
原子级模拟在化学与材料科学研究中发挥着至关重要的作用。然而,由于在计算设置、任务执行以及结果验证等阶段均需要较高的专业知识,其高效运行长期以来仍具有较大挑战。2026年1月8日,美国阿贡国家实验室的研究人员在《Communications Chemistry》上发表其最新研究,题为“ChemGraph as an agentic framework for computational chemistry workflows”。

该研究提出了一种名为ChemGraph的智能体框架,用于简化并自动化计算化学与材料科学工作流。ChemGraph结合了基于图神经网络的基础模型,以实现兼具高精度与高效率的计算,同时利用大语言模型(LLMs)进行自然语言理解、任务规划和科学推理,从而提供直观且交互式的使用界面。研究结果表明,通过采用多智能体架构将复杂任务拆解为多个相对独立的子任务,不仅可以使GPT-4o在相关基准测试中达到100%的准确率,还能够显著提升小规模LLM的性能,使其在部分任务中达到甚至超过单智能体GPT-4o的表现。
ChemGraph代码仓库:
https://github.com/argonne-lcf/ChemGraph
背景
近年来,机器学习技术的快速发展,尤其是面向分子与材料体系的图神经网络和基础模型的提出,为部分传统量子力学方法提供了在精度和可扩展性方面均具优势的替代方案。尽管如此,高效开展分子模拟仍然是一项复杂且耗时的任务,往往需要贯穿整个工作流的专业知识和大量人工操作。研究人员必须谨慎地定义体系参数、选择合适的计算方法并生成输入文件,且这些设置需针对具体研究问题进行定制。与此同时,不同模拟软件在输入语法、编程语言和用户接口方面的差异,进一步增加了操作复杂度。即便是输入配置中的微小错误,也可能导致结果不正确、计算资源的浪费,甚至任务失败。
人工智能(AI)领域的最新进展,尤其是LLMs的出现,为科学研究流程的自动化提供了新的契机。LLMs在自然语言理解、推理和任务执行方面展现出卓越能力,使其非常适合用于引导和管理复杂工作流。近年来,已有多种基于LLM的智能体系统被提出,用于支持不同类型的化学相关任务。
本文介绍了一种由LLM驱动、面向计算化学分子模拟工作流的智能体系统ChemGraph。该系统将自然语言处理与模拟工具相结合,能够执行从SMILES字符串和分子结构生成,到几何优化、振动分析以及热化学计算等一系列任务。
方法
ChemGraph基于LangGraph实现,并遵循ReAct框架。图1展示了ChemGraph的总体结构。首先,LLM智能体会被提供一组预定义的工具。基于用户的提示,智能体决定调用哪一个工具。每次工具调用完成后,LLM会接收工具调用的结果,并判断是否需要进一步的工具调用。在所有工具调用完成后,消息将沿两条路径之一继续传递。在第一种路径中,ChemGraph的行为类似于传统LLM,返回一个融合了工具调用结果的自然语言响应;在第二种路径中,消息会被传递给第二个LLM智能体,其负责生成结构化输出(遵循预定义的JSON模式),直接回应用户的请求。
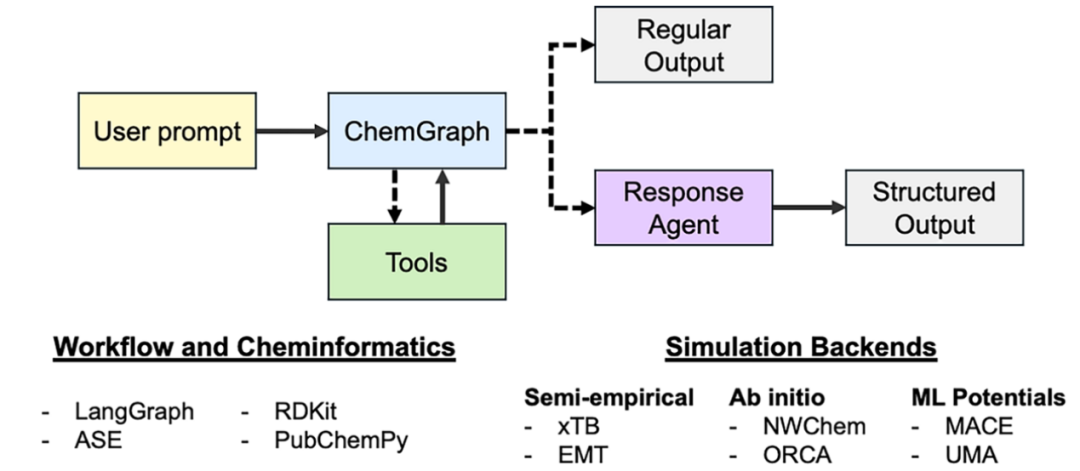
图1 ChemGraph总览
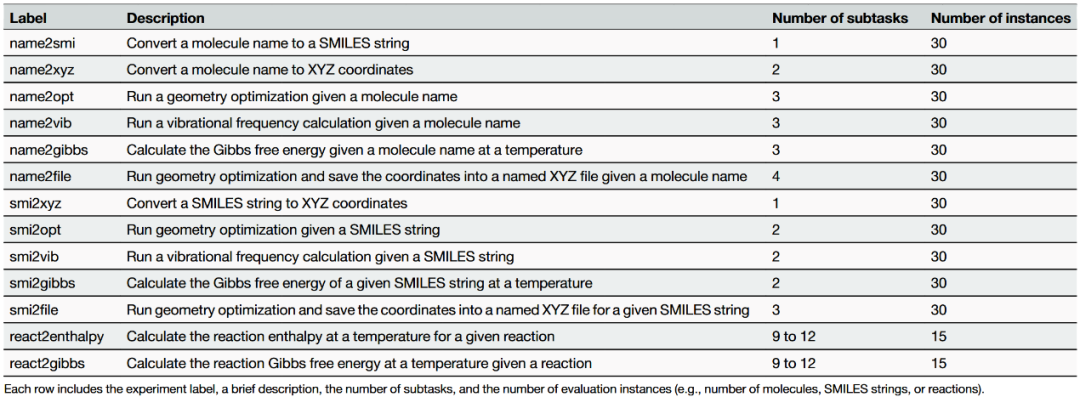
表1展示了ChemGraph中集成的各工具名称及功能。表2展示了用于评估ChemGraph的基准实验详情。
表1 ChemGraph中集成的工具
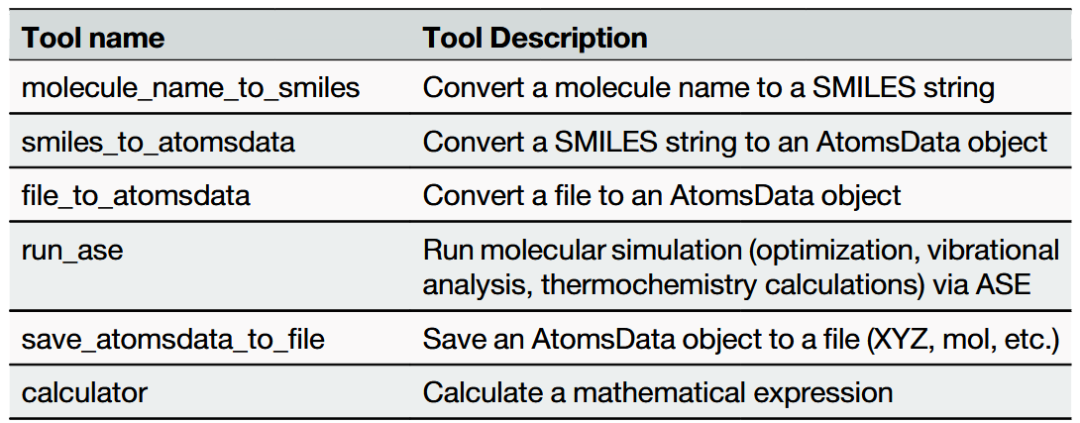
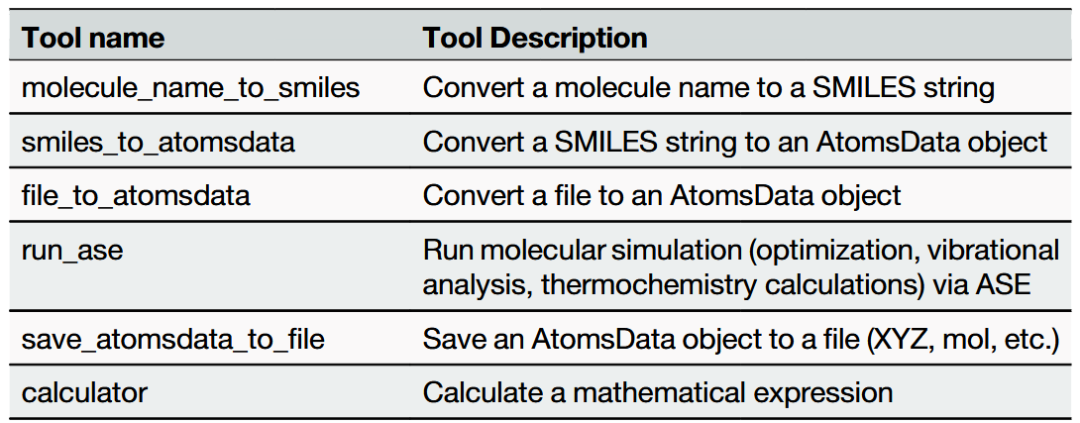
表2 用于评估ChemGraph的基准实验
针对本研究中最复杂的两项任务(react2enthalpy和react2gibbs),作者设计并评估了ChemGraph的多智能体版本。图2展示了该多智能体系统架构。由三部分组成:规划智能体、执行智能体以及汇总智能体。规划智能体负责将用户请求分解为若干子任务,并生成相应的一系列提示。这些子提示会被传递给一个循环控制器,后者依次将每个提示发送给执行智能体。在所有子任务完成后,其汇总结果会被发送给汇总智能体。汇总智能体综合原始用户查询、规划智能体的任务分解以及执行智能体的结果摘要,生成最终答案。
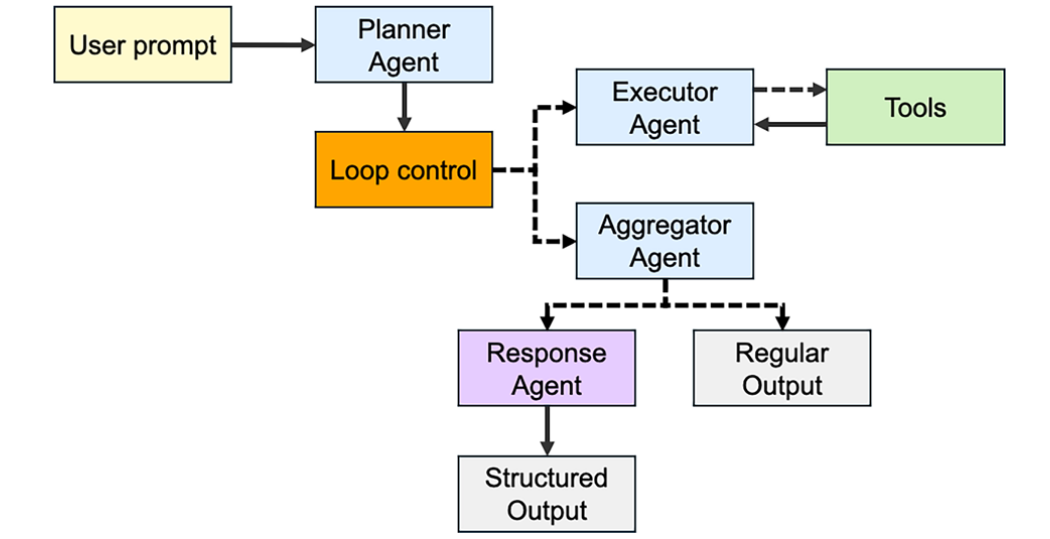
图2 多智能体ChemGraph的体系结构
结果
ChemGraph工作流示例
图3展示了ChemGraph如何调用工具并协调其输出,以完成一个计算化学任务。在该示例中,用户请求ChemGraph使用GFN2-xTB方法计算400K下甲烷燃烧反应的反应焓。ChemGrap(基于GPT-4o-mini)首先将反应中各分子的化学名称转换为SMILES字符串(工具调用1–4)。随后,基于这些SMILES字符串生成原子坐标,并以AtomsData数据结构表示(工具调用5–8)。最后,ChemGraph利用生成的坐标以及用户指定的参数(例如计算器类型和温度)运行热力学计算。该示例表明,ChemGraph能够自主调用工具并执行多个中间步骤,从而得到反应的最终焓变。
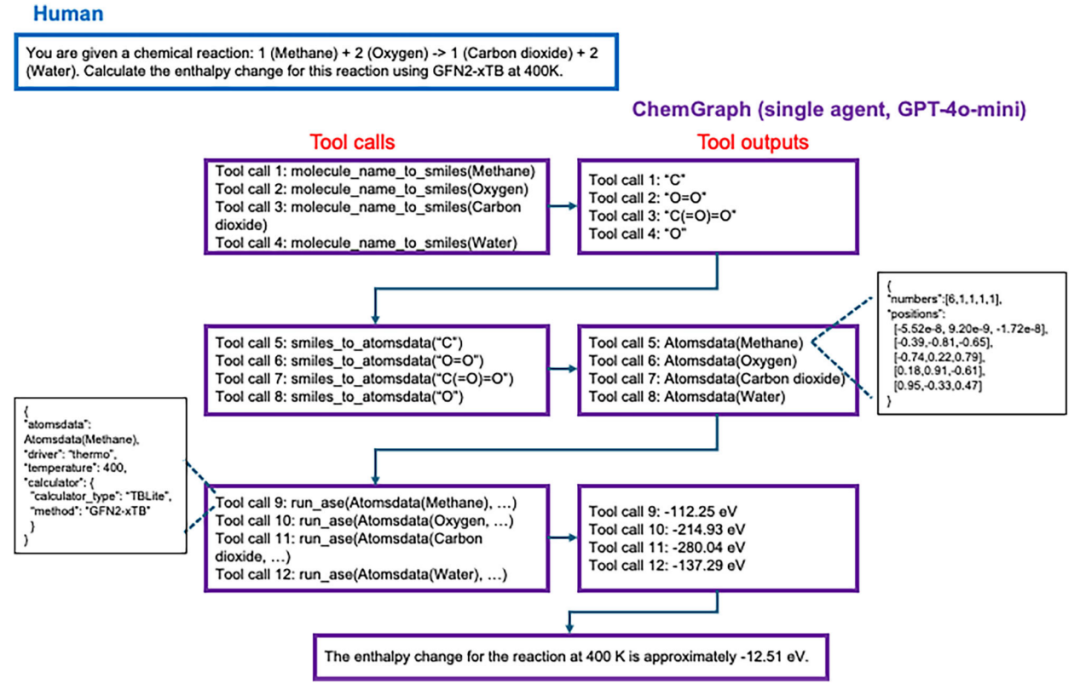
图3 使用GPT-4o-mini,任务为react2enthalpy的human–ChemGraph(单智能体)交互示例。
单智能体评估
研究团队在13项实验中评估了单智能体ChemGraph在三种LLM(GPT-4o-mini、Claude-3.5-haiku和Qwen-2.5-14B)上的性能。对于GPT-4o,仅在最后两个任务(react2enthalpy和react2gibbs)中对其性能进行了评估。图4展示了不同模型在不同任务上的准确率表现。任务复杂度以所需的工具调用次数衡量,并在图5中进行展示。
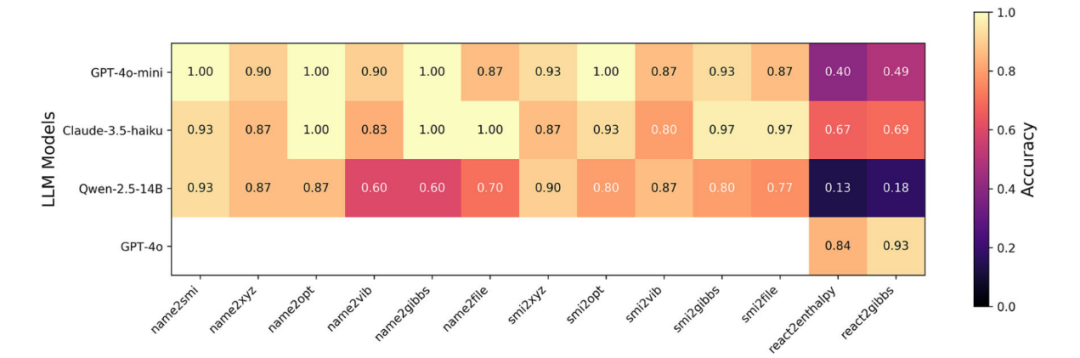
图4 单智能体ChemGraph的准确率热图
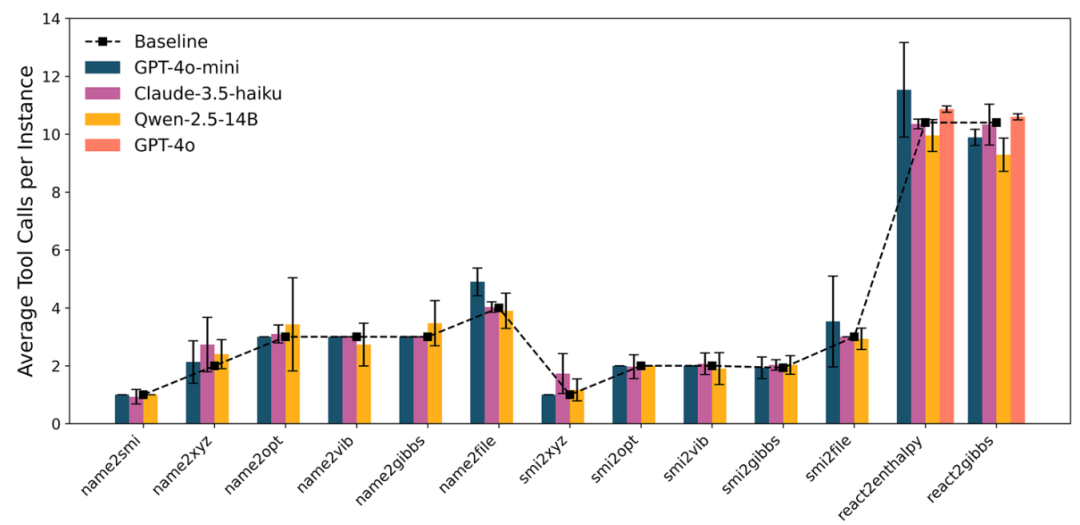
图5 不同LLM在13项实验中的工具调用次数
前六项实验(name2smi至name2file)主要关注以分子名称和其他参数为输入的化学信息学与分子模拟任务。Claude-3.5-haiku和GPT-4o-mini均表现出稳定且优异的性能,在每项任务中均达到了80%以上的准确率。相比之下,Qwen-2.5-14B的性能波动较大。在name2smi任务中,Claude-3.5-haiku并未始终调用molecule_name_to_smiles工具,而是有时尝试依赖其内部的化学知识手动构建SMILES字符串,或直接拒绝使用该工具(图6)。在该任务中,Claude-3.5-haiku的每个分子平均工具调用次数在三种模型中最低(图5)。GPT-4o-mini在该实验中能够准确生成正确答案。Qwen-2.5-14B通常能够生成正确的工具调用,包括工具名称和参数,但其错误多发生在从工具输出中提取结果的阶段。

图6 ChemGraph智能体在name2smi任务中的多轮交互示例
接下来的三个任务(name2xyz、name2opt和name2vib)要求LLM不仅能够正确调用工具,还需生成结构化且格式正确的输出。GPT-4o-min和Claude-3.5-haiku在这些任务中均表现良好,准确率均高于83%。在各模型中最常见的错误包括工具参数设置错误,以及在格式化代理对结果进行汇总时出现的问题。在name2file任务中,用户提示要求使用mace_mp方法进行几何优化,并将结果保存为XYZ文件。GPT-4o-mini在工具调用时经常出现错误,将方法名mace_mp同时作为优化器和计算器传入,从而导致初始执行失败。然而,该模型通常能够利用错误信息的反馈进行恢复,最终达到87%的准确率(图4)。
接下来的五项实验(smi2xyz至smi2file)侧重于以SMILES字符串作为输入的任务。Claude-3.5-haiku和GPT-4o-mini依然保持了稳定且优异的表现,准确率均超过83%。Qwen-2.5-14B在这一组任务中也有所提升,其最低准确率达到77%。在最后两个任务(react2enthalpy和react2gibbs)中,Qwen-2.5-14B表现最弱,准确率低于20%。GPT-4o-mini的表现居中,Claude-3.5-haiku在小型LLM中表现最佳。GPT-4o的性能最优,在两项任务中的平均准确率均超过83%。这些任务中的一个共性错误是,LLM(尤其是小模型)在上下文窗口被大量数据占据时,容易混淆不同的分子属性(例如原子序数、坐标和能量)。
多智能体评估
图7展示了一个Human–ChemGraph(多智能体)交互示例,计算在400K条件下使用GFN2-xTB方法得到的甲烷燃烧反应焓。
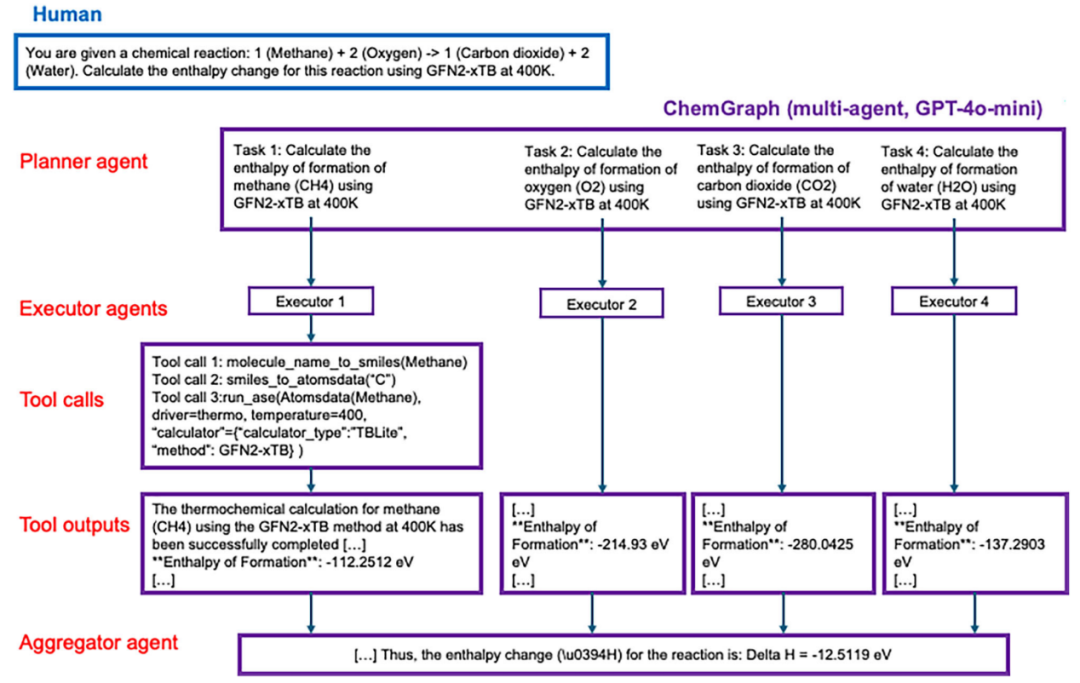
图7 使用GPT-4o-mini,任务为react2enthalpy的Human–ChemGraph(多智能体)交互示例。
作者使用GPT-4o-mini、Claude-3.5-haiku、Qwen-2.5-14B和GPT-4o对多智能体ChemGraph 的性能进行了评估(图8),并将结果与图4中所示的单智能体性能进行了比较。多智能体系统在所有模型上均显著提升了准确率。在react2enthalpy任务中,GPT-4o-mini的准确率从40%提升至87%,Claude-3.5-haiku从67%提升至87%。值得注意的是,这两种模型的表现均超过了单智能体GPT-4o的基线准确率83%。在最后一个任务react2gibbs中也观察到了类似趋势:GPT-4o-mini的准确率从49%提升至87%,Claude-3.5-haiku从69%提升至93%。相比之下,Qwen-2.5-14B仅获得了有限的性能提升,主要原因在于其频繁出现工具调用错误,从而限制了汇总智能体生成准确答案的能力。最后,在多智能体设置下,GPT-4o实现了完美的性能,在react2enthalpy和react2gibbs两个任务中均达到了100%的成功率。
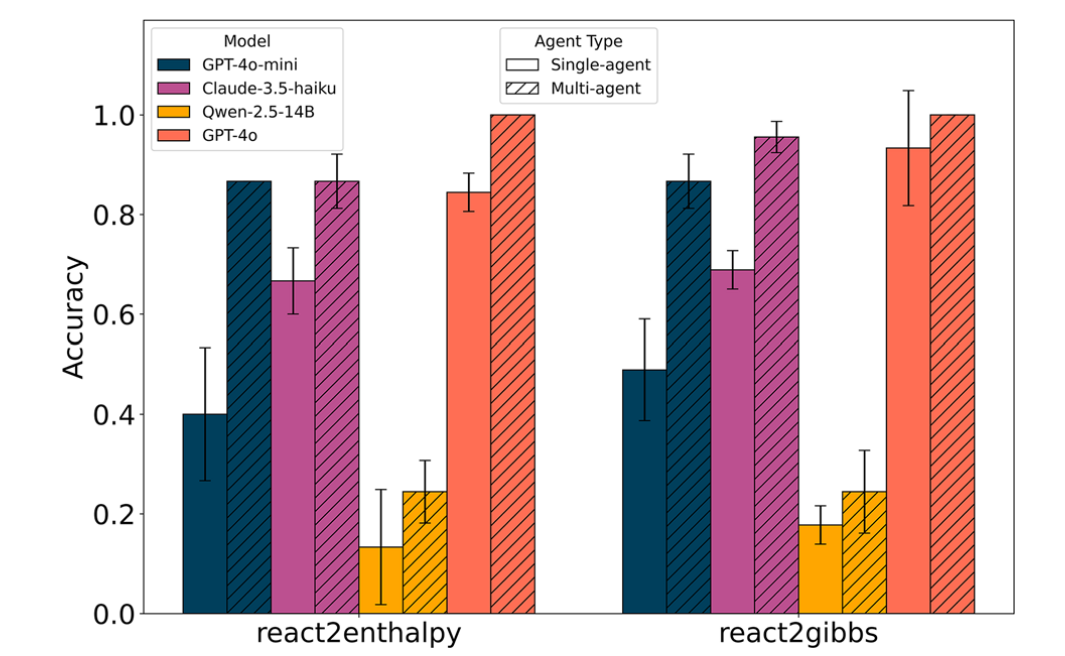
图8 多智能体与单智能体ChemGraph在react2enthalpy和react2gibbs任务中的平均准确率。
总结
本文介绍了一种由大语言模型驱动的代理式框架ChemGraph,旨在通过结构化的工具调用与推理机制,实现分子模拟工作流的自动化。在涵盖13项多样化任务的实验中对ChemGraph进行了评估,这些任务从简单的分子名称到SMILES的转换,到复杂的热力学性质计算等,结果表明,当前最先进的LLM能够以较高的准确率完成这些任务。
研究发现,单智能体系统在仅涉及少量工具调用的任务中表现稳定可靠;然而,在复杂工作流中,由于上下文窗口饱和,其性能会明显下降。为解决这一问题,作者实现了ChemGraph多智能体版本,将复杂查询分解为由不同智能体执行的更小子任务。该策略显著提升了整体准确率,尤其是在反应焓和吉布斯自由能计算等任务中,多智能体架构下的GPT-4o实现了完美准确率,而小型LLM的性能也获得了大幅提升,甚至在某些情况下超过了大型模型在单智能体设置下的表现。
ChemGraph的另一项关键优势在于其模块化设计以及与ASE式计算器的良好兼容性,从而能够集成多种模拟后端。通过执行基于DFT、紧束缚方法以及最先进机器学习势能的工作流,展示了ChemGraph的高度灵活性,体现了其在不同计算方法之间进行快速测试与基准评估方面的潜力。通过将ChemGraph与快速且高精度的机器学习势能相结合,实现了交互式、由自然语言驱动的分子模拟,为高效而精确的化学空间探索提供了有力支持。
参考链接:
Pham, T.D., Tanikanti, A. & Keçeli, M. ChemGraph as an agentic framework for computational chemistry workflows. Commun Chem 9, 33 (2026).
https://doi.org/10.1038/s42004-025-01776-9
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢