
转载自微信公众号:MindDance
在通往通用人工智能(AGI)的道路上,多模态学习无疑是核心战场。然而,当前主流的多模态大模型(LMMs)大多依赖于复杂的组合式架构(如视觉编码器+大语言模型)或强大的扩散模型,这不仅带来了高昂的训练成本,也使得架构本身难以统一。昨日,一篇发表于《Nature》的重磅研究,由北京智源人工智能研究院(BAAI)主导,联合清华大学、北京大学等机构共同推出 Emu3 系列模型。该研究提出了一个极具颠覆性的统一多模态学习框架,其核心在于:仅通过“预测下一个 Token”这一单一目标,便可实现跨模态的卓越理解与生成能力。Emu3 不仅在图像生成、视觉理解和视频生成等多个基准上超越了现有模型,更将这一框架成功扩展至机器人操控领域,为构建物理世界中的具身智能体(Embodied AI)提供了全新的可能性。

多模态学习的 组合 与 扩散 之困
自 AlexNet 以来,深度学习通过端到端的方式取代了繁琐的手工特征工程。然而,在多模态领域,这种“端到端”的简洁哲学似乎遇到了瓶颈。当前,多模态大模型主要由两大技术路线主导:
组合式架构:以 LLaVA 为代表,这类模型通常将一个预训练的视觉编码器(如 CLIP)与一个大语言模型(LLM)进行“粘合”。虽然这种方法在视觉-语言理解任务上取得了巨大成功,但其本质上是两个独立训练模块的拼接,存在模态对齐困难、架构冗余以及难以从头进行联合优化等问题。
扩散模型:以 Sora、Stable Diffusion 为代表,扩散模型在图像和视频生成领域展现了惊人的能力。然而,它们通常需要与 LLM 结合才能实现复杂的文本-图像/视频对齐,并且其迭代去噪的生成过程与 LLM 的自回归推理过程存在本质差异,导致系统复杂且难以统一。
这些主流方法虽然强大,但其复杂的架构和多样的训练目标,使得构建一个能够同时处理感知和生成任务的统一多模态模型变得异常困难。这引出了一个根本性的问题:我们能否像 GPT-3/4 在自然语言处理领域那样,仅用一个单一、简洁的“预测下一个 Token”目标来统一多模态学习?
Emu3 的大道至简
Emu3 团队给出了肯定的答案。他们提出的框架摒弃了复杂的视觉编码器和扩散模型,回归到 Transformer 最核心的自回归预测机制。
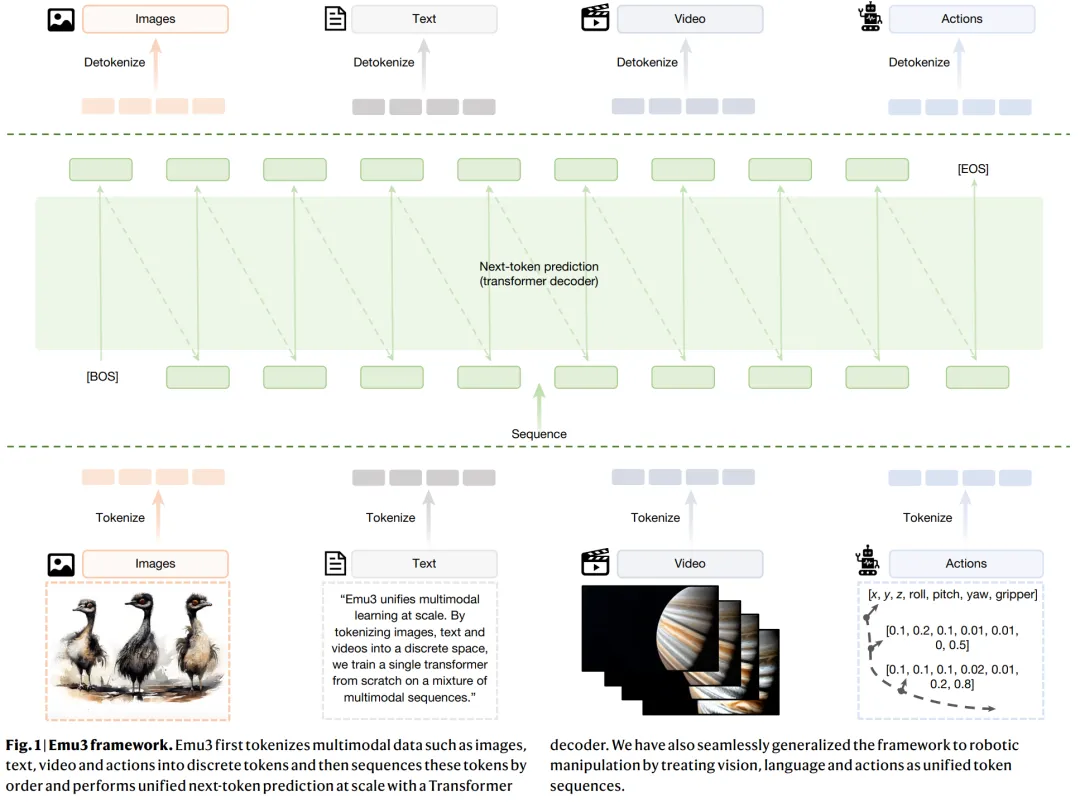
其核心方法可以概括为以下三步:
统一的多模态 Tokenizer: 这是实现统一预测的关键。Emu3 设计了一个强大的视觉 Tokenizer,能够将图像(512×512)和视频片段(540×960)都高效地压缩成离散的视觉 Token 序列。这个 Tokenizer 基于 SBER-MoVQGAN 架构,并创新性地加入了 3D 卷积核,使其能够同时处理时空信息。最终,无论是文本、图像还是视频,都被转换成同一词汇表空间中的离散 Token,为后续的统一建模奠定了基础。
纯解码器Transformer 架构: Emu3 的主体是一个标准的 Decoder-only Transformer,其架构与 Llama-2 等主流 LLM 高度相似。与组合式模型不同,Emu3 没有独立的视觉编码器。所有的多模态数据(文本 Token、视觉 Token、动作 Token)都被平等地输入到这个单一的 Transformer 中,模型只需从左到右依次预测下一个 Token 即可。
三阶段训练策略:
预训练(Pre-training):在大规模的混合多模态数据上进行基础的“下一个 Token 预测”训练。 质量微调(Quality Fine-Tuning, QFT):使用高质量的数据对模型进行微调,提升输出的视觉质量和文本对齐精度。 直接偏好优化(Direct Preference Optimization, DPO):利用人类偏好数据对模型进行对齐,使其生成的内容更符合人类审美和指令意图。
通过这种方式,Emu3 将多模态理解(如看图说话)和多模态生成(如文生图、文生视频)统一到了同一个自回归预测任务中,实现了前所未有的架构简洁性。
结果:全面超越与惊人扩展
Emu3 在多个主流基准测试中展现了卓越的性能,其结果不仅具有竞争力,更在某些方面超越了现有的最佳模型。
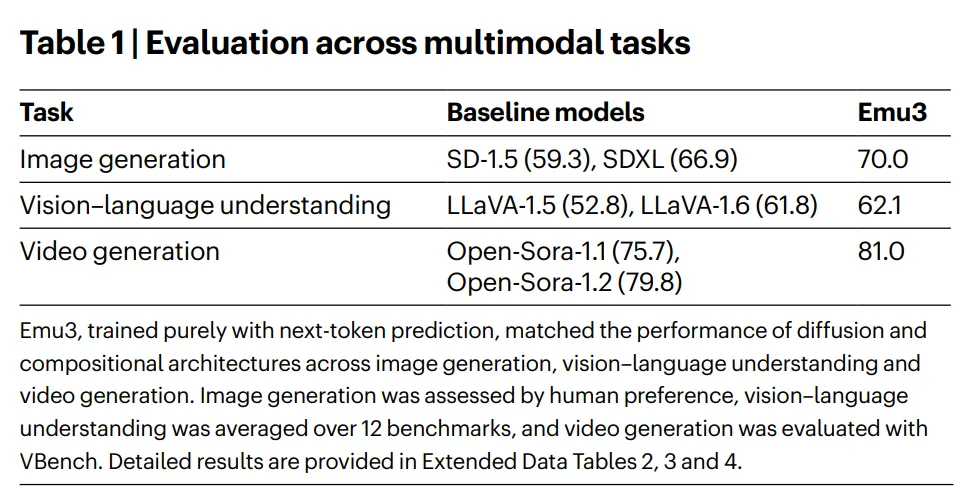

除了在标准基准上取得高分,Emu3 还展示了几个关键的特性:
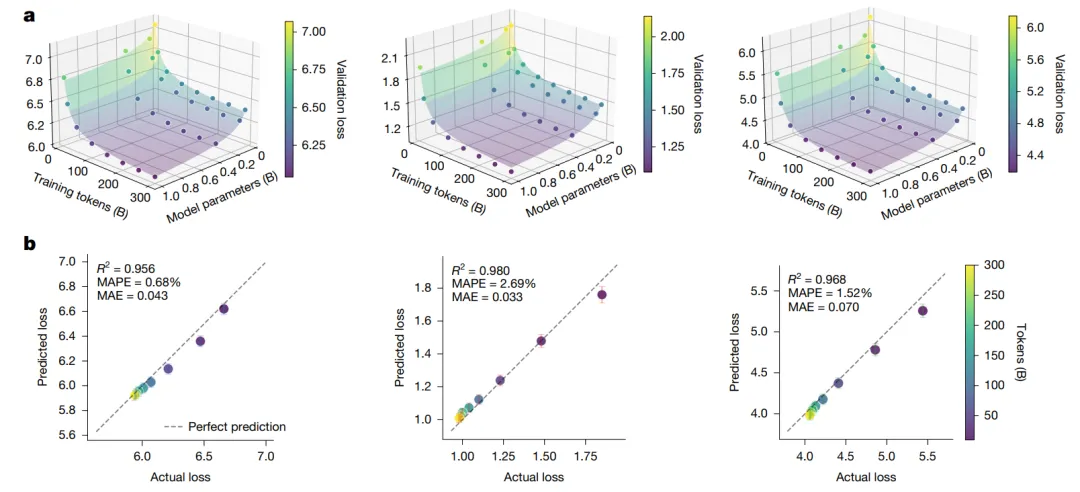
清晰的缩放定律: 研究团队发现,Emu3 的性能随着模型大小和训练数据量的增加,呈现出非常清晰且可预测的幂律缩放行为。这意味着 Emu3 的架构是稳健且可扩展的,其性能提升路径是明确的,这对于进行大规模、高投入的 AI 模型研发至关重要。
对机器人操控的扩展: 最令人兴奋的成果之一是 Emu3 在具身智能领域的应用。研究团队将机器人的动作也进行 Tokenize,并与视觉和语言 Token 一起输入模型进行训练。结果表明,Emu3 能够在 CALVIN 机器人操控基准上,实现与专门设计的视觉-语言-动作模型相媲美的性能。这证明了“预测下一个 Token”这一范式,有潜力统一感知、推理和行动,是通往通用具身智能的一条极具前景的路径。
深层剖析与洞察:Emu3 带来的范式革命
Emu3 的价值远不止于其在各项指标上的领先,其背后蕴含的方法论创新,可能预示着多模态学习领域的一场深刻的范式革命。
“下一个 Token 预测”的大一统: GPT 系列模型在自然语言处理领域的成功,根植于其next-token prediction这一极其简洁而强大的目标函数。Emu3 首次将这种“大道至简”的哲学成功地推广到了包含图像和视频的复杂多模态领域。它证明了,我们或许不需要为不同任务、不同模态设计复杂的独立模块和目标函数,一个统一的自回归预测框架就足以涌现出强大的多模态智能。这标志着多模态学习从组件时代迈向了统一时代。
对编码器-解码器架构的挑战: 长期以来,一个普遍的假设是:对于多模态任务,一个强大的、预训练的视觉编码器(如 CLIP)是必不可少的。Emu3 的一项关键消融实验颠覆了这一认知。研究发现,当从头开始训练时,一个Decoder-only架构的性能,完全不亚于甚至优于一个精心设计的视觉编码器+语言解码器架构。
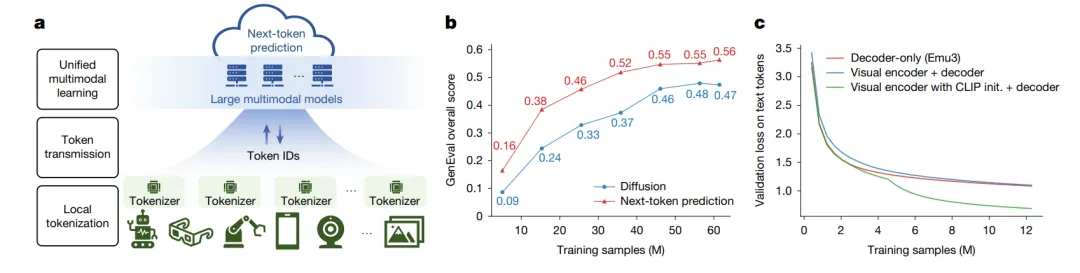
这有力地表明,在足够大的数据和模型规模下,一个统一的 Transformer 模型完全有能力自主学习跨模态的对齐,而无需依赖于预先分离的编码器模块。这为未来 LMM 的架构设计提供了全新的思路。
自回归 vs. 扩散:视频生成的另一条路: 在 Sora 引领的视频生成浪潮中,扩散模型似乎已成为不二之选。Emu3 则展示了另一条截然不同的技术路径:纯粹的自回归生成。它像写小说一样,一个 Token 一个 Token 地“画”出视频的下一帧。虽然在推理效率上可能不及并行性更好的扩散模型,但其优势在于架构的统一性和与 LLM 的天然一致性。Emu3 的成功证明,在视频生成领域,扩散模型并非唯一的答案,自回归模型同样拥有巨大的潜力。
局限与启示
尽管 Emu3 取得了突破性进展,但研究团队也坦诚地指出了其当前的局限性,并为未来指明了方向。
局限性:
推理效率:朴素的自回归解码过程是串行的,这限制了生成速度。未来可以探索并行解码等技术来加速推理。 Tokenizer 的权衡:当前的视觉 Tokenizer 在压缩率和重建保真度之间存在权衡。更高质量的 Tokenizer 将是提升生成效果的关键。 长视频与复杂场景:对于超长视频和以视频为中心的复杂场景,模型的生成质量和多样性仍有待提升。
启示:
Emu3 的研究为通往 AGI 的道路提供了极其重要的启示:统一是关键。一个简洁、可扩展、且遵循清晰缩放定律的统一框架,远比一堆复杂组件的拼接更具潜力。Emu3 证明了,通过将世界万物(文本、图像、视频、声音、动作)都表示为离散的 Token,并用一个强大的 Transformer 进行自回归预测,我们或许真的能够构建出理解并与物理世界互动的通用智能体。
Emu3 的工作令人振奋,它在多模态领域重现了 GPT-3 在 NLP 领域带来的那种统一之美。尤其值得关注的是其在机器人操控上的成功应用。这表明,这种统一的 Token 序列预测范式,不仅能处理抽象的互联网数据,更有潜力成为连接数字世界与物理世界的桥梁。在药物发现领域,这意味着我们可以想象一个能够阅读文献(文本)、分析分子结构图(图像)、观察实验过程(视频)并最终自主操作实验设备(动作)的 AI 科学家。Emu3 为这种终极设想提供了一条清晰且可行的技术路径。
参考文献: Wang, X., Cui, Y., Wang, J. et al. Multimodal learning with next-token prediction for large multimodal models. Nature (2026). https://doi.org/10.1038/s41586-025-10041-x
代码链接:
https://github.com/baaivision/Emu3
https://huggingface.co/collections/BAAI/emu3
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢