

项目资源
代码链接:
https://github.com/RaidonWong/CURP_code
论文链接:
https://arxiv.org/pdf/2602.00742
Demo链接:
http://www.fudan-disc.com/Persona-CURP
引言:
当我们真的开始“大规模模拟一个具体的人”
个性化正在变得越来越重要。
在社会模拟、政策评估、医疗决策测试等场景中,我们不再满足于“模型能回答问题”,而是希望模型能够模拟规模化的不同个体在同一问题下的反应,从而了解大众对特定话题的真实想法。
举个例子:
我们评估“是否放宽医疗监管”,设定两位个体:
40 岁女性,教师,高宜人性,外向型
35 岁男性,工程师,高责任心,内向型
看似个性化,但实际运行中会暴露两个问题:
精细化不足 与 多样化不足
核心问题一:精细化不足
现实个体是多维、连续的,但建模时往往只依赖:少量标签,文本 persona 描述或简单参数注入。结果是:差异停留在标签层面,容易产生刻板印象,复杂问题上的行为差异有限。
无论是文本拼接还是模型微调,本质上都缺少结构化的个体表示。
核心问题二:多样性不足
问题在规模化时更加明显。如果我们希望模拟一次真正的社会调查,不是 2 个人,而是 10 万人—— 我们需要的不是几种“典型 persona”,而是:
连续、丰富、分布合理的个体差异。
但现实中,文本 persona 依赖有限标签集合,差异空间被压缩,增加标签数量,只是简单组合扩展,模型微调若走向逐个用户微调,成本迅速上升。结果导致,要么回答高度相似,难以反映真实多样性;要么差异可以表达,但无法规模化维护。
在社会模拟场景下,这意味着很难生成足够丰富、结构合理的群体行为分布。
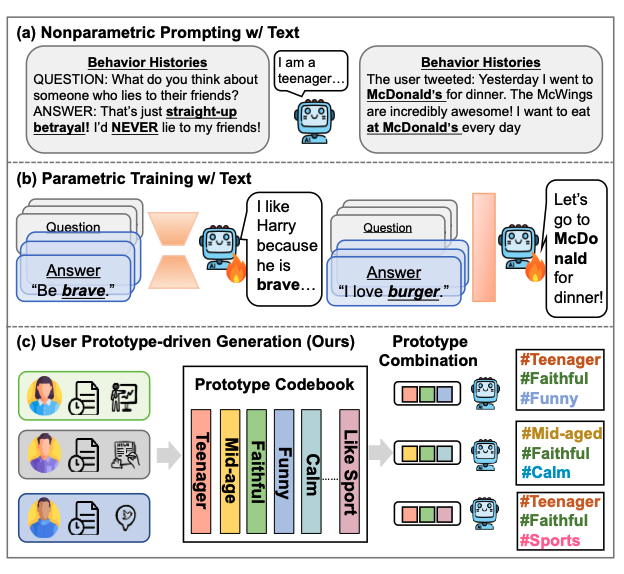
图一:进行用户模拟的两种主要范式和我们的框架
我们真正缺的是什么?
从这个例子可以看到,问题的根源并不在模型大小,而在:
个体差异是如何被表示的。
如果个体表示本身是非结构化的,
那么无论拼接文本还是增加参数,都只是表层修补。
我们需要的,是一种新的基础设施:
能精细表达个体差异
能支持大规模多样化
又不依赖 per-user 模型复制
理论支持:人不是一个“固定标签”
在重新设计个体表示之前,我们先回到一个更基础的问题:
个体差异本质上是什么?
社会心理学中的自我分类理论(Self-Categorization Theory, SCT) 给出了重要启发。
SCT 认为:
个体身份并非一个固定标签,而是在不同情境下,由多个社会原型(prototypes)组合形成。
例如,一个人可能同时具备:
#Teacher
#CommunityOriented
#RiskAverse
#Calm
#HighResponsibility
这些原型不是孤立标签,而是可以组合、叠加、动态变化的行为单元。
换句话说:
个体不是一个标签,而是多个共享原型的组合体。
这为个性化建模提供了一个关键启发:
与其为每个用户单独建模,不如在一个共享原型空间中表示所有个体。
CURP:用原型码本重构个体表示
基于这一视角,我们提出 CURP,用原型码本重构个体表示。
核心思想很简单:不再把用户历史当作长文本拼接,而是将其抽象为可组合的原型单元。
整体结构包括:
User Encoder:提取稳定行为特征
Prototype Codebook:将特征映射为离散原型组合
冻结的 LLM:基于原型完成生成
为什么“原型码本”同时解决两个问题?
① 解决多样化与规模化问题
所有个体共享同一套原型空间
所有数据被训练到统一参数结构中
差异来自“原型组合”,而不是“独立模型”
因此,多样性在统一空间中自然扩展,不需要 per-user 模型复制。
② 解决精细化问题
原型是离散且可组合的维度
不同语义维度可以被分解
差异可以在局部层面调节
相比粗粒度 persona 描述,这种结构更接近可精细控制的坐标系。
模型结构:让“用户”变成可组合的结构表示
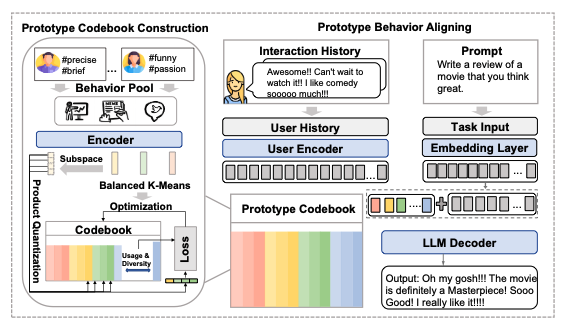
图二:CURP的主要模型框架
① User Encoder:把“杂乱历史”压缩成可计算表示
真实的用户历史通常是:
长
分散
风格不稳定
含有大量无关噪声
如果直接拼接进 prompt,模型会面临两个问题:
上下文被迅速占满
无法自动提取稳定的用户特征
因此,第一步我们引入一个双向编码器(例如 Contriever),专门负责阅读用户历史。
它做的事情不是生成,而是理解——
把每条历史行为编码成向量表示,再通过 mean pooling 得到紧凑的历史特征。
这一阶段的目标可以概括为:
从“文本记录”中提炼出“行为特征”。
但到这里,我们还没有完成真正的用户建模。因为连续向量仍然是黑盒的、不稳定的,也不具备可解释性。
② Prototype Codebook:把连续向量变成“原型组合”
这是 CURP 的核心设计。
我们不直接使用连续 embedding,而是把它们映射到一个共享的原型空间中。
具体来说,我们基于约 15 万用户、2400 万条历史行为,构建了一个包含 1000 个原型的 codebook。每条历史行为会通过 Product Quantization 被拆分成 4 个子空间,并在每个子空间中选择一个最相近的原型索引。
于是,一条历史行为不再是一个难以解释的向量,而是:
4 个离散原型的组合。
可以理解为:
模型从大规模用户数据中自动学习出一组“典型行为模式”,而每个用户都可以由这些模式的组合来表示。
为什么要这么做?
因为离散原型有三个优势:
提升结构化表达能力
减少噪声干扰
便于分析和解释
为了避免原型塌缩(只使用少数原型),我们在训练中加入了三个约束:
Lquant 保证量化后仍接近原始表示
Ldiv 保持原型之间的差异性
Lusage 促进所有原型被均匀使用
最终得到一个稳定、可泛化的“用户原型库”。
这一阶段解决的是:
如何构建一个共享、可扩展的用户表示空间。
③ LLM Decoder:在冻结状态下完成个性化生成
有了用户的原型表示之后,最后一步才是真正的生成。
我们将量化后的原型 embedding 通过一个小型 MLP 映射到 LLM 的 embedding 空间,然后与当前任务的 query 拼接,一起输入到冻结的 LLM Decoder中。
这里有两个关键点:
第一,LLM 是完全冻结的。
第二,我们只训练约 2000 万参数的对齐模块。
在一个 8B 模型中,这只占大约 0.2%。
也就是说,我们没有:
为每个用户单独训练 LoRA
修改 LLM 内部权重
复制模型实例
而是通过结构化原型指导生成。
最终的生成流程是:
用户历史 → 编码 → 原型量化 → 映射 → 拼接问题 → 冻结 LLM 输出答案
这种设计实现了真正的:
plug-and-play personalization
两阶段训练:先“学原型”,再“学对齐”
为了让这套结构稳定工作,我们把训练拆成两个阶段。
Stage I:
Prototype Codebook Construction(PCC)
目标是构建一个通用、可迁移的用户原型空间。
这一阶段完全独立于具体任务,重点是从大规模用户行为中抽象出稳定原型。
可以理解为:
先建好“词汇表”,再让模型学会怎么用。
Stage II:
Prototype Behavior Aligning(PBA)
在有了原型空间之后,我们训练对齐模块,让模型学会:
如何将原型映射到 LLM 表达空间
如何利用原型辅助生成
此时,模型真正学到的是:
如何根据结构化用户表示生成个性化内容。
而不是单纯地模仿历史文本。
实验结果:性能与效率的平衡
我们在四类具有代表性的个性化生成任务上进行了系统评测,包括 Reddit 问答(开放式回答)、新闻标题生成(可控生成)、推文改写(风格迁移)以及商品评论写作(长文本生成)。这些任务覆盖了不同长度、不同场景和不同个性化强度的需求。对比方法方面,我们既考虑了 Prompt-based 方法(如 Zero-shot、ICL、RAG、Persona 生成等),也比较了 Training-based 方法(如 LoRA、Soft Prompt、PPlug、OPPU 等),从“纯提示”到“参数微调”两类主流技术路线进行全面对比。
在此基础上,我们重点关注两个问题:模型效果如何,以及为此付出了多少参数成本。
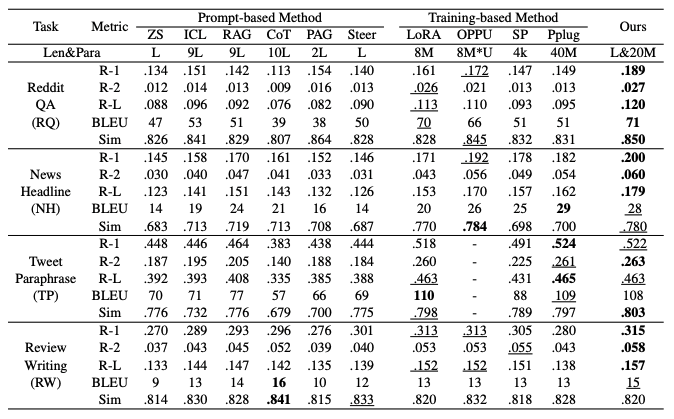
表1:主要实验结果
主实验结果总结
整体性能领先:在四个任务的大多数指标上,CURP 均取得最优或并列最优表现,尤其在开放式生成任务上优势更明显。
显著优于纯 Prompt 方法:相比 ICL、RAG 等方法,CURP 在避免长上下文噪声的同时,获得更稳定、更准确的个性化效果。
接近甚至超过重训练方法:在不进行 per-user 微调的情况下,性能接近或超过 LoRA、OPPU 等训练型方法。
参数效率极高:CURP 仅训练约 2000 万共享参数(约占 8B 模型的 0.2%),无需为每个用户单独训练模块,实现了性能与效率的良好平衡。
简而言之:
我们在几乎不增加模型规模的前提下,实现了更强、更稳定的个性化生成能力。
消融与分析实验
消融实验:原型量化真的必要吗?
一个自然的问题是:
如果直接使用连续用户 embedding,而不做离散原型量化,会发生什么?
为此,我们移除了 codebook,将用户历史的连续表示直接用于生成,对比完整的 CURP 框架。结果如表二和图三所示:
实验结果显示:
整体性能变化并不显著,说明量化并没有明显损失关键信息;
但引入原型后,表示更加结构化,表达区分度更清晰;
模型在稳定性与鲁棒性方面表现更优。
这说明,codebook 的价值并不仅仅体现在指标提升上,而是在于:
在不牺牲性能的前提下,提供更清晰、更可控的用户表示结构。
更重要的是,离散原型带来了一个连续 embedding 难以具备的优势 —— 隐私保护与云端协同能力。
在连续表示方案下,往往需要传输完整的用户 embedding,甚至原始历史文本。而在 CURP 中,用户历史被压缩为少量离散原型索引,这些索引本身是不可逆的,无法还原原始文本内容。
这意味着:
用户端可以本地编码与量化
只需将原型索引上传至云端
云端 LLM 根据索引进行个性化生成
从系统层面看,这种设计天然支持云边协同架构,同时降低隐私泄露风险。
因此,消融实验告诉我们的不仅是:
Codebook 不会拖累性能,
更重要的是:
它在结构化表达、隐私保护与工程落地之间提供了一种更平衡的方案。
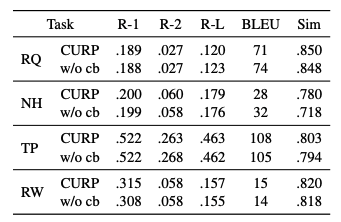
表二:消融实验
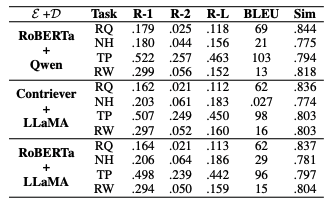
表三:泛化性实验
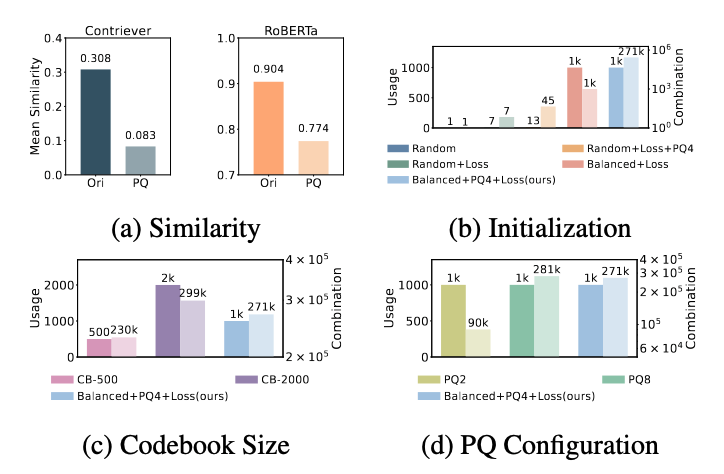
图三:codebook配置设计的影响
进一步分析:它为什么有效?
除了主实验和消融,我们还从多个角度分析了模型行为,试图回答一个问题:
CURP 为什么有效?它学到了什么?
①原型设计分析:更大就更好吗?
如图三所示,我们还分析了不同设计选择的影响,例如:
原型数量(更大词表是否更好?)
子空间数量(PQ2、PQ4、PQ8)
初始化方式(随机 vs 均衡)
结果显示:
合理规模即可达到最佳效果
盲目增加原型数量并不会显著提升性能
均衡初始化明显优于随机初始化
这说明:
有效的结构设计,比简单堆规模更重要。
② 可解释性分析:原型真的有语义吗?
一个关键问题是:
Codebook 学到的原型到底是不是有意义的?
如图四所示,我们在新闻标题任务中分析了不同子空间的原型索引,发现一个非常有趣的现象:
某些子空间始终对应“主题层面”的信息(例如同一政治人物)
某些子空间对应“内容类型”(新闻报道、娱乐调侃等)
还有子空间反映“情绪或立场”(中性、批评、讽刺等)
也就是说,不同子空间自动学到了层次化语义结构。
换句话说:
原型空间不是随机聚类,而是在分解“主题—风格—情绪”等不同维度。
这正是我们希望看到的结构化表达能力。
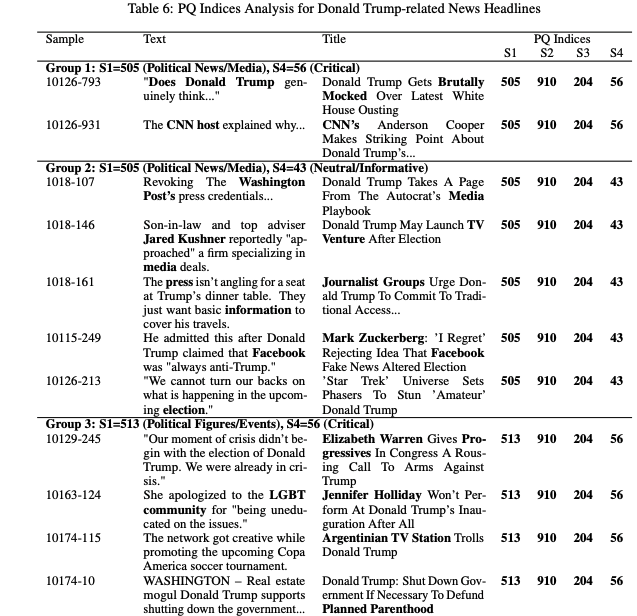
图四:可解释性分析
③历史数量分析:更多历史真的更好吗?
我们还测试了不同历史数量对性能的影响。
对 ICL 和 LoRA 来说:
历史越多,上下文越长
噪声越多,性能反而下降
但在 CURP 中:
性能随历史数量变化非常平稳
即使历史数量变化,模型依然保持稳定输出
原因很简单:
我们并不是直接拼接历史,而是先压缩为结构化原型表示。
这说明:
CURP 更具鲁棒性,也更适合真实场景中的不稳定数据量。
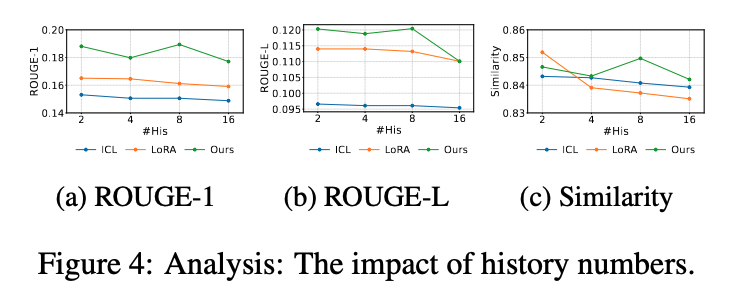
总结:
个性化的关键,不是更多历史,而是更好的表示
在大模型时代,个性化生成已经从“能不能做”走向“如何做好”。
传统做法要么不断往 prompt 里堆历史,要么为每个用户单独微调模型,前者噪声重、后者成本高。CURP 提供了一种不同的思路:
与其改模型,不如重构用户表示。
通过构建共享的原型 codebook,我们将用户从“冗长文本”抽象为“可组合结构”,再通过轻量对齐模块与冻结的 LLM 解耦结合,在几乎不增加模型规模的前提下,实现稳定、可扩展的个性化生成。
实验结果表明,这种结构化表示不仅带来更好的性能—效率平衡,也具备更强的泛化能力与可解释性;同时,离散原型天然支持云端协同与隐私保护,为真实部署提供了工程上的可行路径。
如果说 Prompting 太表层,Fine-tuning 太昂贵,那么 CURP 试图走出第三条路:
用结构化原型,让模型真正“理解用户”。
在个性化生成这件事上,表示方式,或许比模型规模更重要。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区袁天凡、慧敏校园C栋

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢