
导读
食品与营养是人类生存与文化的基石,随着全球饮食文化日益复杂,对食品智能的需求不断增长。然而,通用大语言模型在处理多样化的食品主题和跨文化背景时面临挑战。为此,研究者提出了FoodSky,一个专门为烹饪与营养领域设计的领域特定大语言模型。该模型通过大规模食品语料库训练,并采用专门算法,旨在实现对食品数据的细粒度感知与推理。研究表明,FoodSky在专业考试中展现出专家级性能,为食品计算领域提供了新的基准。
研究背景
食品计算作为一个关键的跨学科领域,致力于利用从农田到餐桌的广泛数据实现食品智能。在食品计算的广阔领域中,烹饪与营养因其对人们健康的直接影响而成为两个关键主题。尽管已有研究探索了食材识别、食谱检索和营养评估等任务,并开始将大语言模型应用于饮食代理领域,但缺乏一个基础的、食品领域的专用大语言模型。这种缺失限制了在烹饪创新和饮食指导方面的进一步改进。受医学、教育、金融等领域专用大语言模型成功的启发,开发食品领域的基础模型成为可能。然而,构建这样的模型面临显著挑战:包括缺乏大规模、高质量的食品语料库;食品领域主题广泛且多样;以及食品的跨文化特性要求模型能够处理不同文化背景下的饮食知识。
研究亮点
设计了一个面向食品与营养专业知识的大语言模型FoodSky,专门处理食品领域任务。 建立了一个大规模、食品导向的指令数据集FoodEarth,用于模型训练,该数据集来源于权威知识图谱、政府数据库和学术资源。 提出了基于主题的选择性状态空间模型和分层主题检索增强生成算法,以增强模型对细粒度食品语义的理解和上下文感知的文本生成能力。 FoodSky在零样本设置下通过了中国国家厨师考试和营养师考试,设立了领域特定大语言模型在食品相关现实挑战中的新基准。
方法与关键结果
研究基于构建的FoodEarth数据集和提出的TS3M与HTRAG算法开发了FoodSky模型。TS3M旨在通过整合主题相关信息来增强模型准确性,其双分支架构能够捕获输入指令中主题与内容之间的语义关系。HTRAG则通过在推理过程中集成检索到的信息来增强生成能力,提供与上下文相关的知识以改善响应的准确性和信息丰富度。模型在厨师与营养师考试基准、食品长对话基准和食品问答基准上进行了广泛评估。在CDE-12K基准的零样本测试中,FoodSky模型在厨师考试和营养师考试上的准确率超越了所有基线通用大语言模型,展现了其领域专业性。在不同主题类别(如饮食科学、食品风味特征、食品安全措施、食品食谱、健康饮食原则)的评估中,FoodSky模型在所有类别上均一致优于基线模型。在食品长对话基准的问答任务中,FoodSky模型在BLEU、GLEU、ROUGE等多个自动评估指标上表现优异,表明其能生成更准确、相关的响应。此外,使用GPT-4作为评判者的主观评估进一步证实,FoodSky模型在生成流畅、逻辑、专业且信息丰富的回答方面具有优势。消融研究表明,TS3M和HTRAG组件各自独立地提升了模型性能,而它们的组合使用则带来了显著的协同改善。数据规模影响的实验则揭示了数据质量对于模型性能的重要性不亚于数据量。
研究结论
FoodSky作为一个面向食品领域的专用大语言模型,通过整合大规模食品语料训练和领域特定算法,成功解决了食品领域知识理解与推理的挑战。其核心贡献在于证明了领域特定大语言模型在专业任务上超越通用模型的潜力,特别是在通过权威职业资格考试方面。从方法学角度看,TS3M和HTRAG的提出为增强大语言模型的主题感知和知识检索能力提供了有效架构。该研究不仅推动了食品计算领域的发展,也为其他需要精确、深入知识的专业领域(如医学、法律、工程)开发专用大语言模型提供了可借鉴的蓝图。尽管当前模型仍受限于文本模态且依赖数据质量,但其展现出的性能为未来开发多模态食品模型、结合用户反馈进行强化学习以及整合更全面的健康数据以实现个性化饮食推荐指明了方向。FoodSky的成功标志着人工智能在赋能烹饪教育、促进饮食健康和支持食品行业创新方面迈出了坚实的一步。
图文赏析
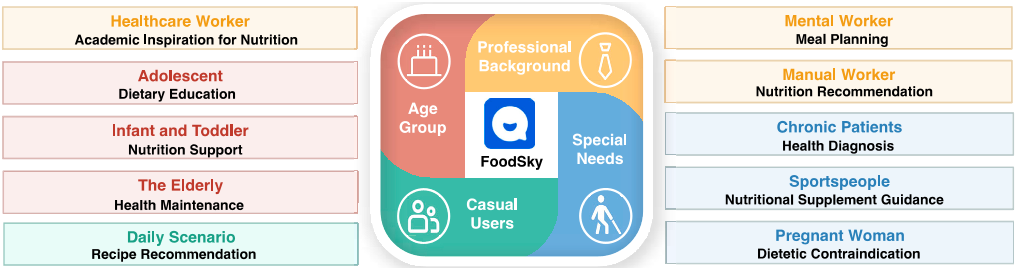
图1 所提出的食品导向大语言模型FoodSky在不同场景下对不同人群的潜在应用。
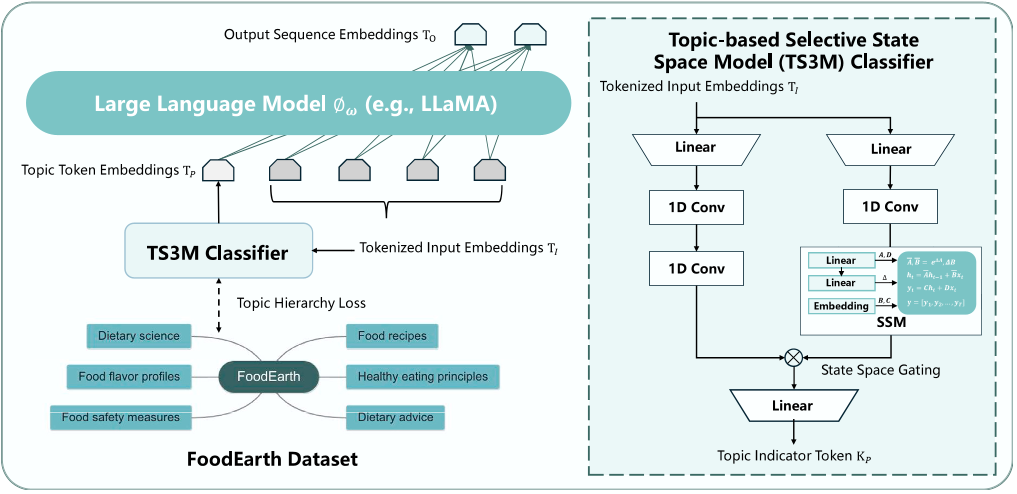
图2 所提出的FoodSky方法的核心模型。在推理过程中,分层主题检索增强生成模块使用主题指示符标记进行食品知识检索。
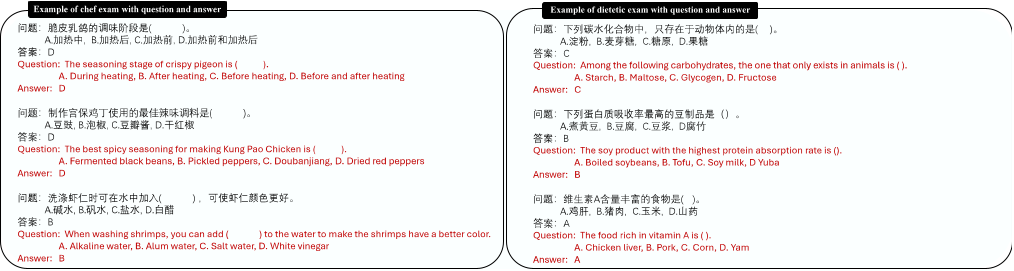
图3 CDE-12K基准中问题与答案的示例及相应的英文翻译。
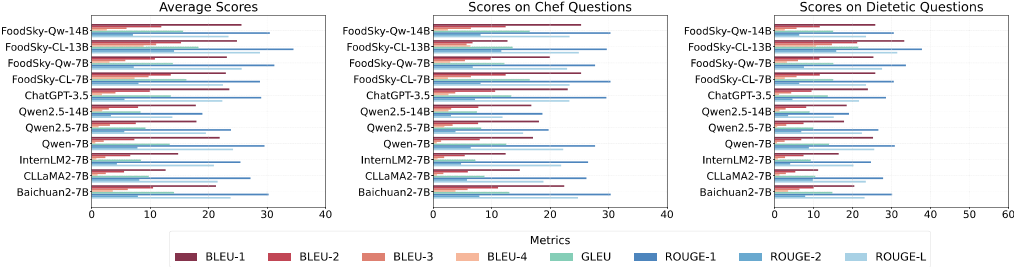
图4 不同模型在FoodLongConv基准上的性能比较(百分比)。
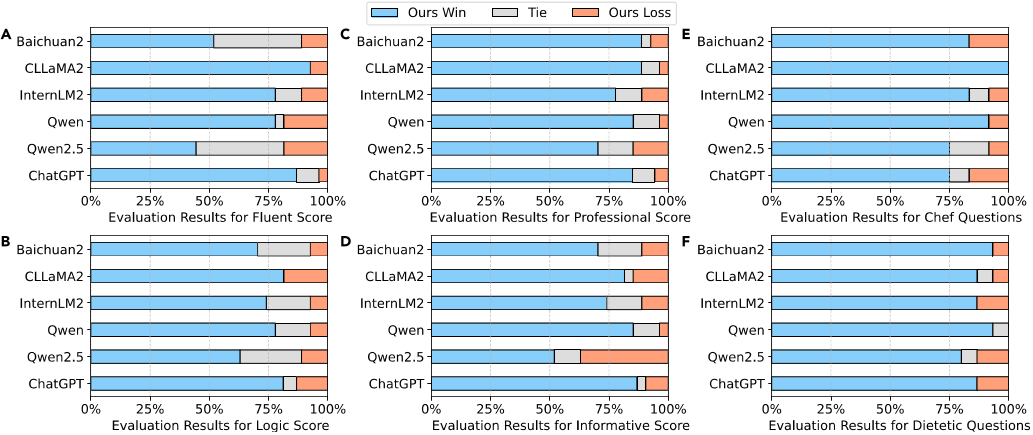
图5 FoodSky-Qw-7B与不同基线模型在FoodQA基准上由GPT-4评估的比较。GPT-4根据模型答案的质量给出流畅度、逻辑性、专业性和信息性评分,并判断每个评分上哪个模型胜出。报告了来自CDE问题的平均胜率。
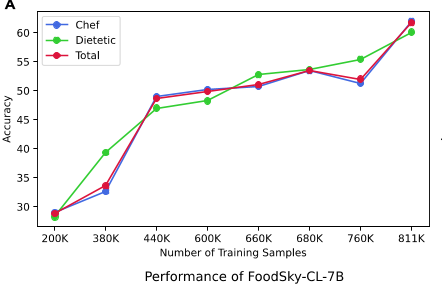
图6 训练集中指令数量的消融研究。结果报告为在CDE-739基准上的准确率,用于测试效率。
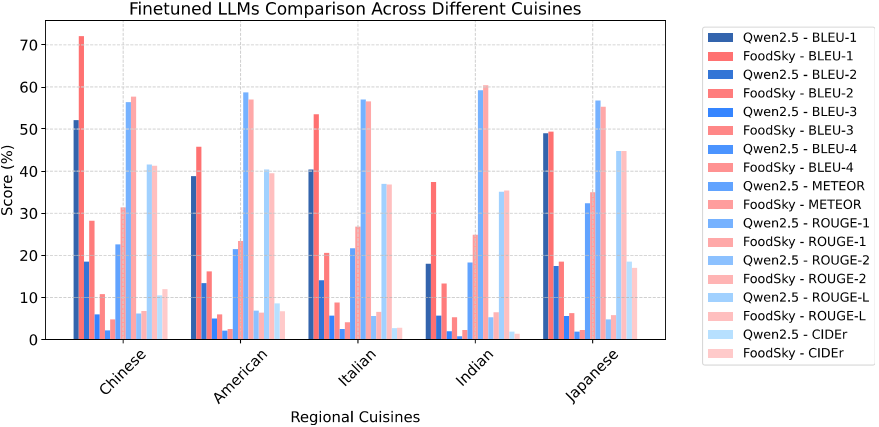
图7 在不同区域菜系上微调后的大语言模型比较。Qwen2.5和FoodSky-Qw-7B在每个菜系上进行了微调和测试。

图8 FoodSky、InternLM2和ChatGPT-3.5的问答可视化定性实验结果。虽然Intern和ChatGPT的输出相对冗余且缺乏重点,但我们的FoodSky的答案更加准确和简洁。
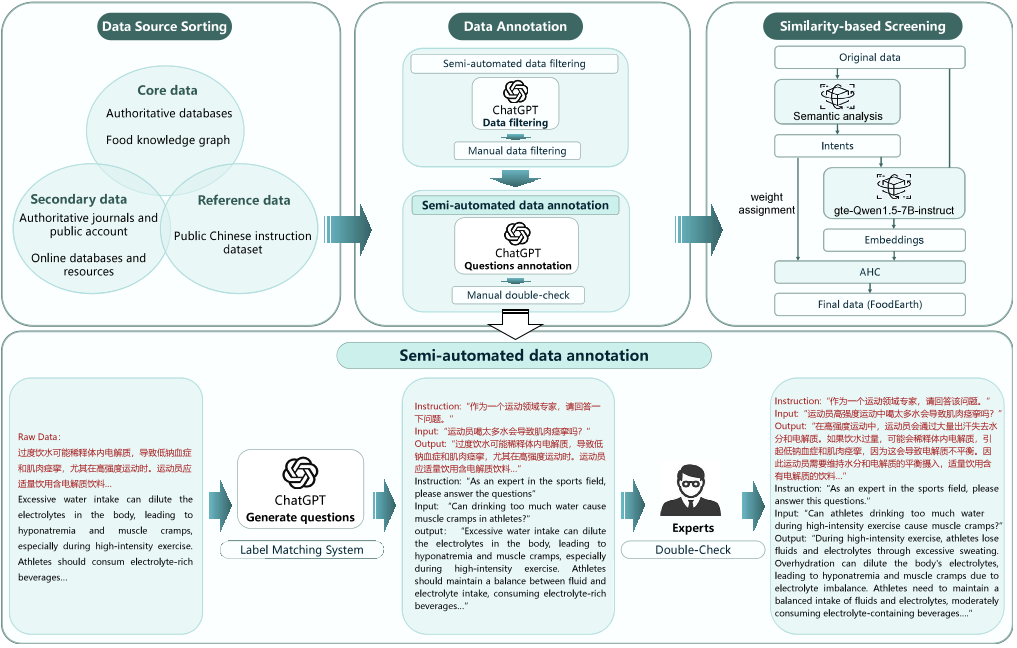
图9 建立FoodEarth的流程,包括数据源整理、数据标注和基于相似性的数据筛选。半自动数据过滤和半自动数据标注是数据标注的主要过程。AHC,凝聚层次聚类。
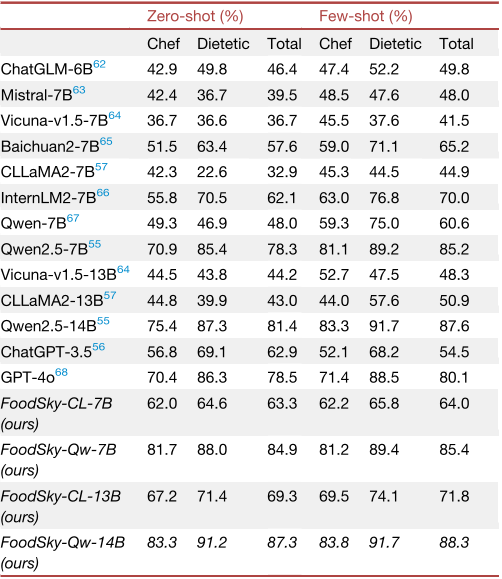
表1 不同大语言模型在CDE-12K基准上的零样本和少样本(5样本)性能,通过准确率评估。
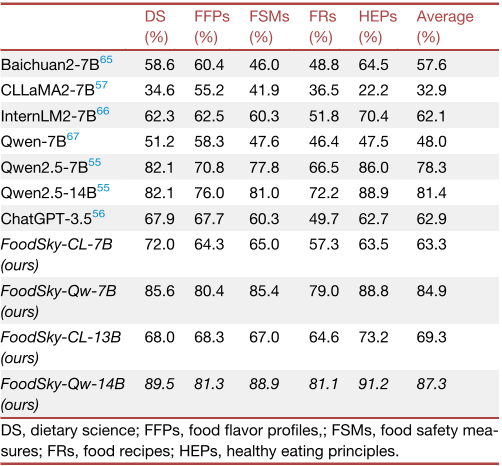
表2 不同模型在不同主题子类别上的零样本性能比较。
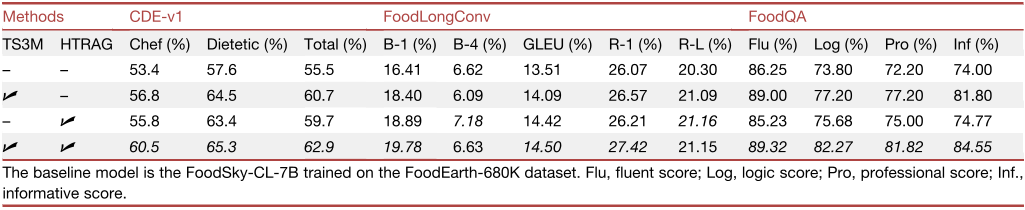
表3 FoodSky-CL-7B模型结构的消融研究。

表4 在FoodSky-CL-7B上比较RAG、RAFT和HTRAG的消融研究,该模型在FoodEarth-680K数据集上训练。

表5 每个数据源的数据量比例和数据内容。
原文链接
1. Zhou P, Min W, Fu C, Jin Y, Huang M, Li X, Mei S, Jiang S. FoodSky: A food-oriented large language model that can pass the chef and dietetic examinations. Patterns. 2025;6(5):101234.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢