

试试让你的 Agent 做一支产品宣传片。
给它一段参考视频,加一句话:「能复刻这个视频,给我的产品做一个宣传片吗?」然后你去忙别的了。十几分钟后,Agent 交回一支完整的 TVC——它自己写了剧本,自己拆了分镜,自己选了模型生成每一个镜头,自己剪辑,自己配乐。你没有碰过任何一个按钮。
已经有产品做出来了。
3 月 18 日,LiblibAI 旗下 AI 视频创作平台 LibTV 正式上线。
它可能是目前市面上第一个,从产品设计的第一天起,就同时为人类创作者和 Agent 设计的视频创作工具——一款产品,两扇门。
LibTV:https://www.liblib.tv/
⬆️关注 Founder Park,最及时最干货的创业分享
超 22000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的 AI 产品曝光渠道
01
给 Agent 设计产品,
已经不是选择题了
过去一年,AI 产品领域有一件事越来越明确:你的用户里正在多出一类新物种——Agent。
不是所有产品都意识到了。但已经意识到的人开始动了。Figma、Canva、Spotify 接入了 OpenAI 的 Apps SDK,让 Agent 可以直接在 ChatGPT 里调用它们的能力。大量 SaaS 工具在接 Skill 接口,让 Agent 能读写数据、触发流程。Obsidian、Google Workspace 都提供了 Cli 版本,我最喜欢的笔记类产品 flomo 发布了 MCP 工具供各类 agent 使用。a16z 的 Stephanie Zhang 在 Big Ideas 2026 播客里说得很直接:「对人类消费者而言重要的东西,对智能体消费而言未必重要。」软件的优化目标正在从「让人看得懂」变成「让 Agent 用得了」。
但看看视频创作这个领域,情况还很早期。
能自动出片的 Agent 工具已经有了——给一句 prompt,剧本到成片全自动交付。有些也开始支持逐镜头调整和风格参数。专业创作者用的工作流工具也有了——画布、节点、连线,控制力很强。但这两类工具的思路是分开长的。Agent 类工具的核心逻辑还是自动化交付,创作者能介入的环节有限,更多时候是在结果层面做取舍。专业工作流那边,搭建成本高,创作中的小修改经常要导出到别的软件处理,给 Agent 用的接口大多还是后补的,不是原生设计。
两类工具各有各的长处,但思路是分开的。一边围绕自动化交付设计,一边围绕人的操控感设计,两套逻辑还没有在同一个产品里真正合流。
LibTV 想做这件事。
02
一款产品,两个入口
LibTV 从第一天起,人类创作者和 Agent 各有各的入口。不是先做 GUI 再补 API,两个入口在产品架构层面就是并行的。
创作者端:工作流画布更可控
打开 LibTV,看到的不是对话框也不是时间线,是一块可以无限放大的画布。文本、图片、视频、音频、脚本五种节点随便摆,用连线串成工作流,可以反复跑。剧本到成片,全在一张画布上。
已经上线 20 多个专业创作功能:9/25 宫格分镜生成、剧情推演四宫格、多机位镜头设计、角色三视图、画面时间推演等等。模型集成了可灵 3.0、Wan 2.6 等主流视频模型,图片和文本侧也接了多个模型。
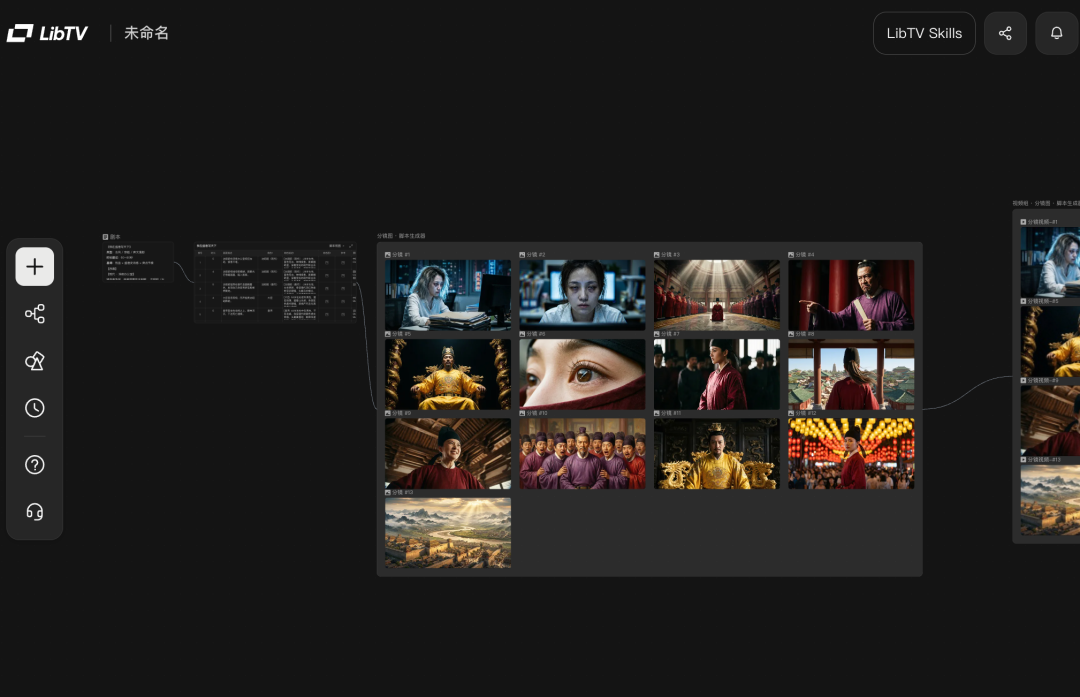
举个场景。一个 3 人创业团队要做 45 秒产品宣传片,没钱请外包。过去怎么做?ChatGPT 写脚本、 Nano Banana 出图、可灵生视频、剪映剪辑、PS 修画面。5 个工具来回切,角色长相每换一个工具就变一次。
在 LibTV 里:画布上用文本模型写分场景脚本,9 宫格分镜一次出 9 张构图方案,挑一个方向。角色三视图把主角形象锁死,后面所有镜头基于同一个设定生成,不会再变脸。逐镜头生成视频,画布上直接剪辑配乐。一个界面,一个下午。做完了把这套工作流存成模板,下次换几个镜头描述重新跑就行。
Agent 端:你来指挥,Agent 执行
Agent 通过 Skill 接口接入 LibTV,直接调用短漫剧生成、视频复刻、音乐 MV 生成这些打包好的创作能力。它能做出什么水平的视频,取决于能调用什么水平的模型和工作流。
有个技术细节值得说一下。Agent 每次发起创作,LibTV 返回的不是一个「等处理完再来取」的任务 ID,而是三样东西——sessionId、projectUuid、projectUrl。sessionId 让 Agent 可以持续查询进展;projectUuid 让整个创作挂在一个可持续的项目对象上;projectUrl 让人类可以随时打开画布接管。Agent 交付的不是一个孤立的 mp4 文件,而是一整个可以继续编辑的项目——人类打开画布就能接着改。
我们实际试了一下。给 Agent 一句话:「做一个 2 分钟的动画短片,讲一个被推荐算法困住的年轻人逐渐觉醒的故事,赛博朋克风格,结尾有希望感。」
然后什么都不用做。

Agent 自己把这句话拆成了 6 幕剧本,自动定好调色方案——冷蓝紫到暖金色的渐变,对应情绪从压抑到觉醒的转变。逐场景生成分镜,逐镜头出视频,配乐剪辑一条龙交付,最后给回一条完整的成片链接和项目画布。哪部分不满意可以随时让它修改,人类只需要等待即可。
这是 LibTV 上线后实际跑出来的结果。产品还在早期阶段,体验还在打磨,不是所有功能都到了最终形态。但核心流程能跑通了:同一套系统,创作者自己做和 Agent 自己做,调的是同一组能力、同一层模型。
03
给 Agent 设计软件,
跟给人设计到底有什么不一样?
LibTV 同一个产品给人和 Agent 同时用,两种用法摆在一起,差异很具体。但在拆解差异之前,先说一个底层问题:为什么给人用和给 Agent 用,设计思路会完全不同?
真格投资总监钟天杰最近写了一篇文章,标题很激进——「我们也许不该再投资 GUI 思维的软件公司」。他的核心论点是:GUI 本质上是人类认知缺陷的补丁。 人类注意力带宽极窄,工作记忆极浅,需要持续的视觉锚点才能维持任务状态。画布、节点、空间布局、即时反馈——这些东西存在的原因不是它们好,而是人类不用它们就没法干活。Agent 没有这些限制。它不需要「看到」才能记住,不需要空间布局来维持上下文,不需要视觉反馈来确认操作生效了。
理解了这一点,下面三个差异就不意外了。
能力怎么包装给 Agent,讲究不一样。
创作者用的是碎片化的工具——拖节点、调参数、选构图、改文案。手上做的事是碎的,脑子在做整合。Agent 不要碎片化工具。它不想「拖一个节点连一条线」,它想「根据这个剧本生成一套分镜」。
给 Agent 设计入口,第一个问题就是能力打包到哪一层。各种 API 太细,Agent 得来回调几十次。一键出片太粗,不同任务没法差异化。Sequoia(红杉)分析 Agent 产品设计时有个说法叫「Goldilocks」——最优解在中间,「把大量控制流交给 LLM,但保留一组轨道和状态感知」。LibTV 的 Skill 就是这个中间层:每个 Skill 里有完整的决策链路,但 Agent 可以在不同 Skill 之间自由组合。
这跟传统意义上「给产品加个 API」是两回事。API 是把人类在界面上点击的流程翻译成代码调用,思路没变;Skill 是让 Agent 用自然语言表达意图,由系统侧完成编排和决策——思路变了。
做决定的方式不一样。
创作者看 9 张分镜图,扫一眼就知道哪张对。说不清为什么,但就是知道。Agent 没有这种直觉。它的办法是靠量:每个镜头生成好几个版本,按一致性、构图、风格匹配度自动筛。用算力换审美。
给 Agent 用的系统得原生支持批量生成和自动比选。这也解释了为什么价格这么重要——Agent 天然就是要多调几倍模型的。
记东西的方式不一样。
创作者靠空间记忆管项目——角色设定在画布左边,分镜在中间,成片在右边,抬眼就知道整体状态。Agent 没有「空间」。做到哪一步了、角色约束是什么、前面镜头用了什么色调,都要显式地传给它。人看一眼就明白的事,Agent 需要系统帮它记住。
这三个差异是任何想给 Agent 开一扇门的产品都得回答的问题。LibTV 给出了一个早期解法,够不够好还得看后续迭代。但问题本身已经绕不过去了。
04
给 Agent 用,
Token 不能太贵
视频创作最大的成本是「抽卡」——大量生成,反复试。一支好作品后面可能是几十上百次生成和筛选。
LibTV 定价有点便宜:
年卡最低 39 折
部分模型叠加优惠后相当于 2 折多
会员 SKU 比竞品低 76%
模型积分 比竞品低 92%
对创作者来说,试错成本降下来了,可以靠量跑出好作品。
但对 Agent 生态来说,便宜这件事可能更要紧。前面说了,Agent 天然需要多版本生成和比选,调用频次比人手动操作高得多。单次调用太贵的话,Agent 做视频在经济上根本不成立。
模型能力决定 Agent 能不能做出好视频,价格决定它敢不敢放开了做。这两件事得同时解决,Agent 视频创作才能从 demo 变成可用的生产力。
05
给 Agent 做视频工具,
难在哪里?
同时做两个入口、接一堆前沿模型、还把价格压到这个程度,LibTV 之所以能这么做,跟 LiblibAI 过去三年干的事直接相关。
模型层,LiblibAI 做了三年多模态视觉创作,从图像生成到风格模型训练,一直在干「把模型能力变成创作者用得上的产品」这件事。跟主流模型厂商和算力平台的合作是长期积累下来的。这解释了定价为什么敢这么激进——上游的供给效率和成本结构,短时间内很难攒出来。
用户层,LiblibAI 平台上有超过 2000 万创作者,社区里沉淀了十万多款原创风格模型。这些创作者用什么模型、调什么参数、做什么类型的内容、在哪些环节卡住——产品团队对创作流程的理解是从这里来的。LibTV 的功能设计(9/25 宫格分镜、角色三视图、多机位镜头)是从大量真实创作行为里提炼出来的。
产品经验层,LiblibAI 在 2025 年就在设计领域推出过一个垂直 Agent 产品「星流」。怎么给 Agent 设计入口、Skill 怎么封装、Agent 跟人的协作流程怎么跑通——这些问题团队已经踩过一轮坑。LibTV 的双入口设计是在之前实践基础上的迭代。
还有一层东西值得单独说。2000 万创作者沉淀下来的不只是使用数据,还有审美资产。十万款风格模型、大量被验证过的创作工作流——这些东西带着创作者的审美判断。在 LibTV 里,创作者可以把画布上调好的工作流存成模板,模板里记录的不只是「用了哪些节点、连了哪些线」,还有每个环节的参数偏好:镜头时长、构图倾向、色调范围、节奏结构。另一个创作者拿去用,出来的东西会带着前一个人的审美印记。Agent 拿去执行,同样如此。审美通常锁在个人直觉里,没法传。LibTV 想把它变成可以存下来、可以在社区里流通的东西。人出审美,Agent 出产能,社区做流通——这是它想搭的飞轮。
所以 LibTV 更像是 LiblibAI 三年积累到了一个节点之后的自然产物:技术合作提供模型供给,创作者社区提供需求洞察和审美沉淀,Agent 产品经验定义产品形态。
06
Agent 不是功能,
是新用户
回到行业角度来看。
LibTV 在做的事——同时为人和 Agent 设计一款产品,不是一个特例。它背后是一个正在加速的行业变化:越来越多的产品团队开始把 Agent 当成一类真实的用户来对待。
Linear 是一个很具体的例子。这个项目管理工具过去一年做了一系列改动:issue 可以直接指派给 AI coding agent,跟指派给同事一样;专门做了一个 Agent Session 面板,显示 Agent 的工作进度和推理过程;手机端也能跟踪 Agent 的任务状态。它给 Agent 设计了独立的权限体系、webhook 事件类型、OAuth scope。不是加了个 API 就完事——从分配任务、跟踪进度、权限管理这些核心功能层面,Agent 就是团队成员。
Shopify 走得更远。今年初推出的 Universal Commerce Protocol,让 Agent 可以自主发现商品、比价、下单,走完整个购物流程。它还出了一套 Checkout Kit,专门让 Agent 在对话流程里完成支付。Shopify 的逻辑很清楚:未来的买家不只是人,还有替人跑腿的 Agent。产品架构得为这类用户重新设计。
Sierra 创始人、OpenAI 董事长 Bret Taylor 在 Sequoia 的播客 Training Data 里给了一个时间线:20 年前,企业的主要数字界面是网站。10 年前,变成了 App。下一步,是 Agent。 Taylor 认为这个变化里最大的机会在垂直领域——每个行业的工作流不一样,需要的 Agent 方案也不一样。通用平台做不了这件事,得垂直深入。他管这个叫「新一代的软件即服务」。Sierra 自己的做法很说明问题:给电信、银行、保险这些行业分别搭定制化的客户服务 Agent,定价按 Agent 自主解决问题的数量收费,转人工的不收钱。这个定价模型本身就在说——Agent 就是产品,不是产品的附属功能。
Jensen Huang 前两天在 GTC 2026 上把这件事说得更紧迫:「今天世界上每家公司都需要一个 Agent 系统战略。这就是新一代计算机。」 他直接把 Agent 框架比作 Windows 和 HTML——不是一个可选的新功能,是下一代基础设施。
这些判断指向同一件事:Agent 作为用户,不是一个遥远的假设,已经在改变产品的设计方式了。Linear 改了任务分配,Shopify 改了交易流程,Sierra 改了定价模型。每家公司迟早要回答同一个问题:你的产品准备怎么接住这类新用户?
LibTV 是在视频创作这个垂直领域给出的一个早期回答。


OpenClaw 背后核心框架 Pi:好的 Coding Agent 应该让用户来决定需要什么
提示词工程、上下文工程都过时了,现在是 Harness Engineering 的时代
对话 Seede AI:帮人类创作只是第一步,我们想帮人类理解 Agent 产出的内容
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢