

AlphaFold2及其开源实现OpenFold的问世,彻底革新了蛋白质结构预测领域,为蛋白质折叠机制解析、靶向药物设计与蛋白质从头合成奠定了技术基础。然而,这类基于Transformer架构的模型长期被视为“黑箱”,其内部组件对预测精度的贡献度、组件重要性与蛋白质特性的关联等关键科学问题,始终缺乏系统性的量化分析。
近期发表于NeurIPS 2025的研究《Quantifying the Role of OpenFold Components in Protein Structure Prediction》,构建了组件级消融分析体系,精准量化了OpenFold核心模块的功能权重,并揭示了组件重要性与蛋白质长度的强相关性。该研究不仅为理解AlphaFold类模型的工作机制提供了全新视角,更为模型轻量化、性能优化与架构创新指明了方向。
OpenFold的核心计算单元为Evoformer模块,其通过48个堆叠的计算块,迭代优化两种关键表征:多序列比对(MSA)表征与残基对(Pair)表征。Evoformer内部包含MSA行列注意力、三角注意力、过渡MLP层、三角乘法更新等多个功能组件。
此前针对AlphaFold2和OpenFold的研究,多聚焦于辅助损失函数设计、训练策略优化或粗粒度的架构调整,深入到单个组件的功能解析层面很大程度上尚未探索。而随着AlphaFold3、Boltz等后续模型沿用相似的Transformer架构,解析OpenFold组件的贡献度,具有重要的跨模型迁移价值。
本研究的核心目标在于:
构建一套系统的组件级消融实验方法,量化单个模块对结构预测精度的影响。 识别对绝大多数蛋白质预测起决定性作用的核心组件。 揭示组件重要性与蛋白质长度等理化特性的关联规律。
为实现对OpenFold组件的系统性解构,研究团队设计了模型组件定位、多维度实验设计、严格数据验证三位一体的分析体系。
OpenFold的预测流程分为三个阶段:
预处理阶段:通过同源序列比对生成MSA表征,通过残基间相互作用分析生成Pair表征。
Evoformer迭代优化阶段:每个Evoformer块包含两条并行处理通路,分别优化MSA与Pair表征。其中,MSA通路包含MSA行注意力(整合同源序列的残基信息)、MSA列注意力(关联单条序列内的残基特征)与MSA过渡MLP层;Pair通路包含三角乘法更新(保障残基三元组的几何一致性)、三角注意力与Pair过渡MLP层,两条通路通过外积均值运算实现表征交互。
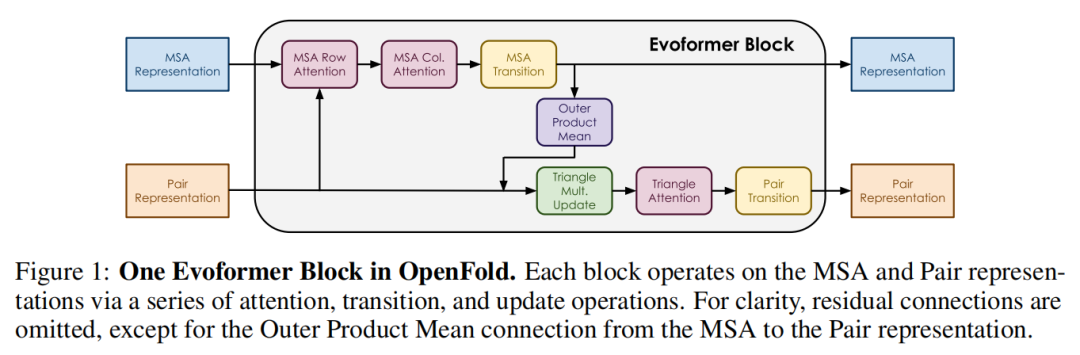
结构生成阶段:由结构模块将优化后的表征映射为3D原子坐标。
研究团队设计了三类梯度递进的实验,以全面评估组件功能:
注意力模块消融:在所有Evoformer块中跳过指定注意力层,直接通过残差连接传递特征。 非注意力模块与表征消融:跳过过渡MLP、三角乘法更新等非注意力模块,或直接将MSA/Pair表征置零后输入结构模块。 长度相关性分析:计算组件消融后模型性能变化值(ΔTM-score)与蛋白质长度的Spearman相关系数,量化两者的关联强度。
实验数据集采用CAMEO数据库子集,筛选出长度小于700个残基、基线TM-score大于0.7的154个蛋白质,确保数据质量与模型性能基线的可靠性。
评估指标选用TM-score(衡量预测结构与实验结构的相似度),通过对比基线模型与组件消融模型的TM-score差值(ΔTM),量化组件的贡献度。同时,实验重复三次取平均值,并通过线性回归与Spearman相关性分析,验证结果的统计学显著性。
研究通过系统性实验,绘制了OpenFold组件的功能权重图谱,得出三项重要性的结论。
通过对注意力组件的消融实验发现:
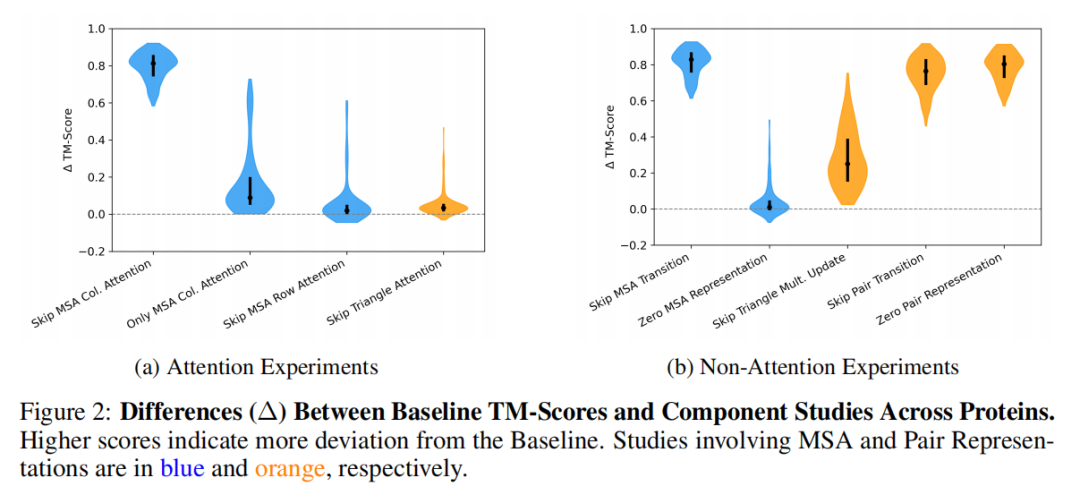
MSA列注意力是全局核心组件:跳过该模块后,绝大多数蛋白质的预测性能出现显著下降,ΔTM值的中位数达到0.089,是所有注意力组件中影响最大的模块。进一步实验表明,仅保留MSA列注意力即可使模型性能接近基线水平,这揭示了OpenFold对进化序列信息的强依赖性——同源序列的残基关联模式是结构预测的核心依据。 MSA行注意力与三角注意力的贡献具有蛋白特异性:跳过MSA行注意力对多数蛋白质的性能影响微弱,而三角注意力的消融仅对部分短蛋白质的预测精度产生显著影响。
对非注意力组件的分析则进一步验证了过渡MLP层的关键作用:
跳过MSA过渡MLP或Pair过渡MLP层后,模型性能出现断大幅下跌,ΔTM中位数分别达到0.829与0.765,这与Transformer架构中MLP层负责特征非线性变换的理论高度一致,证明其是承载关键语义信息的核心单元。 Pair表征是结构预测的直接依据:将Pair表征置零后,模型完全丧失预测能力;而MSA表征置零的影响相对有限,这说明Pair表征是连接序列特征与3D结构的关键桥梁。
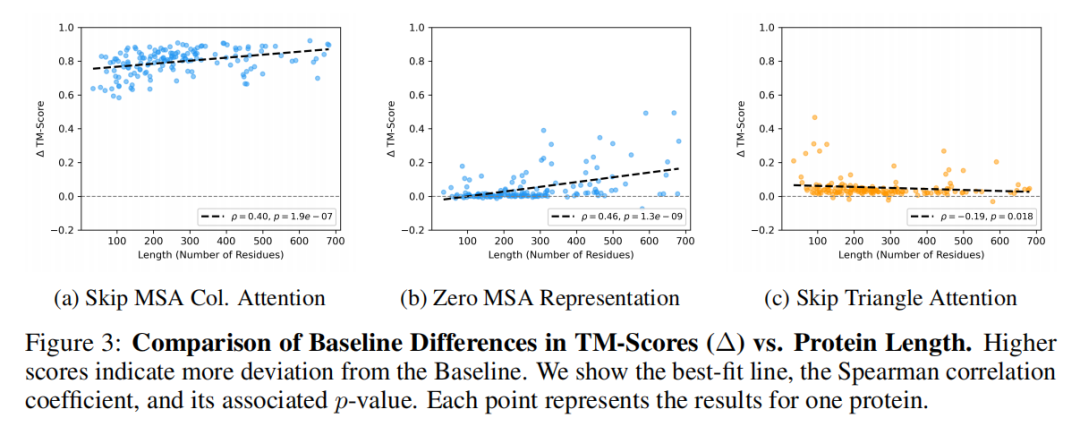
研究通过相关性分析,揭示了组件贡献度与蛋白质长度的定量关联,核心规律如下: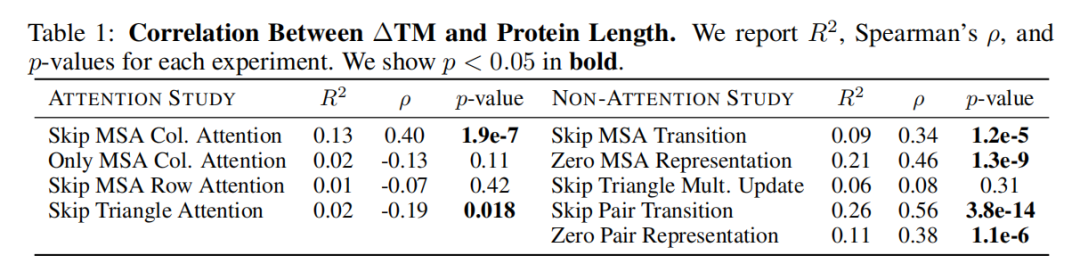
上述结果表明:
长蛋白质的预测高度依赖MSA驱动的组件:MSA列注意力、MSA/Pair过渡MLP层是长蛋白结构预测的核心,这是因为长蛋白的序列信息更复杂,需要通过MSA列注意力整合跨残基的进化关联,再由过渡MLP层实现高阶特征的提取。 短蛋白质的预测对几何约束组件更敏感:三角注意力通过保障残基三元组的三角不等式,维持短蛋白结构的几何一致性,因此对短蛋白预测的贡献度更高。 三角乘法更新的贡献度与长度无关:该组件的消融效果在不同长度的蛋白质中差异极大,说明其重要性可能与蛋白质折叠类型、残基相互作用模式等其他因素相关。
研究通过 表征置零 与 噪声替换 两组对照实验,验证了表征层级的功能权重:
置零实验:Pair表征置零导致模型性能完全崩溃,而MSA表征置零仅造成部分性能损失,证明Pair表征是结构预测的必要条件。 噪声替换实验:将MSA/Pair表征替换为服从相同均值与方差的随机噪声后,结果与置零实验高度一致——Pair表征的噪声替换引发性能暴跌,而MSA表征的噪声替换影响有限。
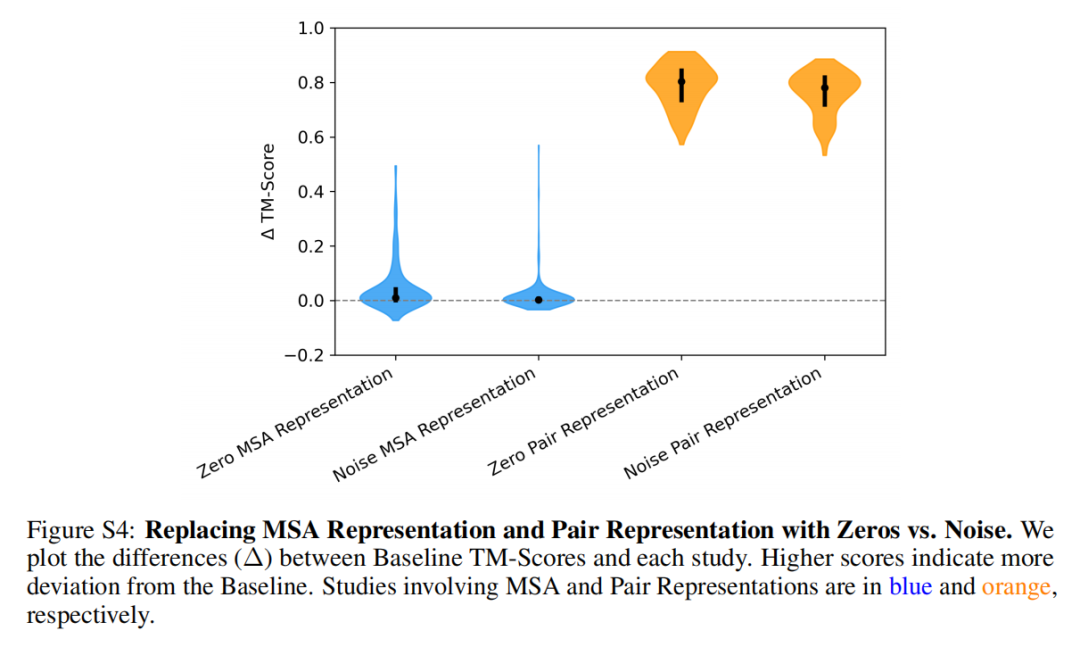
这一结果从表征层面印证了:OpenFold的预测能力本质上依赖于Pair表征中编码的残基间空间约束信息,而MSA表征的核心作用是为Pair表征的优化提供进化层面的先验知识。
理论层面:填补了AlphaFold类模型可解释性的关键空白该研究构建了组件-性能-蛋白质特性的关联图谱,明确了MSA列注意力、过渡MLP层与Pair表征是模型的核心功能单元,颠覆了 注意力机制是Transformer唯一核心 的传统认知,为理解深度学习模型在生物大分子领域的工作机制提供了范式。
应用层面:为模型优化与轻量化提供了精准靶点基于研究结论,后续可针对不同长度的蛋白质设计差异化的模型架构:
针对长蛋白质:强化MSA列注意力与过渡MLP层的计算资源配置,提升长序列特征的提取效率。 针对短蛋白质:保留三角注意力模块,精简非必要的MSA处理单元,实现模型的轻量化部署。 通用优化方向:聚焦Pair表征的优化策略,通过增强残基对空间约束的编码精度,提升模型整体性能。 技术层面:建立了生物大分子模型组件分析的标准流程研究提出的“组件消融-性能量化-特性关联”分析框架,可迁移至AlphaFold3、Boltz等后续模型,也为RNA、DNA等其他生物大分子结构预测模型的解析提供了方法论参考。
该研究通过严谨的组件级消融实验与量化分析,系统性地揭示了OpenFold核心模块的功能权重与长度依赖规律,为蛋白质结构预测模型的“黑箱”解构迈出了关键一步。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢