

论文标题:ZATOM-1: A Multimodal Flow Foundation Model for 3D Molecules and Materials
arXiv 编号:2602.22251v2
发表时间:2026 年 3 月 6 日(预印本)
主要机构:Lawrence Berkeley 国家实验室、MIT、耶鲁大学、剑桥大学、UC Berkeley
通讯作者:Alex Morehead、Rex Ying、N. Benjamin Erichson、Michael W. Mahoney
开源地址:https://github.com/Zatom-AI/zatom
目录
1. 研究背景与动机 2. 核心问题定义 3. 模型架构详解 4. 训练方法:多模态流匹配 5. 阶段二:多任务预测微调 6. 实验设置 7. 实验结果全面分析 8. 消融研究与关键洞见 9. PLATOM-1:等变变体的启示 10. 局限性与未来方向 11. 与相关工作的系统对比 12. 总结与影响评估
1. 研究背景与动机
1.1 化学 AI 的碎片化现状
当前 AI 驱动的化学研究呈现出明显的双重割裂:
割裂一:领域割裂
• 针对非周期性小分子的模型(如 Equivariant Diffusion、GeoLDM、SemlaFlow)与针对周期性晶体材料的模型(如 DiffCSP、MatterGen、FlowMM)长期各自为政,几乎没有架构层面的共享。 • 分子模型通常假设有限体积的孤立系统,无法处理晶格周期性;材料模型则依赖分数坐标和晶格参数的特殊表示,不适用于分子。
割裂二:任务割裂
• 生成模型(如扩散/流匹配模型)专注于从头设计新结构,但不具备直接预测物理化学性质的能力。 • 预测模型(如 Equiformer、PaiNN、eSEN)高度优化于单一性质的精确预测,但不具备生成能力,且每个任务通常需要独立的超参数调优和训练流程。
这种碎片化导致严重的工程与科研效率问题:一个希望同时探索分子设计和性质预测的研究人员,往往需要维护、训练和调试数十个不同的专门模型。
1.2 科学基础模型的新范式
受 NLP 领域 BERT/GPT 和蛋白质领域 AlphaFold3 的成功启发,研究者开始寻找"化学版基础模型"——能够通过大规模无监督预训练获得通用化学表示,再迁移至多种下游任务。
ZATOM-1 的核心假设:生成式流匹配预训练天然是一种强力的自监督学习信号,其习得的表示能够迁移至性质预测任务,且跨领域(分子↔材料)联合预训练能产生正向迁移,而非负迁移或中性影响。
这一假设此前在 3D 化学领域从未被系统验证,ZATOM-1 提供了首个肯定性的实证证据。
2. 核心问题定义
2.1 统一表示
ZATOM-1 将任意 3D 原子系统(分子或材料)统一表示为五种模态的联合分布:
关键设计:
• 对于非周期分子,分数坐标、晶格边长和角度输入被遮盖为空值 ,损失函数相应屏蔽。 • 对于周期性材料,3D 笛卡尔坐标输入被遮盖为 ,以强制模型使用分数坐标,默认实现旋转不变性。
这一统一设计使得同一模型能够无缝处理两类化学系统,而无需任何领域特定的架构分支。
3. 模型架构详解
3.1 主干网络:Trunk-based Flow Transformer(TFT)
ZATOM-1 的核心架构是标准 Transformer,称为基于主干的流变换器(TFT),其设计哲学是"最大化标准化"——避免手工设计的等变归纳偏置,让模型通过数据增强习得对称性。
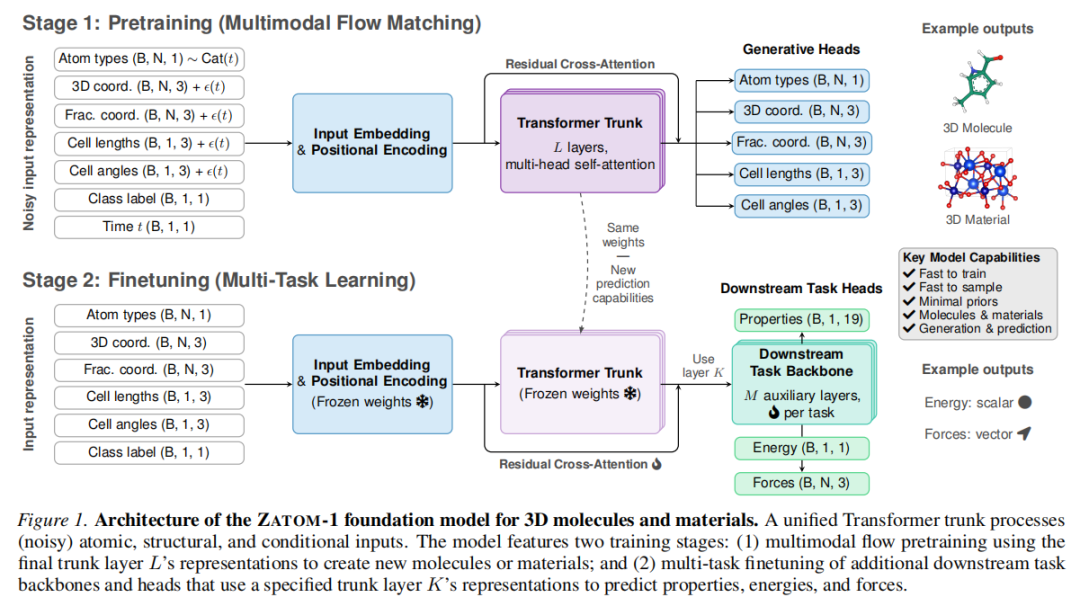
架构组件
三种模型尺寸
3.2 前向传播流程
完整的前向传播分为四个步骤(对应 Algorithm 1):
步骤 1:输入嵌入与位置编码
对于含噪声的原子系统 ,每个原子的初始隐层状态为:
其中 是周期性/非周期性类别标签(训练时以 10% 概率随机丢弃,以支持无分类器引导), 是流匹配时间步, 表示无偏置线性层。
步骤 2:Transformer 主干编码
层 Transformer 编码器产生中间表示 和第 层中间表示 (用于下游任务):
步骤 3:残差交叉注意力去噪头
主干输出 与原始输入嵌入 通过 Transformer 解码器块进行残差交叉注意力,分别得到各模态的精炼表示:
步骤 4:模态去噪预测
• 原子类型(离散): • 3D 坐标(连续): • 分数坐标:同上 • 晶格边长/角度:先对 个原子的表示取均值,再通过 LayerNorm + Linear,得到全局标量预测
3.3 数据对称性学习策略
与 AlphaFold3 类似,ZATOM-1 通过随机数据增强习得对称性,而非硬编码等变性:
• 分子:每个训练样本随机应用 SO(3) 旋转(每批次 8 个增强副本) • 材料:额外施加随机平移增强,学习周期性平移不变性
这一选择带来的代价是需要更多数据和计算来习得对称性,但收益是架构极度简洁、与工业界主流 Transformer 生态高度兼容。
4. 训练方法:多模态流匹配
4.1 流匹配基础
条件流匹配(CFM)是一种训练生成模型的可扩展技术。其核心思想是训练神经网络 近似从源分布向目标分布输运样本所需的时变速度场:
其中 ,(线性插值路径)。
相比扩散模型的优势:
• ODE 积分仅在采样时需要,训练时无需迭代去噪 • 线性插值路径比扩散的随机微分方程更直接,梯度更干净 • 可使用更少的积分步骤达到相同质量(本文 或 步即可)
4.2 连续模态:Euclidean CFM
对于 、、、 四种连续模态,前向过程为:
损失函数为端点预测(endpoint formulation)的均方误差:
采用端点而非速度预测的原因:经验结果表明,预测去噪端点在科学应用中表现更稳定(Stark et al., 2024)。
4.3 离散模态:Discrete CFM
原子类型 是整数,不能直接用欧几里得扩散处理。ZATOM-1 采用离散流模型(Campbell et al., 2024)中的 Discrete CFM:
即在时刻 时,以概率 保持真实原子类型的 one-hot 分布,以概率 保持均匀分布。损失函数为交叉熵:
4.4 总损失函数
五种模态的损失统一为加权多目标:
训练时设 ,对离散损失适当降权以平衡尺度差异。
4.5 关键训练技巧
① 时间步非均匀采样
相比均匀采样 ,Beta 分布在 (接近干净数据)附近采样更多,强迫模型学习高精度细节。
② 损失时间缩放
当 时,, 趋于零,梯度消失。为此引入时间自适应损失权重:
在接近数据端时大幅放大损失,迫使模型精确学习干净结构的细节。
③ EMA 权重平均
推理时使用指数移动平均权重(),显著提升生成质量的稳定性。
4.6 多模态采样算法
推理时交替对每种模态执行一步 Euler 积分(Algorithm 2):
• 离散步(原子类型):基于 Campbell et al. (2024) 的离散流跳转率矩阵,更新每个原子的类别分布 • 连续步(坐标/晶格):结合漂移项 、得分函数项 和可选白噪声 的随机 Euler 步:
其中 为噪声调度函数, 为白噪声强度超参数(通常设为 ,对非周期小分子坐标设为 )。
反直觉发现:启用无分类器引导(Classifier-Free Guidance)会使材料有效率从 90% 骤降至 40%,原因尚不明确,论文默认禁用。
5. 阶段二:多任务预测微调
5.1 微调策略
预训练完成后,冻结主干所有权重,仅训练新增的下游任务组件:
• 下游任务主干: 层辅助 Transformer,使用主干第 层的冻结嵌入 作为输入(通过残差交叉注意力注入),每个任务独立训练 • 默认 (最终层),消融实验表明材料任务用 更优(详见第 8 节)
这种设计的优势:不同任务的主干权重完全共享(零边际存储成本),辅助头极轻量(~20M 参数),且冻结主干避免了对生成能力的灾难性遗忘。
5.2 各任务损失函数
性质预测(19 个 QM9 属性):批内 MAE
能量预测:批内 MSE
原子力预测(加权 MSE):
5.3 微调时间步分布
微调阶段时间步采样改为:
即大量集中在 附近(接近干净数据的区域),确保模型从近乎真实的结构出发进行性质预测,最大程度减少噪声干扰。
6. 实验设置
6.1 数据集
6.2 关键推理超参数
| 50 | |||
注意:QM9 的坐标噪声设为 50 而非 0.01,是因为小分子系统需要更大的随机扰动来提升样本多样性,避免模型坍缩到少数高概率构象。
7. 实验结果全面分析
7.1 晶体材料生成(LeMat-GenBench / MP20)
使用 LeMat-GenBench 评估框架,对 2,500 个采样晶体通过 MLIP 集成(Orb-v3、MACE-MP、UMA)进行严格评估。
7.1.1 关键结果
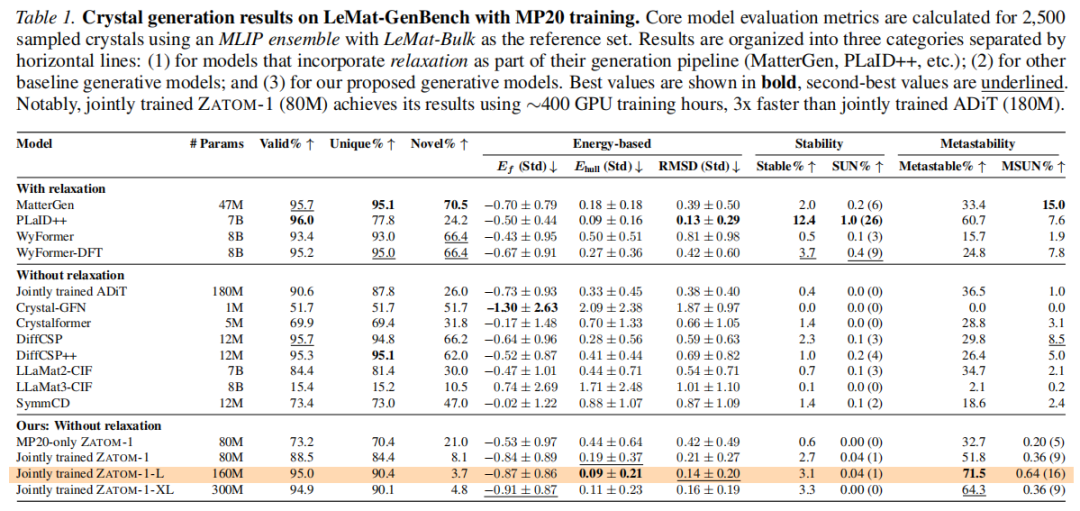
7.1.2 分析
优势:
• ZATOM-1-L/XL 在有效率上达到甚至超越 DiffCSP 等等变基线,且无需弛豫后处理 • 亚稳率(Metastable%)显著领先,ZATOM-1-L 达 71.5%,大幅超越所有无弛豫方法 • 生成样本的平均形成能最低( eV),表明模型倾向于生成热力学稳定结构 • 训练效率突出:80M ZATOM-1 仅需约 400 GPU 小时,而 ADiT (180M) 需 ~1,200 GPU 小时
不足:
• 新颖率(Novel%)极低(3.7%~8.1%),远低于 DiffCSP 的 66.2% 和 MatterGen 的 70.5%。这是过拟合 MP20 训练分布的典型症状,与数据集规模过小直接相关。稳定性高但新颖性低,反映了模型在记忆与泛化之间的权衡。 • SUN(稳定+唯一+新颖)指标几乎为零,正是新颖率低的直接后果。
7.2 小分子生成(QM9)
7.2.1 有效率与唯一率
| ZATOM-1 | 联合(单阶段) | 80M | 94.94% | |
| ZATOM-1-L | 联合(单阶段) | 160M | 95.26% |
ZATOM-1 用 80M 参数、单阶段训练达到了与 180M ADiT 相当的有效率,且仅需 400 GPU 小时对比 ADiT 的 1,200 GPU 小时。
7.2.2 PoseBusters 物理合理性检验
对 10,000 个生成分子进行 7 项严格物理检验,ZATOM-1 整体通过率约 99%(vs. ADiT 的 ~95%),尤其在内能合理性(99.78% vs. 95.86%)方面有显著优势:
| 99.98% | ||||
| 99.95% | ||||
| 100.00% | ||||
| 100.00% | 100.00% | 100.00% | 100.00% | |
| 99.98% | 99.99% | |||
| 内能合理 | 99.78% | |||
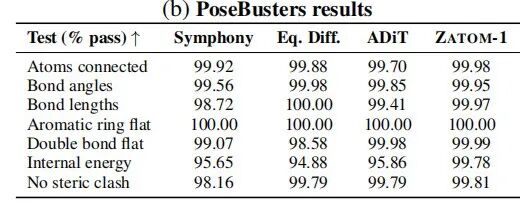
内能合理性的大幅领先表明 ZATOM-1 生成的构象具有更优的热力学合理性,这对药物设计应用尤为重要。
7.3 大分子生成(GEOM-Drugs)
GEOM-Drugs 包含最多 180 个原子的大型类药分子,是检验模型泛化能力的关键基准。
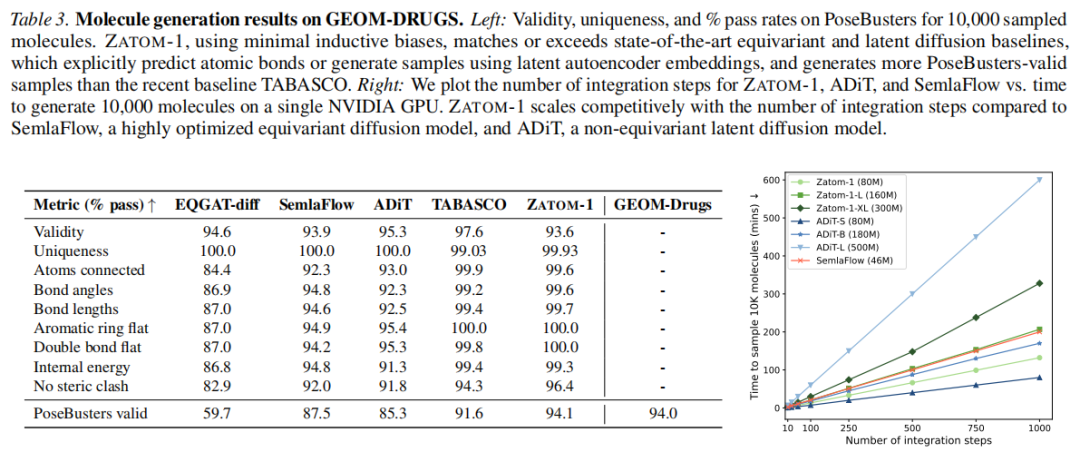
ZATOM-1 是唯一在 GEOM-Drugs 上达到 PoseBusters 综合通过率理论上限(94%)的生成模型,表明其生成的药物样大分子在物理合理性上接近真实药物构象的天花板。
值得注意的是,TABASCO 的有效率(97.6%)高于 ZATOM-1(93.6%),但在 PoseBusters 综合通过率(尤其是位阻碰撞检测)方面劣于 ZATOM-1,表明高有效率不一定意味着高物理真实性。
7.4 推理速度对比
在单张 NVIDIA A100 GPU 上生成 10,000 个样本,ZATOM-1 相比基线的速度优势随积分步数增加而扩大:
| ZATOM-1 | 80M | ~23 分钟 | ~32 分钟 |
| ZATOM-1-XL | 300M | ~60 分钟 | ~80 分钟 |
速度优势来源于两个因素:
1. 无潜扩散开销:ADiT 需要先通过自动编码器将原子系统映射到潜空间,再在潜空间扩散,每次推理需要额外的编解码过程。 2. 线性序列推理:TFT 的注意力在 (原子数)维度是 ,对于 QM9/MP20 规模()的小体系,这一开销完全可以忽略。
7.5 多任务性质预测(QM9)
这是本文最具说服力的结果之一,验证了"生成式预训练改善预测性能"的核心假设。
| 14 | 13 | ||||||
| .038 | |||||||
| 联合预训练 ZATOM-1 | 未优化多任务 | .091 | 46.2 | 34 | 32 | .090 | .041 |
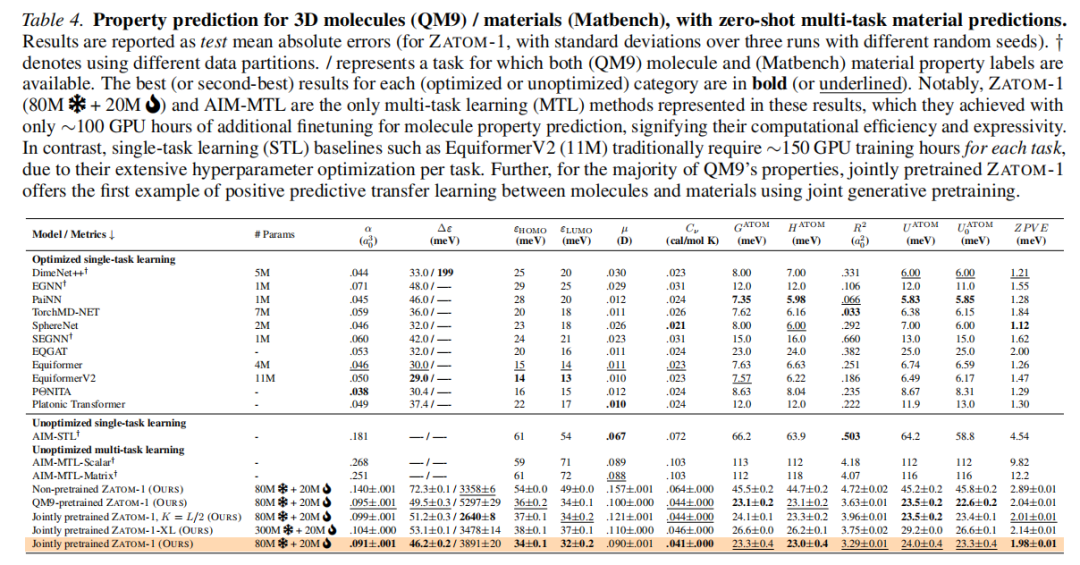
核心发现:
• 联合预训练(同时包含材料数据)比仅分子预训练在大多数属性上误差更低,这是跨化学域正向迁移的直接证据。 • ZATOM-1 在多任务设置下接近甚至超越部分单任务专门模型(如 AIM-STL),而单任务基线通常每个任务需约 150 GPU 小时超参数调优,ZATOM-1 多任务微调仅需约 100 GPU 小时。
8. 消融研究与关键洞见
8.1 联合训练 vs. 单一领域训练
| 联合 QM9 + MP20 | 88.5% | 51.8% | 94.94% |
联合训练在两个域上均优于对应的单域训练,充分验证了"跨化学域互补增益"假设。
8.2 主干层选择 K 的消融(下游预测)
预训练主干第 层的嵌入用于下游任务时,不同层表现差异显著:
| 最优 | ||
| 最优 |
这一现象揭示了主干层次的语义分工:较深层更专注于分子细节,中间层包含更多跨域通用表示,对未见过的材料性质任务具有更好的零样本泛化能力。这与 NLP 中关于 BERT 层次的经典分析高度吻合。
8.3 模型规模的影响
Figure 3 呈现的规模化结果具有重要意义:
• 训练损失 vs. 参数量:在 epoch 2000 时,Pearson 相关系数为 (完美负相关),参数越多损失越低 • 晶体有效率 vs. 参数量:Pearson = ,Spearman = • 分子有效率 vs. 参数量:Pearson = ,Spearman =
这种近乎完美的规模化规律表明 ZATOM-1 的架构设计(标准 Transformer + QKNorm)已进入稳定的规模化机制,符合 Kaplan et al. (2020) 的神经网络规模化定律。
重要例外:预测任务的性能并不随主干规模单调提升(ZATOM-1-XL 的预测性能弱于 ZATOM-1)。作者将此归因于预训练数据集规模过小——当数据量固定时,过大的模型容量导致过拟合,而非欠拟合。
8.4 推理超参数的影响
通过系统超参数扫描(Figure 5),关键发现如下:
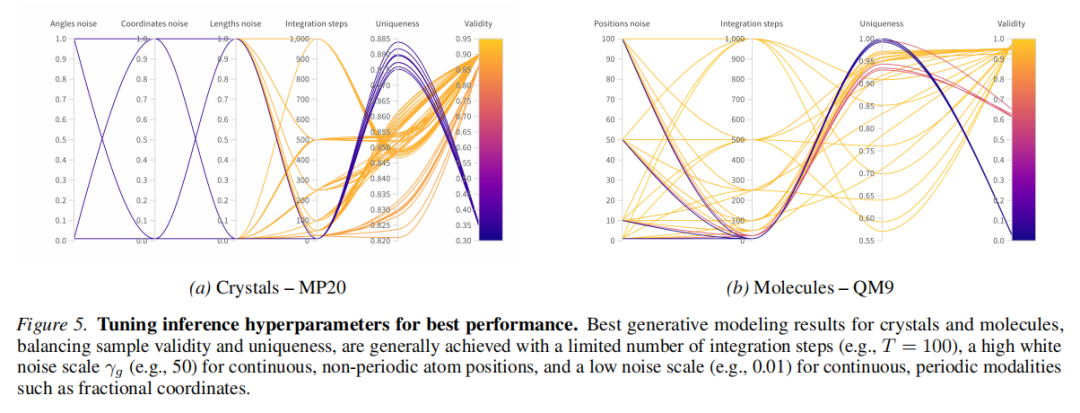
• 积分步数 : 或 即可达到峰值质量,继续增加收益递减 • 白噪声强度 : • 非周期小分子坐标:需要相对较大的噪声()来提高样本多样性 • 周期性材料(分数坐标、晶格参数):需要小噪声(),大噪声破坏晶体几何约束 • 无分类器引导:默认禁用(启用后材料有效率从 90% 骤降至 40%)
9. PLATOM-1:等变变体的启示
9.1 架构:Trunk-based Flow Platoformer(TFP)
PLATOM-1 将 TFT 的标准 Transformer 层替换为 Platonic Transformer 层(Islam et al., 2025),实现对 Platonic 实体的离散旋转-反射子群 的等变性(如正四面体群 或正方体群 )。
特征张量从 变为 (正则 -表示),其中:
• 标量特征(如原子类型)提升为 -不变特征 • 向量特征(如坐标)提升为编码方向信息的非平凡特征
计算效率:为使计算成本与 TFT 相当,设 ,对正四面体群():
• PLATOM-1 参数量约为 ZATOM-1 的 (23M vs. 80M) • 计算量约等于 ZATOM-1(两者计算匹配) • 参数效率提升 倍(等变约束的权重共享)
9.2 实验结果
| PLATOM-1(QM9 单训) | 23M | 249 | 95.20% | ~99.84%(估算) |
关键结论:
• 23M 参数的 PLATOM-1 超越了 300M 参数的 ZATOM-1-XL,表明在数据量有限时,等变归纳偏置的价值相当于约 13 倍参数量的增加 • 收敛提前 37%(249 epoch vs. 399 epoch),等变性显著加速了对称性的习得
9.3 当前局限
PLATOM-1 的等变设计与材料的分数坐标表示根本不兼容:分数坐标是标量,在正则 -表示中提升为不变特征,模型无法感知原始欧几里得几何,导致联合训练不收敛。
未来方向:基于欧几里得坐标统一表示材料(而非分数坐标),使 PLATOM-1 能够进行跨域联合训练。
10. 局限性与未来方向
10.1 已知局限性
| 新颖率低 | ||
| 能量预测弱 | ||
| 数据规模限制 | ||
| MOF 有效率低 | ||
| 材料等变扩展 | ||
| CFG 失效 |
10.2 未来方向
作者明确指出的优先方向:
1. 扩大预训练数据:使用 LeMat-Bulk(500万晶体)和 OMol25(400万分子)进行更大规模预训练 2. 每模态独立噪声调度:在微调阶段为各输入模态设计定制化的噪声添加策略,提升能量预测精度 3. PLATOM-1 联合训练:采用统一欧几里得坐标表示材料,使等变变体支持跨域联合训练 4. 结构多样性数据增强:改进材料的新颖率,可能通过更大的训练集或多样性约束的引导采样实现
11. 与相关工作的系统对比
11.1 与 ADiT 的详细对比
ADiT(Joshi et al., 2025)是 ZATOM-1 最直接的竞争对手,两者都统一建模分子和材料,下面系统对比其设计选择:
| 生成范式 | ||
| 架构 | ||
| 需要自动编码器 | ||
| 参数量 | ||
| 推理速度(100步,10K样本) | 分子 ~32 分钟(6×快) | |
| QM9 有效率 | ||
| GEOM-Drugs PoseBusters | 94.1% | |
| GPU 训练时长 | ~400 小时(联合) | |
| 下游预测支持 | ||
| 开源 |
11.2 与等变方法的对比
等变方法(如 Equivariant Diffusion、DiffCSP、SemlaFlow)将旋转/平移不变性/等变性硬编码入架构:
| 对称性处理 | ||
| 参数效率 | ||
| 收敛速度 | ||
| 跨域泛化 | ||
| 推理速度 | 极快(密集 Transformer) | |
| 可扩展性 | 优秀(符合 scaling law) |
11.3 与潜扩散方法的对比
| 训练复杂度 | ||
| 推理链路 | ||
| 信息损失 | ||
| GPU 小时 |
12. 总结与影响评估
12.1 核心贡献总结
ZATOM-1 做出了以下系统性贡献:
| 方法论 | |
| 跨域迁移 | |
| 统一建模 | |
| 效率 | |
| 规模化 | |
| 开源 |
12.2 对未来研究的启示
对模型设计的启示:
• 标准 Transformer 加适当归一化技巧(QKNorm + SwiGLU)足以在化学领域取得竞争性表现,无需大量领域特定设计 • 等变性(PLATOM-1)在小数据量下的优势相当于 13 倍参数扩展,值得在数据受限的化学应用中认真考虑 • 无分类器引导在生成化学结构时可能适得其反,需要更细致的分析
对研究范式的启示:
• "生成式预训练→预测式微调"在 3D 化学领域是可行且有效的,与 NLP 的 BERT/GPT 范式高度一致 • 不同化学领域的联合训练不仅无害,反而能产生互补增益,支持未来构建覆盖更多化学子领域的大型统一模型
参考文献(核心引用)
• 流匹配基础:Lipman et al. (2023), Albergo & Vanden-Eijnden (2023), Tong et al. (2024) • 离散流匹配:Campbell et al. (2024) • Flash Attention:Dao (2024) • QKNorm 稳定性:Wortsman et al. (2024) • SwiGLU:Shazeer (2020) • 主要竞争方法:ADiT (Joshi et al., 2025), DiffCSP (Jiao et al., 2023), MatterGen (Zeni et al., 2025), Eq. Diffusion (Hoogeboom et al., 2022), SemlaFlow (Irwin et al., 2025) • 评估框架:LeMat-GenBench (Duval et al., 2025), PoseBusters (Buttenschoen et al., 2024) • 神经规模化定律:Kaplan et al. (2020) • Platonic Transformer:Islam et al. (2025)
本文基于 arXiv:2602.22251v2(2026 年 3 月 4 日版本)整理,如有引用请以原始论文为准。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢