

论文地址:
https://arxiv.org/abs/2510.12563
Github地址:
https://github.com/ljcleo/hardcore-logic
评测数据集:
https://huggingface.co/datasets/xhWu-fd/HardcoreLogic
在线排行榜:
https://huggingface.co/spaces/JunsWan/HardcoreLogic
引言
近年来,大型推理模型(large reasoning model, LRM)在复杂逻辑推理任务中展现出令人瞩目的性能,尤其在数独等逻辑推理谜题上已达到较高水平。然而,现有逻辑推理基准(如Enigmata、ZebraLogic)多聚焦于标准格式的谜题(如9x9标准数独),导致模型易过度拟合标准形式、记忆解决方案模式,而非真正理解逻辑规则。这种局限性在面对“长尾”变体时尤为突出:
模型仅能识别标准谜题形式,对非标准规则或结构的变体难以理解;
模型依赖固定推理策略,即使理解变体规则,仍套用标准解法导致错误。
当前的各类LRM是否拥有真正的灵活推理能力?当面对非标准、长尾分布的逻辑谜题变体时,它们能否自适应调整推理策略?针对这一关键问题,来自复旦大学、南加州大学、华为技术有限公司等机构的研究团队提出了HardcoreLogic —— 一个包含5250个长尾逻辑谜题的挑战性数据集。这一新评测基准在10种涵盖不同逻辑推理能力的谜题的基础上,系统性地引入多种长尾变换,使谜题变得更加困难或更不常见,同时特别构造了无解谜题,以填补当前主流评测基准在这方面的空白。
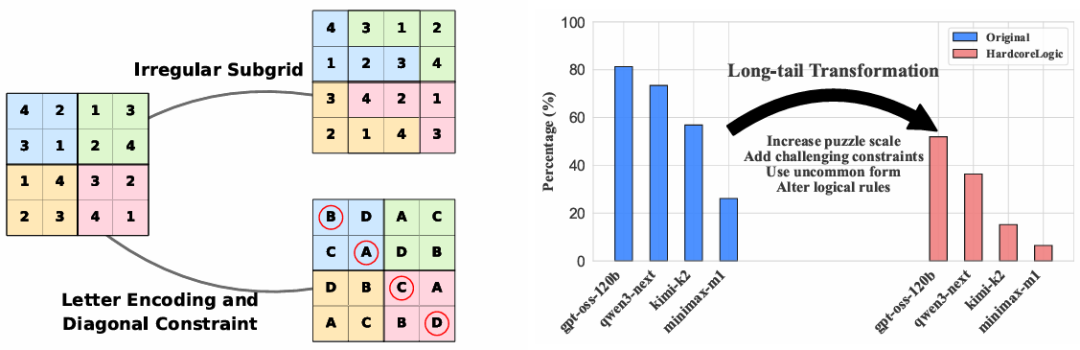
图1(左) :针对数独谜题的两种变换示例:右上的变体具有不规则宫格(规则变异);右下的变体用字母替代数字(形式变异)且要求对角线也不能重复(规则变异)。
图2 (右):模型在标准数据集(Original)与HardcoreLogic上的性能对比。
实验结果显示,各类开源及闭源LRM在HardcoreLogic上均无法达到常规谜题上的答题水平,并呈现出多种相对普遍的错误模式;而在无解谜题上,许多模型也不能准确判别问题无解或试图强行编造解答。这些结果揭示了当前主流LRM在真实逻辑推理中仍然存在的核心缺陷;HardcoreLogic不仅为此提供了针对性的评测谜题,还能进一步作为一种数据构造范式,持续提供不同难度梯度的谜题数据以帮助模型克服这些缺陷。
本论文已经被ICLR 2026接收为主会长文。
基准设计
覆盖谜题类型
HardcoreLogic涵盖6大类10种经典逻辑谜题,全面测试模型的逻辑演绎、模式识别、序列搜索等多种核心推理能力:
逻辑谜题:Zebralogic
网格谜题:Sudoku、Skyscraper、Binario
搜索谜题:Minesweeper、Hitori、Kakurasu
模式谜题:Crypto
图谜题:Navigation
序列谜题:Hanoi
三大长尾变换维度
HardcoreLogic通过以下三种互不重叠的变换构建长尾样本,大幅降低模型记忆优势:
复杂度提升(IC),包括:
搜索空间扩展(IC1):增大谜题规模(如更大网格)、减少初始给定信息,扩大候选解空间;
约束强化(IC2):增加约束间的耦合程度,降低单个约束的信息量,延长推理链。
非标准元素(UE),包括:
形式变异(UE1):改变谜题呈现形式(如数独用字母替代数字、不规则子网格划分);
规则变异(UE2):修改或融合核心规则(如数独增加对角线唯一约束、扫雷用“地雷簇”替代单个地雷计数)。
不可解谜题(UP):基于可解谜题构造存在逻辑矛盾的无解样本,测试模型识别信息不一致、避免“幻觉解”的能力。
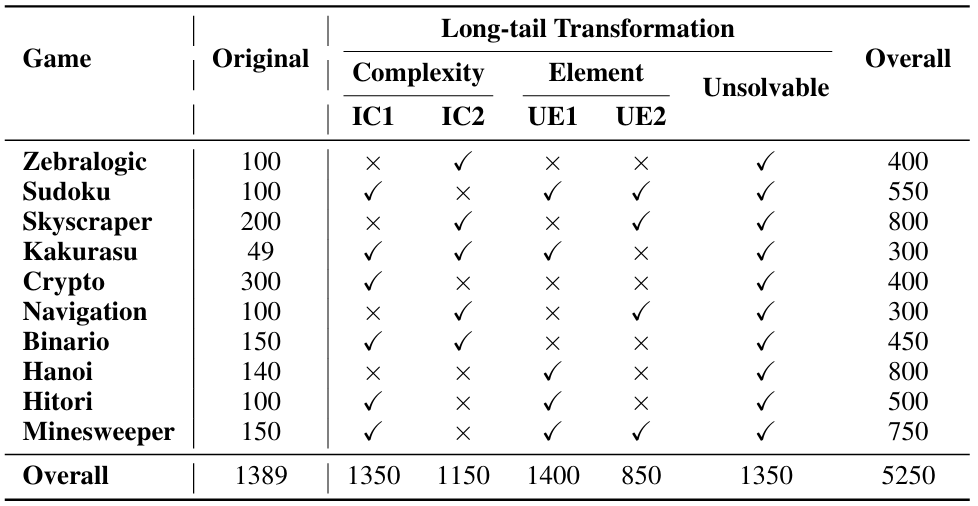
表1 :各个谜题的变体分布及数据量;Original是用于对比的标准谜题数据集。
数据规模与复杂性
相比基于标准谜题的数据集(Original),HardcoreLogic中的样本具有更高的理论复杂度或模型困惑度:
经过IC1变换的谜题普遍拥有更大的解空间,使得暴力搜索无法在常规上下文空间内完成;
经过IC2和UE2变换的谜题普遍具有更大的分支长度和回溯次数,使推理链条更加复杂;
经过UE1变换的谜题虽然不会增大解空间或增加复杂度,但仍然具有更高的模型困惑度。
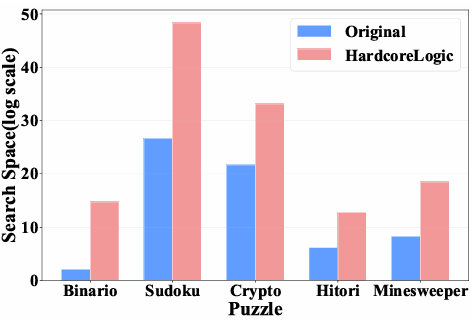
图3 :五个游戏的谜题在IC1变换前后的平均搜索空间大小对比;
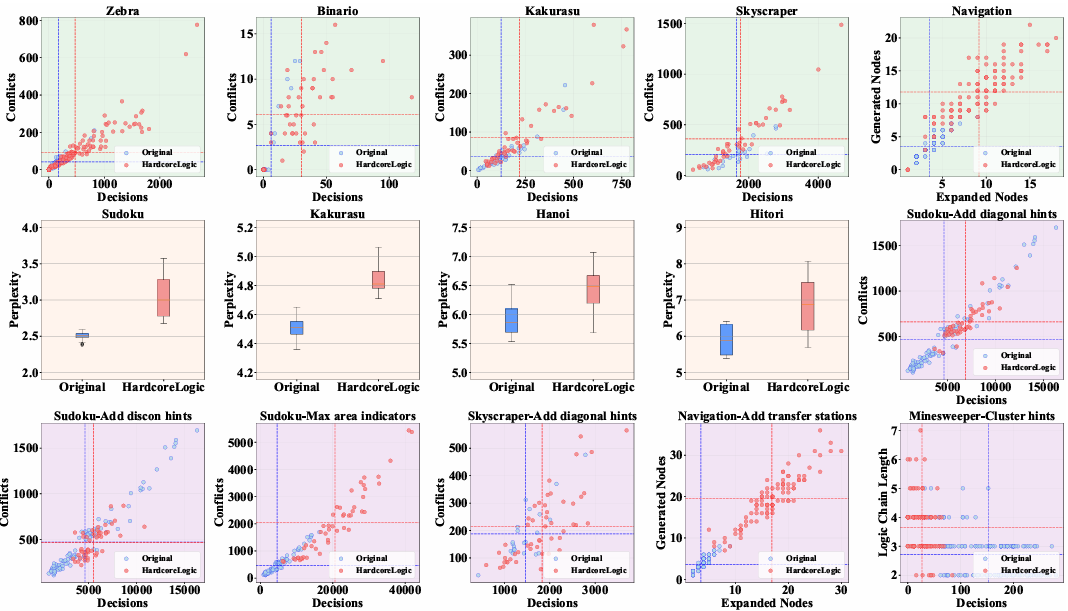
图4 :各个游戏在IC2(绿)、UE1(橙)或UE2(紫)变换前后的复杂度/困惑度大小对比。
实验结果与关键发现
我们在21个主流LRM(包括GPT、Qwen3、DeepSeek等开源/闭源模型族)上进行了全面评估,核心发现如下:
所有模型性能显著下降
无论是开源模型还是闭源模型,在HardcoreLogic上的准确率相比标准数据集均大幅下滑。其中,部分大参数模型(如Kimi-K2)在原始基准上表现中等,但在HardcoreLogic上大幅落后,暴露其依赖“谜题刻板印象”的缺陷。这一现象在涉及的各种游戏上均有体现,尤其是部分标准数据集中较为简单的谜题(如Binario)。
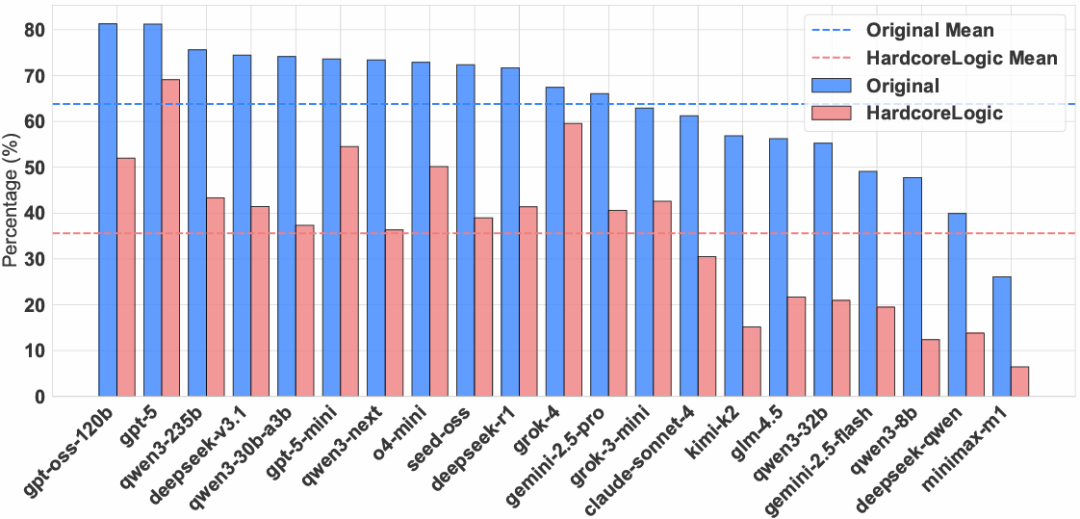
图5 :不同LRM在标准数据集(Original)和HardcoreLogic上的平均准确率。
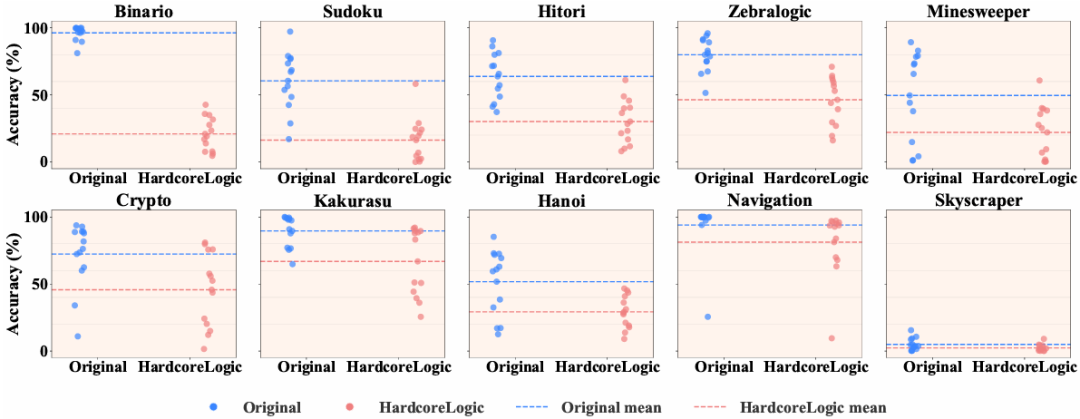
图6 :两个数据集中每种谜题的开源模型平均准确率分布。
IC和UE变换的难度贡献
通过加权线性回归分析,我们发现搜索空间扩展(IC1)对模型性能影响最大,表明模型的推理模式对解空间大小最为敏感。此外,非标准元素变换(包括UE1和UE2)在部分谜题(如Sudoku和Minesweeper)上也导致明显的模型性能下降——尽管这类变换未必会使推理过程更加复杂,但仍然对LRM产生了一定误导。
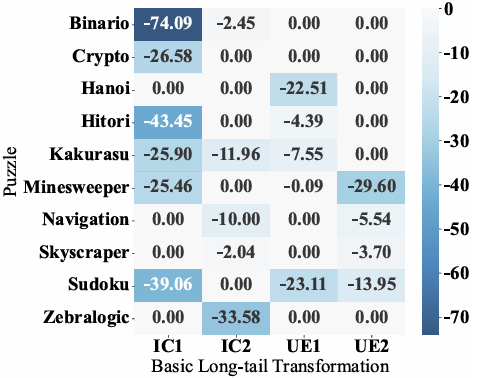
图7 :各类变换对模型平均性能的影响系数。
可解谜题的错误分析
通过对4个代表性模型(gpt-oss-120b、Qwen3-235B、Kimi-K2-Instruct、Minimax-M1)在可解谜题上的50个错误案例进行分类,我们发现了以下六种主要错误类型:
理解偏差(Misunderstanding):模型未真正理解谜题规则或结构;
解法误用(Misapplied):理解规则但套用错误的标准解法;
暴力搜索失效(Brute-Force):强模型试图通过枚举求解,但搜索空间过大导致失败;
事实幻觉(Factual Errors):推理过程中虚构事实或逻辑关系;
推理不忠(Faithfulness):推理过程正确但最终答案错误;
无限重复(Infinite Repetition):弱模型陷入循环输出,无法生成有效答案。
其中,事实幻觉是最普遍的错误类型,而理解偏差、解法误用、暴力搜索失效和无限重复在部分模型上也十分突出。此外与标准数据集相比,模型在 HardcoreLogic 上更容易犯理解偏差和解法误用错误,表明模型并不能适应变体谜题。
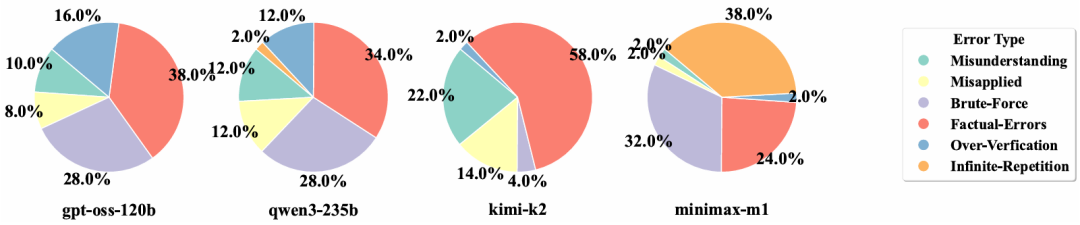
图8 :可解谜题(非UP谜题)的错误情况分布。
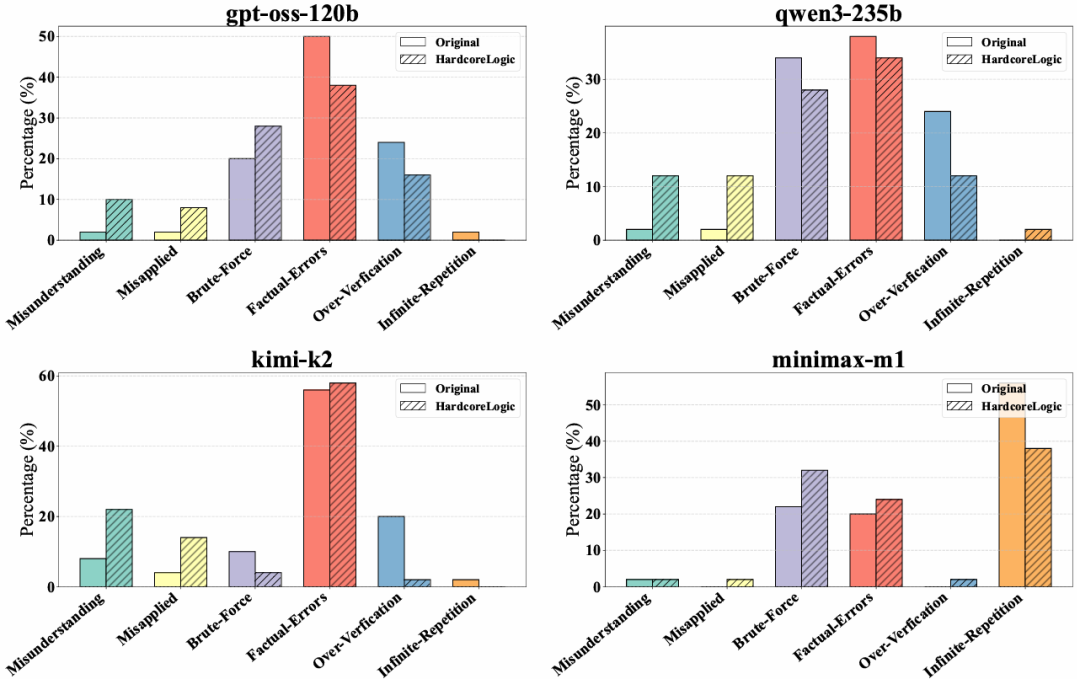
图9 :上述错误类型在标准数据集和 HardcoreLogic 上的频率分布。
不可解谜题
我们单独统计了不可解谜题(UP)上模型的判别性能,发现大多数模型都能较准确地给出不可解的回答。然而这一结果背后仍然隐藏着两个值得关注的现象:
许多模型(特别是较弱的模型)多因无法找到解而“盲目判定”不可解,并非真的找到了谜题信息中的矛盾点;
一些模型即使在推理过程中意识到谜题无解,也仍然坚持返回一个虚构的错误解,导致解答出错。
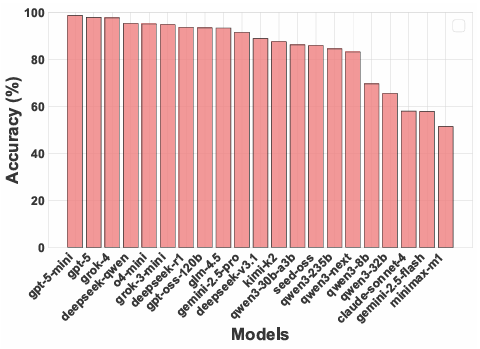
图10 :各模型识别不可解谜题的准确率。
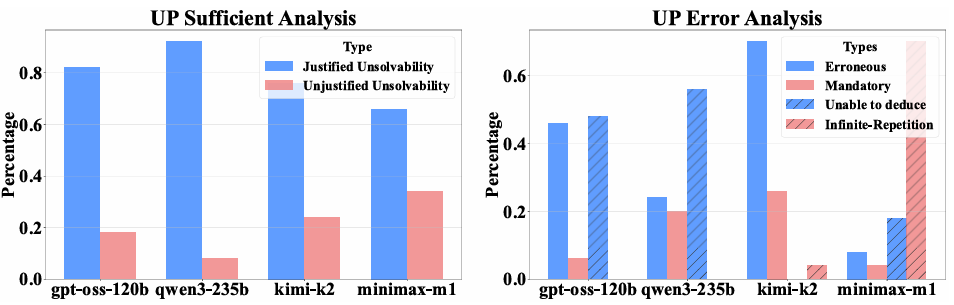
图11:不可解谜题上的充分性分析与错误分析结果。
总结
本研究提出了HardcoreLogic基准,首次系统性构建逻辑谜题的长尾变体,覆盖复杂度提升、非标准元素、不可解谜题三大维度。与常规谜题相比,当前主流的大型推理模型在这些谜题的准确率明显下降,进一步的分析揭示了当前LRM的一些核心缺陷,包括:
过度依赖模式记忆和暴力方法,难以应用至大规模或非常规问题;
逻辑连贯性不足,在长推理过程中容易虚构推理步骤或前后不一致;
对非常规结果(谜题无解)过度怀疑,以至强行编造错误解答。
HardcoreLogic评测集及上述基于HardcoreLogic的发现为将来面向复杂逻辑推理的推理模型提供了更全面衡量方式与更明确的优化方向。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区袁天凡、慧敏校园C栋

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢