
当我们已经习惯用自然语言让 AI 写文章、画图、生成代码的时候,一个更大胆的问题正在被认真讨论:能不能用一句话,让 AI 自主完成一个完整的药物发现流程?
这不是科幻。Insilico Medicine 的 Alex Zhavoronkov 联合礼来公司的 Jiye Shi,近期在 ACS Central Science 上发表了一篇展望文章,系统梳理了 AI 在药物发现中的演进历程,并提出了一个极具前瞻性的愿景——Prompt-to-Drug,即以一段自然语言描述为起点,由 AI 自主完成从靶点发现、分子设计、合成验证到临床试验规划的全流程闭环。他们将这一终极目标称为药物超级智能(Pharmaceutical Superintelligence, PSI)。

AI 在药物发现中的应用并非新鲜事。文章回顾了过去十余年间的三次关键跃迁,每一次都将 AI 的触角延伸到了药物研发流程的更深处。
第一次是传统机器学习阶段。支持向量机、随机森林等算法被广泛用于虚拟筛选、药物-靶点相互作用预测和药效团识别等分类任务。这些方法对噪声数据鲁棒、可解释性强,但本质上停留在模式匹配层面,难以捕捉复杂的非线性关系。
第二次是深度学习革命。GPU 并行计算的飞速发展(其速度甚至超越了摩尔定律)使得分子动力学模拟、对接模拟和结构-活性关系研究成为可能。深度神经网络在高维多组学数据中展现出优于传统方法的预测能力,被用于筛选具有抗菌活性的多肽和预测化合物结合亲和力。
第三次则是生成式 AI 的爆发。变分自编码器(VAE)、生成对抗网络(GAN)和 Transformer 架构的先后出现,赋予了 AI 真正的创造能力——不再只是从已有化合物中筛选,而是从头设计全新分子。Insilico Medicine 开发的 GENTRL 模型是一个标志性案例:该模型仅用 21 天就发现了针对 DDR1 激酶的高活性、高选择性抑制剂,随后在 27 天内完成了合成与验证。此后,他们又在 30 天内完成了一个 CDK20 抑制剂的发现。
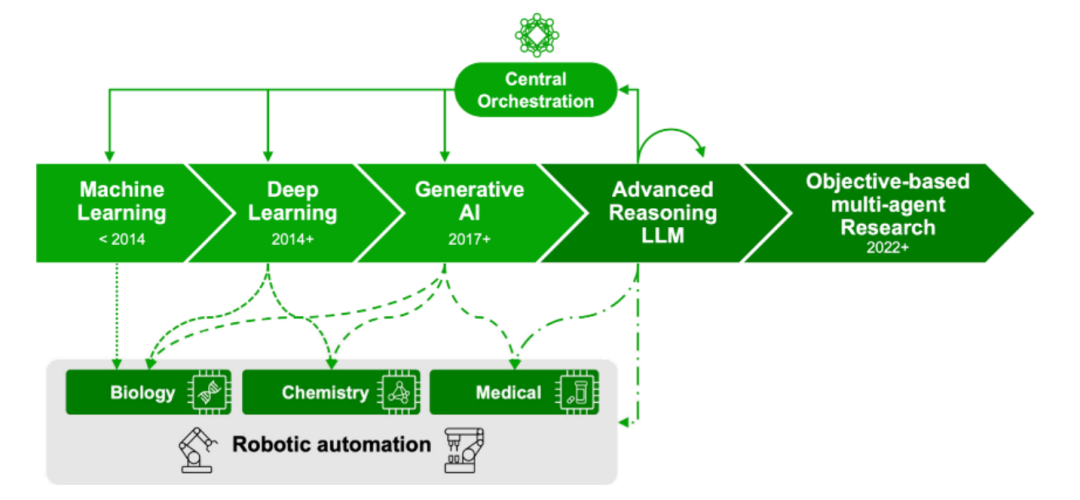
随后,大语言模型(LLM)作为基础模型登场。BioGPT、PandaOmics 等平台能够从海量文献、专利和基金数据中挖掘生物网络与治疗靶点;cMolGPT、DrugGPT 等基于 GPT 架构的生成化学模型则可以直接生成新型药物分子结构。然而,文章也坦率指出了 LLM 在端到端分子发现任务中的固有局限:基于模式识别的生成机制缺乏对生化原理的深层理解,SMILES/SELFIES 的分词方式会丢失立体化学等关键信息,且模型难以探索训练集之外的化学空间。
文章提出了一个颇具洞察力的观点:当前 AI 药物发现的核心瓶颈不在于缺乏优秀的单点工具,而在于这些工具之间的割裂与不互通。
在传统药物研发流程中,靶点发现、分子设计、生物验证和临床开发等阶段由不同团队负责、使用不同平台,产生不同格式的数据。这种拼凑式的工作流导致了大量的切换成本、信息损耗和协调延迟。文章用两个具体例子加以说明:在小分子苗头化合物拓展(hit expansion)过程中,一位科学家需要在化学信息学软件、计算化学工具、采购系统、生成式 AI 工具、逆合成规划软件和检测数据分析工具之间来回切换,而单个科学家往往并不掌握所有这些工具的使用方法;在样品注册与追踪方面,不同治疗模态(小分子、生物制品、RNA 等)分散在不同的 LIMS 系统中,形成了数据孤岛。
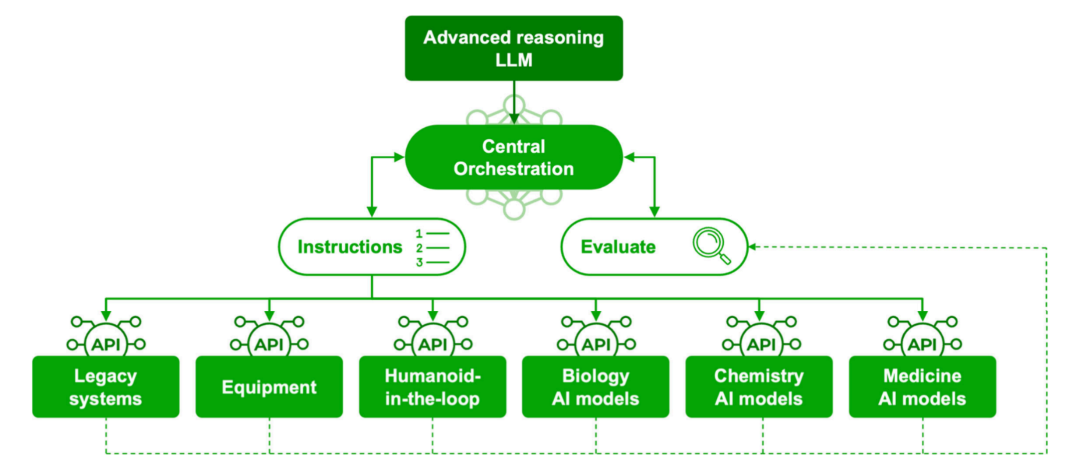
作者认为,真正的变革将来自于把这些分散的子系统连接成一个有向系统之系统(directed system-of-systems),由中央控制器统一编排各个独立运行的组件系统。这种智能系统之系统架构能够同时分析过程输出、评估故障与异常、整合新的子系统资源、预测失败点,并管理数据组织和安全功能。
文章用相当篇幅讨论了 LLM 高级推理能力和多智能体系统在推动端到端药物发现中的关键角色。
当代 LLM 正在超越表层的 token 模式识别,展现出逻辑推理、规划、多步问题求解和因果推理等更深层的认知能力。DrugPilot 是一个基于 LLM 的 AI 智能体框架,能够自主支持完整的药物发现管线,整合多模态数据并高效协调工具使用;AgentD 则能自主检索生物医学数据库、生成药物分子结构、预测性质、迭代优化类药性,并预测三维蛋白-配体构象。
更引人注目的是那些已经实现了实验闭环的系统。ChemAgents 使用基于 LLM 的多智能体架构,能够依序完成文献检索、实验设计、机器人执行实验操作和计算分析结果的全流程——输入仅需一段自然语言提示。Synbot 则可以规划并执行用户提供的化合物结构的逆合成和机器人合成。ChemCrow 和 Coscientist 这类具备类 RAG 能力的平台,甚至可以接受类似规划并执行一种驱虫剂的合成这样的自然语言指令,利用实验室设备合成目标化合物。
在假说生成与科学发现层面,DORA 和 Google 的 Co-Scientist 等 AI 科学家助手的出现进一步拓展了 AI 的能力边界。这些多智能体研究平台能够扫描已发表的研究论文、组学数据集和生物医学数据库,提出新的假说和研究工作流。早期应用案例已经包括:重新定位表观遗传修饰药物治疗纤维化、整合组学数据指导精准医学研究,甚至为天体生物学的质谱数据集规划实验工作流。
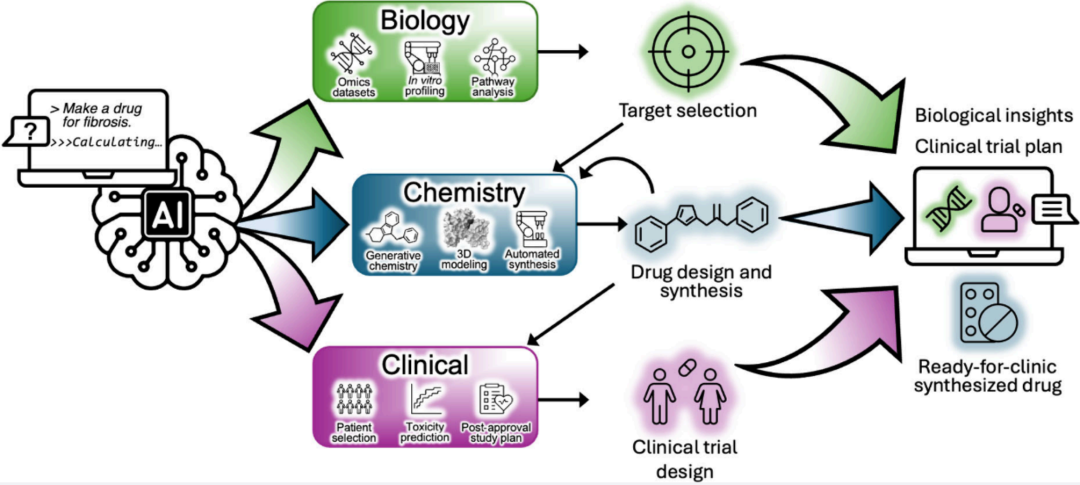
文章的核心贡献之一是提出了一个完整的 Prompt-to-Drug 概念工作流。设想一个场景:用户输入为特发性肺纤维化(IPF)设计一种药物,系统随即启动一整套自主研发流程。
在这个工作流中,一个高级推理 AI 模型充当总导演。它首先整合公开数据与私有数据,结合已发表文献,生成一份研究计划,并派出多组 AI 智能体分头行动。生物学智能体操控自动化实验室,从文献综合和体外实验验证模型中筛选疾病相关靶点;化学智能体调用生成化学平台设计靶向药物分子,遵循传统的先导化合物优化流程,利用对接模型、合成可及性评分和 ADMET 预测算法进行优先级排序;生物学洞见和临床前测试数据则指导后续的临床试验设计,由 PROCTOR、InClinico 和 HINT 等临床预测模型前瞻性地识别最可能获得成功的患者群体和试验方案。
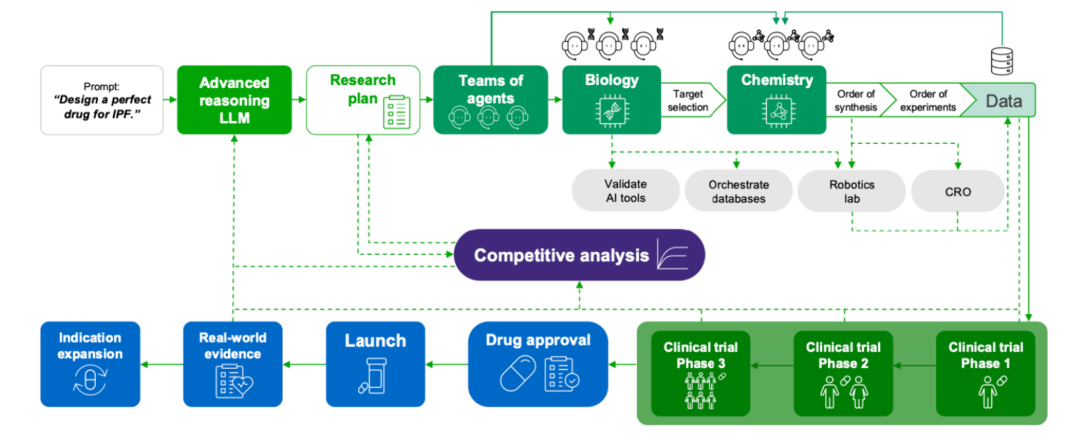
值得一提的是,作者特别强调了混合方法的必要性。纯粹依赖 LLM 的 SMILES/SELFIES 编码是不够的,下一代模型需要将三维分子图、电子密度图和实验检测数据整合到统一的潜空间中进行多模态基础模型训练。在 Insilico Medicine 开发新型 TNIK 抑制剂 rentosertib 的实际案例中,其 Chemistry42 平台正是结合了多种二维和三维结构模型来识别最有前景的先导分子。rentosertib 已完成二期临床试验,证明了 AI 工具确实能够识别具有生物学依据的疾病靶点并设计出安全有效的药物分子。
文章还提出了一个颇具想象力的概念——仿人机器人参与闭环(humanoid-in-the-loop)。由于仿人机器人天然适配为人类科学家设计的传统实验设备和工作空间,它们可以作为中央推理 AI 调度的一个智能体,以不间断轮班的方式执行高技术含量的生物和化学实验操作,最大限度地减少步骤间的停机时间。Insilico Medicine 已经在其自主临床前实验室设施中开发此类工作流,并在抗衰老/抗衰老治疗学研究中取得了初步成果。
尽管愿景宏大,文章并未回避当前技术的局限性。
幻觉问题首当其冲。LLM 生成的生物医学内容中存在较高的幻觉率——无论是生成化学结构的文本描述、提出阿尔茨海默症的候选药物,还是预测靶点拓扑表面积、解读组学数据或识别疾病相关基因,都有大量不准确输出的报告。在 Insilico Medicine 自身的实践中,也观察到生成模型提出合成上不可行或与已知构效关系不符的分子骨架的情况,需要人工干预和专家过滤。
级联错误是另一个关键挑战。在多智能体系统中,早期模块(如靶点口袋和活性预测)中的不准确性可能逐级传播到下游的分子生成、合成规划和临床试验模拟中。即使是 AlphaFold2 这样的金标准工具,也不能在所有情况下都提供准确预测,当早期步骤涉及基于结构的分子拟合和对接模拟时,这类失败链条可能严重复合。文章建议通过智能体间投票验证、置信度传播、实时回溯与任务重启,以及关键节点的人类介入等策略来管理这一风险。
此外,模型输出的可解释性和可追溯性仍然是悬而未决的问题。与传统 QSAR 或基于规则的系统不同,LLM 常常作为黑箱运行,这在监管层面——尤其是作用机制预测、患者分层和临床试验规划等法律要求可解释性的场景——构成了实质性障碍。
文章最后提出了几项建议。首先,面向未来的 AI 药物发现需要多模态、项目特异性的模型——训练数据既要足够广泛又要足够深入,且需根据具体药物开发项目进行针对性过滤。其次,尽管自主执行是长期目标,人类监督和问责在当前科学、法律和监管条件下不可或缺——所有输出都应附带机器可读的完整决策记录,系统需内置人类审查、暂停和否决 AI 决策的机制。第三,这一愿景的实现不可能由任何单一实体完成,需要学术界、生物技术公司和监管机构的全行业协作——研究团队应在每个阶段发表成果,将自动化闭环子系统视为标准实验设备,并从一开始就设计 API 接口以便中央编排 AI 访问和调度。
从 GENTRL 在 21 天内发现 DDR1 抑制剂,到 rentosertib 完成二期临床试验,Insilico Medicine 的实践已经在逐步验证 AI 驱动药物发现的可行性。而从单点工具到系统集成、从辅助决策到自主执行的演进路径,也正在变得越来越清晰。Prompt-to-Drug 或许不会在短期内完全实现,但它所指向的方向——一个由 AI 作为共同科学家驱动创新、改善患者结局、变革药物开发方式的未来——已经在路上了。
参考文献:Zhavoronkov, A.; Gennert, D.; Shi, J. From Prompt to Drug: Toward Pharmaceutical Superintelligence. ACS Cent. Sci. 2026. DOI: 10.1021/acscentsci.5c01473
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢