
超大规模虚拟筛选(ULVS)的发展使得对数亿乃至数十亿级别化合物进行系统性评估,从中发现潜在苗头化合物成为可能。2026年1月27日,斯威本科技大学砂拉越校区与蒙纳士大学的研究人员在《Drug Discovery Today》上发表综述文章,题为“Hit identification in ultra large virtual screening: an integrative review and future challenges”,对该领域的最新进展进行了系统总结。

文章全面回顾了近年来ULVS的主要策略,涵盖基于结构的虚拟筛选、基于配体的虚拟筛选、基于药效团的方法、基于片段的方法以及混合式工作流程,这些方法通常与机器学习(ML)和深度学习技术相结合。诸如VirtualFlow、RosettaVS、Deep Docking和V-SYNTHES等平台,已在多种靶标类型中成功获得具有化学新颖性且经实验验证的苗头化合物。尽管取得了显著进展,ULVS仍面临评分函数准确性、计算资源效率以及方法泛化能力等方面的挑战。未来的ULVS将更加侧重于通过ML引导的优先级排序、基于片段的枚举策略以及考虑合成可行性的化合物库设计,实现更具选择性和自适应性的化学空间探索。
方法
基于结构的虚拟筛选SBVS
SBVS通过将化合物对接至蛋白质的三维结构中,并利用评分函数评估其结合构象与相互作用能量,从而识别潜在苗头化合物(图1)。在超大规模条件下,SBVS仍是唯一能够在数十亿个可合成化合物范围内显式建模蛋白–配体相互作用的筛选框架;但其有效性高度依赖于蛋白结构模型质量、计算规模、构象搜索算法、评分精度以及实验验证之间的平衡。
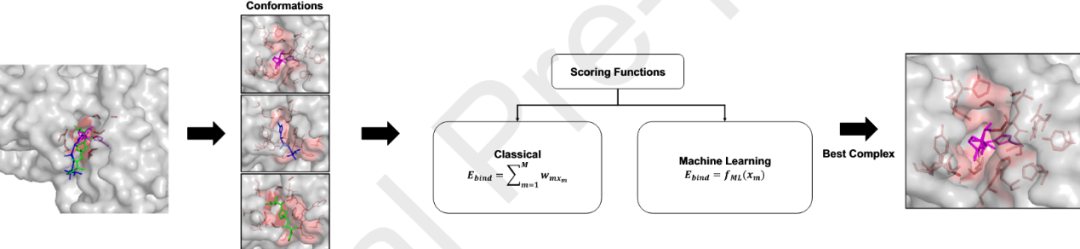
图1 基于结构的虚拟筛选SBVS的核心工作流程
SBVS方法可归纳为三大类策略:(1)规模驱动型流程:利用分布式或云原生计算资源,最大化化学空间覆盖;(2)准确性驱动型流程:对富集子集应用基于物理的精修方法;(3)ML增强型框架:通过数据驱动的优先级排序扩展经验评分体系。这些策略共同表明,现代SBVS已从单一评分函数的对接方法,演进为一种分层化、模块化的筛选范式,能够在超大规模化学库中实现高效且可靠的运行。
基于配体的虚拟筛选LBVS
LBVS基于这样一个基本假设:结构相似性通常与生物活性相关,通过利用已知活性化合物与候选分子之间的相似性来识别潜在苗头化合物(图2)。
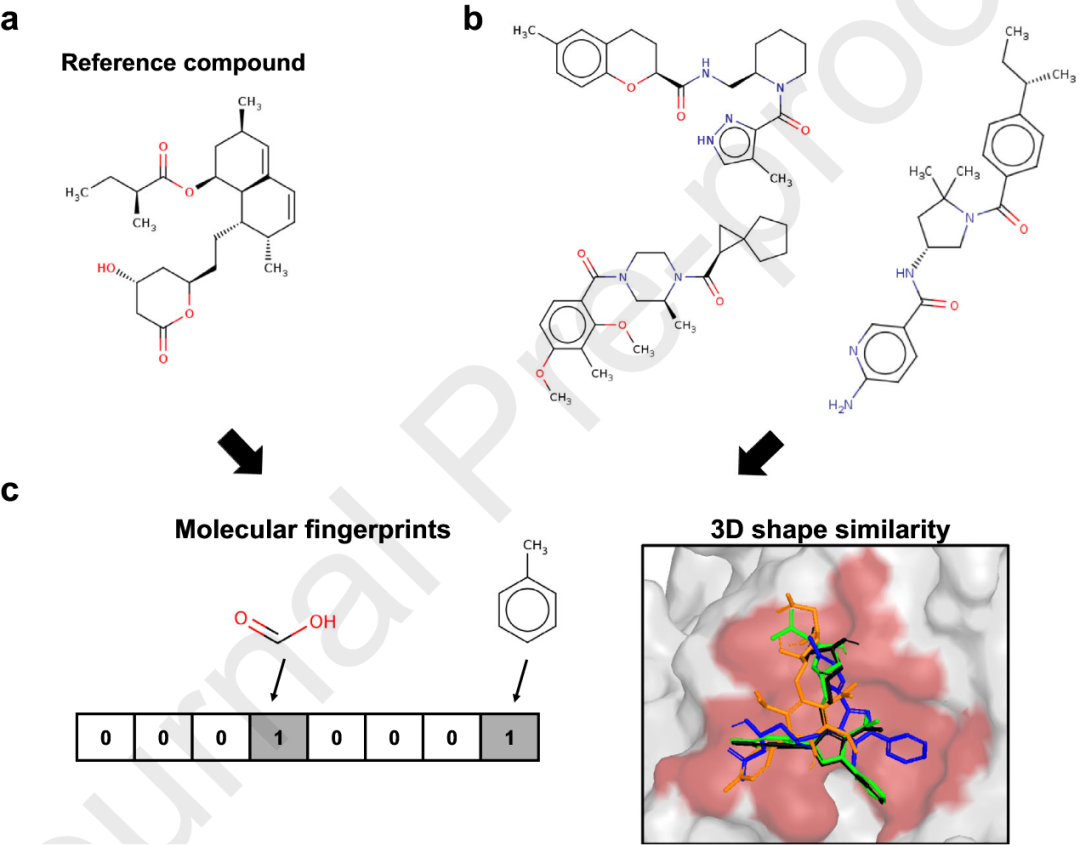
图2 以参考化合物为基础的配体虚拟筛选LBVS
传统的LBVS方法主要依赖二维分子表示(如MACCS keys和Morgan指纹),这些表示通过编码分子亚结构特征,实现快速的相似性搜索。大规模基准测试表明,基于指纹的相似性度量在区分强结合物与弱活性或无活性化合物方面往往表现不佳,尤其是在诱饵分子复杂度较高的数据集中。因此,二维LBVS方法在存在多样且高活性参考配体时最为有效,并日益作为辅助过滤手段而非独立筛选策略加以应用。
为克服二维表示的局限性,现代LBVS越来越多地引入三维相似性信息,包括分子形状、药效团特征以及官能团的空间排布。其中,基于形状的方法,尤其是建立在超快速形状识别(USR)基础上的方法,已显示出优异的可扩展性和前瞻性应用价值。随着LBVS的发展,其进一步将三维相似性与机器学习相结合,以增强骨架跃迁能力和富集效果。代表性方法包括NNGeomVS和FrankenROCS。深度学习(DL)架构的引入进一步推动了LBVS的规模化发展,其通过将分子相似性直接嵌入潜在空间,实现前所未有的筛选规模。LBVS正从指纹相似性向具备几何感知能力、以学习为核心的框架转变,从而能够在超大规模条件下稳定运行。
在ULVS管线中,LBVS方法日益充当可扩展的优先级排序与压缩层,在进入下游的分子对接、药效团精修或混合筛选之前,实现对十亿级化学库的高效导航。
基于药效团的方法
根据药效团特征的来源不同,该类方法可分为两种类型:(1)基于结构的药效团,其特征来源于蛋白–配体复合物、结合口袋相互作用场或蛋白功能热点;(2)基于配体的药效团,其特征则源自已知活性化合物的对齐集合(图3)。
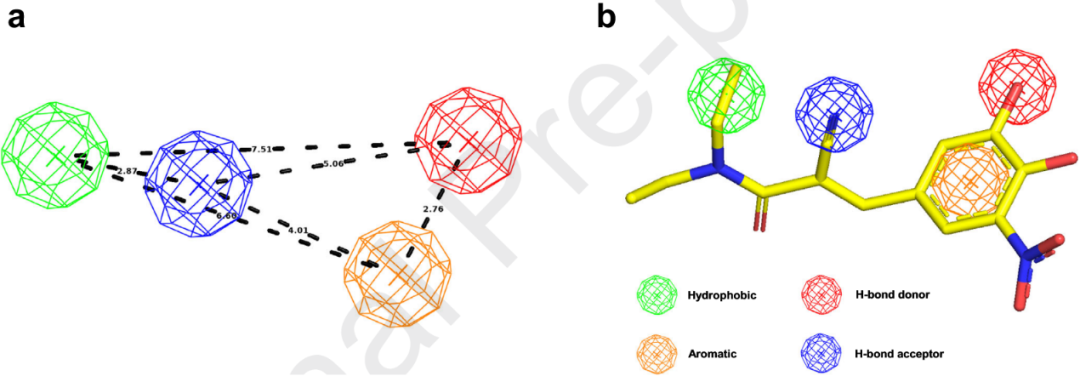
图3 基于药效团虚拟筛选中的关键表示方式。a)药效团距离映射;b)三维药效团比对。
基于药效团的方法在ULVS管线中提供了一种高效且具可解释性的过滤层,尤其适用于关键空间结合需求已知或可从结构与片段数据中推断的场景。通过将经典药效团假设不断融入学习驱动和优化导向的框架中,现代ULVS工作流程在保持可解释性的同时,亦获得了在十亿级化学库中高效运行所需的可扩展性。
混合型方法
混合型虚拟筛选方法通过整合SBVS、LBVS、基于片段的方法以及ML/DL,以应对穷尽式ULVS在计算与实验层面的固有限制。此类工作流程并非对整个化学库进行无差别对接,而是引入中间决策层,例如相似性扩展、生成模型、药效团约束或片段锚定,以将计算资源聚焦于化学和结构上最相关的化学空间区域(图4a)。这一设计理念使得在处理超过1亿规模的化学库时,既能实现高效导航,又能保持苗头化合物质量和化学新颖性。
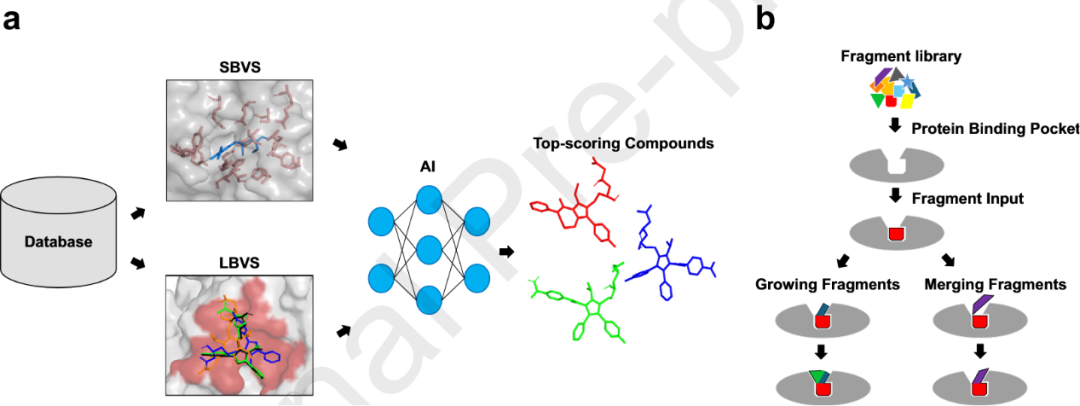
图4 混合型及新兴虚拟筛选工作流
一类混合方法强调通过生成建模与相似性扩展实现自适应化学空间探索。HIDDEN GEM框架即采用该策略,通过结合小规模初始对接、过滤、生成模型以及在Enamine REAL Space中的大规模相似性搜索来实现高效筛选。另一类混合工作流程侧重于通过多阶段精修提升筛选精度,通常将药效团建模、SBVS与分子动力学(MD)模拟相结合。此外,ML加速的混合策略能够在不牺牲实验验证成功率的前提下,实现对超大规模化学空间的选择性、高信息效率导航。基于片段的虚拟筛选(FBVS)已成为在超大规模化学空间中进行高效导航的一种重要混合策略,其核心在于利用实验或结构验证的片段锚点来引导聚焦式探索。与对整个化学库进行穷尽式对接不同,FBVS以低分子量片段与靶标的结合构象作为起点,通过选择性枚举、片段合并或片段生长,逐步构建高亲和力配体(图4b)。在ULVS规模下,该策略可显著降低搜索复杂度,同时保持化学新颖性和实验可行性。
主要ULVS平台
ULVS平台的发展反映了从穷尽式对接向选择性采样策略、可扩展云计算工作流程以及ML加速优先级排序的转变。
VirtualFlow 2.0
VirtualFlow 2.0是目前最为全面的ULVS框架之一,其通过整合大规模配体制备、多种对接引擎支持以及云优化架构,实现了对Enamine REAL Space库中690亿个分子的探索能力。其模块化工作流程包括:用于配体制备的VFLP 2.0、用于虚拟筛选的VFVS 2.0,以及用于流程协调的VFU,使其能够灵活适配多种靶标类型和对接策略。VirtualFlow 2.0已成为应用最广泛的ULVS平台之一,尽管其部分工作流程对经验不足的研究团队而言仍存在一定学习门槛。
RosettaVS
RosettaVS通过引入受体柔性建模并利用全原子最小化对结合构象进行精修,对传统SBVS进行了重要扩展。该特性使其能够探索刚性对接往往难以捕捉的动态结合口袋可塑性,尤其适用于具有隐蔽口袋或高度适应性结合位点的靶标。尽管对受体构象集合的准备以及较高的计算复杂度可能限制部分用户的使用,但RosettaVS在获得高命中率且经实验验证的配体方面的成功,使其成为极具吸引力的平台。
Deep Docking
Deep Docking(DD)通过一种迭代式重训练策略加速结构基础虚拟筛选SBVS,相较传统对接方法可将运行时间缩短最高达100倍。与OpenEye GigaDocking或AutoDock等传统对接系统相比,后者通常需要数万级CPU或GPU资源,而DD在可扩展性与可获得性方面具有显著优势。该平台支持多种常用对接引擎,并提供基于Python的开源实现,同时配备自动化工作流程,使缺乏ML或脚本经验的用户也能便捷使用。
V-SYNTHES
V-SYNTHES采用一种分层的合成子驱动策略。具体而言,首先对一组小规模且具有代表性的骨架–合成子组合进行对接,这一集合被称为最小枚举库(MEL)。仅对得分最高的片段组合进行迭代扩展,通过合成子替换生成并对接完整分子。通过将基于片段的枚举策略与分层对接相结合,V-SYNTHES在继承片段设计优势的同时,实现了ULVS级别的筛选效率。其在保持超大规模化学库兼容性的前提下,能够输出高效力、高选择性且合成可行的先导化合物,使其成为现代苗头化合物发现中一项具有创新性的工具。
局限性与展望
ULVS是发现潜在新药分子的基础性技术路径,其发展得益于大规模可合成化学库、高性能计算平台以及AI驱动的优先级筛选策略的协同进步。从早期QSAR–对接混合方法到十亿级化合物规模的对接筛选,研究表明,结构基础与配体基础策略均能够在多种靶标体系中成功发现化学新颖、经实验验证的苗头化合物,涵盖酶类、GPCR、离子通道以及蛋白–蛋白相互作用界面等。进一步引入片段引导探索、药效团约束以及ML/DL增强评分体系,使筛选在化学空间覆盖度与实验可行性之间达到了更优平衡。
随着化学库规模持续扩展并逼近万亿级分子空间,ULVS既迎来了前所未有的机遇,也面临根本性挑战。对如此规模的化学空间进行穷尽式对接在计算上已不可行,因此,选择性探索策略将成为必然趋势,包括自适应靶标引导采样,替代性ML模型,生成化学方法以及分层的片段基础枚举策略。这些方法能够聚焦于高价值化学子空间,在保持化学新颖性与实验可操作性的同时,大幅降低计算成本。尽管如此,ULVS在实际应用中仍面临若干限制,如评分函数的准确性及其在不同靶标间的泛化能力仍不足;训练数据集偏倚在面对未知骨架时显著影响预测可靠性;计算资源需求、存储与I/O瓶颈仍需通过云原生架构、GPU加速及优化的对接前流程加以缓解;此外,实验验证阶段依然是关键瓶颈,亟需在合成可行性、理化性质过滤及富集子集优先级策略上进行精细化设计。
展望未来,下一代ULVS由智能化、选择性筛选策略所定义。其关键推动因素包括:(1)AI驱动的优先级排序与主动学习,以聚焦超大化学库中在化学与生物学上最具相关性的区域;(2)生成模型与合成意识枚举策略,确保虚拟筛选结果具备下游实验可行性;(3)蛋白与配体的多模态表征体系,以提升跨靶标类别的可迁移性。新兴技术(如量子计算与混合量子–经典方法)未来有望进一步提升评分精度与构象采样质量,尽管其实际影响仍有待验证。未来的成功不仅取决于计算规模的扩展,更依赖于预测模型、化学库设计与实验验证之间的理性整合。通过强调选择性、证据驱动的化学空间探索,ULVS有望彻底改变苗头化合物发现范式,实现更快速、更具成本效益且化学多样性更高的药物先导分子发现。
参考链接:
https://doi.org/10.1016/j.drudis.2026.104616
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢