

Agent 的实时进化,又迎来新进展。
普林斯顿大学王梦迪教授团队提出的 OpenClaw-RL 框架,能够系统性地挖掘每一轮 Agent 交互背后的隐藏价值,将个人对话、终端执行等多种场景下的“下一个状态信号”统一转化为在线学习源,为通用 Agent 的实时进化提供了一种全新解决方案。

论文链接:https://arxiv.org/abs/2603.10165
两个被浪费的有价值信号
在日常使用 AI 助手、coding Agent 时,每一次交互都会产生大量的“下一状态信号”,无论用户的追问、工具的输出结果,还是界面状态的改变。
然而,在现有的 AI 系统中,这些信号往往仅被视为生成下一轮对话的上下文背景,信息被提取后随即被丢弃,并未能转化为实时训练模型的宝贵数据资源。这构成了当前AI训练中一种巨大的“隐形浪费”。
这两个被浪费的有价值信号具体表现为评估信号与指导信号。
评估信号,即下一状态信号隐含的对前一动作的评分,例如用户的重新查询往往意味着对之前回复的不满,而测试的通过或错误日志的出现则分别标志着成功或失败。这种自然的反馈构成了无需额外标注的过程奖励,不仅能够捕捉个人 Agent 在对话中的用户满意度,还能为通用 Agent 在长期任务中提供密集的步骤级信用分配,但现有系统往往忽略这一实时来源或仅将其用于离线训练。
除了给出好坏的评分,下一状态信号中往往还藏着具体的改进建议。比如用户说“你应该先检查文件”,这句话不仅告诉 AI “你错了”,还指明了“该怎么改”。同样,软件工程中的详细报错信息也暗示了修正方向。然而,现有方法要么只会用“对/错”这样的分数来训练,要么依赖提前准备好的“问答对”做模板,都没能利用好这些实时的、带有具体指导意义的反馈信号。
OpenClaw-RL框架的核心突破
据论文介绍,OpenClaw-RL 能够在与 OpenClaw 的个人对话、终端、GUI、SWE 及工具调用环境等多种场景下,为个人 Agent 和通用 Agent 恢复上述两种形式的下一个状态信号浪费。
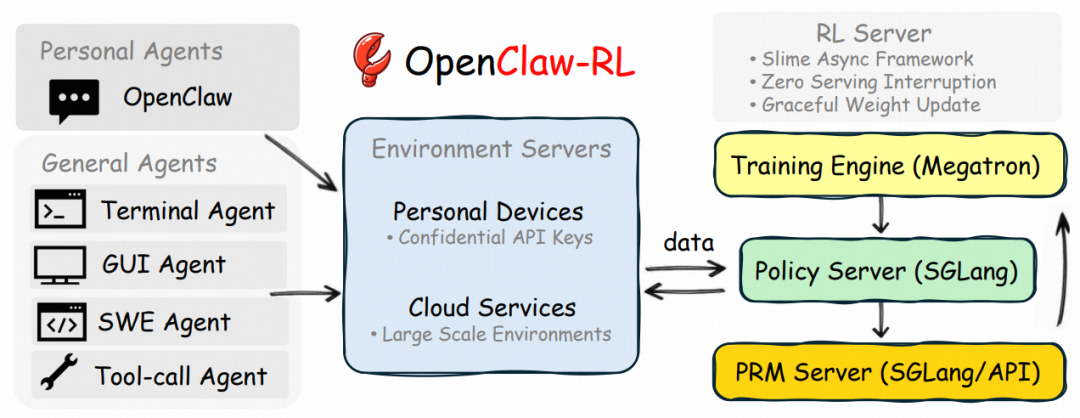
图|OpenClaw-RL 基础设施概述。
为了捕捉其中的评估信号,框架采用二元强化学习(Binary RL),利用过程奖励模型(PRM)依据用户回复或环境输出对每一轮交互进行评分。具体而言,PRM 会根据用户的下一条回复或环境的执行结果,将 Agent 上一轮动作评为+1(好)、-1(坏)或0(中性),并通过多次独立评判后的多数投票获得稳定的标量奖励。这一方法的优势在于覆盖了所有交互,为策略优化提供了一个全局性的的改进方向。
同时,为了从下一状态中获取更具体的指导信号,事后指导同策略蒸馏(OPD)致力于提取诸如用户更正等文本提示,构建出能够帮助模型“事后明白”正确答案的增强提示。
当用户给出明确指正时,系统会从下一状态中提取文本提示,追加到原始对话上下文中,构建增强版教师上下文。随后让同一模型在此增强上下文下重新计算原始答案的令牌概率,与学生模型的原始分布进行比较,二者的对数概率差便构成令牌级方向性优势信号:正差强化该令牌,负差则抑制它。这种方法提供了远超标量奖励的细粒度监督,能够精确到每一个词。
OpenClaw-RL 将这两种优势互补的方法进行了有机结合,利用二元 RL 覆盖所有样本的基础信号,同时让 OPD 专注于包含明确指导的高质量样本。实验结果表明,通过加权结合这两种方法的损失函数,这种混合训练策略能够带来显著的性能提升。
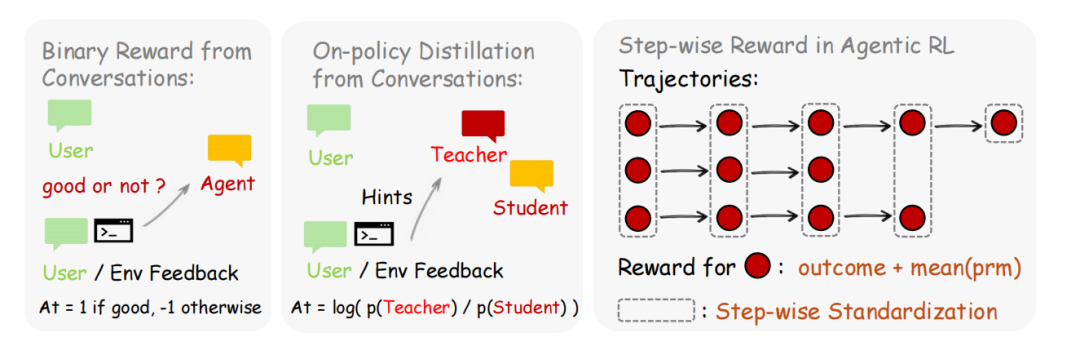
图|方法概述。针对个人 Agent,同时支持二元奖励优化和策略蒸馏训练。实验表明,二者结合可显著提升性能。
应用场景与实验验证
为验证 OpenClaw-RL 的有效性,研究团队在个人 Agent 和通用 Agent 两大场景上分别开展了实验。
在个人 Agent 的实验验证中,团队设计了两个贴近日常使用的模拟场景。在“学生”场景中,模拟学生使用 OpenClaw 完成作业并试图隐藏 AI 使用痕迹,经过优化后的模型学会了避免生硬的 AI 式措辞,转而生成更加自然、拟人的回答;而在“教师”场景中,模拟教师借助 OpenClaw 批改作业并期望评语具体且友好,模型在优化后其评语变得详细且亲切。
量化结果进一步印证了方法的有效性。在结合二元强化学习和 OPD 后,模型的个性化得分从基础 0.17 跃升至 0.81,仅需 36 次交互即可实现显著改进,证明了 OpenClaw-RL 在个人场景下的快速适应能力。
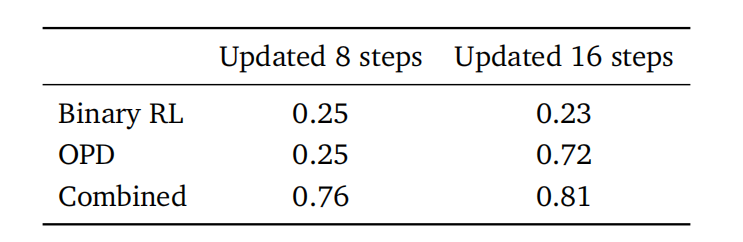
图|不同方法在优化 OpenClaw 中的表现。基线得分为0.17。
在通用 Agent 的应用层面,OpenClaw-RL 展现了卓越的泛化能力,成功覆盖了终端操作、图形用户界面交互、软件工程任务(SWE)以及工具调用等多种复杂环境。
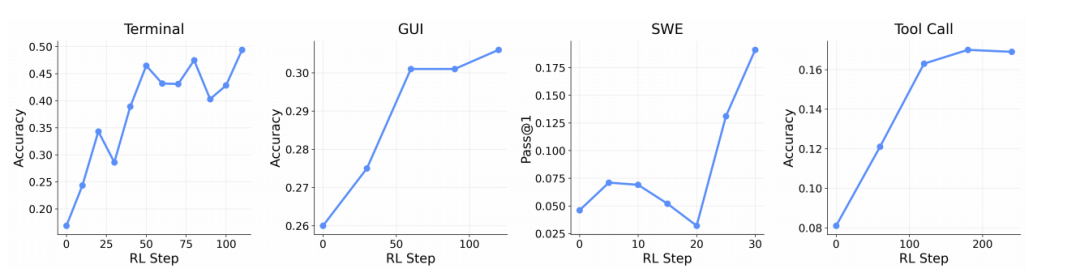
图 | 框架支持跨终端、图形用户界面(GUI)、Swe 及工具调用设置的通用 Agent 进行可扩展强化学习(RL)。
研究发现,将过程奖励与结果奖励相结合,效果始终优于仅使用结果奖励:在工具调用任务上,准确率从0.17提升至0.30;在GUI任务上,从0.31提升至0.33。这一结果证明,对于需要多步交互的长周期任务,仅靠最终结果提供监督信号是远远不够的,而来自每一轮交互的密集过程奖励能够为模型提供更精准的逐步指导,从而显著提升任务完成质量。
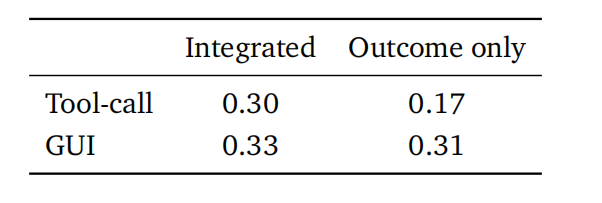
图|在不同场景中整合结果与过程奖励的绩效表现。
此外,该框架还表现出强大的可扩展性,能够支持从 4B 到 32B 不同规模的模型,并实现了最高 128 个并行环境的大规模部署,为未来通用 Agent 的广泛应用奠定了坚实基础。
意义与展望
OpenClaw-RL 的提出标志着 Agent 训练方式的重大革新。
研究团队首次将“下一状态信号”系统性地设计为实时学习源,成功突破了传统强化学习依赖离线数据集的局限。同时,这也是首个支持多交互流异步并行的通用 Agent RL 框架,通过完全解耦的架构实现了学习过程的零中断。
这一成果对于不同群体具有深远意义:对于个人用户而言,Agent 将在日常使用中通过自然的交互持续优化,无需任何额外的数据标注工作;对于开发者而言,这一统一的框架极大地降低了多模态 Agent 训练的技术门槛,并支持在云端进行高效、弹性的扩展部署。
作者:王跃然
如需转载或投稿,请直接在本文章评论区内留言。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢