

报告主题:第一个系统测评Agent Skills的框架 & 有领域专家人工创建的综合领域的agentic benchmark
报告日期:03月03日(周二) 10:30-11:30
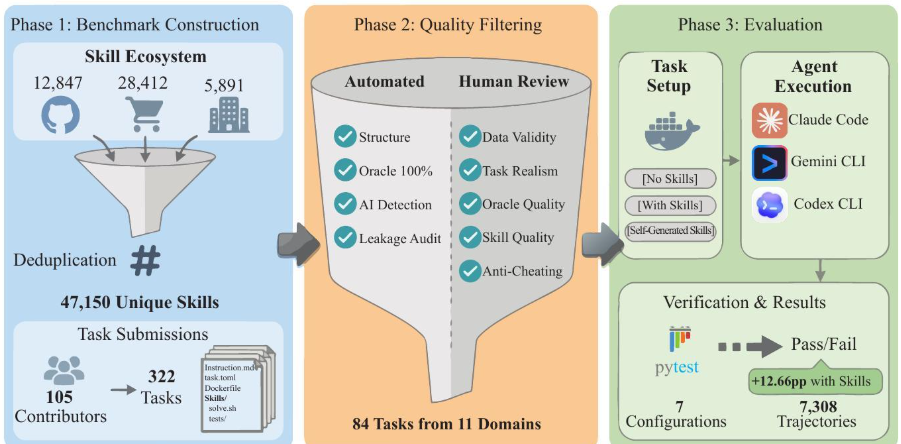
智能体技能(Agent Skills)是一类结构化的程序性知识封装,用于在推理阶段增强大语言模型(LLM)智能体的能力。尽管其应用正迅速普及,但目前尚无统一标准来衡量这些技能是否真正有效。为此,我们提出SkillsBench——一个涵盖11个领域的86项任务的基准测试集,每项任务均为领域专家人工制作和审核,并配有对应人物作者精心筛选的技能集合及确定性验证器。
针对每一项任务,我们均在三种条件下进行评估:不使用任何技能、使用人工筛选的技能,以及使用智能体自生成的技能。我们在7种智能体-模型组合上共运行了7,308条推理轨迹。结果表明,采用人工筛选的技能后,平均通过率提升了16.2个百分点(pp),但提升效果因领域而异(软件工程领域仅提升+4.5pp,而医疗健康领域则高达+51.9pp),且在全部84项可比任务中,有16项反而出现负向增益(即性能下降)。
而智能体自生成的技能在整体上未带来任何显著收益,说明当前模型尚不具备可靠地自主编写其所依赖的程序性知识的能力。此外,聚焦核心功能、仅含2–3个模块的精简型技能,其效果优于内容庞杂的综合性文档;同时,配备技能的小尺寸模型,其性能亦可媲美未配备技能的大尺寸模型。
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
报告嘉宾:
李向一,BenchFlow创始人,获得谷歌首席科学家Jeff Dean, Dropbox联合创始人Arash Ferdowsi, Founders, Inc. 以及 A16z scout fund投资。在公司之外也深度参与维护多个著名开源项目,包括Terminal Bench maintainer & reviewer, Terminal Bench Science maintainer & reviewer,OpenThoughts Agent以及Harbor contributor。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢