

报告主题:DLLM-Searcher让Search Agent在等待工具返回时保持思考
报告日期:03月12日(周四) 10:30-11:30
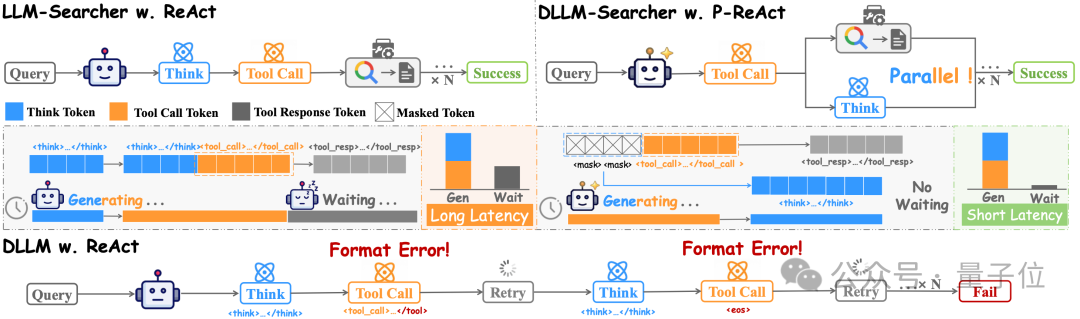
当前 Search Agent 的实际落地主要受制于长时延瓶颈:在经典 ReAct 范式下,智能体往往需要多轮串行执行“推理→tool call→等待工具返回→继续推理”,工具等待与多轮生成叠加后显著拉高端到端 latency,进而削弱交互体验。而扩散大语言模型(dLLM)天然具备并行解码与任意顺序生成能力,这为打破 ReAct 的串行执行提供了基础。
基于此,报告将介绍 DLLM-Searcher:一方面提出新的推理范式 P-ReAct,通过引导模型优先解码 tool_call 区域,使智能体能够“先调用、再返回、同时继续思考”,从而将等待工具返回的空窗与思维生成过程重叠,降低整体推理时延;另一方面,针对现有 dLLM 在推理与工具调用方面能力偏弱的“Agent Ability Challenge”,我们设计了两阶段的 Agentic Post-Training:先用 Agentic SFT 建立格式与工具使用的基础能力,再通过 Agentic VRPO 进一步强化信息获取、推理能力。实验结果表明,DLLM-Searcher 在多个基准上取得与主流 LLM-based Search Agents 可比的任务效果,同时 P-ReAct 带来约 15% 的推理加速,验证了 dLLM 作为高效智能体基座与“并行推理-行动”路径的可行性。
相关论文:
An agentic system for rare disease diagnosis with traceable reasoning
报告嘉宾:
赵嘉浩,是中国人民大学高瓴人工智能学院大四年级本科生,获两年国家奖学金,研究方向聚焦Agentic Post-Train、Information Retrieval。
近年来在IR与LLM结合方向开展研究:其二作工作Evaluating Intelligence via Trail and Error揭示了检索模型与LLM在推理时类似的行为;参与 EMNLP 2025 的 R1-Searcher++,探索通过两阶段 SFT+RL 提升模型的动态检索与推理能力;一作工作 DLLM-Searcher进一步将 dLLM 引入 Search Agent,提出 P-ReAct 与两阶段 Agentic SFT/VRPO 训练框架,实现“等待工具返回时持续思考”的并行化智能体推理。
他在清华 THUIR 课题组与字节跳动Seed团队有实习经历;同时也是开源Agent项目OpenManus(55k stars)贡献者。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢