

当前的主流人工智能(AI)视频生成模型普遍只能生成 5-10 秒的片段,且一次生成动作的时间间隔分钟,距离真正的实时交互相差太多。令人遗憾的是,现有的加速方案主要以牺牲质量为代价,要么依赖 KV 存储、稀疏稀疏等技巧,要么将模型规模压缩至 13 亿(1.3B)参数以换取速度,导致复杂的运动表达严重的能力模糊,高精度间隙细节模糊失真。
那么,AI 视频生成模型真的无法兼顾质量与速度吗?来自北京大学、字节跳动的研究团队及其合作者,提供了一个有希望的解决方案。
他们提出的大小为 140 亿(14B)参数的视频生成模型 Helios,能够在单张 NVIDIA H100 GPU 上以 19.5 帧/秒的运行,生成速度甚至优于部分 13 亿参数的视频生成模型,同时可以保持生成质量。

论文链接:https://arxiv.org/abs/2603.04379
主要贡献如下:
在未使用抗漂移策略(如自强制、误差库、关键帧采样或反向采样)的情况下,Helios 能够生成高质量、强连贯性的分钟级视频。
在未使用标准加速技术(如 KV 缓存、因果掩码、稀疏/线性注意力、TinyVAE、渐进噪声调度、隐藏状态缓存或量化)的情况下,Helios 在单张 H100 GPU 上对一个 14B 视频生成模型实现了 19.5 FPS 的端到端推理速度。
他们引入了优化措施,在减少内存消耗的同时提高了训练和推理吞吐量。这些改进使得在没有并行或分片基础设施的情况下训练一个 14B 视频生成模型成为可能,其 batch 大小与图像模型相当。
Helios是怎样练成的?
Helios 的强大性能得益于以下 3 点核心突破:
一是无限视频生成能力,通过统一历史注入框架,将固定长度的双向预训练模型转化为自回归生成器,实现支持 T2V、I2V、V2V 任务的无限视频续写能力;
二是高质量视频生成能力,是针对位置、色彩、修复三类视频漂移问题,提出高效抗漂移训练策略,无需昂贵长视频微调即可稳定生成分钟级高质量视频;
三是实时视频生成能力,是借助深度压缩流与基础设施级优化,从 token 和采样步数压缩成本,让 14B 大模型的计算成本降至 1.3B 模型及以下水平,实现高效实时生成。
为了实现目标,团队围绕着三个关键维度对 Helios 进行了系统性创新。下面,将对这三大维度展开具体剖析。
1.无限视频生成
通过统一历史注入框架,将一个原本只能生成固定长度的双向预训练模型,转化为一个自回归生成器,并原生支持文本生成视频(T2V)、图像生成视频(I2V)和视频生成视频(V2V)三种任务。
Helios 核心思想是通过历史帧 X-Hist(始终保持 t=0 干净帧)为显式条件输入,与待生成的噪声帧 X-Noisy 拼接后进行去噪,生成与已有内容时序自然衔接的新片段;将新生成片段并入历史帧后循环迭代,实现视频长度的无限延展。
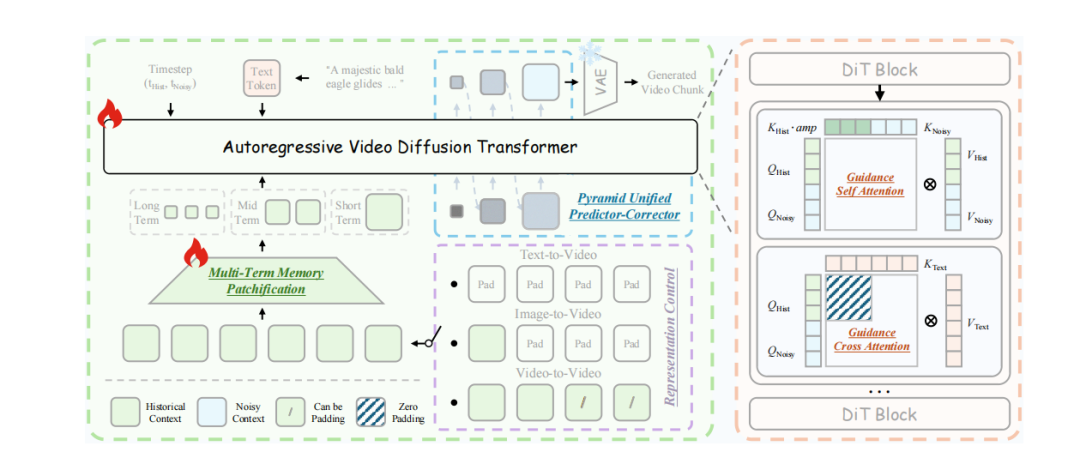
图|Helios 整体架构。它是一个基于引导注意力块的自回归视频扩散 Transformer。通过多阶段记忆分块化和金字塔统一预测校正器,大幅压缩历史与噪声上下文,并通过表示控制统一了 T2V、I2V、V2V 任务。
2.高质量视频生成
论文提出了长视频生成中三种代表性漂移模式,并提出了对应的解决方案。

图|长视频生成中三种代表性的漂移模式:位置偏移、颜色偏移、修复偏移。
位置偏移是当推理阶段的视频长度超出训练时使用的时间范围时,模型接触未知时间位置导致生成质量下降。Helios 提出相对 RoPE,将历史帧时间索引固定为 0~T-Hist,当前生成片段映射为 T-Hist~T-Hist+T-Noisy,实现任意长度稳定生成并减少重复运动。
颜色偏移是随着生成长度增加,会加剧色彩偏移。研究发现正常视频统计特征稳定,漂移视频后期明显偏移且漂移极少出现在初期;因此保留历史首帧作为全局视觉锚点,限制后续帧分布偏移,稳定视频统计特征并减少颜色漂移。

图|正常视频与漂移视频在饱和度、美学及 RGB 统计量的时间趋势对比。正常视频保持稳定,而漂移视频初期呈现相似轨迹,但随后突然偏移并持续不稳定。
修复漂移是模型在推理时却依赖自身生成的、不完美的历史帧,误差会随时间不断累积。Helios 提出帧感知腐蚀机制,在训练时对每个历史帧独立随机施加曝光变化、噪声添加、下采样再上采样等扰动,模拟真实推理中的历史误差,提升模型对不完美历史的鲁棒性,使长视频生成更稳定。
3.实时视频生成
实时生成的关键在于“降本增效”。为此团队从减少 token 数量与减少采样步骤两个维度同时发力。
对历史上下文采取分层压缩,距当前帧越近的历史,保留越精细的细节;越久远的帧,压缩率越高。这一设计符合也削减了历史帧侧的 token 总量。
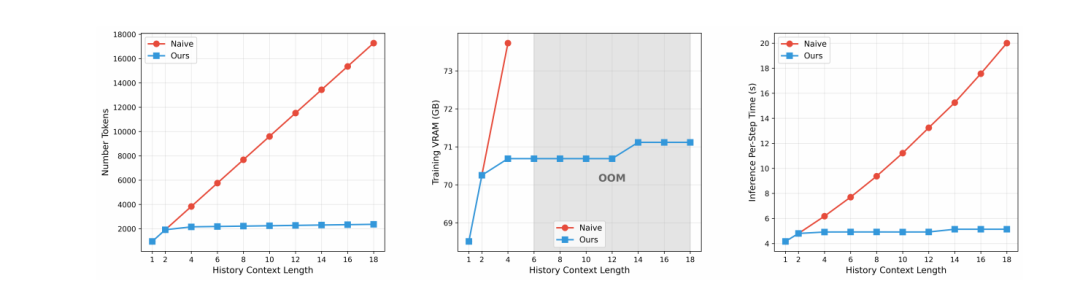
图|多尺度记忆块化的开销削减。分层历史窗口采用逐级增大的卷积核,在将上下文长度不断延伸的同时,保持 token 总量恒定不变。
金字塔统一预测校正器,可以减少嘈杂上下文 X-Noisy 中的冗余。Helios 团队采用从粗到细的生成策略。在早期阶段于低分辨率潜在空间进行采样,随后逐步过渡到高分辨率并恢复完整细节。
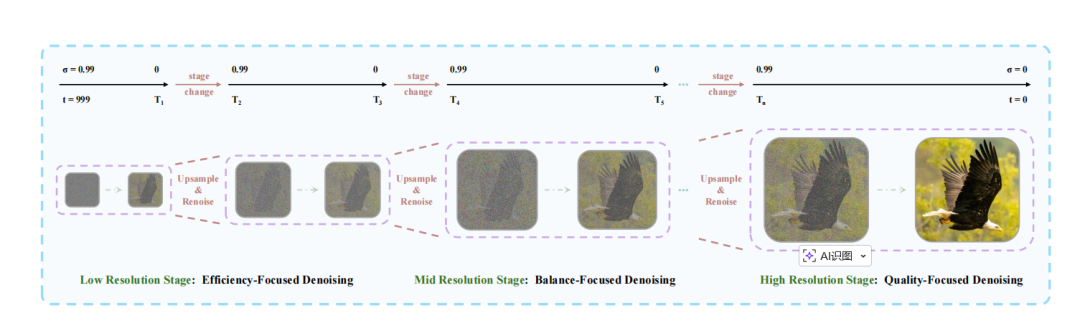
图|金字塔统一预测校正器的概述。该过程分为三个阶段:(i) 低阶段注重效率,(ii) 中阶段平衡质量和效率,(iii) 高阶段优先考虑质量。
Helios 提出的对抗分层蒸馏,在蒸馏阶段,使用能够生成高质量长视频的 Helios-Base 作为教师模型,并始终以真实视频帧作为历史上下文。这种设计仅需在每个训练步骤生成一个片段,大幅提高了训练效率,同时保持长视频生成的稳定性。
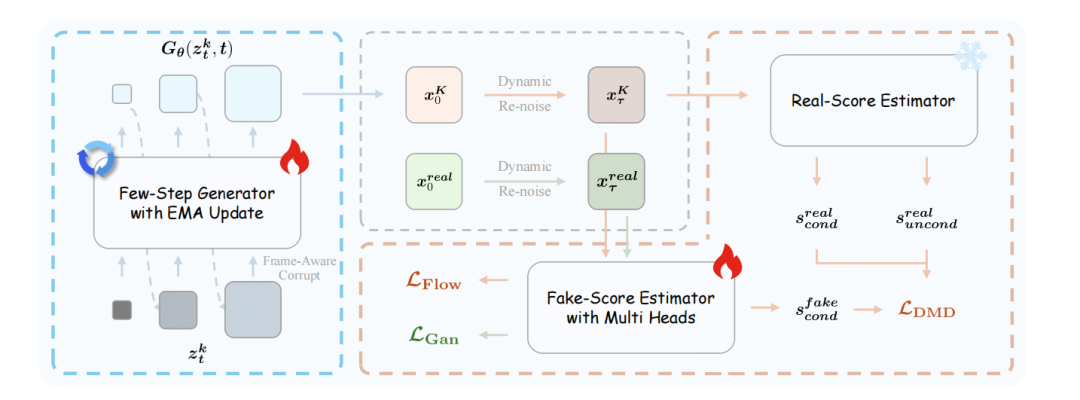
图|对抗性分层蒸馏流程。该框架基于 DMD,并进行了改进,包括纯教师强制、分阶段反向模拟、粗到细学习以及对抗性后训练等。
实验结果
为了解决实时长视频生成缺乏标准化基准的问题,研究团队构建并开源了 HeliosBench。HeliosBench 该测试集包含 240 条经过大语言模型(LLM)优化的提示词。评估涵盖四个时长等级:超短 (81 帧)、短 (240 帧)、中 (720 帧) 和长 (1440 帧)。
短视频生成(81帧):在 81 帧超短视频测试中,Helios 取得了 6.00 的总分,超越了所有已知的蒸馏模型,并达到了与同等规模基础模型相当的水平。
长视频生成(120-1440帧):Helios 在长视频综合得分上达到了6.94,超越了当前最强的基线 Reward Forcing(6.88)。Helios 在各项漂移指标上表现更稳定。用户研究也证实,无论是长视频还是短视频,人类评估者都显著更偏爱 Helios 生成的结果。
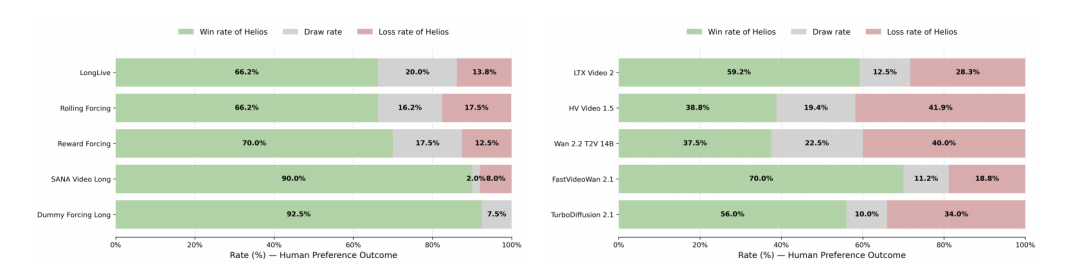
图|Helios 与对比模型的人工评估结果。
在单张H100上,Helios 的推理速度远超同级别的模型,甚至快于一些经过蒸馏的 1.3B 小模型。同时,在短、长视频生成任务上,其质量评分均显著优于现有的蒸馏模型,与强大的基础模型性能相当。
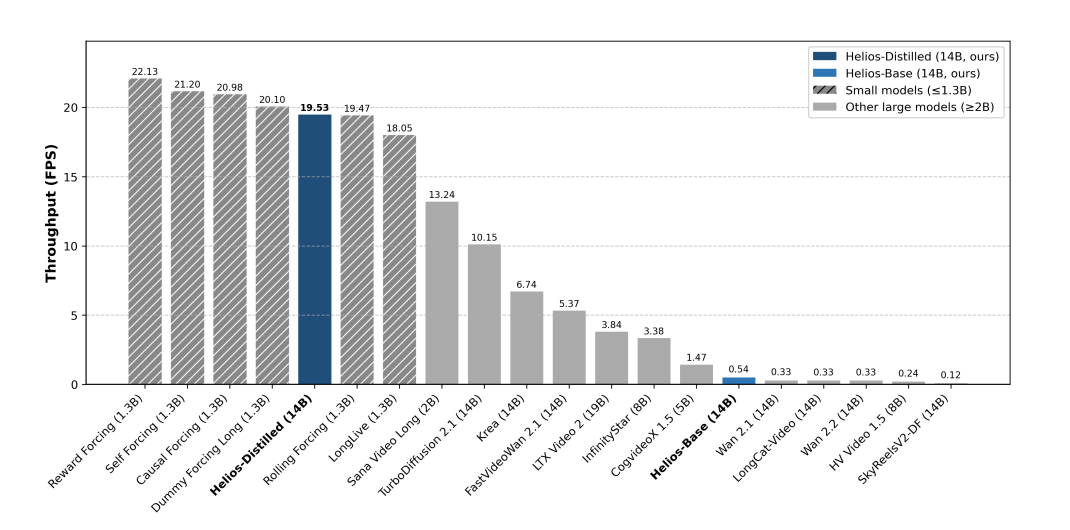
图|H100架构上各类视频生成模型的端到端吞吐量(FPS)。实验结果均在相同分辨率下获得,采用FlashAttention、torch compile 和 KV-cache 等加速技术。Helios 模型的性能显著优于同规模模型,且与较小规模的蒸馏模型速度相当。
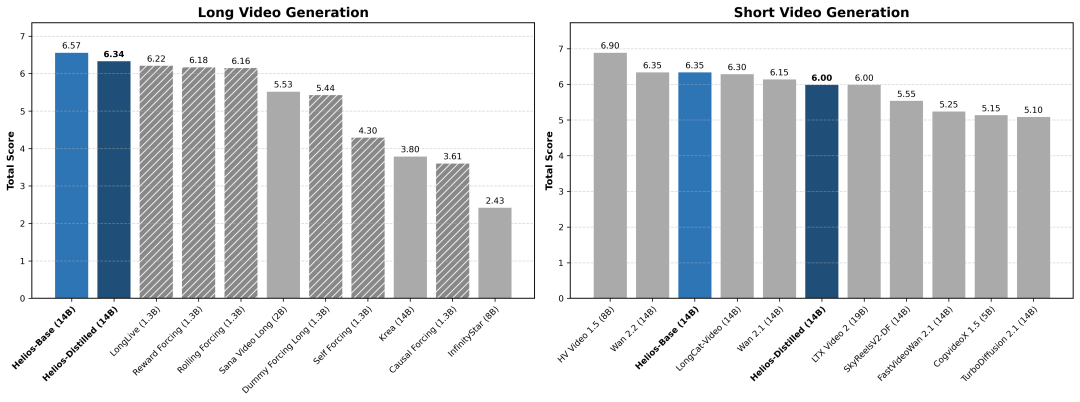
图|Helios 及其对比模型的基准性能。无论是在短视频生成还是长视频生成任务上,Helios 都优于现有的蒸馏模型,同时其性能已接近基础模型的水平。
Helios 支持 T2V、I2V、V2V任务,同时结合交互式插值技术,还能实现交互式生成,生成的视频细节丰富、运动自然,无明显漂移。
图|Helios 文本生成视频展示。
图|Helios 图像生成视频展示。
图|Helios 互动视频展示。
不足与展望
尽管 Helios 表现卓越,但研究团队也保持了冷静的观察:
评价指标的空白:现有评估指标不足以准确衡量视频生成模型的性能。尽管 Helios 能够根据文本提示生成真实自然的视频,但现有的指标(如美学评分和流畅度评分)与先前方法相比仅呈现出微小差异。未来一个值得期待的方向,是开发与人类感知更为对齐的评估指标,以更真实地反映人类的主观判断。
边界闪烁问题:与现有自回归模型类似,生成片段在拼接边界处可能出现闪烁伪影。 尽管如此,本方法在该问题上仍持续优于先前方案。未来工作可探索强化学习技术,通过显式优化流畅度相关目标,进一步提升视频的时序一致性。
高分辨率扩展性问题:受计算资源影响,本文实验最高仅在 384×640 分辨率下进行,更高分辨率的设置尚未探索。 本工作将实时长视频生成作为世界模型与视频生成领域的核心能力加以优先研究,未对长视频记忆进行专项设计。提升分辨率与强化长视频记忆机制,都是重要的未来研究方向。
尽管 Helios 高分辨率扩展与边界平滑度上仍有可进化空间,但它已经做到了一件真正重要的事:打开了实时长视频生成的大门。
作者:王江珏
如需转载或投稿,请直接在本文章评论区内留言。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢