

论文链接:
https://arxiv.org/abs/2601.19773
代码仓库:
https://github.com/NanshineLoong/EID-Benchmark
引言
当我们向医生咨询时,是一股脑说出所有不适,然后等待一个“最终结论”,还是在一问一答中逐步澄清、层层深入?
在现实世界中,医疗诊断本质上是一个高度动态且交互的过程。患者最初往往只能提供模糊、零散的主诉与症状线索,医生则需要通过多轮追问与检查选择,逐步补全关键信息,形成可验证的证据链,并在信息不断更新的过程中校正假设、收敛结论。
然而,当前许多大模型在医疗任务上的评测仍停留在“静态问答”范式:默认所有患者信息一次性完备呈现,模型只需基于完整输入进行一次性推理并给出诊断。在这一设定下,模型表现更多反映的是“在证据已给定时能否推理正确”,却难以揭示更贴近真实问诊的关键问题:当诊断失败时,究竟是因为模型未能主动获取关键证据而导致信息不足,还是在证据已相对充分的情况下仍出现推理偏差。
因此,证据搜集(Evidence Elicitation)应被视为医疗大模型能力评估中的核心环节:模型不仅需要“会推理”,还需要“会提问、会查证”,能够识别信息缺口并采取有效的追问与检查策略,避免因证据不全而产生不可靠结论。
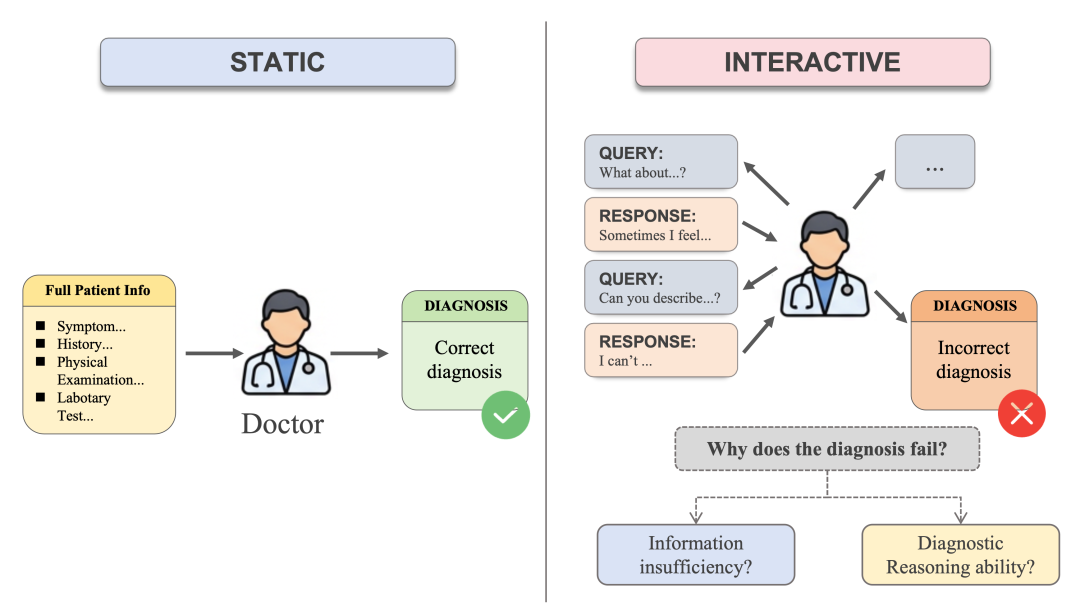
图 1:静态评估与交互式评估对比。 静态评估中模型一次性接收完整信息后直接诊断;交互式评估中模型需多轮问询与检查主动获取证据,并可在失败时区分“信息不足”与“推理不足”两类原因。
基于此,本工作旨在推动大模型在医疗问诊的评估从静态的“一次性问答”走向动态的“交互式诊断”,并将证据搜集能力作为核心评测对象:不仅关注模型最终是否给出正确结论,也关注其在多轮交互中能否定位信息缺口、提出有效追问、主动获取关键证据,并据此构建支撑诊断的证据基础。
在这一评估视角下,我们观察到:
(1)诊断推理能力较强的模型,并不一定在交互过程中具备同等水平的证据搜集能力;相反,一些规模较小、推理能力相对有限的模型,却能够在多轮问询中更有效地获取关键信息。
(2)将证据搜集与诊断推理在流程上分离,并在二者之间引入显式的诊断验证机制,能够显著改善整体诊断表现。进一步在不同阶段使用与能力需求更匹配的模型,例如由交互能力更强的模型负责证据采集,由诊断能力更强的模型负责推理与验证,往往能够取得优于只使用单一强模型的效果。
交互式问诊评估框架
为了解决现有评估方法的局限性,我们首先设计了一个交互式问诊评估框架。该框架旨在模拟真实的临床问诊流程,其核心在于评估模型主动获取信息的能力,而不仅仅是最终的诊断准确性。
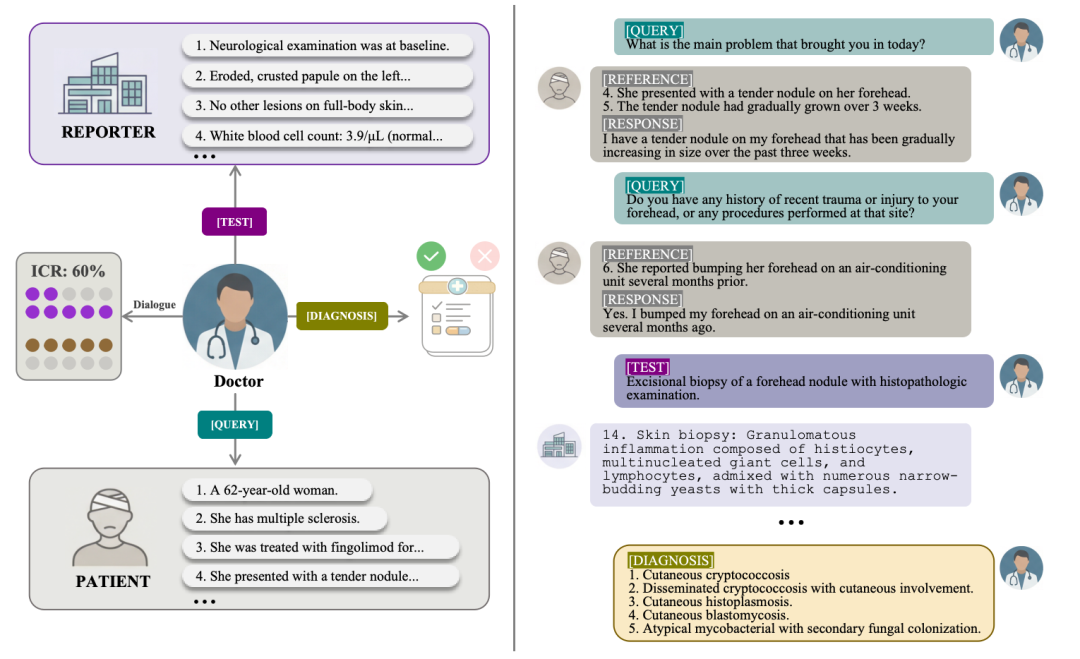
图 2:交互式评估框架示意图。左图展示医生智能体在对话中与模拟患者、模拟报告员交互以逐步获取证据,并在过程中计算信息覆盖率(ICR)和诊断成功率;右侧则是一个具体的咨询轨迹案例,展示了从提问、证据回应到最终诊断的全过程。
核心角色组成
我们的框架包含三个关键角色:
医生智能体 (Doctor Agent):即被评估的大语言模型,它需要决定是继续提问、请求检查,还是给出最终诊断。
模拟患者 (Simulated Patient):根据真实的病例信息,以自然语言的方式回应医生的提问,提供主观症状和病史。
模拟报告员 (Simulated Reporter):提供客观的临床检查和实验室测试结果。
关键评估指标:信息覆盖率 (ICR)
为了量化模型主动获取信息的能力,我们引入了一个核心评估指标:信息覆盖率 (Information Coverage Rate, ICR)。它衡量的是模型在交互过程中,成功收集到的相关证据占全部证据的比例。
具体来说,对于每一个病例,我们都预先定义了诊断该疾病的相关证据集。ICR 的计算方法是将模型在交互中实际收集到的证据与这个标准答案进行比较。计算公式如下:
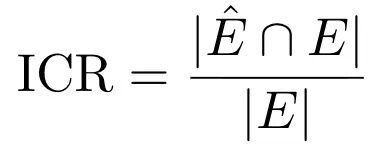
其中,E表示该病例的必要证据集合,E ̂表示模型实际收集到的证据集合。
EviMed-1K 数据集构建
为支撑交互式问诊评估框架,我们构建了大规模、多样化的基准数据集 EviMed-1K。该数据集整合五个互补来源,覆盖从全科医学、专科诊断到罕见病诊断等多类临床场景,共计 1000 个样例。为适配交互模拟与信息覆盖率计算,我们进一步将原始的病例描述自动转化为由一系列最小化、自包含的“原子证据”组成的数据表示,使得模型在多轮问询与检查中获取到的证据能够被追踪与量化。
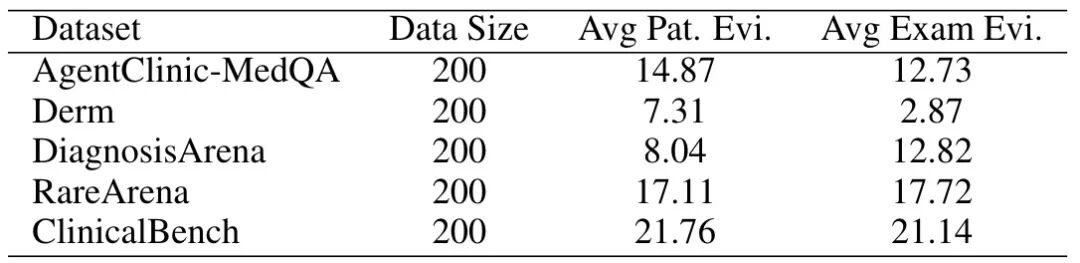
表 1:EviMed-1K 统计概览。“Avg Pat. Evi.” 表示每例平均的患者侧证据数量。“Avg Exam Evi.” 表示每例平均的检查/化验等客观证据数量。
REFINE问诊策略
为提升模型在交互式问诊中的证据搜集能力,我们提出一种反馈驱动的问诊策略 REFINE(Reasoning-Enhanced Feedback for INformation Elicitation)。与“收集若干信息后直接给出结论”的流程不同,REFINE 在决策链中显式加入诊断验证(diagnosis verification)环节:模型先基于当前证据形成诊断假设,再通过验证器检查证据是否充分、缺口在哪里,并将结构化反馈回传,从而形成“提出假设—发现缺口—定向追问”的闭环,指导后续更有效的信息获取。
REFINE 由四个相互协作的模块组成:
信息收集器 (Information Collector):与评估环境交互,按轮次提出追问或请求检查,获取初步证据。
证据总结器 (Evidence Organizer):将多轮交互中获得的零散信息整理为结构化的证据摘要,便于后续推理与核验。
诊断推理器 (Diagnosis Reasoner):基于当前的证据摘要,提出一个初步的诊断假设。
诊断验证器 (Diagnosis Verifier):对诊断假设进行一致性与充分性检查,判断现有证据是否足以支撑该结论;若不足,则生成明确反馈(如缺失的关键证据类型、需要澄清的不确定点等),并将反馈传回信息收集器,驱动下一轮更有针对性的追问与检查选择。
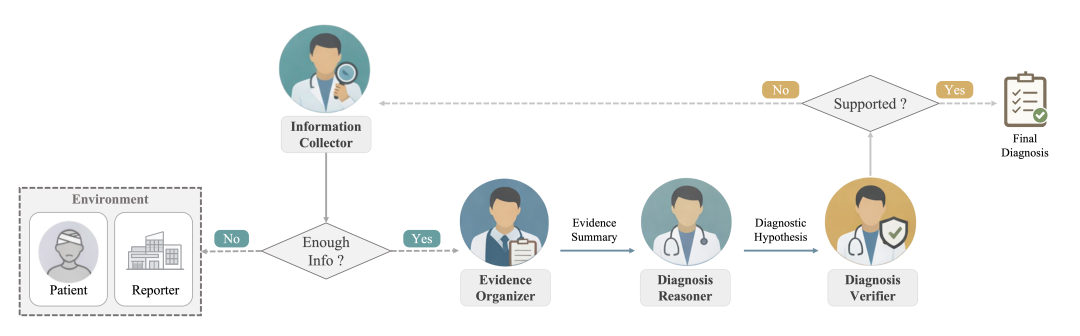
图 3:REFINE 策略概览。 该策略通过引入诊断验证器,形成了一个“信息收集-整理-推理-验证”的反馈闭环,使智能体能够主动识别并弥补信息缺口,优化证据搜集过程。
实验结果
实验设置
我们选取了 10 个覆盖闭源与开源、不同规模与能力梯度的大模型,在 EviMed 上进行评测。评测包含两种设置:
静态上限(Static Upper Bound, UB):一次性提供完整患者信息与检查结果,模型直接输出诊断,用于刻画“信息完备时的推理上限”。
交互评估(Interactive):模型需要在多轮问询/检查中主动获取证据,并在过程中计算 信息覆盖率 ICR 与最终 诊断成功率 SR。在交互设置下,我们进一步比较了多种策略(Baseline、ReAct、SC,以及本文提出的 REFINE)。
Finding 1:
会推理≠会搜集关键证据
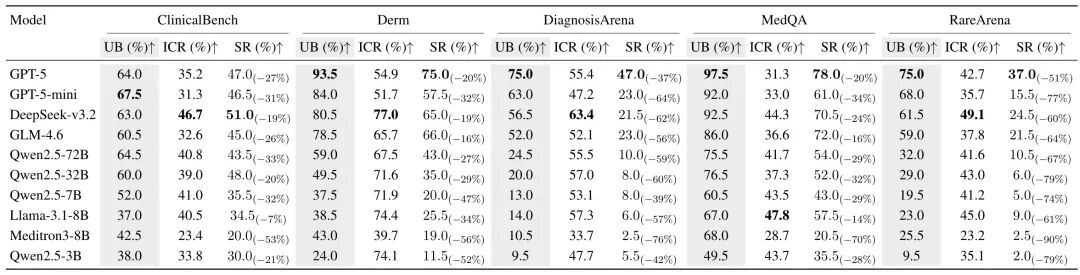
表 2: 静态上限(UB)与交互基线(Baseline)结果对比。 UB 为静态设置下的诊断成功率;交互基线给出信息覆盖率(ICR)与 SR,并标注了 SR 相对 UB 的下降幅度。
实验首先证实了静态评估与交互式评估之间的性能差异。几乎所有模型在从静态转向交互式环境时,诊断成功率都出现了显著下降。像 GPT-5 这样推理能力极强的模型,虽然在静态环境下表现优异,但在交互环境中的信息搜集效率(ICR)却并非最高,这表明强大的推理能力并不能直接转化为高效的证据搜集能力。
Finding 2:
优化问诊策略能同时提升 ICR 与 SR
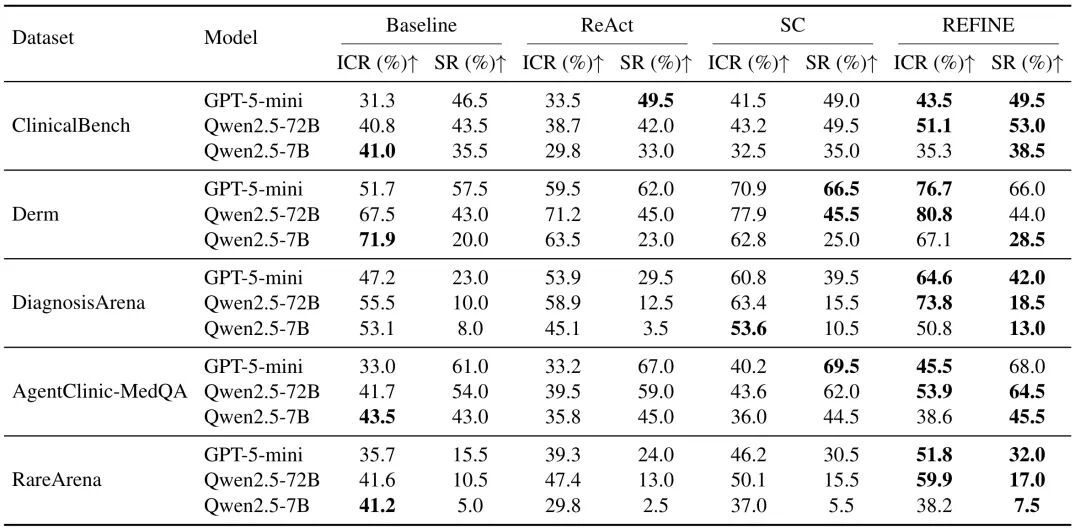
表 3: 不同问诊策略在交互评估下的表现对比。 对比 Baseline、ReAct、SC 与 REFINE 的 ICR/SR。整体上,REFINE 在多数模型与数据集上取得最高 ICR,并带来显著 SR 提升,尤其在罕见病相关数据集上更明显。
在交互评估中,策略差异会直接改变模型的交互行为。整体趋势显示出更有效的证据搜集往往带来更高的诊断成功率,但不同策略的稳定性差异明显。
ReAct 通过显式的“思考—行动”循环强化每步决策,但在较弱模型上可能出现 ICR 与 SR 同时下降,这可能是因为“更长的多轮轨迹”会带来对话冗长与决策扰动。
SC(Summarized-Conversation) 将“证据搜集”和“最终诊断”解耦:先完整问诊收集,再基于结构化总结诊断,整体上更稳定地提升 ICR 与 SR。
REFINE 在多数模型与数据集上取得最高 ICR,并显著提升 SR。尤其在 DiagnosisArena 与 RareArena 这类更具挑战的数据集上提升更突出,说明“验证—反馈—再追问”的闭环机制对难病例更有效。
Finding 3:
ICR 与 SR 总体正相关,但不完全一致
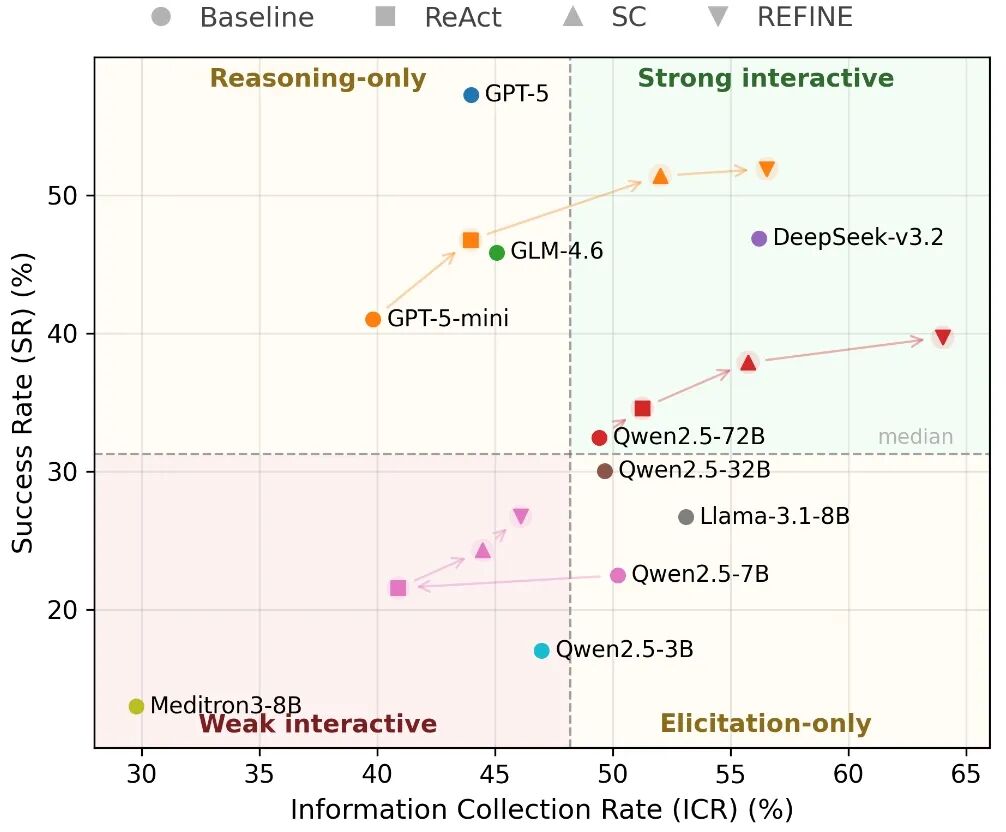
图 4: 交互评估下 ICR 与 SR 的关系。 每个点表示一个模型或策略变体在五个数据集上的平均表现。整体上 SR 随 ICR 增长而提升,但不同模型系列存在系统性偏离,体现出证据搜集能力与诊断推理能力的部分解耦。
为了更好地理解“证据搜集能力”和“诊断推理能力”之间的关系,我们对所有模型及其策略变体在交互评估下的 ICR–SR 进行了散点分析
整体来看,SR 通常随 ICR 的提升而上升。例如,从 GPT-5-mini 到 GLM-4.6,再到 DeepSeek-v3.2,以及从 Meditron3-8B 到 Llama-3.1-8B,这说明“覆盖更多关键证据”往往能够带来更高的诊断成功率。
然而,这种关系并非在所有模型上都严格成立。例如GPT-5 系列往往具有较高的 SR,但 ICR 相对较低;而 Qwen2.5 系列则表现出更高的 ICR,却对应较低的 SR。这表明证据搜集能力与诊断推理能力虽然整体相关,但在不同模型中仍呈现出部分解耦的特点。
从策略角度看,大多数方法在提升 ICR 的同时也同步提升了 SR,这说明增强模型的信息获取能力,通常是提升整体诊断成功率的有效路径。
Finding 4:
角色匹配的模型协作显著提升整体性能
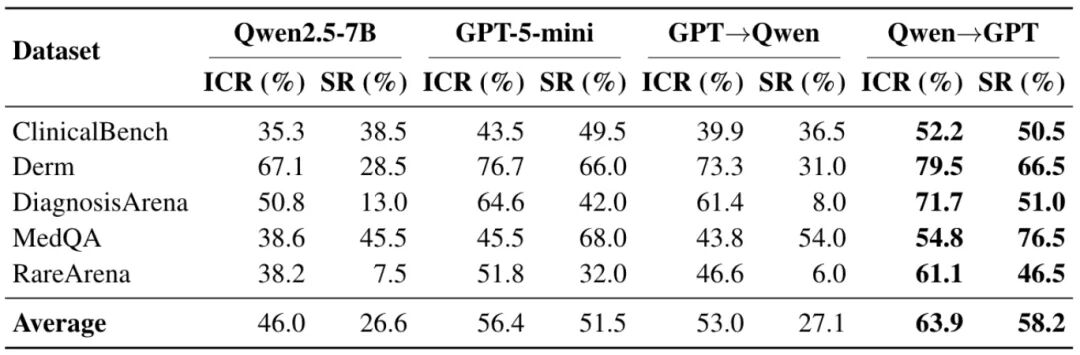
表4:记 M1→M2为用 M1充当信息收集器(Collector),用 M2负责组织、推理与验证(Organizer/Reasoner/Verifier)。结果显示,当模型优势与角色需求匹配时,可同时提升 ICR 与 SR;反向配对则可能显著退化。
基于前一节中 GPT-5 系列与 Qwen2.5 系列在 ICR 与 SR 上的能力错配,我们进一步探索了 角色匹配的模型协作。在 REFINE 框架下,我们将 Qwen2.5-7B 作为信息收集员,而将 GPT-5-mini 作为证据组织、诊断推理与验证模块(Qwen→GPT),并以相反的角色分配(GPT→Qwen)作为对照。
实验结果如表所示,Qwen→GPT在所有数据集上同时取得最高的 ICR 与 SR,并在 DiagnosisArena 与 RareArena 等高难场景中,相较单一 GPT-5-mini 也获得了显著提升。相反,GPT→Qwen的表现则整体劣于单一 GPT-5-mini:其 ICR 在多个数据集上的 SR 甚至低于单一 Qwen2.5-7B。
这些结果表明模型协作只有在能力与角色需求相匹配时才会产生互补增益。这种策略提供了一种更具成本效益的部署路径:将高频的问询任务交由“会问”的轻量模型,而将低频但关键的推理与验证交由强诊断模型完成。
总结
本工作系统性地揭示了在交互式医疗诊断中,证据搜集(evidence elicitation)是长期被低估却直接影响诊断可靠性的关键环节。围绕这一问题,我们提出了交互式问诊评估框架,并设计了由反馈驱动的 REFINE 策略,为评估与提升大模型在多轮问诊中的信息获取能力提供了更可操作的工具与路径。
实验结果进一步表明,优秀的诊断智能体并非仅依赖单一维度的“强推理”。更准确地说,诊断推理与证据搜集是相互支撑、共同发挥作用的两个环节:证据搜集决定模型能否获得足以支撑判断的关键信息,推理能力决定模型能否在已获得信息的基础上进行有效整合与决策。任何一环薄弱,都可能使系统在真实交互环境中表现受限。因此,未来研究需要从“信息完备前提下的静态问答”进一步走向对动态交互、缺口识别、定向追问与闭环验证等能力的系统训练与评估。
本研究仍存在局限性。当前评估建立在可控的模拟环境之上,与真实临床实践在信息噪声、多源数据融合、检查可得性与成本约束等方面仍有差距;将临床信息抽象为“原子证据”也在一定程度上简化了症状表述的多样性与病程演化的复杂性。尽管如此,我们希望这项工作能为理解交互式诊断中“问什么、何时问、问到何种程度”的关键问题提供更清晰的刻画框架,并为构建更接近临床工作方式的医疗智能体奠定基础。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区袁天凡、慧敏校园C栋

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢