
第一篇“DeepSeek 时刻” 一周年;
第二篇DeepSeek之后:中国开源人工智能生态的架构选择
在本篇中,我们介绍了中国人工智能企业和机构的发展路径与轨迹,并对开源的未来方向进行了展望。对于致力于开源生态的研究人员、开发者,以及关注行业动态的政策制定者而言,开源已成为中国AI组织近期发展的主流选择。这背后,既有组织内部的战略考量,也有全球社区协作的推动。从模型权重到技术论文,再到部署基础设施,全方位的开放共享正成为实现大规模应用与产业集成的关键路径。
在回顾了 DeepSeek R1 之后的战略与架构变化之后,我们首次得以窥见中国开源人工智能 "有机生态" 的形成过程。多股力量在此汇聚:既有长期深耕开源的成熟参与者,也有新进入的组织,还有一些则彻底调整方向,主动投身于新的开放文化。这些变化共同表明,开放协作的路径对各方而言是互利共赢的。
这种协作正在超越国家边界;在 Hugging Face 上,关注度最高的组织是 DeepSeek,而关注度排名第四的则是 Qwen。
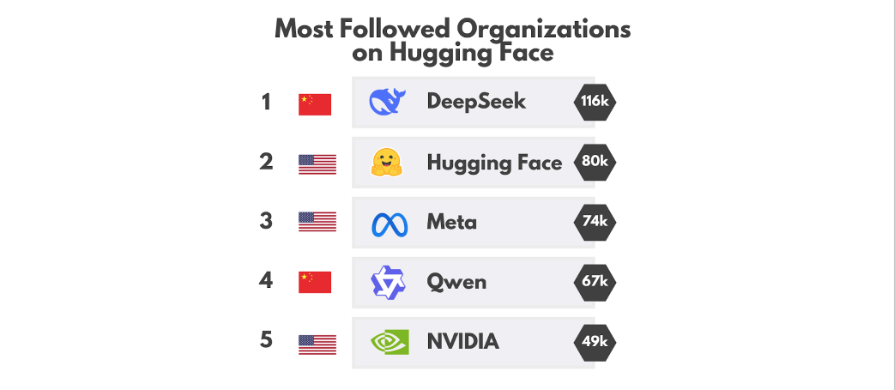
除了模型之外,公开共享的科学成果和技术方法不仅为其他组织提供了参考,也惠及了整个开源社区。 Hugging Face 上最受欢迎的论文大多来自中国组织,主要包括字节跳动、DeepSeek、腾讯和 Qwen。
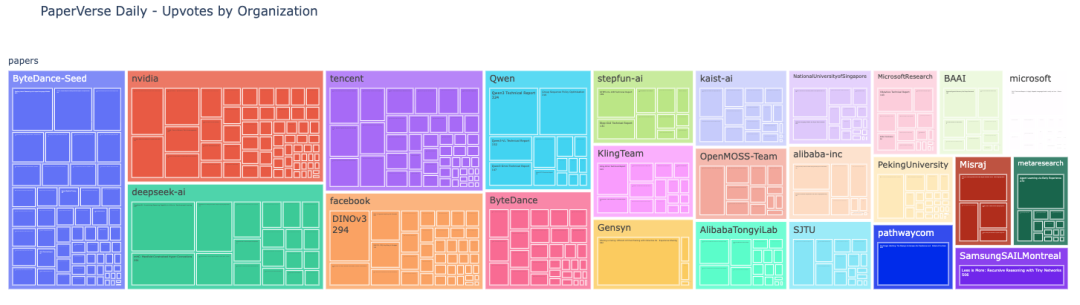
https://huggingface.co/spaces/evijit/PaperVerse
阿里巴巴将开源定位为一项生态系统与基础设施层面的战略。Qwen 并未被塑造成单一的旗舰模型,而是持续扩展为一个覆盖多种规模、任务和模态的模型家族,并在 Hugging Face 以及其自有平台 ModelScope 上保持高频更新。其影响力并未集中于某一个具体版本之上,而是被反复作为组件在不同应用场景中复用,逐步承担起通用 AI 基础底座的角色。
截至 2025 年中,Qwen 成为 Hugging Face 上衍生模型数量最多的基础模型,已有超过 11.3 万个模型以 Qwen 为基座构建,超过 20 万个模型仓库标注了 Qwen,远高于 Meta 的 Llama(2.7 万)或 DeepSeek(6 千)。在组织层面,阿里巴巴的衍生模型总量几乎相当于谷歌与 Meta 的总和。
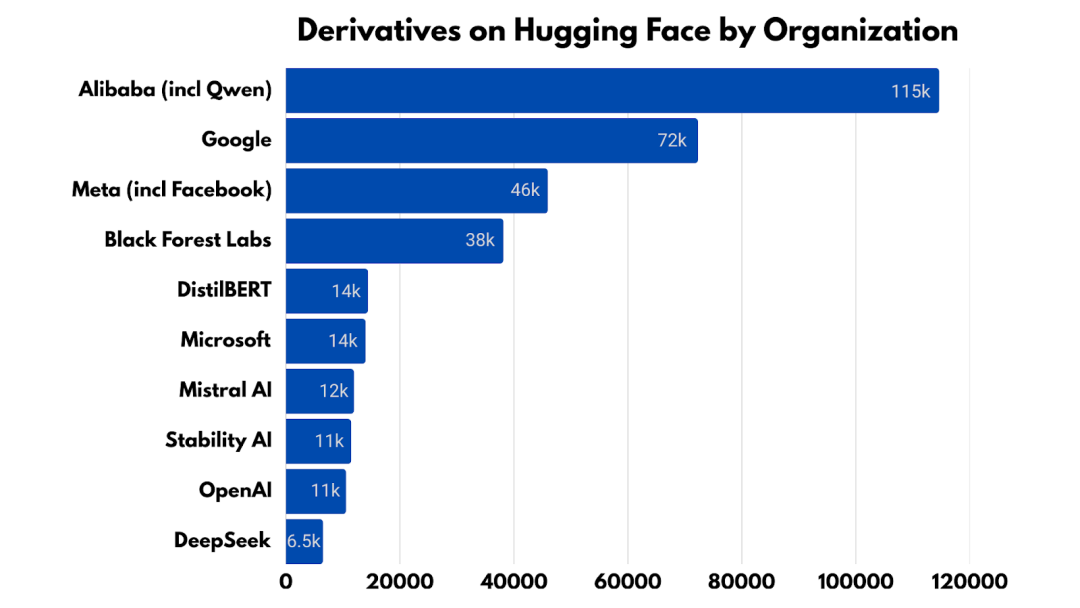
与此同时,阿里巴巴将模型研发与云计算及硬件基础设施进行对齐,把模型、芯片、平台和应用整合进一个统一的工程技术栈之中。
腾讯同样完成了一次从“借用”到“自建”的重要转变。作为 R1 发布后最早将 DeepSeek 集成进核心消费级产品的头部公司之一,腾讯起初并未将开源作为对外叙事的重点。相反,它通过插件式集成的方式引入成熟模型,在内部开展了大规模验证,随后才逐步开始对外发布自身能力。自 2025 年 5 月起,腾讯在自身已有优势的领域加速推进开源发布,尤其是在视觉、视频和 3D 方向,并以“腾讯混元”(现称 Tencent HY)这一品牌推出,这些模型很快在社区中获得了广泛采用。
字节跳动则延续其 “AI 应用工厂” 的发展路径,选择性地开源高价值组件,同时将竞争重心保留在产品入口和大规模用户使用之上。在这一背景下,字节跳动 Seed 团队贡献了多项重要的开源成果,包括用于多模态 UI 理解的 UI-TARS-1.5、用于数据中心化代码建模的 Seed-Coder,以及用于系统性推理评估的 SuperGPQA 数据集。尽管其开源存在感相对低调,字节跳动在中国 AI 市场实现了显著规模,其 AI 应用 "豆包" 在 2025 年 12 月的日活跃用户数已突破一亿。
百度的变化引人注目。其 CEO 曾公开对开源持保留态度,但公司同样开始转向。经过多年对封闭模型的优先投入后,百度通过免费使用和模型开源的方式重新进入生态体系,例如 Ernie 4.5 系列模型。与此同时,百度加大了对其开源框架 PaddlePaddle 的投入,并持续推进自研 AI 芯片昆仑芯,该芯片业务已于 2026 年 1 月 1 日宣布启动 IPO。通过在更开放的系统中打通模型、芯片与 PaddlePaddle,百度得以在算力、成本和监管等共同约束下,降低成本、吸引开发者并影响行业标准,同时保持自身的战略控制力。
在初创公司中,月之暗面(Moonshot)、智谱 AI(Z.ai)和 MiniMax 在 R1 发布后的数月内迅速完成调整,并为开源社区带来了新的动能。Kimi K2、GLM-4.5 和 MiniMax M2 等模型均跻身 AI-World 的开源模型里程碑榜单。到 2025 年底,智谱 AI 和 MiniMax 发布了各自迄今最先进的开源模型,并在随后不久先后宣布了 IPO 计划。
Kimi K2 的开源发布被社区广泛称为 “又一个 DeepSeek 时刻” 。尽管月之暗面尚未宣布 IPO,但市场报告显示,截至 2025 年底,该公司已完成约 5 亿美元融资,并将 AGI 以及基于智能体的系统作为其主要商业化方向。
那些以应用优先的公司,如小红书、哔哩哔哩、小米和美团,也开始训练并发布自有模型。凭借其在真实使用场景和行业数据方面的天然优势,一旦通过开源以较低成本获得了强推理能力,自研模型便具备了现实可行性。这使它们能够围绕自身业务对 AI 进行定制,而不再受制于外部服务商的成本结构或能力边界。
如果说商业领域迅速抓住了这一 ROI 为正的增长机遇,那么科研机构和更广泛的社区则更加积极地拥抱了这一转变。诸如北京智源研究院(BAAI)和上海人工智能实验室等机构,将更多资源转向工具链、评测体系、数据平台和部署基础设施建设,例如 FlagOpen、OpenDataLab 和 OpenCompass 等项目。这些努力并未追逐单一模型的性能极限,而是着力夯实整个生态系统的长期基础。
新生态系统的决定性特征并不在于模型数量的增加,而在于一条完整链条的形成。模型可以被开源并持续扩展;部署方案可以被复用并实现规模化;软硬件能够协同设计、灵活替换;治理能力也可以被嵌入系统并接受审计。这标志着从孤立式技术突破,转向真正能够在现实世界中运行的系统。
这一生态并非一蹴而就,而是建立在自 2017 年以来多年积累的基础设施 “顺风” 之上。过去数年中,中国持续、周期性地投入数据中心和算力中心建设,逐步形成了以 “东数西算” 为核心的全国一体化算力布局。国家层面规划建设了 8 个国家级算力枢纽和 10 个数据中心集群,引导算力需求从东部向中部和西部地区转移。
公开信息显示,中国计划持续加大能源供给能力的投入。到 2025 年,中国的总体算力规模约为 1590 EFLOPS,位居全球前列。中国方面的相关数据指出,面向 AI 训练和部署的智能算力预计将以约 43% 的年增长率持续提升,显著快于通用算力的增长速度。与此同时,数据中心的平均电能使用效率(PUE)已降至约 1.46,显示出整体能效水平的改善,并为大规模 AI 应用提供了坚实的硬件基础。能源问题显然成为关键关注点之一。
如果说 2017 年发布的《新一代人工智能发展规划》主要侧重于方向指引和基础能力建设,那么 2025 年 8 月推出的 “AI+” 行动计划则明确将重点转向大规模部署与深度融合。这标志着一条在发展方向上不同于 AGI 的路径。R1 的出现,恰好在工程与生态层面提供了此前缺失的 “升力”,成为系统性激活既有算力、能源和数据基础设施的催化剂。
因此,在 R1 发布后的一年中,中国 AI 的发展沿着两条主要路径显著加速。第一,AI 更深度地嵌入工业与业务流程之中,从以聊天机器人为代表的应用,逐步迈向智能体系统和工作流。第二,对自主可控 AI 系统的重视程度明显提升,体现在更加灵活的训练路径,以及愈发本地化的部署策略之上。
回顾来看,真正的转折点并非模型数量的增长,而是开源模型使用方式的根本性变化。开源从一种可选方案转变为系统设计中的默认前提,模型也由此成为更大工程体系中可复用、可组合的基础组件。
从 DeepSeek 到“AI+”,中国在 2025 年所走的道路并非围绕性能峰值的竞逐,而是在开源、工程效率与可规模化交付的基础上,构建了一条务实可行的发展路径,而且这条路径已经开始自行运转。
资源约束并未限制中国 AI 的发展,相反,在某些方面,它们重塑了其发展轨迹。DeepSeek R1 的发布起到了催化剂的作用,引发了国内产业体系的一系列连锁反应,加速了一个更加有机结构化生态系统的形成。与此同时,这一转变也为持续推进本土研究与开发创造了一个关键窗口。随着这一生态逐渐成熟,其长期影响,以及全球 AI 社区将如何与一个日益自我维持的中国 AI 生态系统展开互动,都将成为未来值得深入讨论的重要议题。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢