的专家,灰色虚线框表示未来m个token的窗口。
观察实验:开源MoE模型大比拼
我们测试了20个开源MoE模型,参数量从3B到54B不等,涵盖主流架构(包括SwitchTransformers、Mixtral、DeepSeek-V2、Qwen3等)。测试基于11个不同领域的语料集的路由结果,包括通用语料、专业文本和下游任务输出等不同场景。
除上述开源模型外,我们还训练了一批1.4B左右参数量的简化模型,通过控制变量的方式进一步验证观察结果。
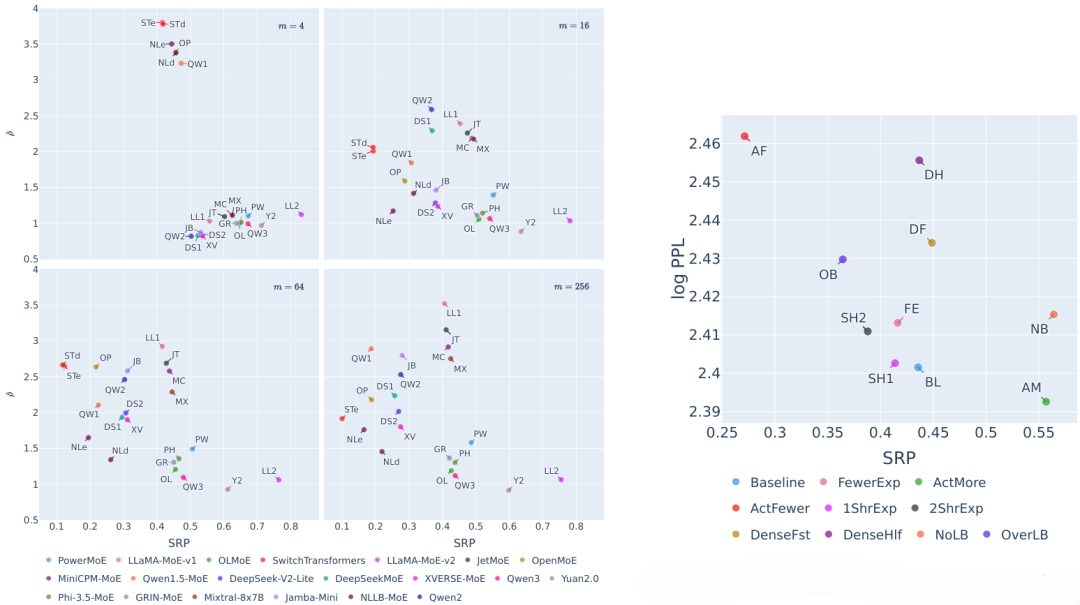
左图:开源模型在不同段长度m下的SRP(横轴)和段级路由激活比例
(纵轴,即段级路由相比原路由激活专家的倍数);右图:简化模型在m=16时的SRP(横轴)和平均困惑度对数(纵轴)。
根据SRP(段长度m=16)的表现,我们可以大致将实验的开源模型分为四组:
LLaMA-MoE-v2、PowerMoE、Qwen3、Phi-3.5-MoE和OLMoE等模型具有最强的长期局部路由一致性,段级路由激活比例约为1.25;
Mixtral-8x7B、MiniCPM-MoE、JetMoE和LLaMA-MoE-v1等模型拥有次高的SRP,但长期段级路由激活比例升至2.5左右;
XVERSE-MoE、Jamba-Mini、DeepSeek-V2-Lite、DeepSeekMoE和Qwen2等模型的SRP中等偏低,段级路由激活比例则略低,约为2.0;
NLLB-MoE、Qwen1.5-MoE、OpenMoE和SwitchTransformers等模型的SRP最低,短期段级路由激活比例已很高。
关键发现:什么影响了路由一致性?
发现1:负载均衡的权衡
一个很自然的观察结果是,高局部路由一致性往往意味着低局部负载均衡——这是一个此消彼长的关系。我们通过简化模型验证了这一点:无负载均衡损失时,训练后模型SRP高达56.42,但专家激活频率标准差高达13.21;而在过强的负载均衡下,模型SRP仅36.42,但专家激活非常均匀。
然而,观察实验进一步表明:Qwen3、GRIN-MoE、Phi-3.5-MoE、OLMoE等模型同时实现了高SRP和中等负载均衡。这说明它们具有良好的全局负载均衡——虽然单个查询只激活部分专家,但不同主题的查询会激活不同的专家组,最终覆盖所有专家。
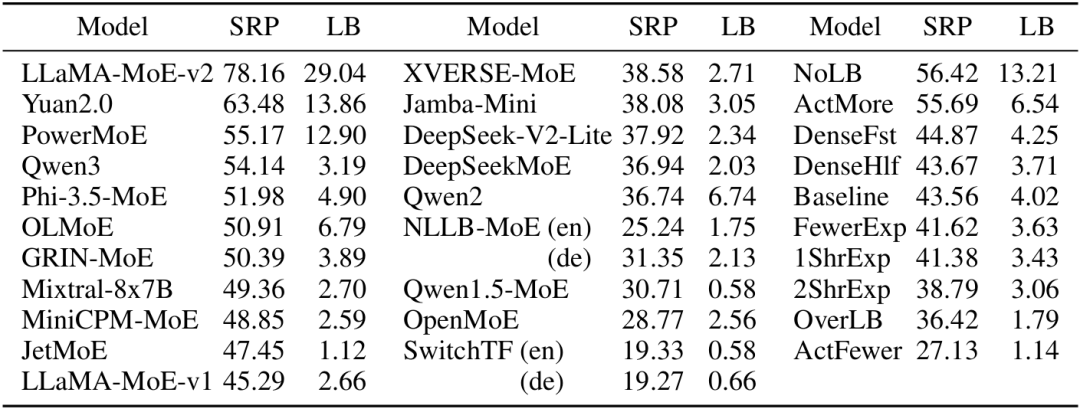
表:SRP和负载均衡(各个专家激活频率的标准差)的比较结果。
发现2:共享专家是"罪魁祸首"
无论是观察实验还是在简化模型上的验证实验都表明,共享专家(Shared Experts)会显著降低局部路由一致性:
所有SRP较高的模型都没有使用共享专家;
简化模型实验显示:1个共享专家使SRP从43.56降至41.38,2个共享专家进一步降至38.79。
我们认为以下两个潜在原因导致了这一现象:
旁路效应:更多信息通过共享专家处理,真正的MoE部分变得不那么重要;
组合空间缩小:在总专家数量固定的前提下,共享专家减少了可选专家和激活专家的数量,限制了路由调整的可能性。
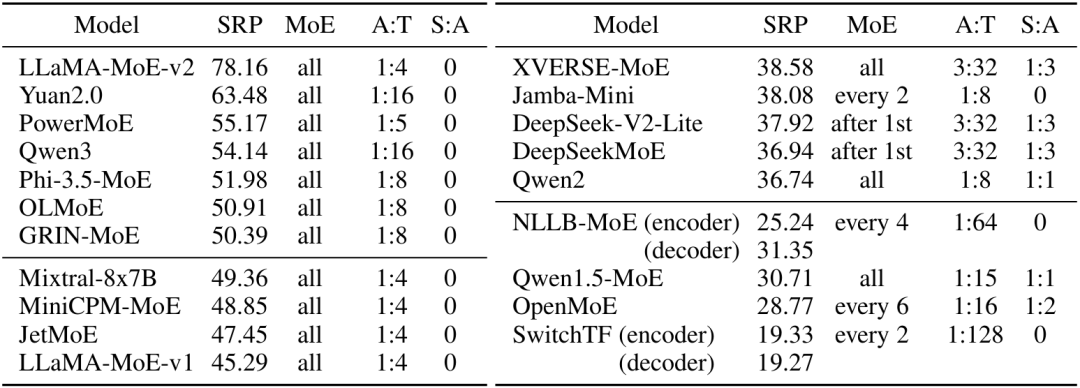
表:开源模型的SRP和部分模型架构参数(MoE层分布、专家激活比例、共享专家与激活专家之比)。
发现3:专家组合空间越大越好
如上所述,将部分专家划分为共享专家会缩小专家的组合空间;在此基础上,我们进一步检查了其它可能影响专家组合空间的因素。
简化模型实验表明,减少总专家数(增大粒度)会降低SRP,而激活专家的数量则与SRP同步增减,亦即更多的专家组合有利于局部路由一致性;相比之下,在MoE层之间插入非MoE层的影响则小得多。在现有模型上的观察实验也部分支持上述发现。
发现4:领域特化专家>词汇特化专家
我们首先考察了SRP与语料所属领域的关系,发现了以下几种模式:
Qwen3, Phi-3.5-MoE, GRIN-MoE, OLMoE 等在ArXiv、StackExchange、GitHub等技术领域表现出显著更高的SRP(比全局SRP高10%以上);
LLaMA-MoE-v2, Yuan2.0, Qwen3等在Wikipedia等通用领域SRP更高;
Mixtral-8x7B, MiniCPM-MoE, JetMoE等在各领域SRP差异不大。
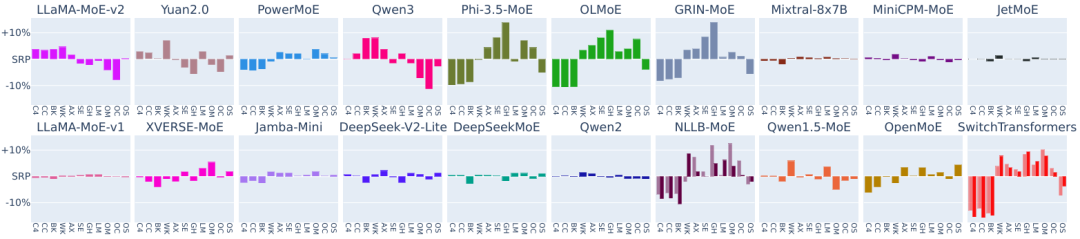
图:开源模型在不同领域的SRP相对全局SRP的差异。从左到右:C4、CommonCrawl、Books、Wikipedia、ArXiv、StackExchange、GitHub、LMArena、OpenMath、OpenCode、OpenScience。
我们进一步发现,领域特化(Domain Specialization)与SRP呈强正相关,而词汇特化(Vocabulary Specialization)的影响较小;此外,拥有较多领域特化专家的模型,如Qwen3、Phi-3.5-MoE、GRIN-MoE和OLMoE,也都较好地实现了(全局)负载均衡。我们认为这是由于领域特化专家在特定主题下会被持续激活(高局部路由一致性),但在不相关主题下会失活(实现全局负载均衡)。
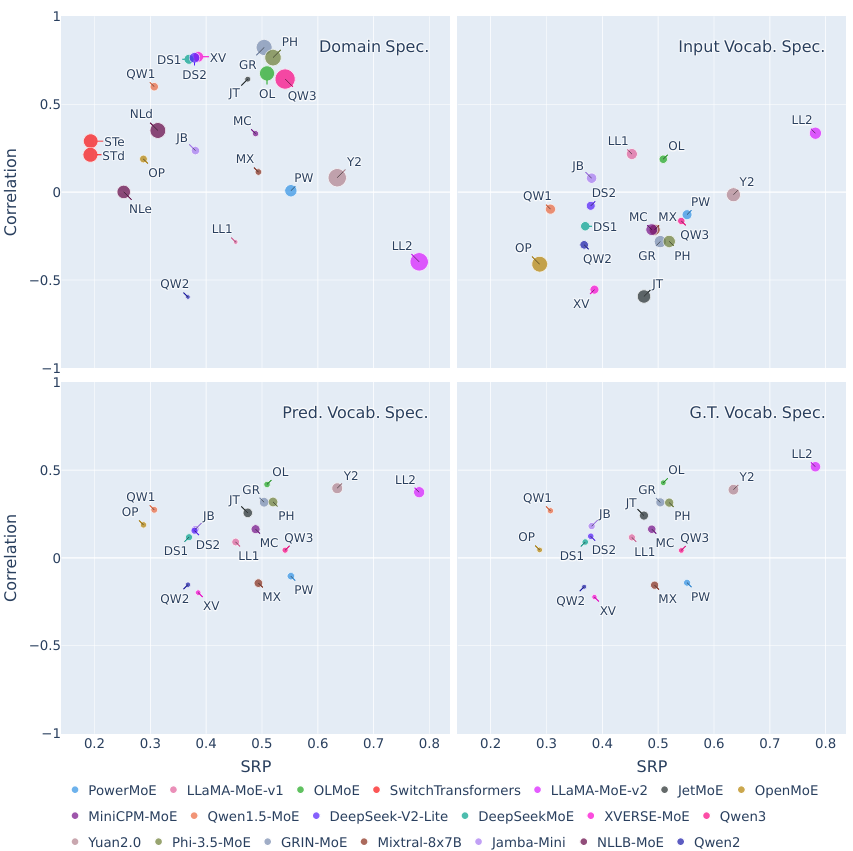
图:开源模型的SRP(横轴)、专家特化程度(圆点半径)及二者的相关系数(纵轴)。
基于SCH的实验
与SRP相比,基于SCH的分析更贴近于真实的专家卸载场景。在SCH上的实验结果给出了以下经验结论:
缓存大小建议:2x法则
我们首先比较了不同段长度m下,各个MoE模型的SCH随缓存比ρ的变化情况。实验结果显示,对于中等以上(16或更高)的段长度,除了SCH最高的模型(同时也是SRP最高的模型)在ρ=2附近出现明显转折点外,其它模型的SCH大致随缓存的扩增线性增加。因此我们认为,当缓存大小为活跃专家数量的2倍(ρ=2)左右时,专家卸载能在效果与效率之间取得良好的平衡。
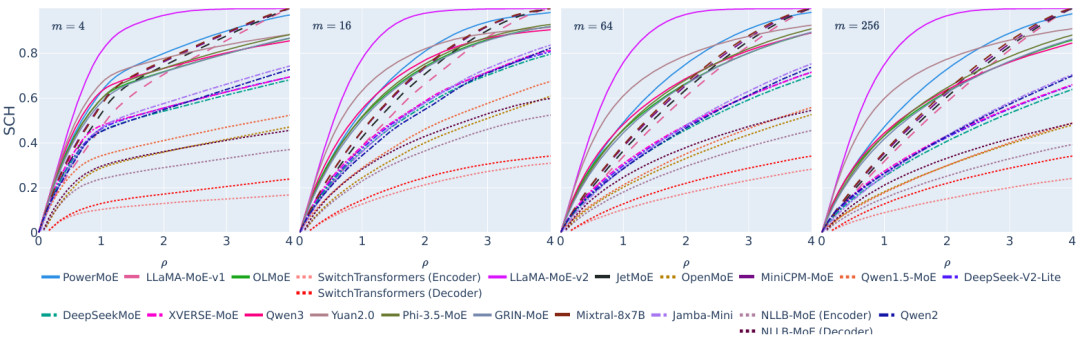
图:不同段长度m下SCH随缓存比ρ的变化。
理想缓存算法的可行替代
我们进一步比较了SCH所用算法和常用缓存算法(LRU、LFU)的命中率,以及理论最优缓存命中率之间的关系。结果表明,SCH与多种常用缓存算法的命中率高度相关,并且普遍更接近理论最优缓存命中率。考虑到理论最优缓存算法实际上几乎无法实现,我们认为SCH能够作为理想缓存算法的可行替代,帮助逼近专家卸载系统的性能上界。

左表:SCH与常用缓存算法的命中率相关系数(Fixed 为固定缓存专家);右表:不同缓存比下的缓存算法的相对命中率(理论最优命中率归一化为100)。
总结
本研究首次系统性地量化了MoE模型的“局部路由一致性”这一关键属性,表明不是所有MoE模型都适合专家卸载。
基于上述实验发现,我们为MoE模型设计和部署提供了以下建议:
优化负载均衡策略:追求全局负载均衡而非局部负载均衡;
慎用共享专家:如果计划支持专家卸载,避免或减少共享专家的使用;
扩大专家组合空间:在可行范围内增加专家数量和激活数量;
培养领域专业化专家:通过预训练数据分布引导专家专业化;
缓存大小设为2x:将缓存大小设为活跃专家数量的2倍,平衡效果与效率。
这些发现为内存受限设备上高效部署MoE模型提供了重要指导,也为未来MoE架构设计指明了方向。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区袁天凡、慧敏校园C栋

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢