

主要贡献
提出了预探索零样本视觉语言导航设定,允许智能体在执行导航任务前对环境进行充分预探索,突破了传统零样本VLN仅依赖在线局部感知的限制,更贴合真实机器人应用场景。 构建了空间场景图(SSG),通过对预探索获取的3D点云进行楼层分割、房间分割、房间分类和目标检测等结构化标注,高效编码环境的全局空间结构与语义信息,为智能体提供全局感知基础。 设计了零样本VLN智能体SpatialNav,整合三大核心组件:以智能体为中心的空间地图(支持粗粒度空间推理)、罗盘对齐的视觉表征(降低输入开销并保持方向一致性)、远程目标定位策略(支持未来感知决策),实现高效导航。 实证验证了全局空间信息在不同智能体和环境中的有效性,SpatialNav在离散和连续环境数据集上的性能显著超越现有零样本方法,甚至接近部分有监督学习方法的水平。
研究背景
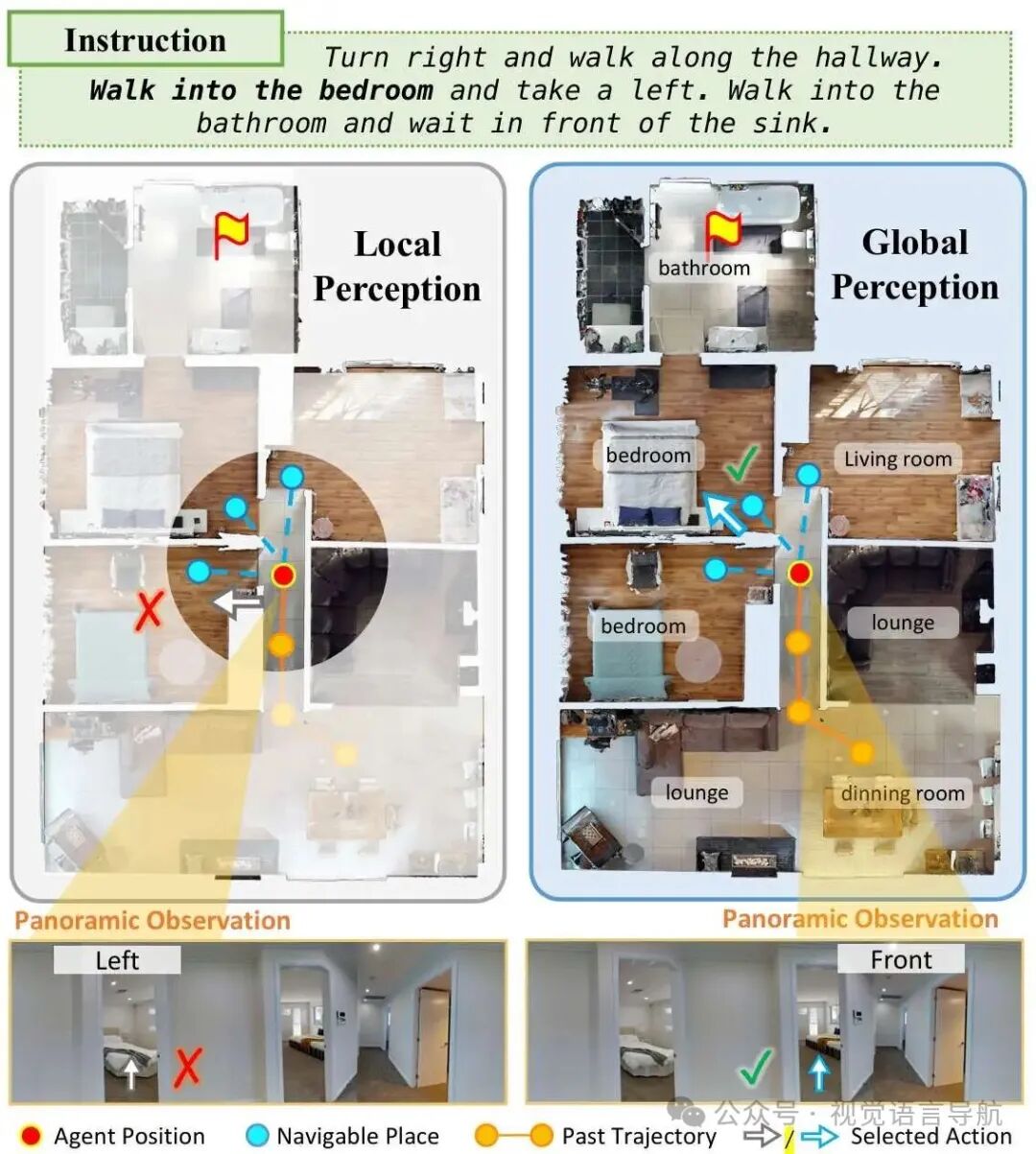
VLN任务定义: 视觉语言导航(VLN)是具身AI领域的核心问题,要求智能体遵循自然语言指令在复杂真实环境中完成导航,需融合视觉感知、语言理解与空间推理能力。 现有方法主要分为两个大类: 有监督学习方法:依赖大规模领域特定训练数据,通过预训练隐式学习空间先验(如房间布局规律、功能区域关联),但泛化能力受限,难以适应未见过的环境。 零样本方法:借助多模态大语言模型(MLLMs)实现无任务特定训练的泛化导航,但仅依赖局部观测决策,缺乏全局空间信息。这种“短视”的方法导致几个关键问题: 探索效率低下:由于缺乏对整体布局的了解,智能体可能会反复访问同一区域或选择不必要的长路径。 难以消除歧义:当存在多个局部合理的行动时,智能体缺乏做出最优决策所需的全局上下文信息。 长远推理能力差:缺乏全面的空间理解,难以完成需要多步骤规划的复杂导航任务。
零样本方法和监督方法之间的性能差距主要源于空间感知能力的差异。监督智能体通过接触不同的环境来隐式地学习全局空间先验知识,而零样本智能体则仍然局限于即时的视觉观察。
研究动机: 现实场景中(如扫地机器人),智能体通常在固定封闭环境中工作,具备预探索环境的条件。基于此,通过预探索构建全局空间表征,可弥补零样本智能体缺乏空间先验的缺陷,提升导航性能与泛化能力。
研究方法
论文采用贴合真实场景的VLN设定,允许智能体在执行导航任务前,通过现有SLAM系统采集RGB视频,生成环境的稠密或稀疏3D点云(预探索阶段)。 核心目标分为两部分: 一是为原始3D点云添加结构化空间标注(如楼层-房间-物体的层级关系)和语义标签(如房间类型、物体类别),构建可跨任务复用的空间场景图(SSG); 二是设计SpatialNav智能体,高效利用该场景图实现零样本导航。
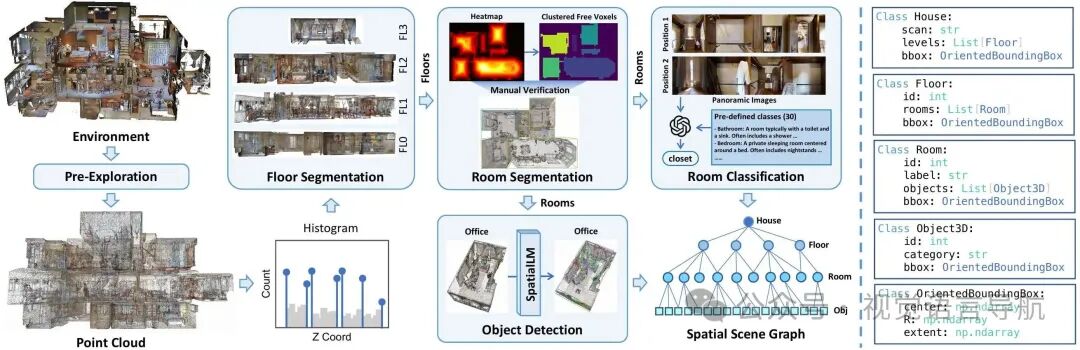
通过四阶段自动化 pipeline 处理3D点云,形成层级化图结构:
楼层分割:计算所有点的高度直方图,应用DBSCAN算法,选取排名最高的峰值作为不同楼层。 房间分割:采用基于几何启发式的方法,将每个楼层划分为封闭区域(即房间)。针对该方法在连续开放空间中性能下降的问题,对面积大于20平方米的区域进行人工验证优化。 房间分类:收集预探索阶段每个房间内的图像或视频帧,提示GPT-5按照预设的房间类别列表,为分割后的房间分配语义标签。 物体检测:在Matterport3D数据集的训练扫描数据上微调SpatialLM模型,该模型接收房间级点云输入,输出物体的边界框及类别标签。 最终构建的SSG以楼层、房间、3D物体为节点,以包含关系为边,形成紧凑的环境知识库。
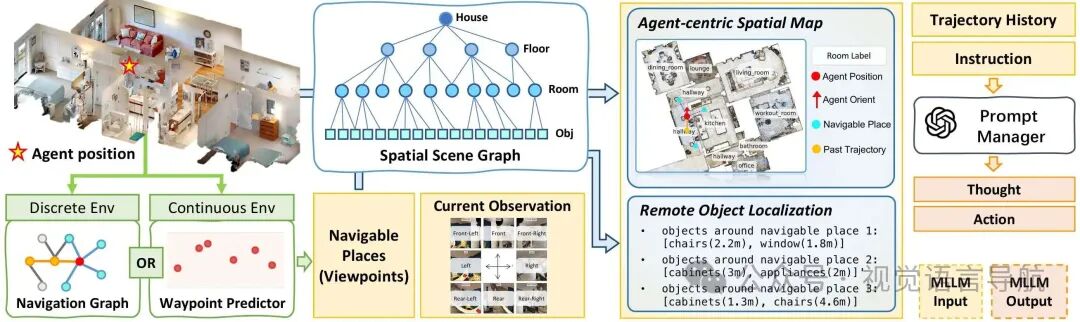
智能体基于多模态大语言模型(MLLM)构建,通过三大核心组件高效利用SSG,突破局部感知局限:
以智能体为中心的空间地图
定位逻辑:根据智能体当前Z轴坐标确定楼层,结合X-Y坐标定位所在房间。 地图构建:在同一楼层内,定义半径约7米的感知范围,将智能体位置及周边房间投影到俯视地图,且智能体朝向始终与地图向上方向对齐。 核心作用:提供简洁的任务相关空间布局,支持粗粒度空间推理,避免无关信息干扰。 罗盘式视觉表征
观测处理:将全景视觉观测离散为8个方向视图(0°-360°,每右转45°一个),每个视图视野设为90°,无需调整仰角。 表征形式:将8个视图按顺时针顺序排列在3×3网格的周边,中心放置罗盘标识,形成单张罗盘式图像(默认分辨率1024×1024)。 核心作用:保持与空间地图的方向一致性,将视觉输入令牌数从1700+降至640左右,降低计算开销。 远程目标定位
检索逻辑:针对离散环境的导航图节点或连续环境的候选路径点(由路径点预测器生成),查询SSG获取其周边一定范围内的物体语义信息。 信息形式:提取物体类别及与候选位置的距离,压缩为简洁文本描述,融入智能体决策上下文。 核心作用:让智能体预判不同导航方向的未来观测,支持前瞻性决策。 决策流程:整合空间地图、罗盘式视觉观测、远程目标信息、轨迹历史及语言指令,输入GPT-5.1生成下一步导航动作。
实验
数据集与模拟器 离散环境:采用R2R(783条轨迹)、REVERIE(1328条轨迹)数据集,基于Matterport3D模拟器,验证集均为未见过的11组场景。 连续环境:采用R2R-CE(随机采样100条轨迹)、RxR-CE(随机采样200条轨迹)数据集,基于Habitat v0.3.2模拟器。 评估指标 轨迹长度(TL) 导航误差(NE,越低越好) 成功率(SR,越高越好)、成功定义为智能体停在目标3米范围内 Oracle成功率(OSR,越高越好) 路径长度加权成功率(SPL,越高越好) 归一化动态时间规整(nDTW,越高越好) 基线方法 离散环境:6种有监督学习方法(如ScaleVLN、DUET)和4种零样本方法(如SpatialGPT、NavGPT)。 连续环境:7种有监督学习方法(如Efficient-VLN、NavFoM)和5种零样本方法(如VLN-Zero、Smartway)。 实现细节 罗盘式图像:8个256×256方向视图拼接为1024×1024图像。 空间地图:宽高1024像素,网格大小0.015m,感知半径7.68m。 远程目标定位:检索候选位置同一房间内的物体,按类别分组。 骨干模型:采用GPT-5.1作为MLLM backbone;连续环境中使用Shi等人2025年提出的路径点预测器。
离散环境表现
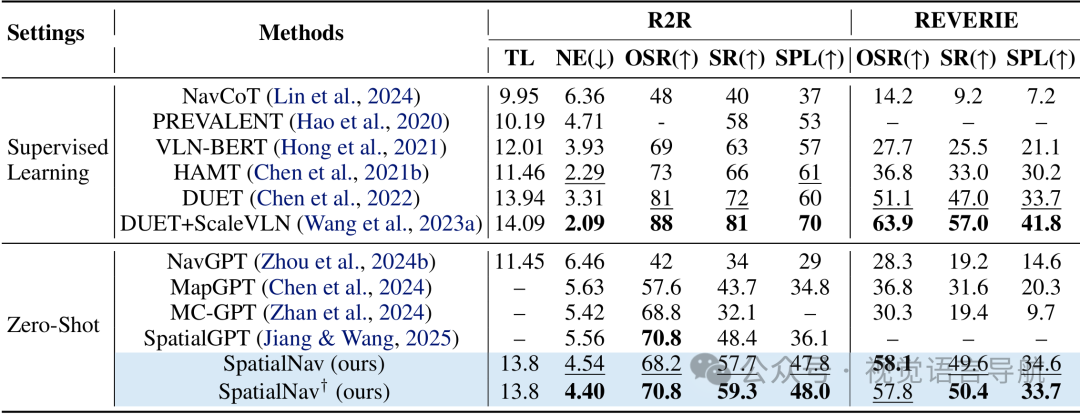
SpatialNav在R2R val-unseen数据集上SR达57.7%、SPL达47.8%,较最强零样本基线SpatialGPT分别提升9.3%和11.7%。 性能接近PREVALENT、VLN-BERT等有监督学习方法;在REVERIE数据集上SR达49.6%,超越所有零样本基线。 采用真实标注的变体SpatialNav†性能进一步提升,验证了空间标注质量对导航效果的关键作用。 连续环境表现
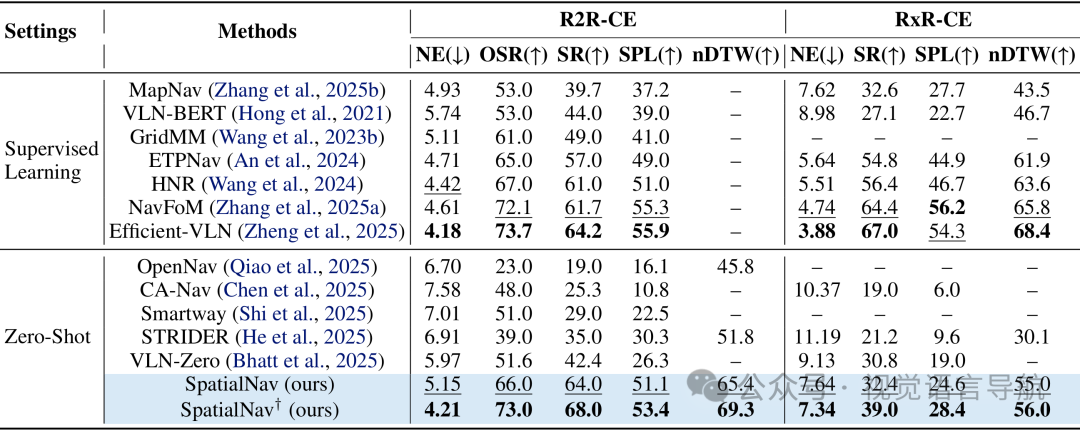
在低级别控制更复杂的连续环境中,SpatialNav显著优于所有零样本方法。 针对R2R-CE数据集,较VLN-Zero(同样基于预探索全局记忆)实现+21.6%的SR提升和+24.8%的SPL提升,核心原因是SSG同时建模了全局布局与详细语义,而VLN-Zero仅依赖符号化场景图。 在RxR-CE数据集上SR达32.4%,仍保持性能优势,证明空间知识的通用性。
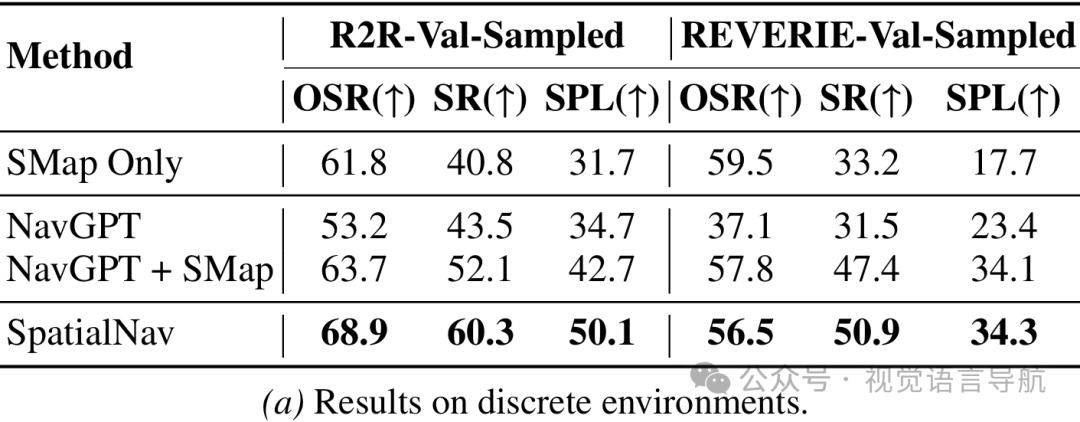
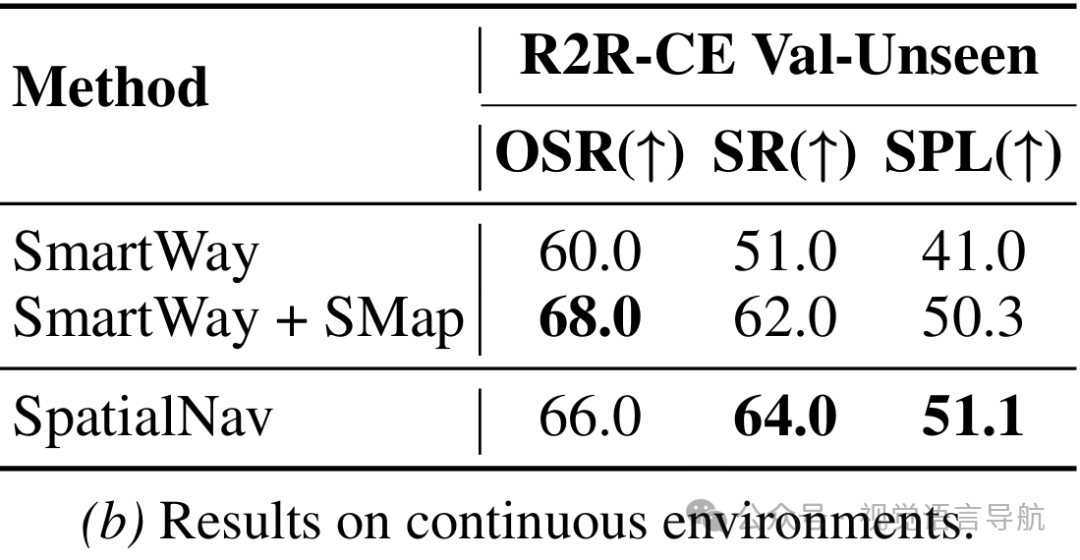
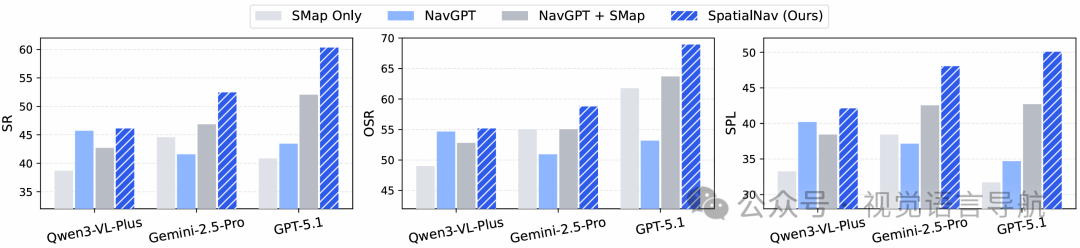
空间知识的有效性验证 设计“仅空间地图”(SMap Only)基线,不使用任何视觉或文本观测,仅依赖空间地图、导航指令和导航点,仍取得良好性能,证明空间地图本身包含足够导航信息。 为现有零样本方法(NavGPT、Smartway)添加空间地图后,其SR、SPL等指标均显著提升,说明显式空间信息是跨智能体、跨环境的有效信号。 测试不同MLLM骨干(GPT-5.1、Gemini-2.5-Pro、Qwen3-VL-Plus),仅Qwen3-VL-Plus因输出模式固化,提升比较微小,其余均有明显增益,且SpatialNav在所有骨干上表现最优,证明方法对骨干模型的低依赖性。
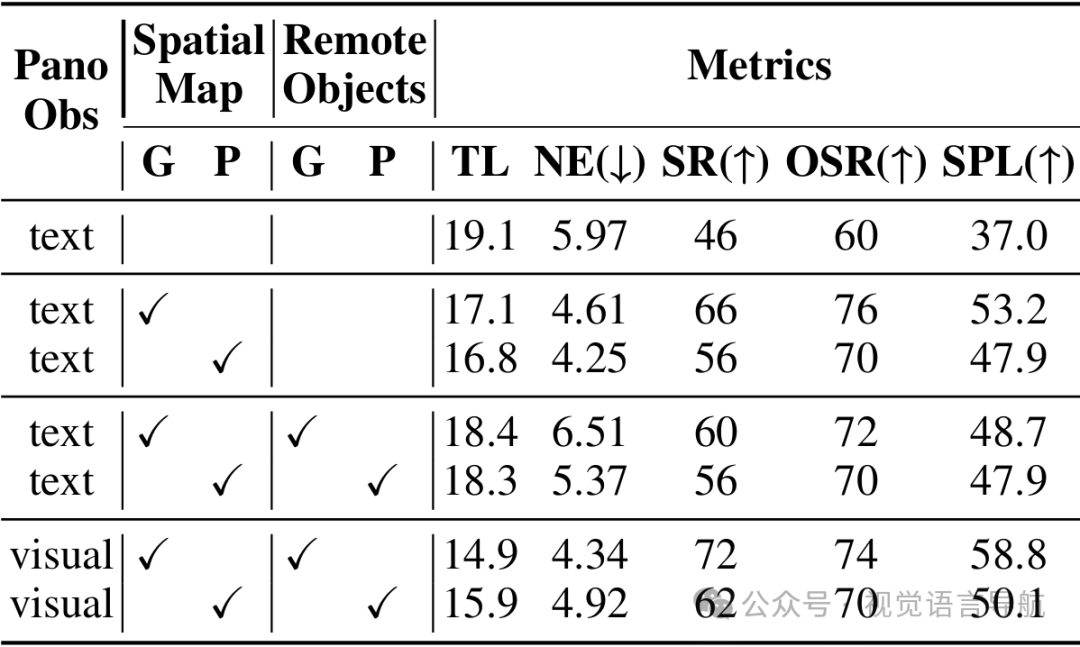
组件有效性分析 仅添加空间地图即可提升基线性能;但文本观测下添加远程目标语义会因语义歧义导致性能下降,而罗盘式视觉观测可缓解该问题,说明空间语义需与视觉观测进行有机结合才能发挥最大作用。 真实标注(G)的性能始终优于模型预测标注(P),但预测标注仍能带来显著收益,验证了SSG构建 pipeline 的实用性。
罗盘式视觉表征效率 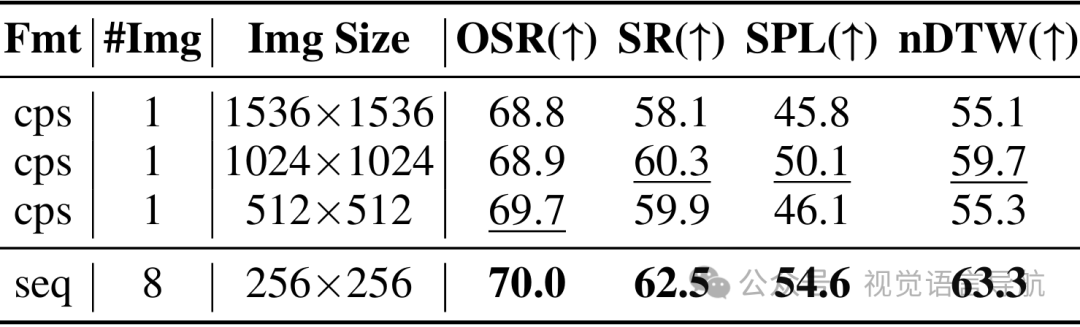
1024×1024分辨率的罗盘图像性能最优,SR达60.3%、SPL达50.1%。 虽然8个视图顺序输入的性能略优(SR=62.5%),但需消耗1700+视觉令牌,而罗盘图像仅需640个令牌,兼顾效率与准确性,因此作为默认方案。 空间地图感知范围 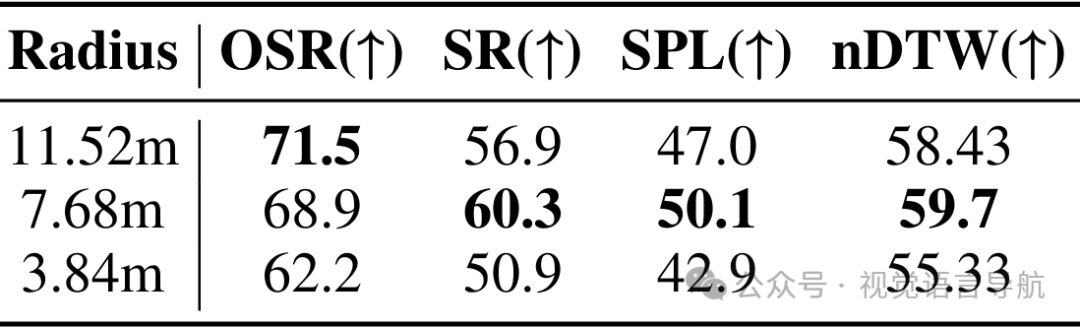
7.68m半径为最优选择,SR=60.3%、SPL=50.1%、nDTW=59.7%,实现空间信息与决策效率的平衡。 3.84m(接近局部感知范围)提供的额外信息有限,性能提升不足;11.52m(过大半径)引入无关冗余信息,导致SR下降。
结论与未来工作
结论: 本文提出的预探索设定与空间场景图,有效解决了零样本VLN智能体缺乏全局空间信息的核心问题。 SpatialNav通过整合以智能体为中心的空间地图、罗盘式视觉表征和远程目标定位,实现了高效、泛化的导航,显著缩小了零样本方法与有监督方法的性能差距,凸显了全局空间表征对通用导航的重要性。 未来工作: 探索空间场景图与有监督学习方法的融合,设计适配全局空间表征的训练范式,进一步提升导航性能。 优化3D点云重建与空间标注的自动化 pipeline,降低计算开销与人工干预需求,提升方法的实用性与扩展性。 解决开放空间或边界模糊场景的房间分割难题,增强空间场景图在复杂环境的鲁棒性。
复旦大学数据智能与社会计算实验室
Fudan DISC

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢