

DeepSeek 稀疏注意力(DSA)被证明能够在不牺牲模型质量的前提下有效降低注意力计算开销,为大语言模型(LLM)的高效长上下文推理提供了一个代表性生产级解决方案。
然而,DSA 引入的轻量级闪电索引器仍保持 O(L²) 的复杂度,且必须在每一层独立运行,使其整体注意力计算开销占比随上下文长度增加而快速增长。
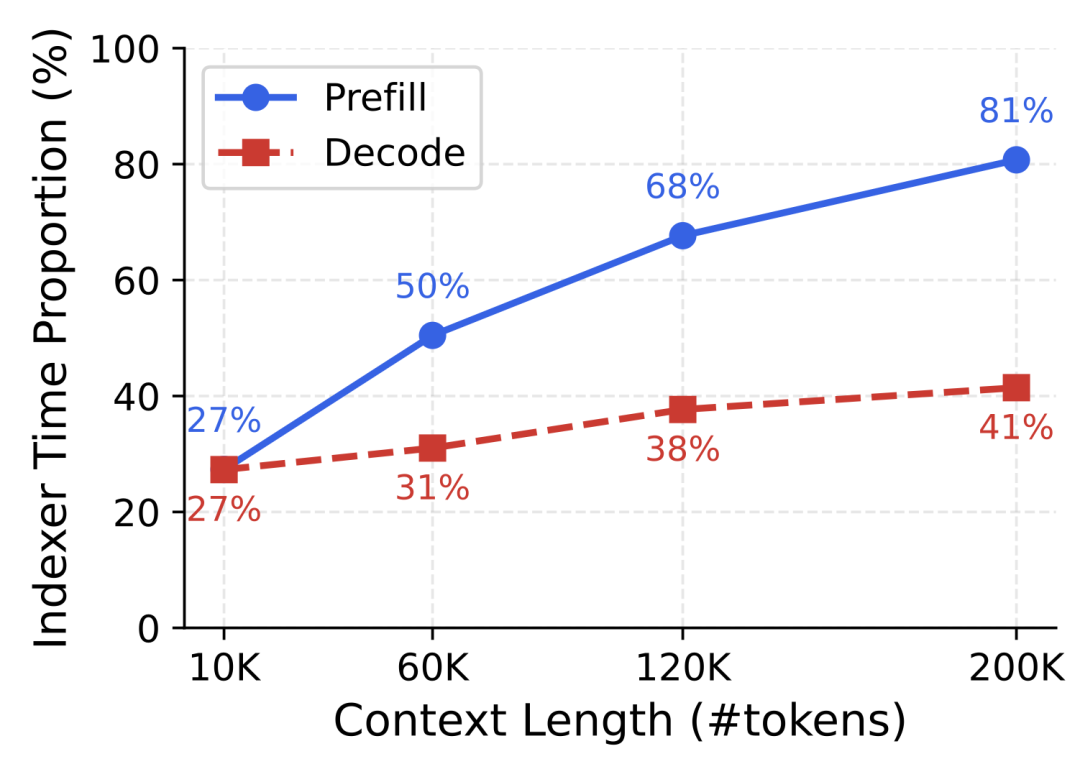
图|在 200K 上下文规模下,索引器占用了 prefill time 的 81%。
因此,降低索引器开销将是加速长上下文 DSA 推理的关键。
如今,只需少量代码,即可让 DSA 去除 75% 的索引器,在 200K 上下文场景下将预填充提速 1.82 倍、解码提速 1.48 倍,且同样几乎不损失模型性能。
这得益于清华大学、智谱(Z.ai)团队联合提出的 IndexCache。
该方法基于一个关键发现,即模型在相邻层选择重要 token 时具有高度的相似性,通过跨层复用这些索引,IndexCache 能够在不牺牲模型质量的前提下,大幅减少冗余的索引器计算。
值得一提的是,研究团队也在 744 亿参数的 GLM-5 上进行了初步验证,进一步证实了该方法的可扩展性与实际应用价值。

论文链接:https://arxiv.org/abs/2603.12201
GitHub:https://github.com/THUDM/IndexCache
核心理念
IndexCache 的诞生源于研究团队的一个观察发现:DSA 模型中相邻层的索引器输出的 top‑k 令牌集合具有极高的相似性,重叠率普遍在 70% 至 100% 之间。
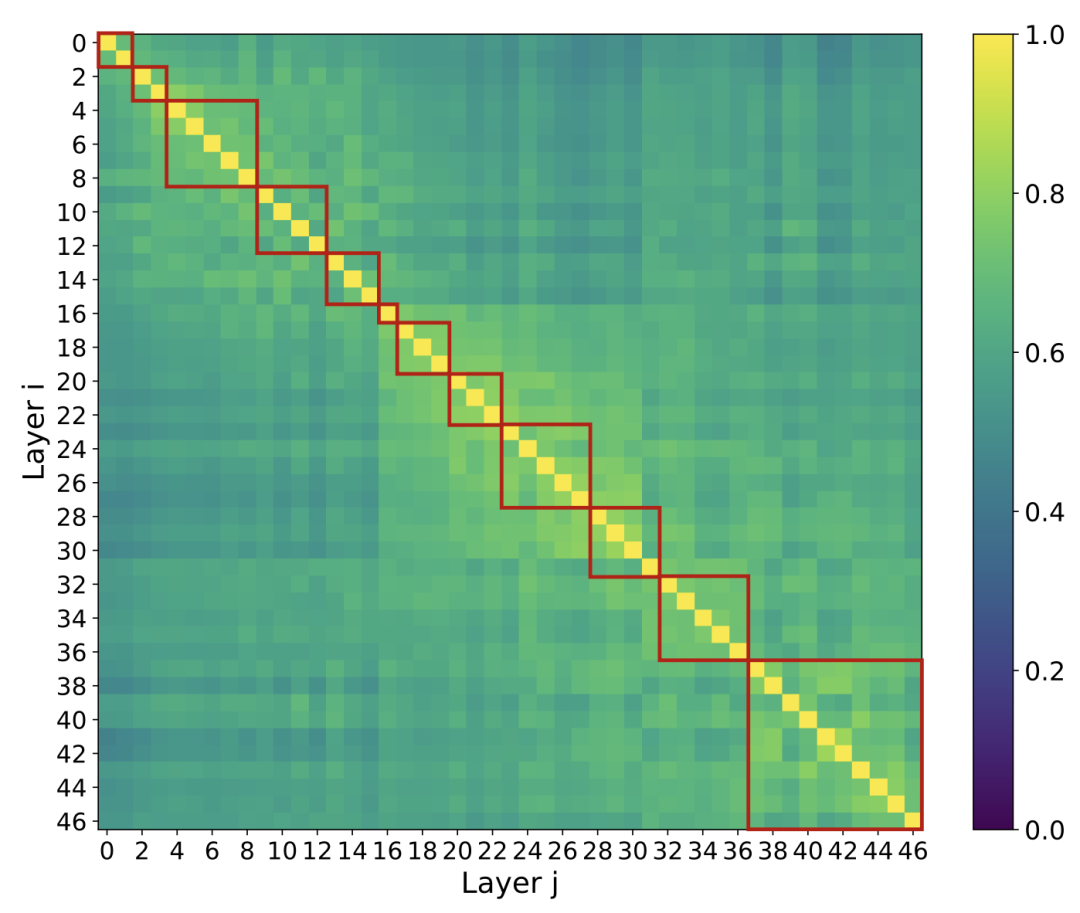
图|跨层 top-k 重叠热力图。大多数索引器的计算都是冗余的。
这表明大量计算是冗余的,若能减少或消除这些重复计算,就能在不影响模型质量的前提下大幅提升效率。
为此,他们利用这种跨层冗余性,在 IndexCache 中将模型层划分为两类,一类是全量层(Full Layer),它们保留原有的索引器,负责计算并缓存当前最新的 top‑k 索引;另一类是共享层(Shared Layer),它们不再运行自己的索引器,直接复用最近一个全量层所缓存的索引,进行后续的稀疏注意力计算。在推理过程中,只需为每一层增加一个简单的条件判断,即可在计算与复用之间切换,实现索引器的跨层共享。
如何确定哪些层应该作为全量层、哪些作为共享层?研究团队提供了两种互补的解决方案。
第一种是无训练方案,适用于已经训练好的 DSA 模型。它通过一个基于小批量校准数据的贪心搜索算法,逐一尝试将某些层转为共享层,并评估其对模型输出的影响,最终保留那些不可或缺的关键层作为全量层。
第二种是训练感知方案,适用于从零开始训练或需要微调的场景。它引入了一种多层蒸馏损失,让每个全量层的索引器不仅学习适应自身层的注意力分布,还同时学习服务于其后多个共享层的需求,从而使其选出的索引能够对所有被服务层都足够有效。

图 | 推理循环并排对比。(a)标准 DSA 在每一层运行闪电索引器。(b)IndexCache 添加了一个条件分支(红线):F 层计算并缓存新索引;S 层复用缓存索引。需注意 Tcache 是仅存储当前索引张量的临时缓冲区;该缓冲区在每个 F 层被覆盖,且仅需标准 DSA 已分配的 GPU 内存空间。
实验效果
研究团队在 30B 参数的 DSA 模型上进行了系统评估,实验结果显示,IndexCache 带来了速度的显著提升。
当上下文长度达到 200K token 时,仅保留 1/4 索引器的配置下,预填充阶段加速比达到 1.82 倍,用户等待首个输出 token 的时间几乎减半。在解码阶段,单请求的吞吐量提升至 1.48 倍,模型生成回复的速度明显加快。即使在上下文较短的场景下,IndexCache 也能带来可观的加速效果。
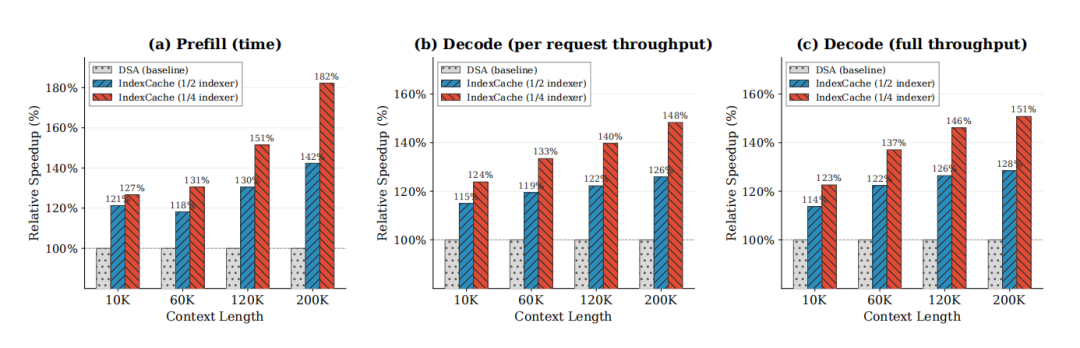
图 | 在 30B 模型上三种推理设置下,IndexCache 相对于 DSA 基准模型的相对加速比。DSA 基线模型的加速比已标准化为 100%。
研究团队还将这一方法初步应用于 744B 参数的 GLM-5 模型。实验数据显示,在长上下文任务中,IndexCache 同样能够实现至少 1.3 倍的端到端加速,验证了该方法在更大规模模型上的有效性。
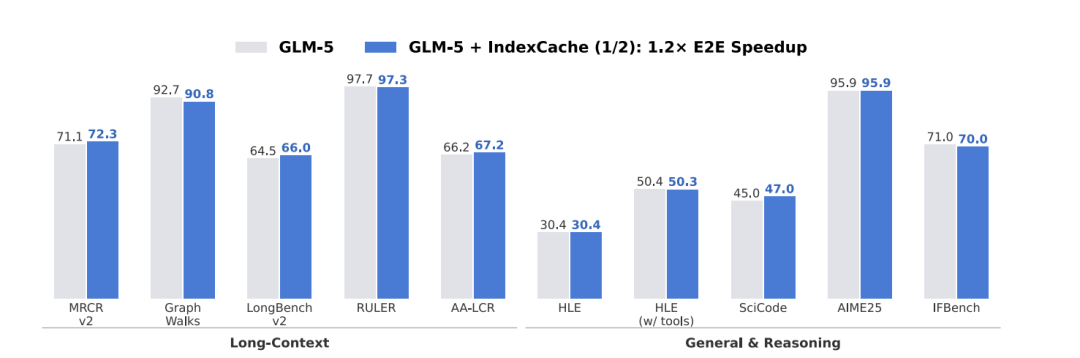
图 | GLM-5 与 GLM-5+IndexCache 的基准测试对比。IndexCache 在保持长上下文任务和推理任务性能相当的同时,可消除 50% 的索引器计算量,实现约 1.2 倍的端到端加速比。
更重要的是,速度的提升并未以模型性能为代价。在多个长上下文基准测试中,采用 IndexCache 的模型在 1/4 索引器的保留率下,各项得分与原始 DSA 模型几乎持平。在 AIME 2025 和 GPQA-Diamond 等推理任务上,采用搜索模式的 IndexCache 甚至略微超越了原始模型。研究团队观察到,适当的索引复用可能起到轻微的正则化作用,帮助模型在某些任务上表现更好。
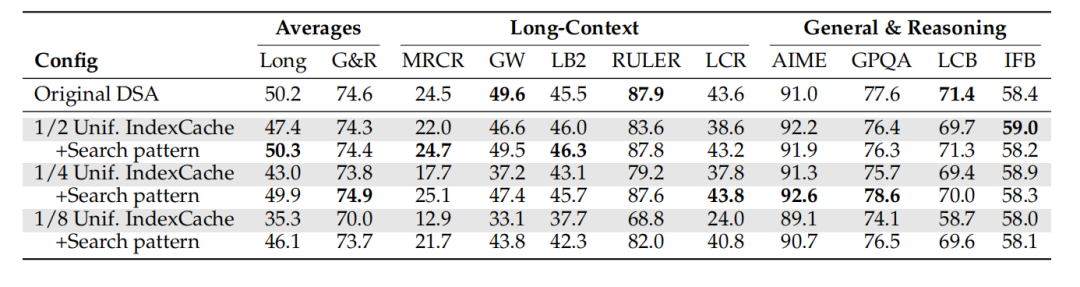
图 | 在1/2、1/4 和 1/8 索引器保留率下进行无训练 IndexCache 测试。采用 Long 和 G&R 聚合基准测试分数。研究团队比较了均匀交错与搜索模式之间的性能差异。
训练感知版本的 IndexCache 表现更为出色。在均匀保留一半索引器的配置下,其长上下文基准平均得分甚至超过了原始 DSA 模型,表明通过针对性的训练,模型完全可以适应跨层共享的推理模式。
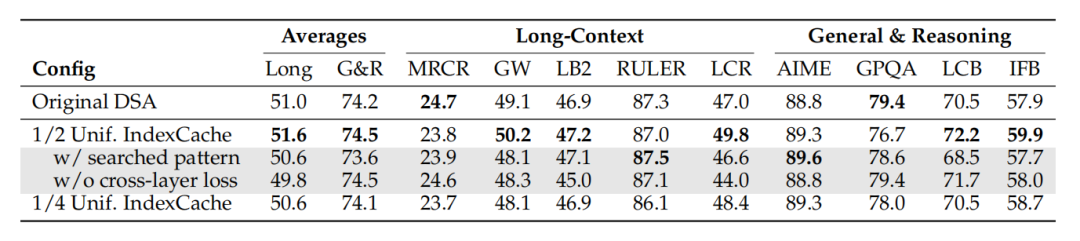
图 | 训练感知型 IndexCache 在 1/2 和 1/4 索引器保留率下采用均匀交错策略。带搜索模式:采用贪婪搜索模式替代均匀交错策略。无跨层损失:每个索引器仅针对其自身层进行蒸馏训练。
意义与展望
IndexCache 捕捉到了跨层的索引选择稳定性,这是稀疏注意力机制中的一个关键冗余。并以此为核心解决了索引器自身的效率瓶颈。这一方法为长上下文大模型的高效、低成本部署提供了一个切实可行的解决方案,使得在保持模型性能的同时显著降低计算开销成为可能。
从实际应用的角度来看,IndexCache 带来的好处是直观的。对于用户而言,无论是处理超长文档还是进行复杂的多步推理,预填充延迟最高可降低近一半,解码速度也显著提升。对于服务提供者而言,这意味着更低的计算成本和更高的吞吐量,长上下文应用能够以更经济的方式落地。
研究团队已经在 744B 参数的 GLM-5 模型上初步验证了 IndexCache 的有效性,并计划将训练感知版本的 IndexCache 应用于这一更大规模的模型,进一步挖掘其潜力。
此外,这种“跨层重用”的思想并不局限于 DSA,任何涉及动态 token 选择的稀疏注意力方法,都有望从中受益。随着稀疏注意力逐渐成为前沿大模型的标配,跨层索引复用或将成为高效推理流程中的一个标准组件。
作者:王跃然
如需转载或投稿,请直接在本文章评论区内留言。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢