
【论文标题】Incomplete Utterance Rewriting as Semantic Segmentation
【作者团队】Qian Liu , Bei Chen, Jian-Guang Lou, Bin Zhou, Dongmei Zhang
【发表时间】EMNLP 2020
【论文链接】https://arxiv.org/abs/2009.13166
【公开代码】https://github.com/microsoft/ContextualSP
【推荐理由】本文提出一种全新的思路,将CV中的语义分割的方法用于不完整话语重写,提出了一个新颖的模型,并在数据集上取得很好的效果。
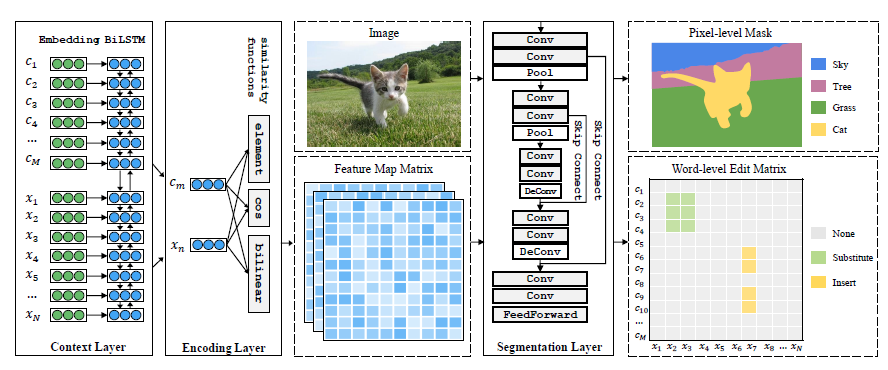 近些年单轮对话的理解已经取得了较大的进展,但多轮对话仍是学术界的一个难题。多轮对话的一大挑战就在于用户会抛出语义不完整的问题,如省略实体或者通过代词指代到对话历史中的实体。这样的挑战推动了上下文理解方向的研究工作,包括早期端到端的上下文建模方法,和近期研究者们所关注的不完整话语重写(Incomplete Utterance Rewriting)。不完整话语重写旨在将对话中语义不完整的句子重写为一个语义完整的、可脱离上下文理解的句子,以恢复所有指代和省略的信息。由于该任务的输出严重依赖于输入,已有工作绝大部分都是在复制网络的基础上进行改进。而微软亚洲研究院的研究员们另辟蹊径地将该任务视为一个面向对话编辑的任务,并据此提出了一个全新的、使用语义分割思路来解决不完整话语重写的模型。在本篇论文中,研究员们提出了一个使用语义分割思路来预测编辑过程的模型 RUN (Rewriting U-shaped Network)。与传统基于复制网络的生成模型不同,RUN 将不完整话语重写视为面向对话编辑的任务: 对话中的语句片段可以插入到某个位置,或替换某个片段。该模型在benchmark数据集上显示出出色的性能。
近些年单轮对话的理解已经取得了较大的进展,但多轮对话仍是学术界的一个难题。多轮对话的一大挑战就在于用户会抛出语义不完整的问题,如省略实体或者通过代词指代到对话历史中的实体。这样的挑战推动了上下文理解方向的研究工作,包括早期端到端的上下文建模方法,和近期研究者们所关注的不完整话语重写(Incomplete Utterance Rewriting)。不完整话语重写旨在将对话中语义不完整的句子重写为一个语义完整的、可脱离上下文理解的句子,以恢复所有指代和省略的信息。由于该任务的输出严重依赖于输入,已有工作绝大部分都是在复制网络的基础上进行改进。而微软亚洲研究院的研究员们另辟蹊径地将该任务视为一个面向对话编辑的任务,并据此提出了一个全新的、使用语义分割思路来解决不完整话语重写的模型。在本篇论文中,研究员们提出了一个使用语义分割思路来预测编辑过程的模型 RUN (Rewriting U-shaped Network)。与传统基于复制网络的生成模型不同,RUN 将不完整话语重写视为面向对话编辑的任务: 对话中的语句片段可以插入到某个位置,或替换某个片段。该模型在benchmark数据集上显示出出色的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢