

报告主题:VIGA: 会用Blender引擎“思考”的Agent
报告日期:02月04日(周三)10:30-11:30
本期报告将由北京大学殷绍峰进行分享。
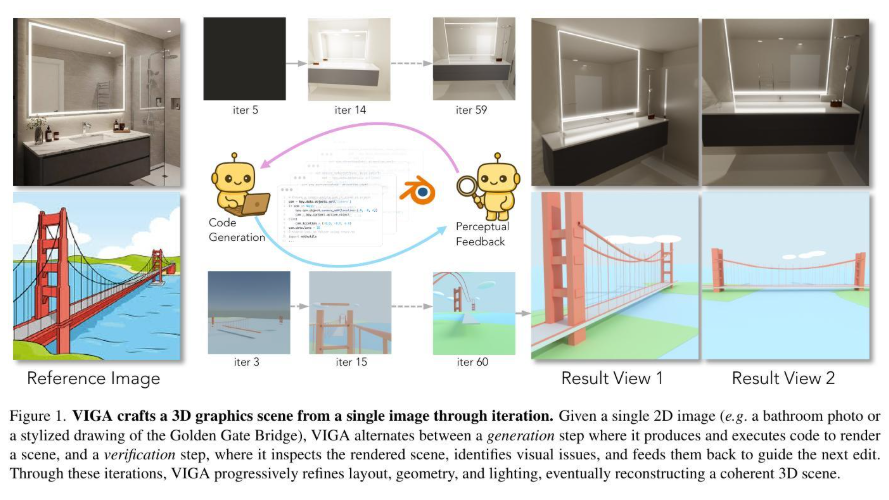
视觉即逆向图形学(Vision-as-inverse-graphics),即将图像重建为可编辑的图形程序,一直是计算机视觉领域的长期目标。然而,即使是强大的视觉-语言模型(VLM)也无法一次性实现这一目标,因为它们缺乏精细的空间和物理感知能力。我们认为,弥合这一差距需要通过迭代执行生成-验证交错的多模态推理。基于此,我们提出了 VIGA(视觉即逆向图形代理),它从一个空的世界开始,通过闭环的编码-运行-渲染-比较-修改过程来重建或编辑场景。为了支持长远推理,VIGA 结合了 (i) 一个交替扮演生成器和验证器角色的,可使用外部技能库的代理,以及 (ii) 一个包含计划、代码差异和渲染历史的动态上下文记忆。 VIGA 无需辅助模块,因此不依赖于特定任务,可涵盖广泛的任务,例如 3D 重建、多步骤场景编辑、4D 物理交互和 2D 文档编辑等。实验结果表明,VIGA 在 BlenderGym (+35.32%) 和 SlideBench (+117.17%) 上的单次测试基线性能均显著提升。此外,VIGA 也无需微调,因此不依赖于特定模型,从而能够使用统一的协议来评估异构的视觉-语言模型(VLM)。为了更好地支持该协议,我们引入了 BlenderBench,这是一个具有挑战性的基准测试,它对图形引擎的交错多模态推理进行评估,VIGA 在该基准上性能提升了 124.70%。
殷绍峰,北京大学智能科学与技术专业实验班(“智班”)大四本科生,曾前往加州大学伯克利分校(UCB)交换一学期。目前研究重点为多模态代理(Agent)系统。曾获国家奖学金,商汤奖学金,北京大学三好学生等荣誉。



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢