
DRUGONE
研究人员提出了一种名为 spEMO 的人工智能框架,用于联合分析空间多组学数据与病理图像。该方法通过整合病理基础模型生成的图像嵌入与大语言模型提供的文本知识嵌入,构建统一的多模态表示空间,使模型能够同时利用组织形态信息与分子表达信息进行推理。实验表明,该方法在空间区域识别、spot类型注释、疾病预测、多细胞相互作用推断以及医疗报告生成等多个任务上均优于传统单模态方法,显示出多模态基础模型在空间生物学研究和临床应用中的广泛潜力。

病理诊断和空间组学研究往往需要同时依赖组织形态、基因表达以及蛋白信息等多种数据来源,但现有机器学习方法通常只能处理单一模态,难以充分利用这些互补信息。近年来,大规模病理图像训练的基础模型在图像理解任务上表现突出,而空间转录组与空间多组学技术也逐渐能够在组织尺度上提供高分辨率分子信息。然而,这两类数据仍缺乏统一建模框架。
另一方面,直接训练基于组学数据的基础模型存在困难,因为测序数据噪声较高且数据结构复杂。已有研究发现,利用外部知识生成的文本嵌入可以辅助生物数据分析,但这种思路尚未被系统应用于空间多模态场景。因此,研究人员尝试构建一个统一系统,使病理图像表示、分子表达信息以及文本知识能够在同一表示空间中协同工作,从而实现更完整的空间生物学解析。
spEMO 多模态整合框架
spEMO 的核心思想是通过多模态嵌入融合来构建统一表示空间。具体而言,研究人员首先将整张病理切片划分为多个图像patch,并利用病理基础模型生成每个空间位置对应的图像嵌入。同时,通过语言模型获取与基因或蛋白相关的知识嵌入。随后,将这些嵌入与空间转录组或多组学数据结合,投影到统一的表示空间中。
该框架既可以在零样本设置下直接使用融合后的嵌入进行分析,也可以将融合表示输入到特定任务模型中进行进一步训练,例如图神经网络或分类模型。这种设计使系统既能利用预训练模型的知识,又能针对具体任务进行优化。
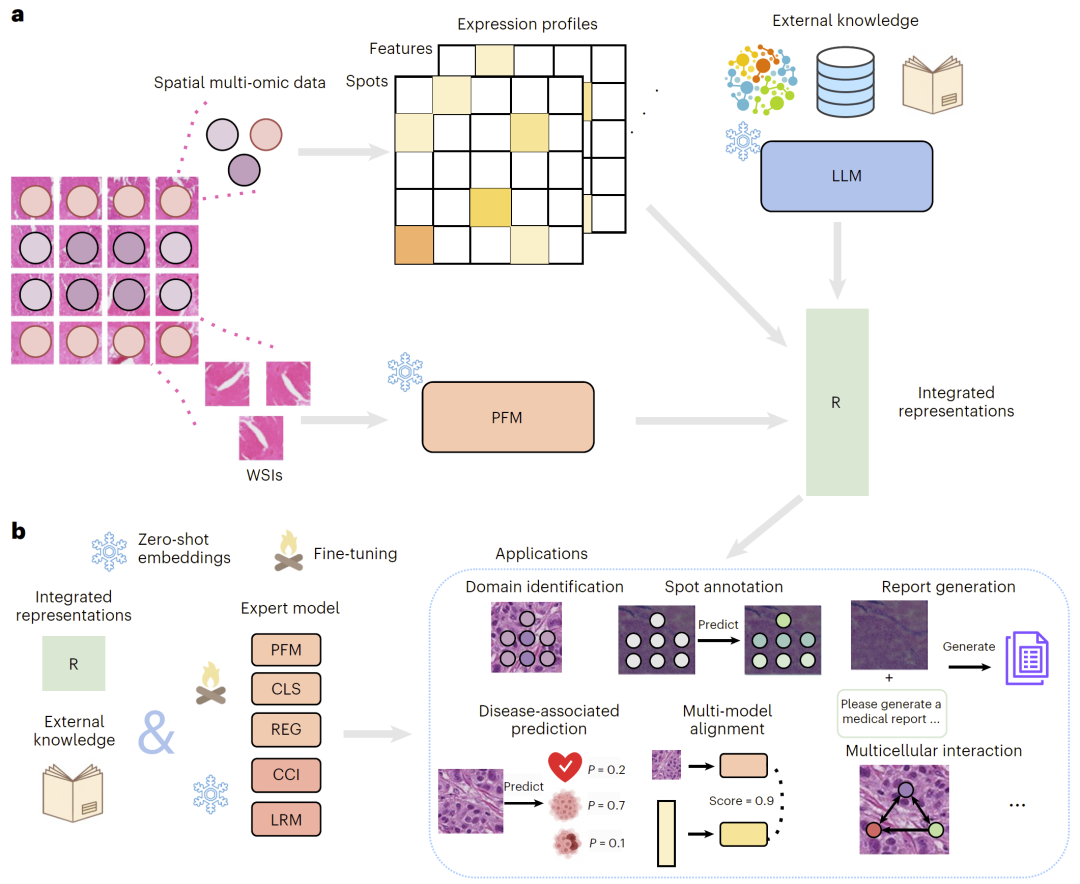
图1:spEMO框架总体概览。
spEMO提高空间区域识别能力
在空间转录组数据分析中,识别组织中的空间区域是最基础的问题之一。研究人员在脑组织SpatialLIBD数据上测试了spEMO,并将其与传统基于主成分的方法以及多种现有模型进行比较。结果显示,引入病理图像嵌入后,模型在多个聚类指标上均明显提升,并能够更准确地恢复真实的皮层结构分层。
进一步分析发现,这种性能提升的原因在于图像嵌入包含更强的空间自相关信息,因此能够更好地反映组织结构的连续性和空间模式。
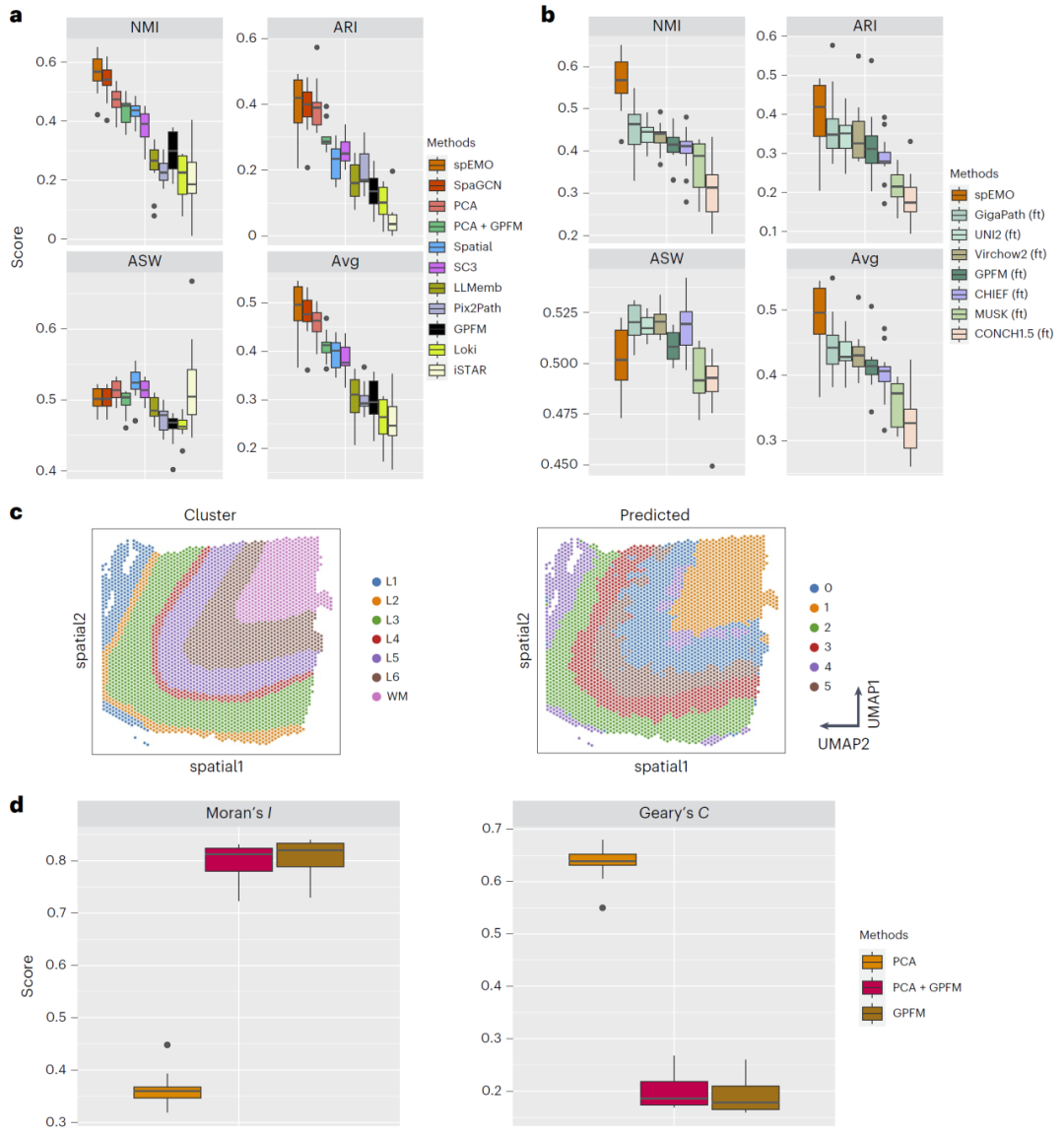
图2:spEMO在空间区域识别任务中的贡献分析。
spEMO改善多组学空间数据的区域识别
研究人员进一步测试了没有图像信息的空间多组学数据集(同时包含RNA与蛋白表达)。在这种情况下,研究人员使用语言模型生成的基因和蛋白描述嵌入作为补充信息。结果表明,引入这些文本知识嵌入后,空间区域识别精度明显提高,并达到接近专用多模态模型的水平。这说明即使缺乏图像信息,外部知识嵌入仍然能够帮助解析空间结构。
spEMO提升spot类型注释精度
在spot类型注释任务中,研究人员将该问题视为监督分类任务,通过训练分类器预测每个空间位置的细胞或组织类型。实验结果显示,仅使用基因表达信息时模型性能有限,而加入病理图像嵌入后,预测准确率显著提升。不同病理基础模型生成的图像嵌入均能带来性能增益,说明组织形态信息在细胞类型识别中具有重要补充作用。
spEMO整合图像信息提升疾病预测
研究人员随后评估了spEMO在整张组织切片层面的疾病预测能力。在包含多种癌症和健康组织的空间数据集中,研究人员发现基因表达与图像嵌入捕获的是互补信息:基因表达更反映组织分子特征,而图像嵌入更有助于区分不同疾病形态。将两者结合后,模型的疾病分类性能显著提高,并在交叉验证中获得最佳准确率。
此外,实验还显示文本知识嵌入在该任务中并未带来明显提升,说明不同模态对不同任务的重要性并不相同。
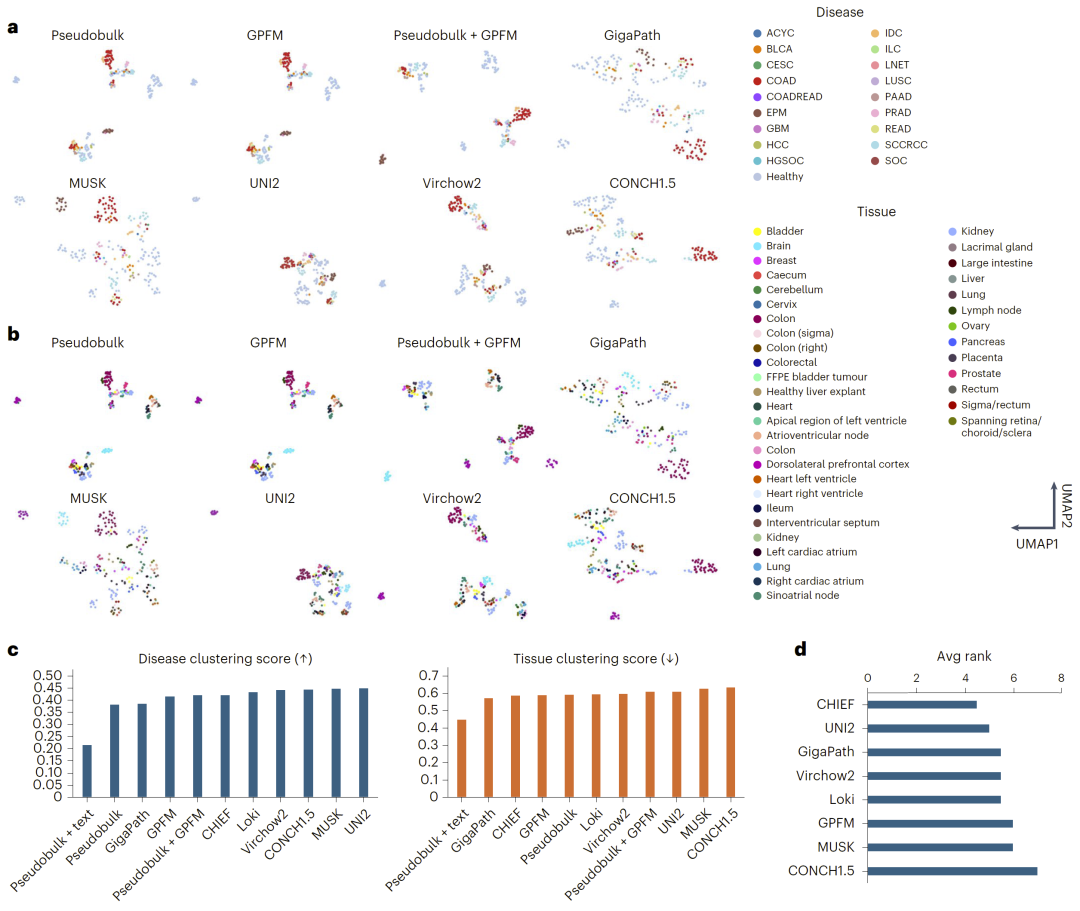
图3:不同元数据标注下的嵌入聚类评分与可视化结果。
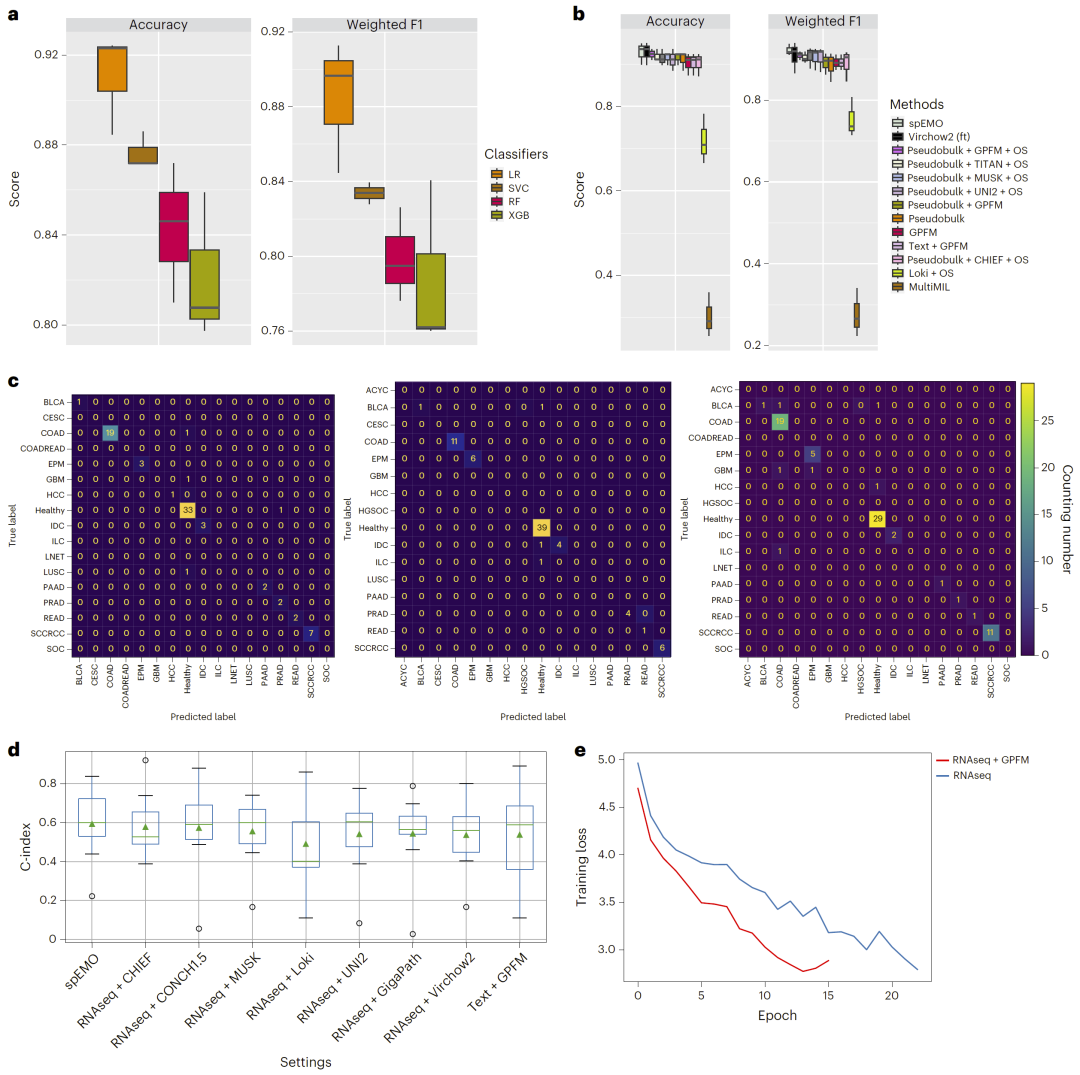
图4:利用图像嵌入提升疾病状态预测性能的结果。
spEMO支持药物响应预测与生存分析
研究人员进一步将该方法用于更具临床意义的预测任务。在乳腺癌数据集中,利用图像嵌入能够更好地区分患者对治疗药物的响应情况。在TCGA结直肠癌数据上,联合使用基因表达和图像嵌入进行生存预测时,模型获得最高C-index,并且训练过程收敛更快、过拟合更少,表明多模态信息能够显著增强临床预测能力。
spEMO帮助发现新的多细胞相互作用
为了验证该方法在生物机制发现方面的潜力,研究人员利用图像预测得到的空间基因表达数据,分析结直肠癌样本中的细胞通信网络。通过空间变异基因检测与细胞通信分析工具,研究人员发现一个CXCL13–CCR7信号轴在特定肿瘤区域具有明显活跃性。该组合此前未在该癌症中系统报道,提示该方法可能帮助识别新的免疫调控机制。
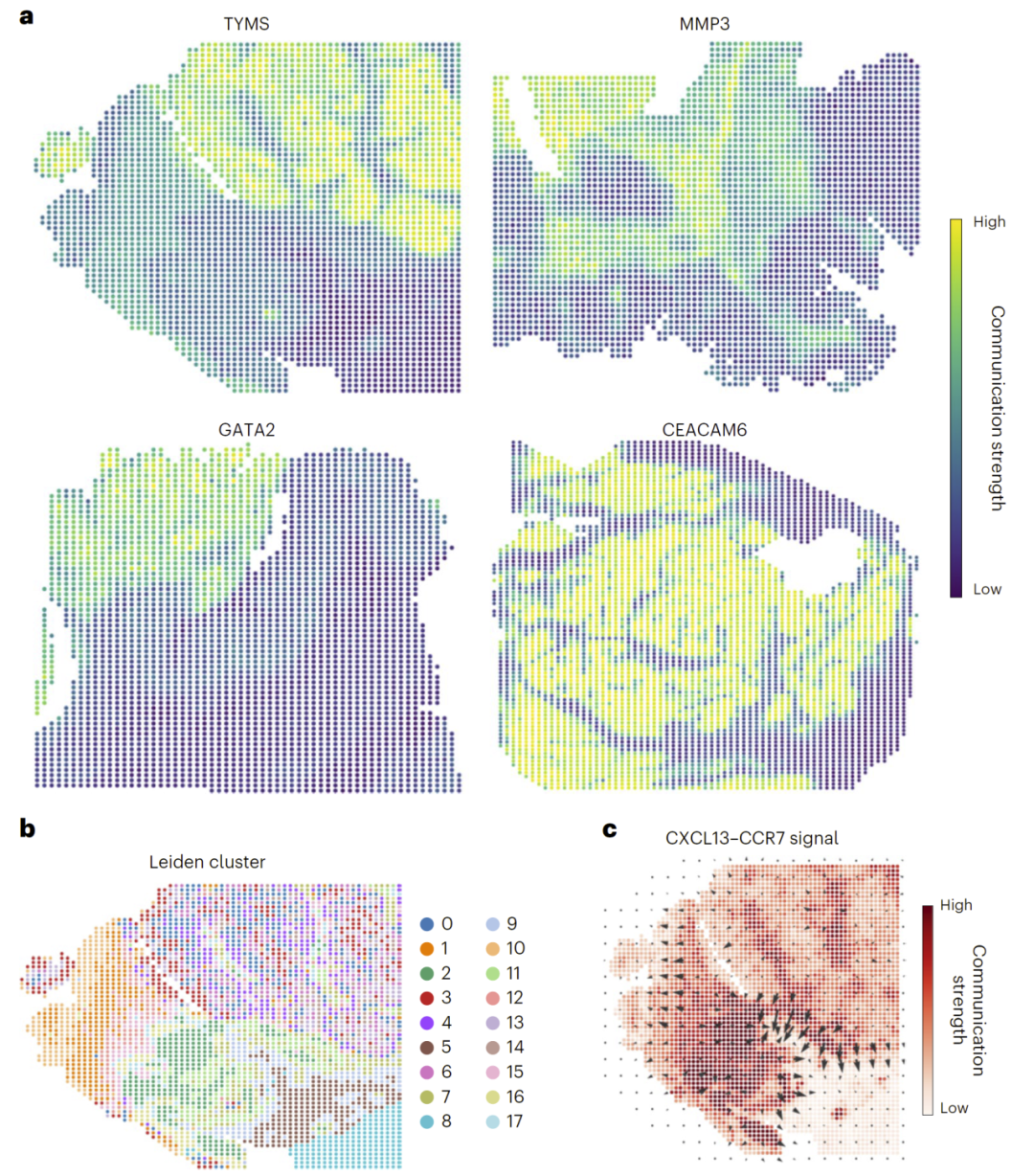
图5:基于预测基因表达谱的多细胞相互作用分析。
spEMO实现多模态医疗报告生成
研究人员还探索了该框架在自动医疗报告生成中的应用。通过同时输入病理图像与高变基因信息,让多模态模型生成结构化诊断报告。实验结果显示,与仅使用图像或仅使用基因相比,同时提供两种信息时生成报告的完整性和正确性均显著提高。在医生人工评估中,模型生成的报告通常包含更全面的诊断信息,尽管篇幅略长,但总体质量更高。
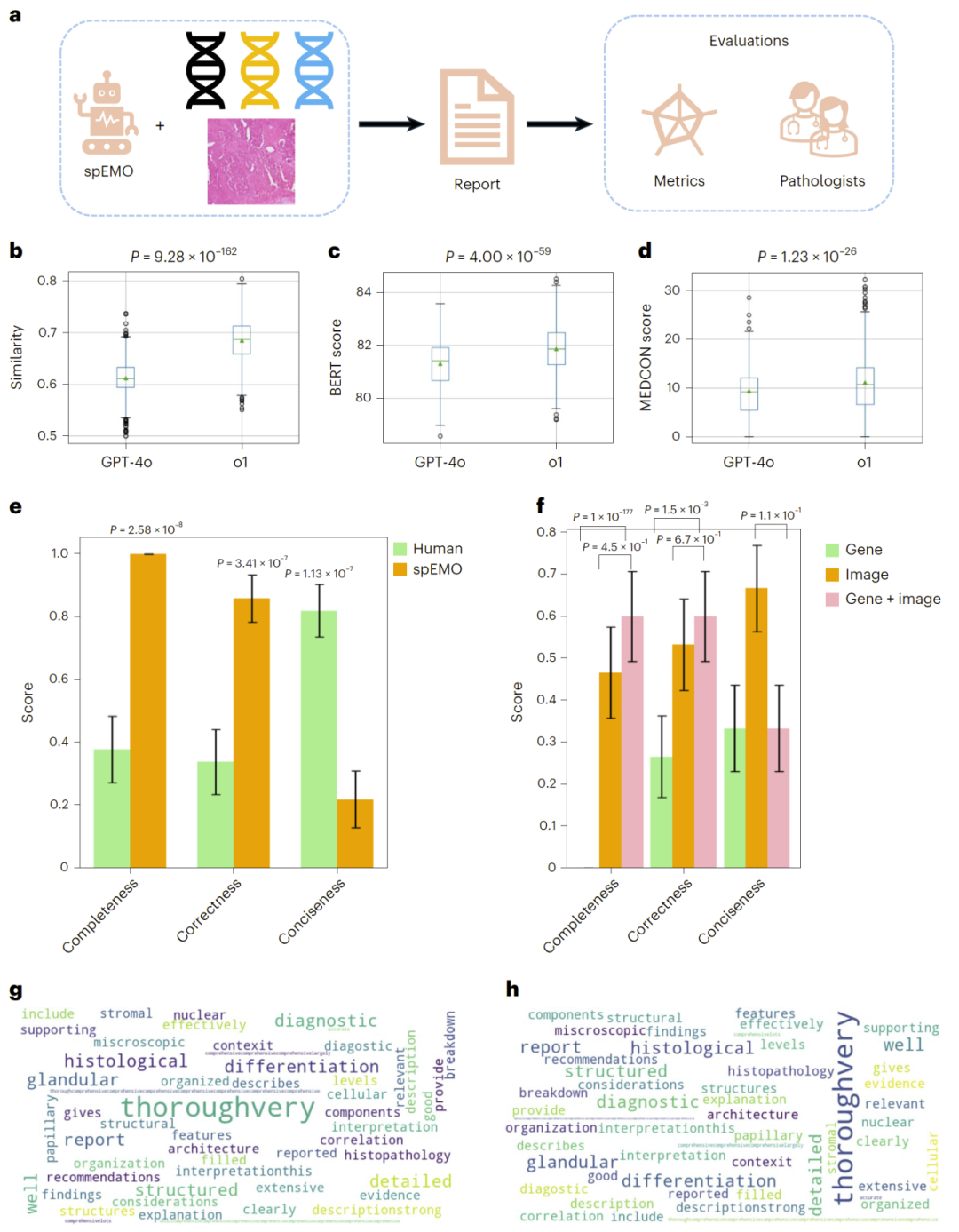
图6:多模态AI智能体生成医学报告的流程与结果。
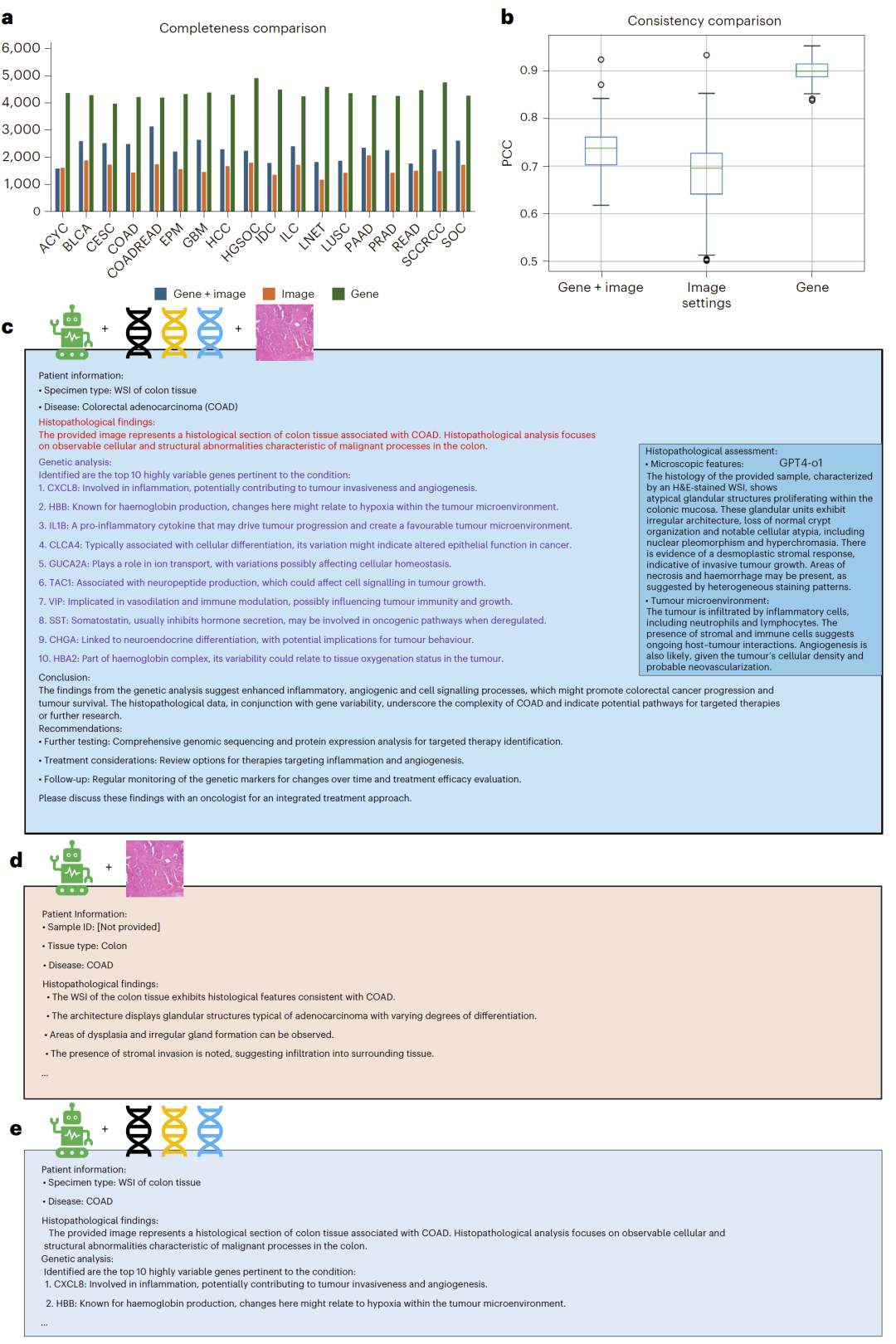
图7:医学报告生成任务的评估结果与示例。
讨论与意义
研究结果表明,将多模态基础模型嵌入进行统一整合能够显著提升空间生物学分析能力,并提高模型生成临床总结的解释性与完整性。该研究还指出,外部知识嵌入(如语言模型表示)在许多任务中能够提供关键补充信息,从而解释为何多模态方法常常优于单模态模型。
总体来看,这一框架为未来整合病理基础模型、组学基础模型以及语言模型提供了系统化设计蓝图,并有望推动空间医学与转化研究的发展。
整理 | DrugOne团队
参考资料
Liu, T., Huang, T., Ding, T. et al. Leveraging multi-modal foundation models for analysing spatial multi-omic and histopathology data. Nat. Biomed. Eng (2026).
https://doi.org/10.1038/s41551-025-01602-6

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢