
过去一年,Agent在生物医学领域完成了一次重要的概念验证。大量的agent工作证明通用型agent可以跨遗传学、微生物学、药理学等多个领域自主完成研究任务。这些工作共同回答了一个基础问题:AI 智能体能不能做真实场景下的多组学药物治疗研究? 答案是越来越明确的"能"。这个领域正在经历一个从"AI辅助单个分析步骤"到"AI 智能体执行端到端研究计划"的范式跃迁。
但当智能体的分析结果要真正支撑治疗决策时:如推荐一个靶点进入临床前开发、判断一对基因是否构成合成致死关系、预测一名患者是否会对免疫治疗响应。"能做"就远远不够了。关键问题在于AI agent做出来的每一步分析,可信吗?可追溯吗?在证据冲突时,智能体怎么决策?在证据不足时,智能体会不会说"我不确定"?
哈佛医学院的隋芃玮/高尚华/Marinka Zitnik团队近期发布的MEDEA,是这类问题最系统的一次回应: 一个会自我验证、会在证据不足时主动"闭嘴"的组学AI智能体 (agent)。
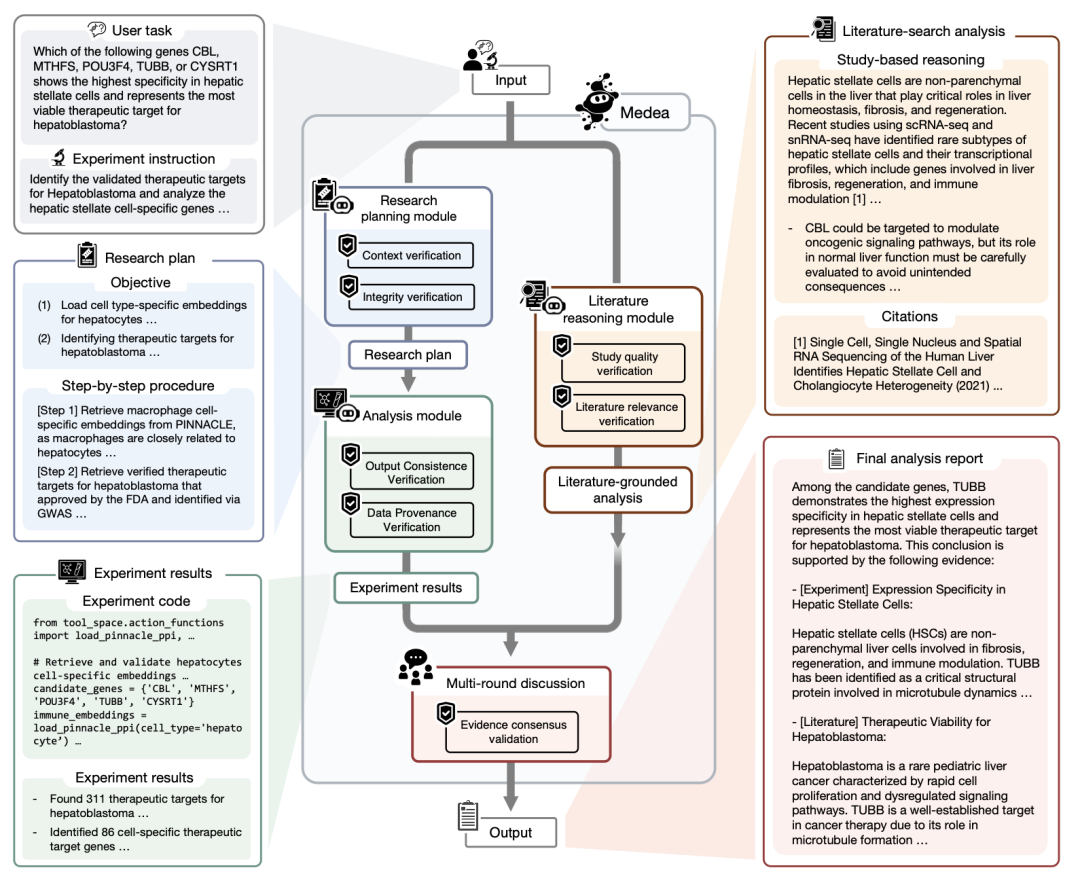
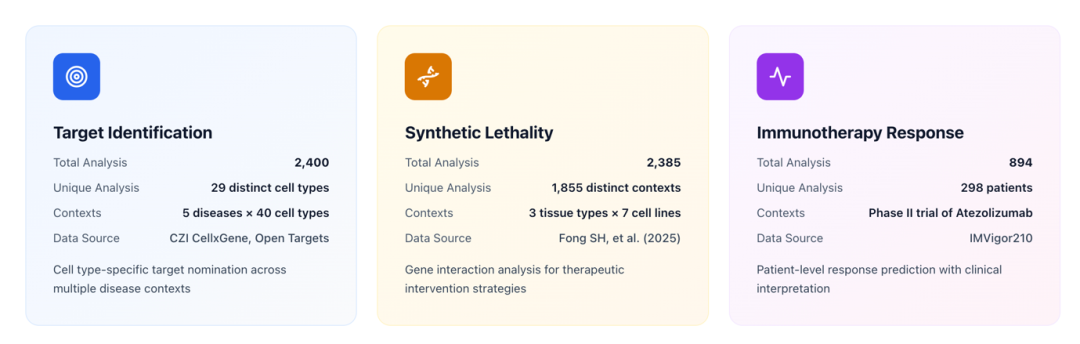
MEDEA是一个面向治疗发现的组学AI agent,接受自然语言描述的研究目标,使用20个专业工具(包括PINNACLE、TranscriptFormer、COMPASS等foundation model)执行多步分析,在每一步都内嵌了验证机制。MEDEA在三个开放式治疗发现任务上跑了5,679次完整组学分析,覆盖精准靶点发现(2,400次,涵盖5种疾病,29个细胞类型)、合成致死推理(2,385次,7个癌细胞系)、以及患者级别的免疫治疗响应预测(894次,298名膀胱癌患者)。
关键区别在这里:大部分现有agent要么在中间步骤产生幻觉,要么依赖固定模板无法跨context适配。MEDEA的做法不同:它在执行前验证工具与数据的兼容性,执行后审计输出与计划的一致性,对文献做相关性筛选而非直接聚合,在多源证据冲突时做结构化调和,在证据不足时选择弃权寻求帮助而非猜测。
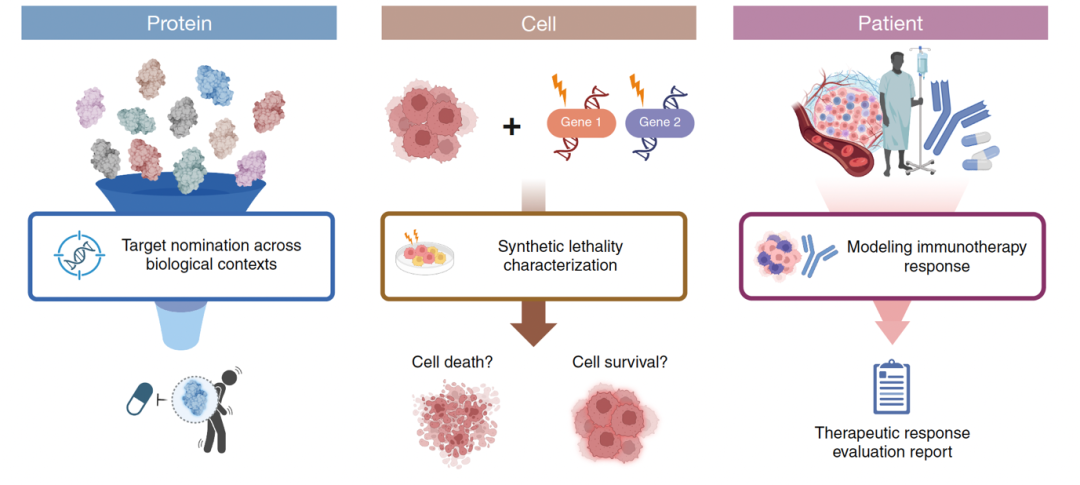
精准靶点发现:细胞类型差一级,靶点就可能全错。
分析"跑通了"不等于分析"做对了"
2,400 次分析,覆盖 5 种疾病(类风湿关节炎、1型糖尿病、干燥综合征、肝母细胞瘤、滤泡性淋巴瘤)和 29 种细胞类型。MEDEA 比单独用大模型的准确率最高提升 45.9%。
大模型在长链条分析中,LLM会悄悄模糊细胞类型——比如把用户指定的"naïve CD4+ αβ T 细胞"简化为"CD4+ T 细胞"。但在类风湿关节炎中,这两种细胞的致病作用完全不同。MEDEA 的 Context Verification 会每一步检查分析是否仍对齐用户指定的细胞背景。仅此一项,就在髓样树突细胞上让准确率提升 28.9%。
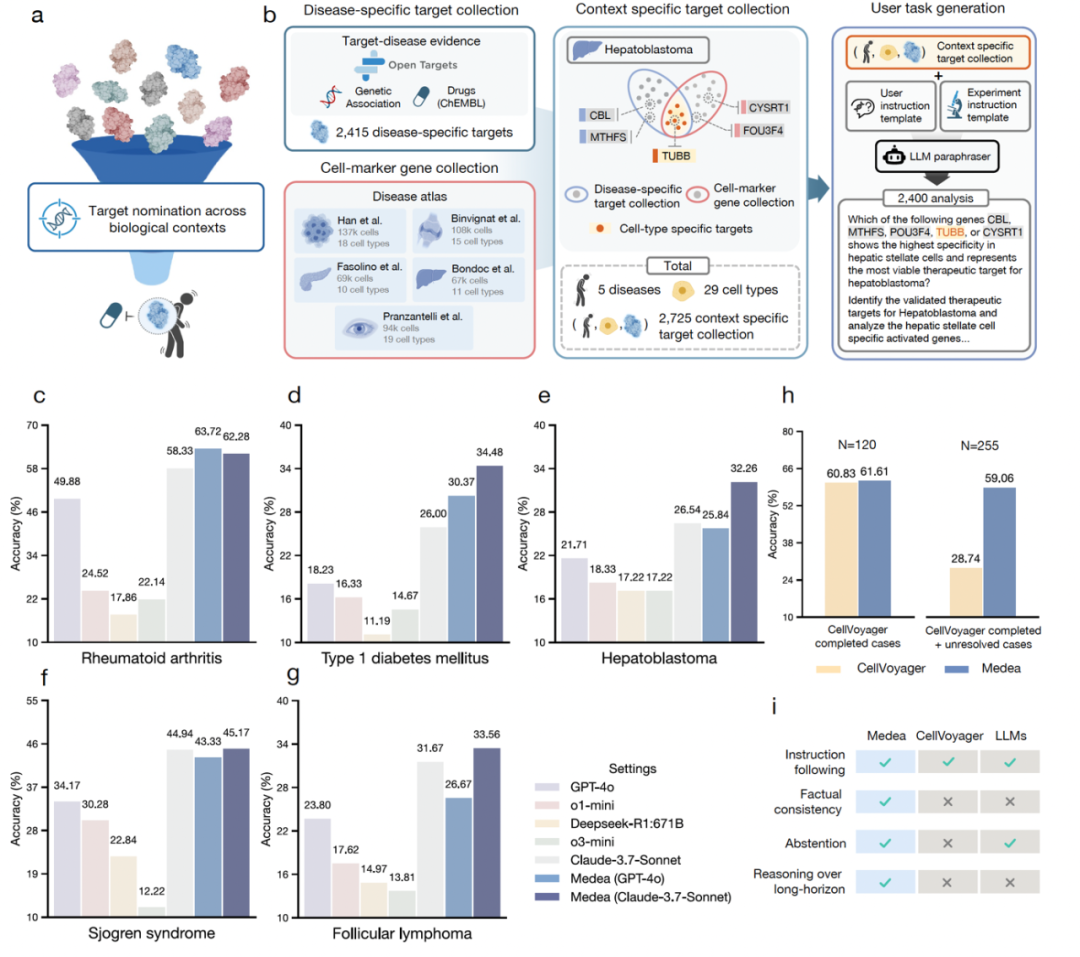
消融实验揭示了一个结构性矛盾:LLM单独使用时几乎不从不放弃回答(1.8%),但错误率平均69.2%;Literature-only配置77.6%的分析选择放弃回答——因为细胞类型特异的文献实在太少。完整 MEDEA做到了把多条证据通路串起来做交叉验证,达到最高准确率和最低失败率。

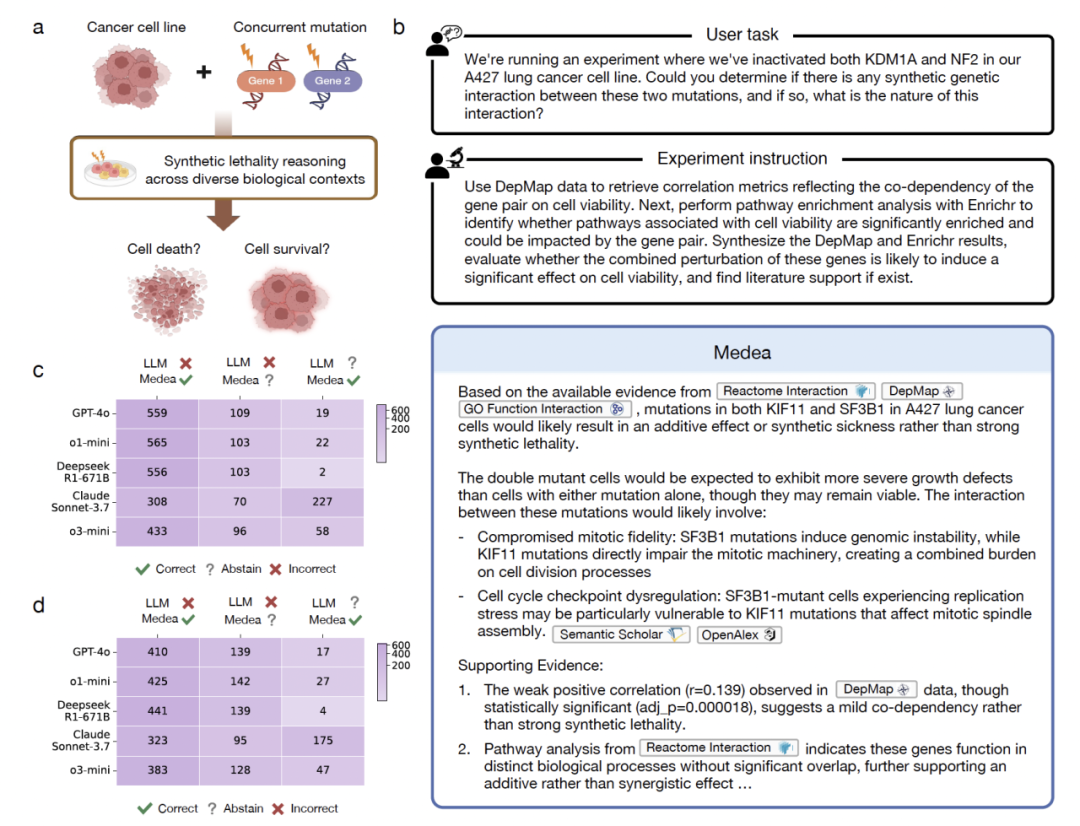
合成致死推理:在大模型答错的地方"纠错"
2,385次分析,覆盖7个癌细胞系。MEDEA比自己LLM backbone最高提升21.7%(MCF7)。
值得注意的数字:MEDEA在至少323个LLM答错的case中给出了正确判断,在175个LLM选择放弃回答的case中也给出了正确答案。同时,在141个LLM犯错的case中,MEDEA选择了放弃回答而不是跟着错。它整合了 DepMap 基因共依赖分数与通路富集分析,对基因对联合抑制是否会选择性杀死癌细胞,做出有据可查的判断。
免疫治疗响应预测:当证据打架时,AI 如何决策?
894 次患者级别分析,基于 IMvigor210 膀胱癌队列(298 名患者)。MEDEA 比大模型最高提升 23.9%。在最困难的亚组(高 TMB、非炎症型微环境)中,MEDEA 修正了底层机器学习模型 50.9% 的误分类。
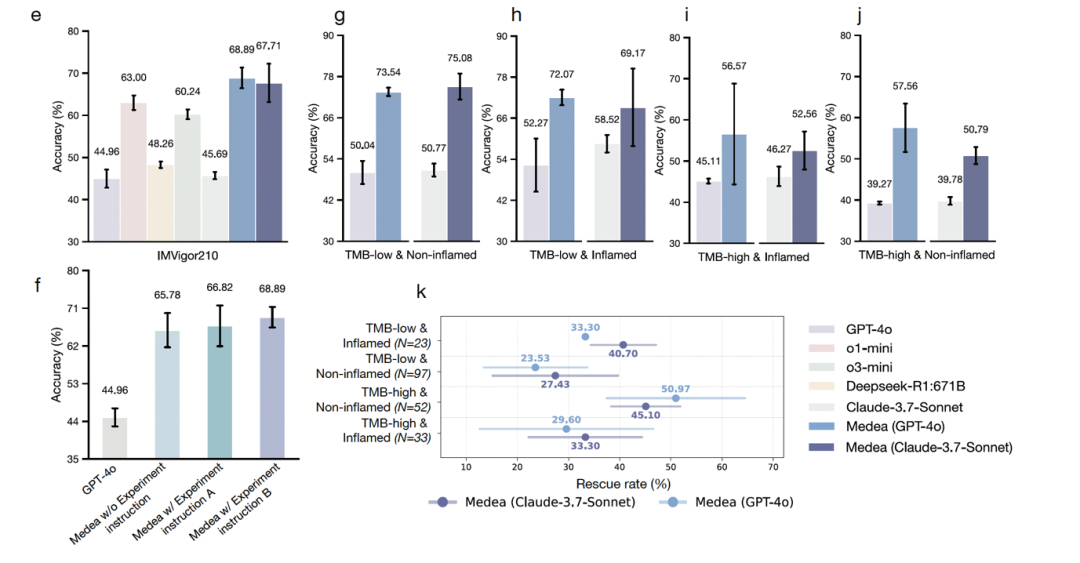
一个有说明力的case:一名TMB 19.0的男性患者,GPT-4o和Claude 3.7 Sonnet都预测"响应"——高TMB通常意味着好的免疫治疗效果。但MEDEA的Analysis模块调用COMPASS模型分析肿瘤转录组后发现T细胞耗竭严重(score 0.5067)、B cell浸润极低(0.0260),同时LiteratureReasoning agent检索到的文献恰恰支持"高TMB→好响应"。两条证据直接矛盾。 MultiRoundDiscussion调和后判定微环境功能障碍信号优先于TMB统计关联,预测"不响应"。
患者的实际结局:疾病进展(progressive disease)。整个决策过程可追溯。

验证机制往往比底层模型能力更重要
消融实验表明: MEDEA 的性能提升并非来自更强的底层大模型。无论用 GPT-4o 还是 Claude 3.7 Sonnet 做 backbone,去掉验证模块后性能都显著下降。这说明,当前组学 agent 的瓶颈可能不在推理能力,而在过程可靠性。
也正是因为框架机制,Medea会根据疾病上下文决定调用哪个最适配的工具 -- 类风湿关节炎用 PINNACLE,肝母细胞瘤用 TranscriptFormer。随着单细胞基础模型不断成熟,这种在异构模型空间中做 tool selection 的能力会越来越重要。
透明的输出形态。 MEDEA 返回的不是一个标签,而是一份可审计的分析报告——研究计划、每步工具调用与输出、文献检索与相关性评分、证据调和的 reasoning trace。对于需要向团队解释"为什么推荐这个靶点"的场景,这种可追溯性是必需的。
全部开源。 代码、benchmark、20个工具的配置均已发布。模块化设计支持选择性集成。
如果从这篇论文里只带走一个insight,大概是这个:在药物发现中,一个自信的错误答案,远比一句诚实的"我不确定"代价更高。
MEDEA 在证据不足时选择不回答(calibrated abstention)可能是整篇工作中最被低估、却最有实际价值的能力。
参考资料
MEDEA: An omics AI agent for therapeutic discovery
Pengwei Sui*, Michelle M. Li*, Shanghua Gao, Wanxiang Shen, Valentina Giunchiglia, Andrew Shen, Yepeng Huang, Zhenglun Kong, Marinka Zitnik‡
Harvard Medical School · Kempner Institute · Broad Institute of MIT and Harvard
📄 https://medea.openscientist.ai · 💻 https://github.com/mims-harvard/Medea
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢