
Generative Social Choice
生成式社会选择
Ariel Procaccia教授特邀讲座
IIIS Distinguished Lecture
2026年3月16日,哈佛大学计算机科学系 Alfred and Rebecca Lin 教授 Ariel Procaccia 做客清华大学交叉信息研究院,带来题为 “生成式社会选择”(Generative Social Choice) 的讲座。交叉信息院助理教授郑舒冉主持讲座,近100名清华师生在 FIT 楼多功能厅参加。郑舒冉助理教授首先介绍Ariel Procaccia教授在人工智能、算法、经济学及社会问题的交叉研究,及其系列兼具理论和应用价值的项目。
01
这场讲座在讲什么?
这场讲座探讨的问题,听起来很学术,
其实和每个人都息息相关:
当一群人意见相左时,我们习惯用投票决定。
但传统投票的困境在于:
选项是给定的,而最优方案可能不在其中。
大家投出的,只能是“矮子里拔将军”。
Procaccia 教授的关注点正在于此:
如果借助AI生成更能代表民意的方案,
再从中形成更优的集体决策,
我们能否更有效地推进共识?
这正是“生成式社会选择”试图回答的核心问题。

02
为什么传统投票有时不够用?
教授以“英国脱欧”为例:
公众的真实立场往往是一整条光谱,
从完全脱欧到维持现状,中间存在许多层次。
(如名义脱欧但保留很多经济联系等)
若投票时只有“脱欧/不脱欧”两个选项,
那么制度就只能表达最粗糙的两端,
许多真实诉求便被压扁了。
这也发生在日常集体决策中。
比如改造学校食堂,学生诉求多元。
(如延长营业时间、增加窗口、降低价格……)
若只让在“涨价提质”和“维持现状”中二选一,
其政策结果往往会失真。
联系到传统“社会选择理论”,
尽管该理论旨在研究“如何公平展现民意”,
但它往往默认:选项已经给定了。
而今天很多复杂社会问题的难点恰恰在于:
真正好的选项,可能需要先“被创造出来”。

03
AI能帮什么忙?
大模型的强项,是基于已有内容生成新内容。
比如综合多方意见,形成更平衡的政策表述。
那么能否让AI从众人的原始意见出发,
生成若干条有代表性的方案?
这正是“生成式社会选择”的基本方向。
注意,这不是“让AI随便总结”,
而是在一个严格、可检验的框架里做两件事:
(1)生成候选陈述;
(2)判断陈述是否真正代表不同人群的意见。
生成的内容要在理论上站得住脚,
能证明确实有代表性,而不只是“看起来像”。

04
如何衡量陈述“有代表性”?
这正是要解决的核心挑战。
如果只让AI总结,容易出现两个问题:
一是说得比较空泛,貌似沾边但不尽人意;
二是只照顾多数人,忽略少数群体意见。
为此,教授提出新标准:“平衡正当代表性”。
这个名字听着拗口,意思却很直白:
如果有一群人数可观且观点相近的人,
最能代表他们立场的关键陈述却被遗漏了,
那这个结果就不够“平衡正当”。
从数量关系看,
假设有 n 个人参与,要选出 k 条陈述。
若存在这样一群人,
那么 k 条陈述就未达到“平衡正当代表性”:
他们至少有 n/k 人,
且对某条已选陈述的满意度为 α,
但还有另一条未选陈述能让满意度都高于 α。

05
什么是“生成式社会选择”?
可以把它理解成:
把“民主决策”和“生成式AI”结合起来的方法。
传统社会选择更像是在做:
给定菜单,统计偏好,选出结果。
而生成式社会选择想做的是:
先收集很多人的真实意见,
再用AI生成更有代表性的说法或方案,
然后用一套公平原则筛选,
确保不是只照顾声音最大的那群人。
换句话说,它想解决的不只是“选哪个”,
而是连“候选内容本身”一起优化。



06
这套方法如何运作?
按讲座介绍,大致可以理解为如下流程:
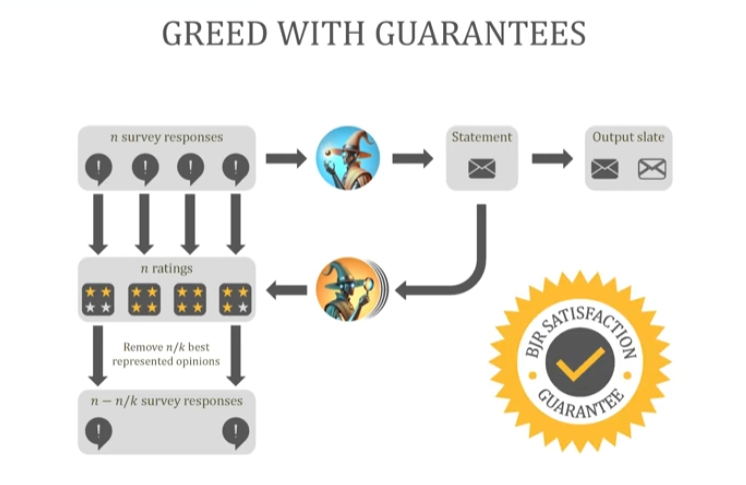
先通过问卷、访谈、讨论等方式,收集参与者的真实意见。这些意见通常是零散、长度不一、角度不同的,甚至互相矛盾。
用“生成式查询(Generative Query)”提出候选陈述,旨在生成使参与者满意度最大化的陈述。比如从几百条原始意见中,生成若干条可能的“代表性陈述”。
用“判别性查询(Discriminative Query)”为陈述打分,旨在判断某陈述是否能完全代表某人观点。
检查平衡正当代表性,逐步筛选。每次剔除评分最高的n/k条观点,重复k次,最终形成代表性陈述集。
07
未来应用及挑战?
“生成式社会选择”的意义在于:
它试图把提出候选方案这一步,
也纳入公平和民主的研究框架中。
这比传统投票更进一步。
这套方法可应用在很多现实场景里:
如面对城市规划、教育改革等复杂议题,
模型可将意见梳理成更有代表性的政策表述。
然而,教授也提到了现有大模型的局限:
如大模型上下文窗口有限,
如“代表性”不是非黑即白,很难精确评估,
如应用到真实议题,需考虑情绪、语境等因素。
总而言之,这个方向很有前景,
但距离成熟应用还有不少基础工作要做。

08
现场问答
在座师生与教授热烈互动,探讨人工智能安全、“多数派偏见”和科研发展路径等问题。
Q
交叉信息院校友、清华大学人工智能学院助理教授王同翰:鉴于大模型在生成式社会选择中的决定性地位,是否需考虑对其权力进行分治,以防范潜在的安全风险?
A
Procaccia教授:这确实是一个至关重要的问题。可以借鉴姚先生此前提出的“组建委员会”思路,通过多个 LLM 相互协作与制衡来化解这一难题。随着 LLM 能力的不断增强,这一问题将愈发凸显,如何引入相应的安全机制,是未来值得深入探索的重要方向。
Q
交叉信息院2025级本科生刘帅泽:除了“平衡正当代表性” 外,是否引入其他公理?如何防止少数派声音被淹没?
A
Procaccia教授:“平衡正当代表性”只是代表性底线,还可引入更强准则如“扩展正当代表性”,确保足够多的少数群体也能被代表。生成式社会选择的核心价值在于其数学上的严谨性。与普通的 AI 总结(仅凭概率生成)不同,他的算法通过“选出一个、剔除一批”的迭代逻辑,可以从数学上证明:无论输入数据如何,最终结果绝不会违反预设的公平公理。
Q
交叉信息院2021级本科生温和:在“正当代表性”框架下,是否需要引入特定的后训练(Post-training)或强化学习(RL),以克服大模型固有的“多数派偏见”,从而在数学层面更精准地对齐正当代表性公理?
A
Procaccia教授:为防止模型盲目顺从主流观点,可先输入一方观点引导模型形成结论,再引入截然相反的少数派意见。若模型能够在新视角加入后,通过“迭代更新”在总结中公平地反映对立立场,才说明其具备了真正的代表性处理能力。这种非盲从的多视角整合能力,是衡量模型是否满足正当代表性公理的关键。
Q
交叉信息院2025级硕士陈锐:回顾学术历程,您对博士生最重要的建议是什么?
A
Procaccia教授:我观察到,真正让博士生脱颖而出的,是提出好问题的能力——即创造力和问题意识。但挑战在于,这种能力未必是可以直接传授的。为尝试培养这一能力,去年我在经济学和计算科学课程中增加了一个新环节:要求学生在每次作业中提出一个原创研究问题,并进行初步分析。
Q
交叉信息院2025级博士生陈宇昕:在多年的教学生涯中,您认为一名优秀的研究者最核心的能力或技能是什么?
A
Procaccia教授:我想提一点,在这个时代,重要的不是追逐趋势,而是找到你真正的激情所在。现在这一点变得更难了,因为大家对趋势的追捧很狂热,很多人会担心,如果我不做热门话题,会不会落后或被忽视?但在我看来,做研究更应该关注的是你对所发现的东西是否充满热情。
采编 | 姜月亮
责编 | 吕厦敏
审核 | 袁洋

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢