
作者:卓佩、锋锐、钓鳌、鹏奕、胧隐
导语:本文介绍阿里妈妈营销算法 AI Agent 团队、智能创作与 AI 应用团队以及中国人民大学,于2026 年1月底 AAAI 主会 Oral 环节分享的最新成果。该工作聚焦于用户长期行为在Agent个性化和偏好的理解的评估和优化 相关的工作。
阿里妈妈营销平台上服务于客户的 营销Agent(AI小万),每天需要回答与执行客户的各类营销问题与任务。区别于传统的问答bot,Agent需要基于客户的当前状态、历史行为等记忆深度理解客户的个性化偏好,从而解决客户和投手的个性化营销优化问题,在此背景下,2024年末,AI小万算法同学在此方向展开探索。此时Memory与自进化在Agent领域尚未像今天成为top热点(2026年初),本工作可以被视为在此方方向的探索和调研。
由于相关领域数据稀缺且存在客户数据安全问题,本工作通过数据合成,模拟服务型人机交互场景的长期交互行为来作为调研和研究基础。同时构建了首个包含多段用户交互日志和对话历史的评测基准数据集PAL-Bench。基于该数据集,本工作探索了针对不同形式的交互历史进行差异化和层次化的建模,提出了层次化异质的记忆建模框架Memory,显著提升了智能体对用户个性化需求和偏好的理解能力。该工作最终被收录于 AAAI 2026 录用为 Oral 论文。
论文:Mem-PAL: Towards Memory-based Personalized Dialogue Assistants for Long-term User-Agent Interaction
作者:Zhaopei Huang, Qifeng Dai, Guozheng Wu, Xiaopeng Wu, Kehan Chen, Chuan Yu, Xubin Li, Tiezheng Ge, Wenxuan Wang, Qin Jin
论文地址:https://arxiv.org/abs/2511.13410
项目地址:https://github.com/hzp3517/Mem-PAL
客户与平台之间的交互日趋频繁和多样化。客户每天都在与平台产生大量交互:浏览商品、查看报表、操作投放、与chatbot进行对话等等,甚至是进行投诉和寻求人工帮助;这些大量的真实埋点和日志,实际上刻画出了客户和投手在营销场景下的投放习惯、兴趣偏好和真实需求。
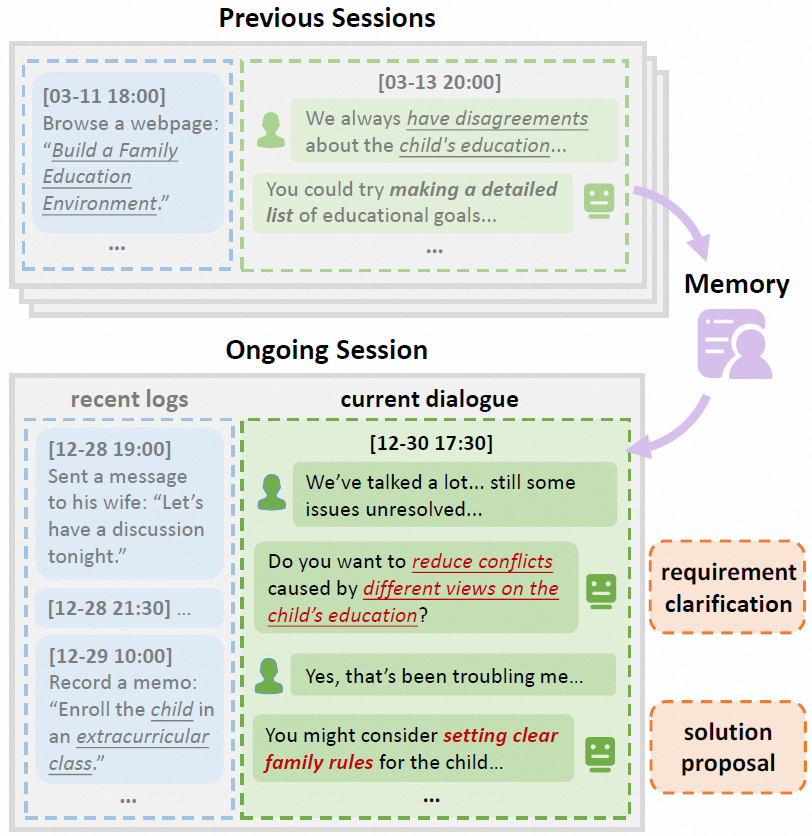
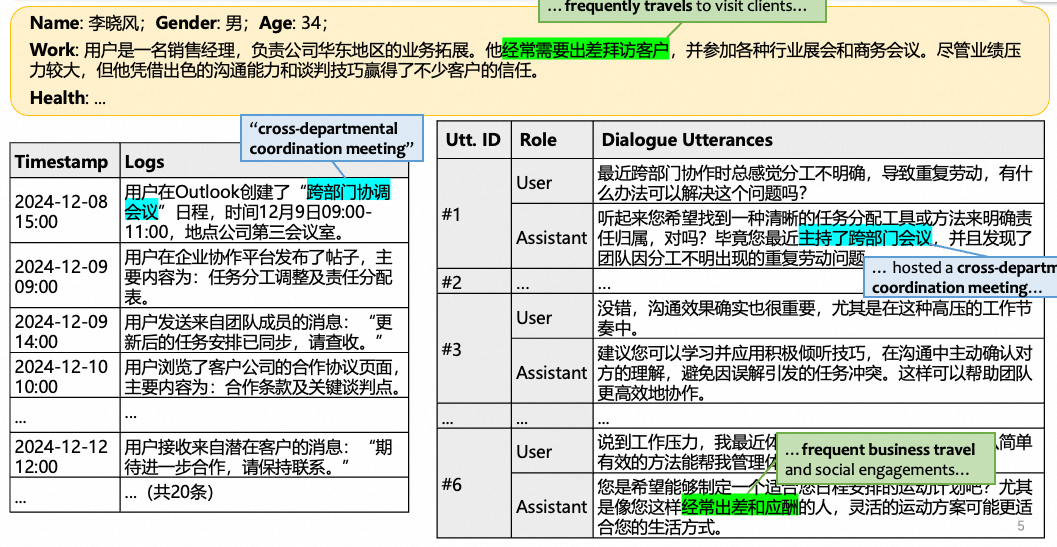
然而,目前绝大多数平台型助手Agent并没有真正利用好这些信息。每次对话仿佛都是"初次见面"——Agent无法记忆客户上周刚对比过的哪几个投放计划,也不知道客户更看重用户拉新还是转化效果,也不了解生成总结和报告时客户对哪些数据更加关注。Agent不得不反复通过澄清,让用户解释自己的背景和需求,体验远谈不上"个性化"。希望构建一个像老朋友(Pal)一样"懂你"的个性化Agent——能基于长期积累的行为日志和对话历史,准确理解客户的真实意图,提供真正贴合个人偏好的回应。下图是一个例子:
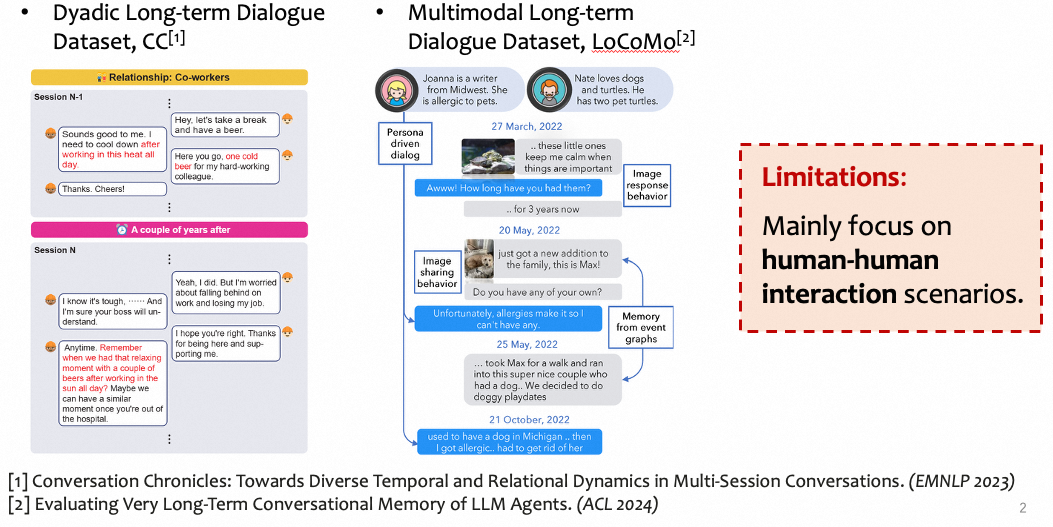
早期工作主要面向Human-to-Human闲聊场景。 PersonaChat为用户设定简短人设,但仅支持单会话。MSC将其扩展至5个会话,首次模拟跨天交互。此后,Conversation Chronicles引入角色关系建模,SHARE和LoCoMo分别探索了共享记忆与多模态历史。然而,这些数据集模拟的本质上是社交闲聊,与服务型用户-助手交互存在场景层面的根本差异。
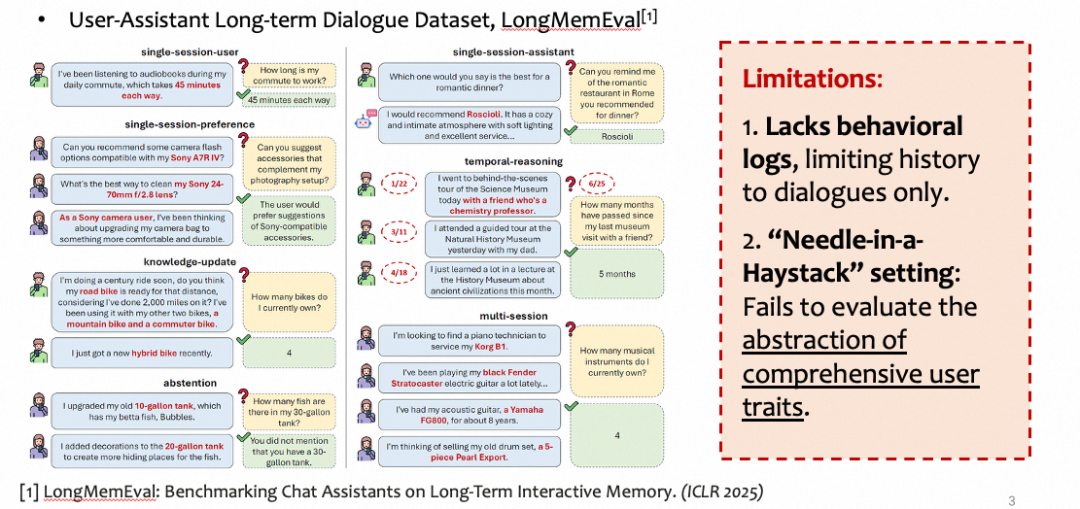
近期工作转向用户-助手交互,但各有侧重。 LongMemEval构建了约500会话、5000轮对话的超长历史,聚焦于客观事实的提取与回忆;ImplexConv关注隐式信息推理;MapDia探索助手的主动话题转换能力。但上述工作存在两个共同的盲区。
第一,行为感知单一——现有数据集几乎仅包含对话文本,缺少客户则的交互行为日志(搜索记录、消息收发、设备操作等)这一真实场景中的重要信息源。
第二,评估停留在客观事实层面——LongMemEval的核心设置是在大量无关对话中检索特定用户事实,本质上是"大海捞针"任务,对用户主观偏好的建模与评估严重不足。
PAL-Bench正是针对这两个盲区而提出:它同时包含行为日志与对话记录两种异构历史,并将评估重心从客观事实提取转移到主观需求理解与偏好对齐上。
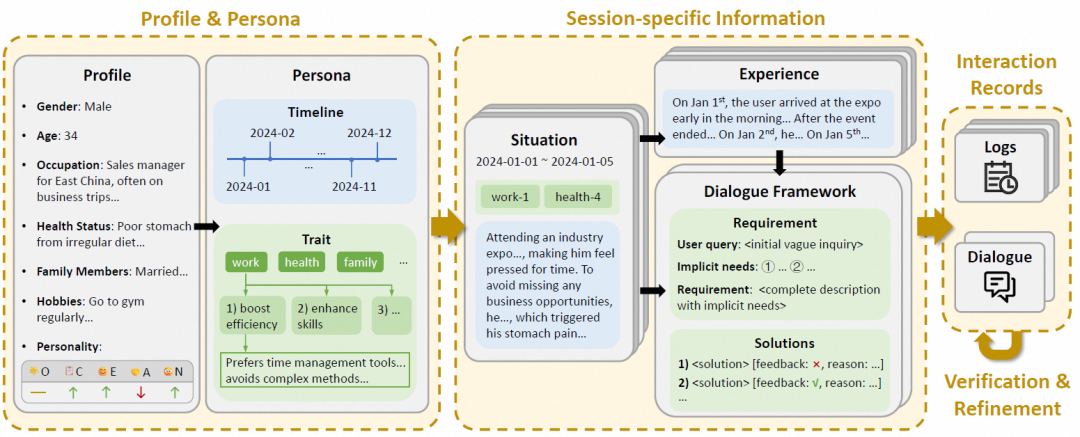
由于真实长期交互数据面临高采集成本与隐私约束,本工作设计了一套多阶段LLM合成流水线构建PAL-Set。核心思路是“从宏观到微观逐层细化”——先确定用户的长期稳定特征,再展开为会话级控制信号,最终生成细粒度交互记录,从而兼顾人设的长期一致性与短期动态变化。
第一层:用户画像与人设。 为每位用户生成基础画像(性别、年龄、职业、健康、家庭等)并基于大五人格模型赋予性格特征,在此基础上合成两类宏观约束:(1)跨越数月的个人时间线,按月概述客观事件,提供时序连贯性;(2)一组用户特质,定义多个抽象需求类型及其正/负面偏好描述,为偏好一致性提供语义锚点。
第二层:会话级控制信息。 将宏观人设展开为具体会话情境:月度时间线扩展为4-6个需求导向的情境条目,每个条目再细化为日记式体验描述,为日志合成提供素材。同时构建对话框架,预定义每个话题的用户查询、隐含需求、完整需求及8个候选方案。方案构建采用两阶段策略——先无用户信息生成8个通用方案,再依据偏好筛选出最匹配与最不匹配的各2个,确保负面方案仅是偏好不符而非质量不佳,将评估焦点锁定在偏好区分能力上。
第三层:交互记录生成。 基于上层控制信息分别合成两类记录:行为日志涵盖8种预定义类型(网页搜索、消息收发、设备操作等),通过灵活格式保证行为多样性;对话记录通过预定义的对话动作与转换模板控制交互流程,确保符合服务型对话的典型模式。
与已有数据集的对比。 将PAL-Set与现有长期对话数据集进行横向比较,可以清晰看出其差异化定位。已有数据集均局限于纯对话历史:PersonaChat仅支持单会话(14.8轮),MSC和CC扩展至5个会话但规模仍然有限,LoCoMo虽达到19.3个会话、304.9轮对话,但仍属于人-人闲聊场景。LongMemEval在数据规模上最为突出(500会话/5K轮),但其中大量对话来自公开数据集(ShareGPT、UltraChat)、与当前用户无关,本质上是为测试"大海捞针"能力而人为拉长上下文,并非同一用户的真实长期交互积累。相比之下,PAL-Set是唯一同时包含行为日志与对话记录的用户-智能体交互数据集,每位用户平均28.9个会话、400.9轮对话,且所有交互均围绕同一用户的一致人设生成,更贴近真实的长期个性化交互场景。

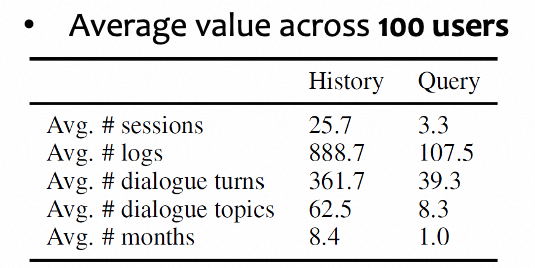
数据集包含100位合成用户,历史集与查询集的划分以用户交互的最后一个月为界。从统计数据来看,每位用户的历史集平均包含25.7个会话、888.7条日志、361.7轮对话和62.5个对话话题,时间跨度达8.4个月;查询集平均包含3.3个会话、107.5条日志和39.3轮对话,覆盖约1个月。这一规模为长期个性化建模提供了充足的历史上下文和评测样本。
为确保合成数据的可靠性,研究团队开展了人工评估:3名计算机专业标注者对随机抽取的50个会话(来自5位用户)进行1-3分评分,分别检查日志是否反映了预定义的用户体验事件、对话是否与用户画像及偏好一致。结果显示,日志平均得分2.75、对话平均得分2.67,极少出现1分(不匹配)的情况,表明多阶段合成流水线能够有效生成与预定义用户特征高度一致的个性化交互记录。
PAL-Bench设计了三项评测任务,从不同粒度系统考察助手对用户个性化需求与偏好的建模能力:两项单轮问答任务和一项多轮对话交互任务。
任务一:需求重述(Requirement Restatement)
该任务考察助手能否从用户模糊的初始查询中,结合交互历史推断出完整的用户需求。输入为每个话题对应的初始用户查询(通常简短且欠明确),期望输出为包含隐含需求的完整需求描述。例如,当用户简单询问"怎么让工作更高效"时,助手需要结合其频繁出差、常被临时会议打断等历史背景,推断出"需要一个适合高频出差节奏的时间管理方案"和"减少外部干扰以保障重要任务完成"等隐含需求。评测采用BLEU分数衡量文本匹配度,并引入GPT-4 Score专门评估对隐含需求的覆盖程度——预定义的2项隐含需求每匹配一项得1分、部分匹配得0.5分,最终映射至[0, 100]区间。
任务二:方案提议(Solution Proposal)
该任务评估助手能否理解用户偏好并据此提供匹配的解决方案,包含两个子任务。方案生成要求助手基于完整需求描述生成符合用户偏好的方案,以预定义的正面方案为参考计算BLEU分数。方案选择则要求助手从8个候选方案中识别出最匹配用户偏好的2个,通过Selection Score量化评估——选中正面方案+1分、选中负面方案-1分、中性方案0分,总分范围[-2, +2]后映射至[-100, 100]。这一评分设计直接反映了模型区分用户正负偏好的精细程度,而非简单的方案质量判断。
任务三:多轮对话交互(Multi-turn Dialogue Interaction)
该任务评估助手在完整对话流程中的综合个性化能力。具体构建方式为:User-LLM(Qwen-2.5-Max)依据预定义的用户画像、情境和偏好进行角色扮演,与待评估的Assistant-LLM进行多轮交互,每轮的对话动作预先指定但不限制具体生成内容。评估由Evaluation-LLM(GPT-4-turbo)从需求理解(助手能否准确推断用户的实际需求)和偏好对齐(助手提出的方案是否符合用户偏好)两个维度进行配对比较。为减轻LLM评估中的位置偏差与随机性,采用FairEval框架——每对比较进行6次、交替调换输入顺序,取平均分确定胜负,最终报告Win/Tie/Lose统计。
现有的个性化回复生成方法大致可归为三类。
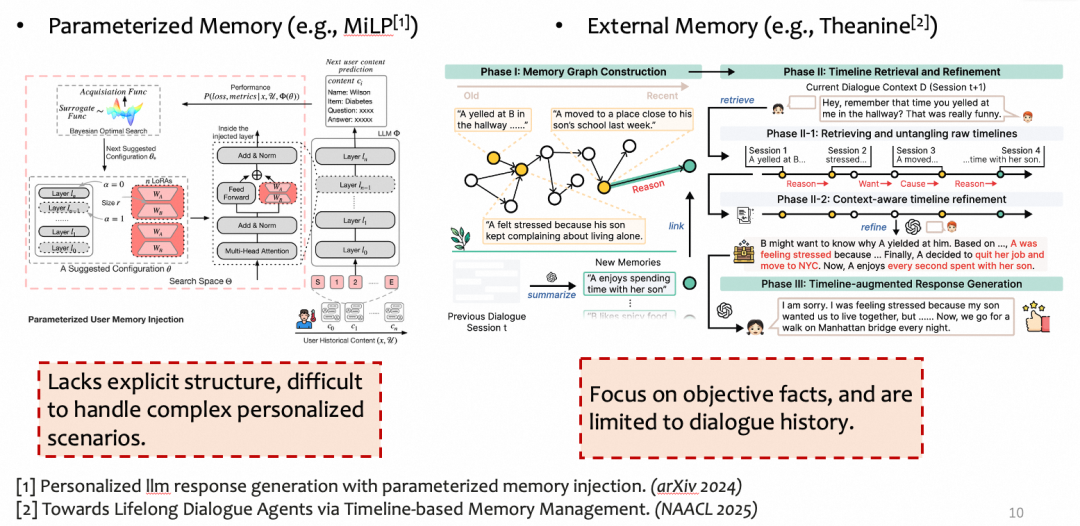
全量输入法直接将用户所有历史放入提示词,依赖模型的长上下文能力。这种方式简单直接,但当输入过长时模型容易在海量信息中遗漏关键个性化细节,效果往往不尽如人意。
参数化记忆法(如MiLP、Persona-Plug等)通过微调模型参数将用户信息隐式编码到模型内部。这类方法缺乏显式的记忆组织结构,难以应对需要精细偏好区分的复杂场景;同时由于需要修改模型参数,无法适用于只能通过API调用的闭源大模型,在实际部署中存在明显限制。
外部记忆+检索增强生成(RAG)法是目前最主流的方向。MemoryBank维护带有遗忘机制的记忆库,RecurSum通过递归摘要压缩长期对话,ConditionMem引入条件触发机制动态激活相关记忆。然而,这些方法均仅针对对话历史设计,缺乏对行为日志的处理能力;且记忆组织停留在单一抽象层级,未区分具体情境细节与长期稳定特质,难以同时支撑需求理解和偏好对齐两个层面的个性化建模。
针对长周期历史数据中信息异构(日志 vs 对话)和层级复杂(具体细节 vs 抽象偏好)的挑战,本文提出了一种分层异构记忆框架(Hierarchical and Heterogeneous Memory, HMemory)。
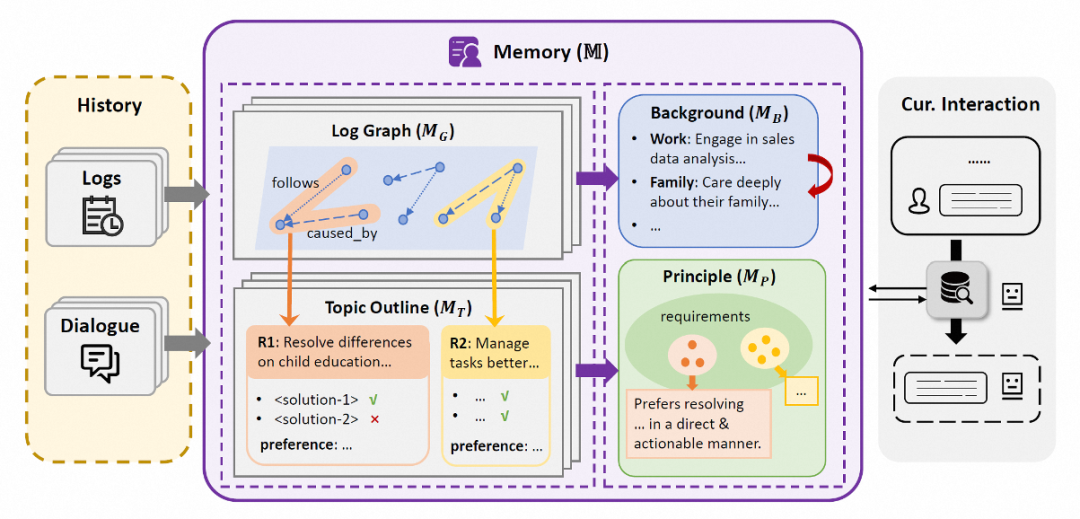
该框架将记忆建模为两个层级、四个模块:
该框架将记忆建模为两个层级、四个模块:
1)具体层(Concrete Level):
日志图谱(Log Graph,
): 利用LLM挖掘碎片化日志之间的因果与时序关系,构建情境子图,将离散行为转化为连贯的用户经历描述。
话题大纲(Topic Outline,
): 对历史对话进行结构化提取,总结每个话题下的用户显式/隐式需求及对解决方案的反馈。
2)抽象层(Abstract Level):
背景画像(Background,
): 基于具体的日志情境,递归更新用户在工作、家庭、健康等维度的长期背景信息。
需求类型与偏好准则(Principle,
): 从具体话题中聚类并抽象出用户的宏观需求类型和对应的偏好准则(例如“偏好直接的建议”或“注重性价比”)。
在交互过程中,模型采用检索增强生成(RAG)策略,根据当前查询检索这四类记忆中最相关的信息,从而帮助交互助手理解用户当前话语背后所体现的长期特性,并实现个性化增强的回应。
实验结果表明,Memory 框架在理解用户隐式需求和长期偏好方面显著优于现有基线模型。
需求复述任务:引入日志信息和长期记忆显著提升了模型对用户意图的还原度。在“方案推荐”任务中,我们的方法在方案选择得分的指标上大幅领先,证明了分层抽象记忆对于捕捉用户复杂偏好的重要性。
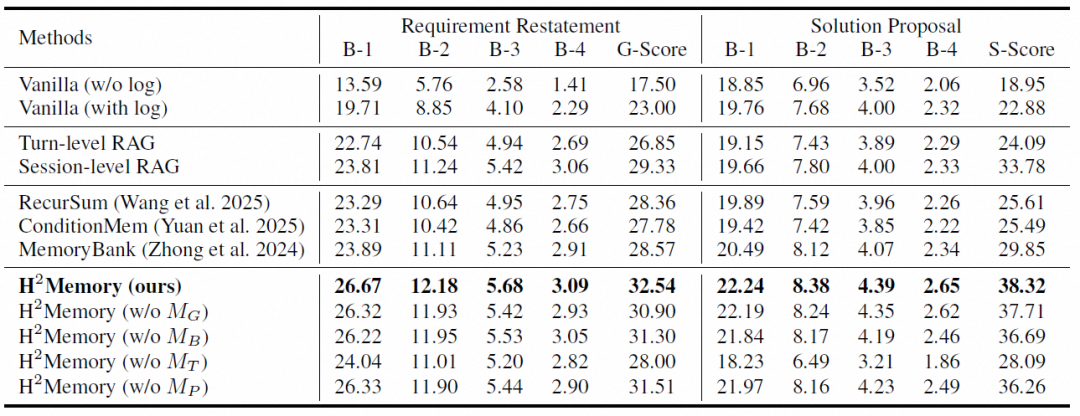
多轮对话交互评估:与User-LLM的模拟交互显示,我们的方法在需求理解和偏好匹配度上均取得了最高的胜率。此外,我们还在外部英文数据集 LongMemEval 上验证了所提出框架的泛化能力。

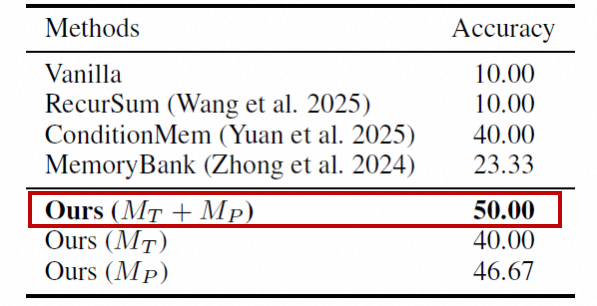
外部数据集验证: 为检验泛化性,在LongMemEval的"single-session-preference"英文子集上进行了实验。由于该数据集仅含对话,只使用了H²Memory的对话建模组件(MTM_T_ + MPM_P_)。结果显示,两者结合达到50%准确率,优于所有基线(最高为ConditionMem的40%),证明了方法在不同数据集和语言上的适用性。
此外补充实验中, 使用Deepseek-V3.1和bge-base-zh进行的额外实验表明,更强的基座模型能进一步提升PAL-Bench上的整体表现,同时H²Memory相对基线的优势依然显著(p < 0.01),验证了框架对不同模型组合的良好泛化能力。
Memory机制如今已毫无争议地站在了Agent研究的舞台中央,成为学术界和工业界竞相投入的焦点方向——无论是长期记忆的组织与检索、基于记忆的自我进化,还是个性化偏好的持续建模,都在快速催生大量新工作。在这一蓬勃发展的浪潮中,Mem-PAL作为其中一种的一朵浪花,在基于长期行为的偏好对齐上,抛砖引玉。其中所设计的数据合成方法以及Memory建模思路,随着Memory中涉及的基础行为数据的不断标准化,正在不断应用于阿里妈妈相关营销Agent的升级和迭代中。
💡 关于我们
我们是阿里妈妈营销算法AI Agent与客户成长团队,致力于将前沿Agentic AI技术深度融入营销算法全链路,驱动业务增长、助力客户成长。我们期望为商家提供最前沿的Agentic产品体验,在营销域全链路实现AI原生化体验;在客户增长域,通过将Agentic AI应用于用户意图洞察与智能决策,贯通智能触达、流失预警、投放引导全链路,实现AI运营数字员工。算法层面,我们持续推动Agentic架构演进,探索Multi-Agent群体智能范式与层次记忆模型,并通过后训练、自进化持续学习等技术不断提升Agent的智能化水平,探索工业级通用智能体的实现路径。团队创新工作已发表于KDD、ACL、AAAI等领域顶级会议。诚挚欢迎具有大模型、AI Agent、LLM后训练等背景的同学加入我们!
📮联系邮箱:kehan.ckh@taobao.com;pengyi.wxp@taobao.com
相关岗位校招进行中,欢迎扫描二维码投递!


也许你还想看
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢