

OpenClaw (原名 Clawdbot)爆火。
对于个人极客来说,OpenClaw 是有趣的。但对于企业和商业环境来说,问题立刻暴露:昂贵(烧 Token)、不可控(安全边界模糊)、存在隐私问题,且难以协作。
可以说,目前的 Agent 更多还是惊艳的 Demo,不是可以规模化的产品。
Monolith 砺思资本办了一场「After the Model」技术沙龙,聊了聊:Agent 离规模化落地还有哪些难题?
在活动中,一个被反复提及的观点是:Agent 需要是一个可持续工作的系统,而非单次任务的跑通。
这意味着,光有「模型智力」是远远不够的。想跨过工程这条鸿沟,必须还要「死磕」这几个硬指标:稳定性、高吞吐量、成本控制、精确的状态管理。
以下是活动的一些核心 Insight,供从业者参考。
⬆️关注 Founder Park,最及时最干货的创业分享
Founder Park 联合扣子,举办了一场 Skill 招募大赛。如果你手里有一套在用、能交付结果的方法论,很适合来试试!

- 可落地的 Skill 搭建方法
从一个想法或一套 SOP,拆解成真正能跑起来的 Skill
- Skill 的展示与放大通道
不只是自己用,而是被更多人看到、用到
- 被看见后的实际激励
好的 Skill,有机会获得明确回报
01
教模型做事的成本太高,
不能用黄金盖平房
01
教模型做事的成本太高,
不能用黄金盖平房
01
教模型做事的成本太高,
不能用黄金盖平房
任何系统的可持续性,最终都得回归到单位经济模型(UE)。如果 Agent 创造的价值覆盖不了它消耗的成本,那么无论模型多么先进,这个系统在商业上都是不可持续的。
当前 Agent 的门槛主要存在于数据与设施上。
在 SFT(监督微调)模式下,我们依赖人类专家来教模型做事。但在 GUI Agent(让 AI 操作电脑界面)这种高门槛任务中,这种依赖变成了难以承受的负担。
为了获得高质量的 GUI 任务数据,部分从业者发现,他们需要雇佣「985 高校的高年级博士生」来进行标注,而即使是这样高水平的人力,标注一条数据也需要耗费 20 分钟。
这种高昂的时间与人力成本直接限制了数据的规模,团队最终只标注了 200 多个任务,无法进一步扩大。
简单点说,我们实际上正在用黄金盖平房——依靠堆砌专家人力来换取智能的提升,在复杂 Agent 场景下是不可持续的。
这反向逼迫行业必须转向 RL(强化学习)——让 Agent 在虚拟环境里自己试错、自我博弈,摆脱对昂贵人工数据的依赖。只有这样,才能把数据成本从"按人头算"变成"按算力算",实现边际成本的下降。
但是,RL 的门槛也不低。
传统的工业级 RL 训练往往依赖庞大的算力集群。即使是经过优化的训练流程,仍然需要 16 张显卡(8 卡采样、8 卡训练)以及大量的 CPU 资源来支撑仿真环境。
对于大多数中小企业或学术团队而言,这是一笔不菲的开销。如果无法通过 RL 实现数据的自我生成,Agent 的商业模式会被高昂的人力成本直接锁死。
破局的关键是构建高仿真环境,让 Agent 通过自主探索产生海量交互数据,再通过设计有效的奖励信号,用 RL 训练出更强的策略。
02
光速的 GPU 算力,
但被迫在龟速的操作系统上训 Agent
02
光速的 GPU 算力,
但被迫在龟速的操作系统上训 Agent
02
光速的 GPU 算力,
但被迫在龟速的操作系统上训 Agent
当前 Agent 训练面临的悖论还有:光速的 GPU 算力,配上了龟速的操作系统。
在传统的 RL 任务(比如下棋、打游戏)中,环境反馈是毫秒级的,步长短、速度快。
但在 GUI Agent 场景下,Agent 执行一个动作——比如在虚拟机里点击 Excel 按钮——需要经历"虚拟机渲染→截屏→图像回传→视觉模型处理"的漫长链路。
实际训练中,完成一个 Step 的交互甚至需要30 秒以上,令人难以忍受。
极高的延迟又进一步导致了计算资源的极度浪费——在传统的 RL 流程中,架构通常是紧耦合的。这意味着,当 GPU 在更新模型时,环境在等待;而当环境在采样数据时,GPU 又在空转。
这种时空的错配、互相阻塞导致了极低的计算利用率。
除了速度慢,环境的复杂度也呈指数级上升。
不同于文本生成,GUI Agent 面临的是一个像素级(Pixel-level)的动作空间,理论上它可以在屏幕上的任意坐标进行点击或拖拽,这使得动作空间接近无限。
这使得奖励极为稀疏。比如"将 Excel 内容打印为 PDF"这样的任务,Agent 需要连续执行几十个步骤。在这个过程中,环境往往一片死寂,不会告诉 Agent 中间某次点击是对是错,只有最后一步才能得到结果。
这种「长程视野 + 稀疏反馈 + 无限空间」的组合,构成了 Agent 所在环境的真实面貌——它是一个充满了摩擦的环境。我们不能再用训练聊天机器人的逻辑来训练 Agent。
对于创业公司而言,这意味着必须投入资源去构建仿真训练环境,这比单纯购买 H100 显卡更考验团队的技术沉淀。
03
基础设施:太重、太贵、玩不起
03
基础设施:太重、太贵、玩不起
03
基础设施:太重、太贵、玩不起
如何解决环境问题?
在现场,不同的分享者分别从横向扩展与纵向轻量化两个维度,给出了 Infra 重构的答案:解耦(Decoupling)。
横向解耦:打破采样与训练的同步锁
面对 GUI Agent 交互速度极慢的问题,有研究者提出了一种名为 Dart(Decoupled Agent RL)的框架。
其核心逻辑是将采样端与训练端在物理上彻底分开。
在这一架构下,采样端不再等待模型更新,而是利用 Kubernetes(K8s)并行启动上百个 Docker 容器作为 Environment,持续不断地生产轨迹数据。数据通过一个基于 MySQL 的轨迹管理器进行异步调度,再输送给训练端。
这种设计虽然引入了 Off-policy(数据和模型不同步)的挑战,需要通过数据筛选机制来平衡,但收益是巨大的,至少有三层:
消除了 GPU 等待环境反馈的空转时间
实现了 5.5 倍的环境利用率提升
整体训练吞吐量翻了近一倍
这也意味着,Agent 的 Infra 必须具备处理异步数据流的能力,而非传统的同步批处理,将训练过程转变成了一个持续流动的、高吞吐的流水线。
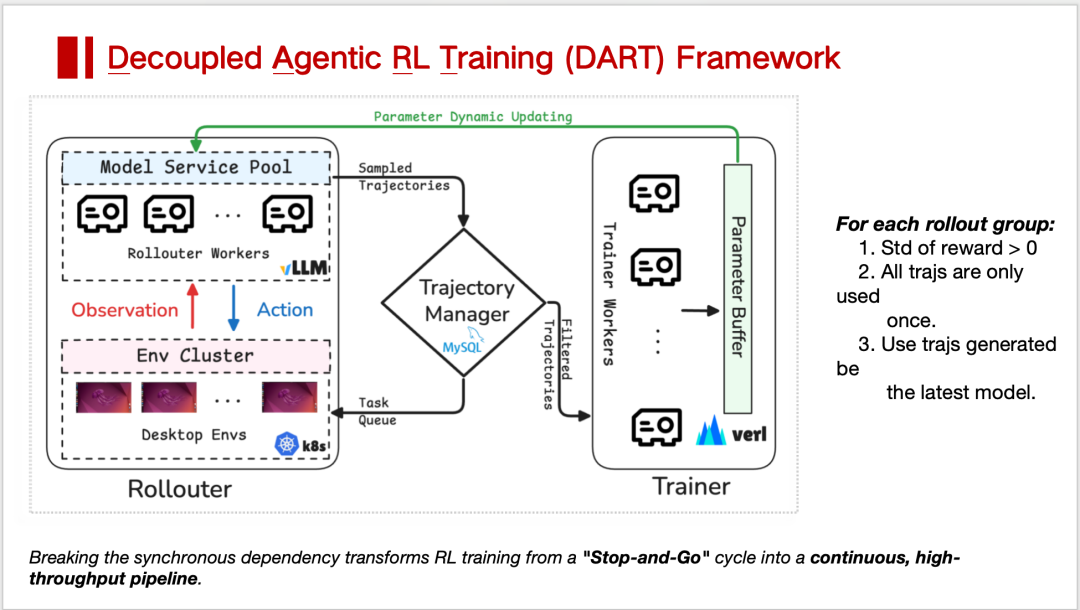
Dart 框架
纵向解耦:降低算力门槛
Infra 的另一个痛点在于「重」。
现有的工业级框架(如 Verl, OpenRLHF)往往针对大规模集群,代码量庞大且模块耦合严重,对于学术界或资源受限的初创团队而言,修改算法逻辑或适配小规模集群的门槛极高。
另一位研究者展示了轻量化的解耦思路——开发模块化框架,将算法逻辑、模型架构与分布式引擎分离。
这种 RL-Centric 的设计理念,把工程复杂度封装在模块边界内,实现了"逻辑即实现"——研究者可以像搭积木一样,通过插件化配置自由组合 GAE、GRPO、PPO 等算法组件,大幅降低了处理底层分布式的负担。
同时他们还通过 CPU Offload 技术实现了显存复用——推理采样时将训练参数卸载至 CPU,优化更新时再加载回 GPU,显著降低了硬件门槛。
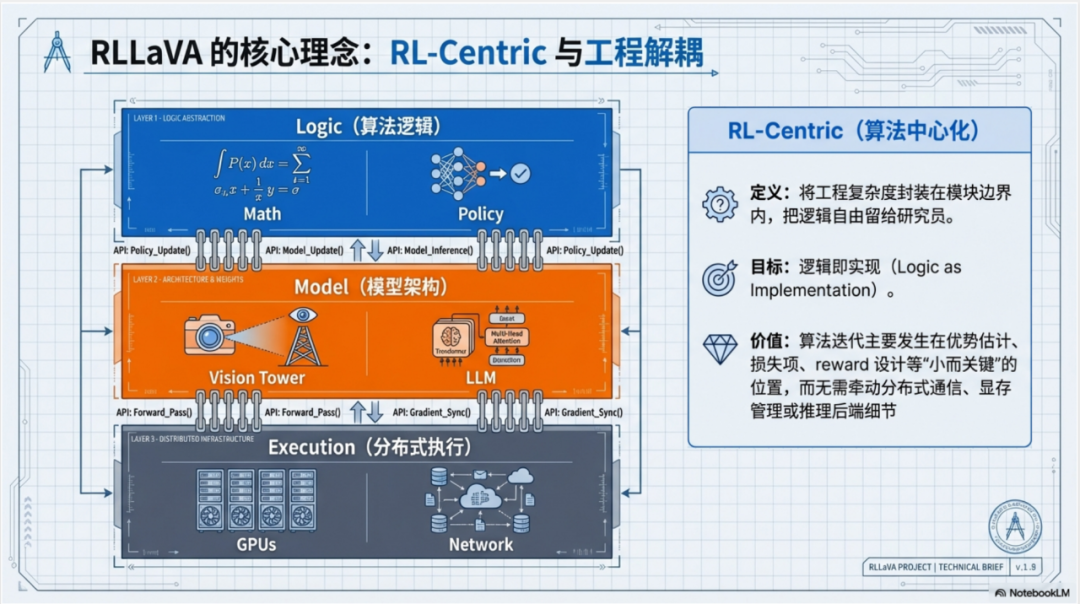
RLLaVA 框架
所有这些技术细节背后的逻辑都趋于一致:要让 AI Agent 可行,首先得把它的工位(基础设施)配齐。现有的工具太重、太贵、太慢。因此,我们需要更轻量、模块化的中间件,让中小团队也能玩得起 Agent 训练。
这也正是 Infra 领域的创业机会。
04
Long Context 并不等同于记忆
04
Long Context 并不等同于记忆
04
Long Context 并不等同于记忆
算力和环境之外,另一个问题是状态管理。
Transformer 架构虽然强大,但它缺乏可读写存储器,无法显式地存储或更新中间的推理状态,也没有循环或递归机制。
在处理简单问答时,这种无状态特性不是大问题;但在面对复杂的软件开发或长程逻辑推理时,这种缺陷是致命的。
由于缺乏对推理状态的有效管理,模型在解决复杂递归任务时,往往会出现推理链路断裂或逻辑漂移。
这些问题,相信重度使用 AI 的用户都能感受到。
学术界与工业界也正在尝试从架构底层进行修补。诸如Mamba 等 State Space Models(SSM)、Linear Attention 机制、Stack 机制,正在成为解决这一问题的热门方向。
这些新架构试图通过更高效的状态压缩与传递机制,让模型具备原生的状态推演能力,从而弥补 Transformer 在长程状态管理上的先天不足。
另一个思路是改变推理的载体。当前大多数 Agent 依赖自然语言进行思维链推理,但自然语言在精确计算和状态追踪上有局限。
一种思路是让模型学会用代码思考——代码天然具备变量、函数和逻辑流,比自然语言更适合精确的状态管理。

Code Thinking
在工程落地层面,一个常见误区是把 Long Context(长上下文)等同于"记忆"。但单纯拉长上下文窗口既不经济也不实用。
实际场景中,记忆被划分为两类:用户侧记忆和执行侧记忆。前者类似传统用户画像,记录用户偏好和基本信息,大多数 AI 客服已具备雏形。后者是 Agent 自我进化的关键——不仅要记住「用户是谁」,更要记住「我上次是如何完成任务的」,包括执行轨迹和经验教训。
当再次遇到类似任务时,Agent 应能复用成功路径或规避踩过的坑,而非从零开始。
在记忆架构上,一种思路是将其设计为file system 式的分层存储。当 Agent 需要回顾时,它执行的是读取文件的操作,而非在上下文窗口中大海捞针。
对于一个系统而言,「记忆」的本质不应该是记住所有的对话历史,而是能够像计算机一样,精确地管理每一个变量的周期与状态。
总而言之,对于企业级应用来说,客户不在乎你的上下文窗口有多长,只在乎 AI 能不能记住「我上次说过什么」以及「公司的业务规则是什么」诸如此类问题。
解决健忘问题,是 Agent 从玩具走向企业级员工的入场券。
05
护城河变了,
赢家也会变
05
护城河变了,
赢家也会变
05
护城河变了,
赢家也会变
尽管这场沙龙是一场偏向技术、工程层面的交流,但我们仍能从中提取出很多信号。
过去我们认为护城河在于模型本身,但随着开源模型能力的快速逼近,护城河正在从"单点模型能力"向"系统整合能力"扩展。
未来的赢家,不一定是模型最强的团队,而是那些能通过优秀的 Infra 架构、低成本的数据闭环和高效的记忆管理,最大化释放模型能力的团队。工程化能力正在成为新的差异化来源。
其次,我们需要注意,卖铲子的逻辑变了,Agent Infra 是被低估的洼地。
正如沙龙中所讨论到的,为了让 Agent 真正落地,我们需要全新的基础设施,不是传统的云计算,而是专门为 Agent 设计的诸如异步训练框架、解耦的采样环境和向量化记忆文件系统之类的 Agent Native Infra。
目前的 Agent 开发栈依然非常原始。这意味着,谁能为 Agent 开发者提供好用的「IDE」、「调试器」和「虚拟训练场」,谁就有机会成为 AI 2.0 时代的 Databricks 或 Snowflake。
最后,随着 GUI 等复杂场景的出现,人工标注的成本显然已不可持续。
未来的数据壁垒,不再是谁爬取了更多的互联网文本,而是谁能构建更逼真的仿真环境,让 Agent 在其中自我博弈、自我进化。这种通过 RL 产生的高质量合成数据,将是下一阶段最稀缺的资源。
我们永远处在一个不断出现噪音,排出噪音的商业环境中,Agent 的深水区才刚刚开始。


Clawdbot 如何搭建永久记忆管理系统:全靠 MD 文档
Clawdbot开发者:未来一大批应用都会消失,提示词就是新的interface
BAI、高瓴领投,ThetaWave李文轩:我们想成为下一代年轻人默认的知识获取入口
网易云音乐前 CTO 曹偲:代码越来越不重要,好的架构才是软件工程核心
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢