
Hugging Face 的 Models 和 Datasets 仓库非常适合用来发布最终产物。但在生产级机器学习流程中,会持续产生大量中间文件 (如 checkpoints、optimizer states、处理后的数据分片、日志、trace 等) 。这些文件变化频繁,可能同时来自多个任务,而且通常并不需要进行版本控制。
Storage Buckets 正是为这种场景设计的:一种类似 S3 的可变对象存储。你可以在 Hub 上浏览它,用 Python 脚本操作,或通过 hf CLI 管理。由于它们基于
Xet https://hf.co/docs/hub/en/xet

当你处理以下场景时,很快就会发现 Git 并不是一个理想的抽象:
训练集群在训练过程中持续写入 checkpoints 和 optimizer states 数据流水线对原始数据集进行迭代式处理 Agent 系统存储 trace、记忆以及共享知识图谱
这些场景的存储需求其实非常一致:能够快速写入、按需覆盖、同步目录、删除过期文件,并保持系统持续高效运行。
Bucket 是 Hub 上的一种非版本化存储容器。它位于用户或组织的命名空间下,使用标准的 Hugging Face 权限系统,可以设置为私有或公开,并且有可在浏览器中访问的页面。同时也可以通过类似 hf://buckets/username/my-training-bucket 这样的地址在程序中访问。
Buckets 构建在
Xet https://hf.co/docs/hub/en/xet
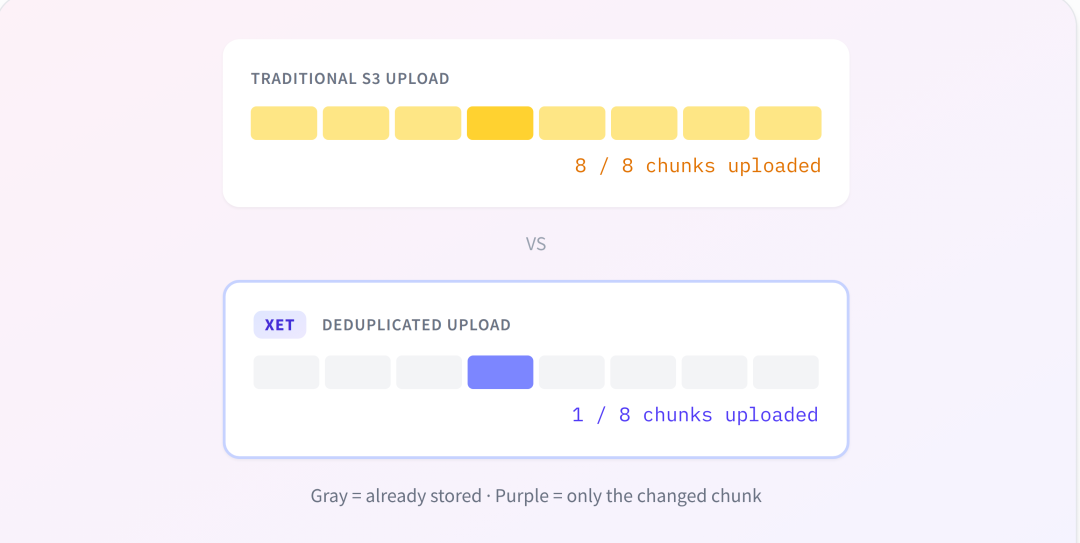
Xet 并不会把文件当作整体的二进制块来处理,而是会将内容拆分为多个 chunk,并在不同文件之间进行去重。例如:
上传一个与原始数据高度相似的处理后数据集?很多 chunk 已经存在。 保存连续的训练 checkpoint,其中大部分模型参数保持不变?同样可以复用已有 chunk。
Buckets 在上传时会自动跳过已经存在的数据块,从而减少带宽消耗、加快传输速度,并提高存储效率。
这与机器学习工作负载非常契合。训练流水线通常会生成大量相互关联的产物,例如原始数据与处理后的数据、连续 checkpoint、Agent trace 以及其衍生摘要等,而 Xet 正是为利用这种数据重叠而设计的。
对于 Enterprise 用户,计费是基于 去重后的存储量,因此共享 chunk 可以直接减少实际计费空间。去重不仅提升速度,也能降低成本。
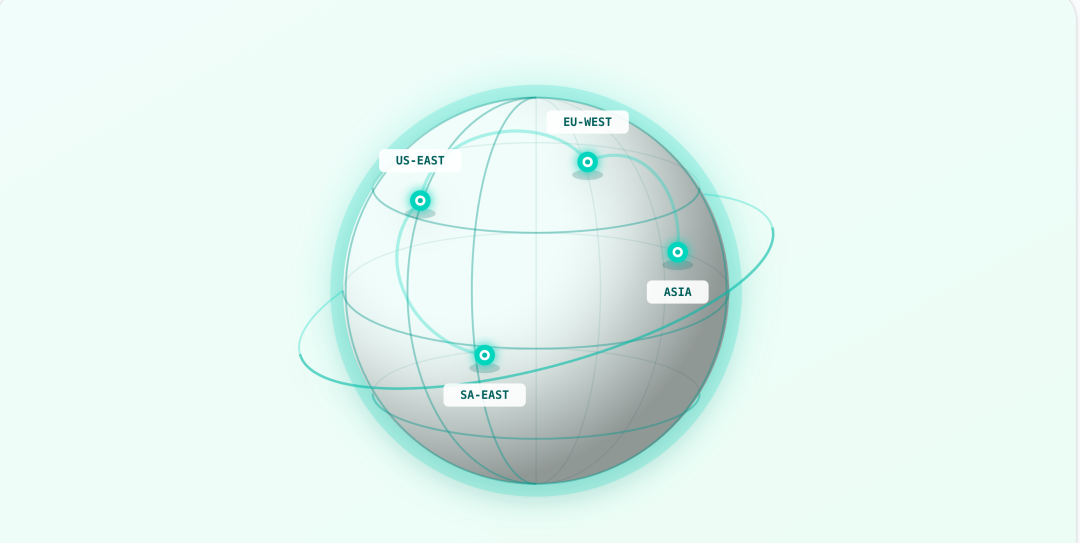
Buckets 存储在 Hub 上,这意味着默认是全球可访问的存储。但并不是所有工作负载都能接受跨区域读取数据的延迟。对于分布式训练和大规模数据流水线来说,存储位置会直接影响吞吐量。
Pre-warming 可以把“热点数据”提前放到更靠近计算资源所在的云服务商和区域的位置。这样一来,就不需要在每次读取数据时都跨区域传输。你只需要声明数据应当在哪个位置可用,Buckets 就会在任务启动前把数据准备好。
这在以下场景中特别有用:例如训练集群需要快速访问大型数据集或 checkpoint,或者在多区域架构中,不同阶段的流水线运行在不同云环境时。
目前我们首先与 AWS 和 GCP 合作,未来还会支持更多云服务提供商。
使用 hf CLI,你可以在 2 分钟内创建并使用一个 bucket。首先安装并登录:
curl -LsSf https://hf.co/cli/install.sh | bash
hf auth login
为你的项目创建一个 bucket:
hf buckets create my-training-bucket --private
假设你的训练任务将 checkpoint 写入本地目录 ./checkpoints,可以把这个目录同步到 Bucket:
hf buckets sync ./checkpoints hf://buckets/username/my-training-bucket/checkpoints
对于大规模传输,你可能希望先查看会发生什么。--dry-run 会打印执行计划,而不会真正进行操作:
hf buckets sync ./checkpoints hf://buckets/username/my-training-bucket/checkpoints --dry-run
你也可以把同步计划保存到文件中,之后再执行:
hf buckets sync ./checkpoints hf://buckets/username/my-training-bucket/checkpoints --plan sync-plan.jsonl
hf buckets sync --apply sync-plan.jsonl
完成后,可以通过 CLI 查看 bucket 内容:
hf buckets list username/my-training-bucket -h
或者直接在 Hub 上浏览:https://hf.co/buckets/username/my-training-bucket.
整个流程非常简单:创建 bucket,把工作数据同步进去,在需要时查看它,而真正需要发布的内容再放入带版本控制的仓库中。 对于一次性操作,可以使用 hf buckets cp 复制单个文件,或使用 hf buckets remove 删除过期对象。
以上功能同样可以通过 Python 使用
huggingface_hub https://github.com/huggingface/huggingface_hub v1.5.0 https://github.com/huggingface/huggingface_hub/releases/tag/v1.5.0
from huggingface_hub import create_bucket, list_bucket_tree, sync_bucket
create_bucket("my-training-bucket", private=True, exist_ok=True)
sync_bucket(
"./checkpoints",
"hf://buckets/username/my-training-bucket/checkpoints",
)
for item in list_bucket_tree(
"username/my-training-bucket",
prefix="checkpoints",
recursive=True,
):
print(item.path, item.size)
这使得 Buckets 可以很方便地集成到训练脚本、数据流水线或任何需要以编程方式管理产物的服务中。Python 客户端还支持批量上传、选择性下载、删除以及 bucket 迁移等更精细的操作。
Buckets 也可以在 JavaScript 中使用
@huggingface/hub https://www.npmjs.com/package/@huggingface/hub
Buckets 还可以通过 HfFileSystem 使用,这是 huggingface_hub 中一个兼容
fsspec https://filesystem-spec.readthedocs.io/
from huggingface_hub import hffs
# List files in a bucket directory
hffs.ls("buckets/username/my-training-bucket/checkpoints", detail=False)
# Glob for specific files
hffs.glob("buckets/username/my-training-bucket/**/*.parquet")
# Read a file directly
with hffs.open("buckets/username/my-training-bucket/config.yaml", "r") as f:
print(f.read())
由于 fsspec 是 Python 远程文件系统的标准接口,因此像 pandas、Polars 和 Dask 这样的库可以直接使用 hf:// 路径从 Buckets 读取或写入数据,而无需额外配置:
import pandas as pd
# Read a CSV directly from a Bucket
df = pd.read_csv("hf://buckets/username/my-training-bucket/results.csv")
# Write results back
df.to_csv("hf://buckets/username/my-training-bucket/summary.csv")
这样你就可以在不改变代码读写方式的情况下,将 Buckets 集成到现有的数据工作流程中。
Buckets 是一个高效且可变的存储空间,用来存放那些仍在不断变化中的产物。当某些内容变成稳定的交付结果后,通常就应该放入带版本控制的模型仓库或数据集仓库中。
在未来的规划中,我们将支持 Buckets 与仓库之间的双向直接传输:例如将最终的 checkpoint 权重提升到模型仓库,或者在数据流水线完成后,把处理好的数据分片提交到数据集仓库。 这样一来,工作层 (用于处理中的数据) 与发布层 (用于最终成果) 既保持分离,又能无缝衔接,形成一个完整的 Hub 原生工作流程。
在向所有用户开放 Buckets 之前,我们与一小部分合作伙伴进行了私有测试。

非常感谢 Jasper、Arcee、IBM 和 PixAI 在早期版本测试中提供的帮助。他们发现了许多问题,并提出了大量反馈,直接推动了这个功能的完善。
Storage Buckets 为 Hub 补上了一个关键的存储层。它为机器学习中那些 高吞吐、可变的数据 提供了原生的存放位置,比如 checkpoint、处理后的数据、Agent trace、日志,以及所有在最终定稿之前仍然有价值的中间产物。
由于 Buckets 构建在 Xet 之上,它不仅比把所有内容都强行用 Git 管理更易用,也更适合 AI 系统中常见的这类相互关联的数据。这带来的好处包括:更快的传输速度、更高效的去重能力,以及在 Enterprise 方案中基于去重后存储量的更优计费方式。
如果你已经在使用 Hugging Face Hub,Buckets 可以让你的更多工作流程都留在同一个平台上。如果你来自 S3 风格的对象存储环境,Buckets 也提供了熟悉的使用模式,同时更适配 AI 产物,并能无缝过渡到 Hub 上的最终发布流程。
Buckets 已包含在现有的
Hub storage plans https://hf.co/docs/hub/en/storage-limits#storage-plans storage page https://hf.co/storage
了解更多并亲自尝试:
Buckets guide Hub documentation CLI Installation guide CLI guide 和reference Example Bucket on the Hub Storage pricing
Buckets guide https://hf.co/docs/huggingface_hub/en/guides/buckets Hub documentation https://hf.co/docs/hub/storage-buckets Installation guide https://hf.co/docs/huggingface_hub/en/installation guide https://hf.co/docs/huggingface_hub/en/guides/cli reference https://hf.co/docs/huggingface_hub/en/package_reference/cli Example Bucket on the Hub https://hf.co/buckets/julien-c/my-training-bucket Storage pricing https://hf.co/pricing#storage
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢