

【该工作由南京大学自然语言处理组与微软亚洲研究院合作完成,论文入选AAAI2026Oral。扩展版论文链接:https://arxiv.org/abs/2505.21505,代码:https://github.com/NJUNLP/Language-Neurons-Alignment】
01
研究动机
大型语言模型在多语言场景下已经展现出较强的整体能力,但由于预训练语料在不同语言之间分布不均衡,高资源语言与低资源语言之间仍存在显著性能差距。鉴于低资源语言的数据本身难以获取、难以支撑额外的大规模预训练,如何在现有模型基础上提升其能力成为实际需求。在这一背景下,多语言对齐(Multilingual Alignment)作为一种更具可操作性的途径,为增强低资源语言的推理表现提供了有效方向。
目前,多语言对齐方法的效果已在多项任务中得到验证,然而一个关键问题始终缺乏系统性解释:多语言对齐为什么有效?它在模型内部究竟改变了哪些结构与表征方式?为回答这一问题,近期研究开始尝试从神经元粒度理解多语言能力来源。现有主流划分通常将与语言相关的神经元分为两类:一类仅在某一种或极少数语言上表现出较高激活,被称为语言特定神经元(language-specific);另一类在所有语言中均保持较强激活,被视为通用神经元(general)。这一二元框架为分析多语言能力提供了初步结构化视角,但在实际统计中,如图所示,仍存在无法被准确归类的激活模式:有相当数量的神经元会在多种语言上频繁激活,却并未在所有语言中保持一致作用:在现有体系下,它们通常被笼统归入语言特定,但其跨多语言的激活特征又与真正意义上的语言特定神经元并不一致。这一现象提示,要深入理解多语言对齐的内部机制,仅依赖“语言特定—通用”的二元划分可能不足,亟需更精细的描述与分析框架。

图1:某神经元在不同语言上激活概率的示例
02
方法:语言神经元的三元分类法与识别算法
2.1 三类语言神经元的划分与定义
结合激活概率统计,我们重新整理并扩展了语言神经元的定义体系:
语言特定神经元: 只在某一种语言上具有高激活概率,对其他语言激活很弱。它们主要承担该语言特有的输入 / 输出形式的编码与解码。
语言相关神经元: 在多种但非全部语言中保持高激活,用来刻画跨若干语言共享的结构与模式。(这是重点刻画的“中间层次”类别,也是以往工作容易混入语言特定的部分)
通用神经元: 在所有语言上都具有较高激活,更多与任务相关的通用知识和推理模式有关,而不是绑定于某一种语言。
2.2 神经元识别算法
仅根据在哪些语言上出现激活难以准确判断神经元的功能,我们更关心其是否真实参与多语言推理过程,而非在与任务无关的文本上偶然被激活。为此,我们在语言维度上引入两个核心指标:
(1)激活概率分布的熵: 用于衡量神经元在不同语言间的激活偏好,即语言特异性。
(2)跨语言的最大激活概率: 用于衡量神经元在至少某些语言上是否具有足够高的激活强度,即有效性。
我们将两项指标整合为统一评分体系,对所有神经元进行排序:
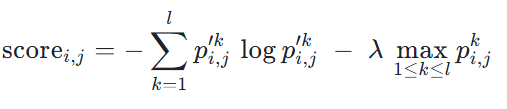
从而同时过滤掉激活弱、语言偏好不明显的神经元,以及“看似特化但实际不参与推理”的神经元。
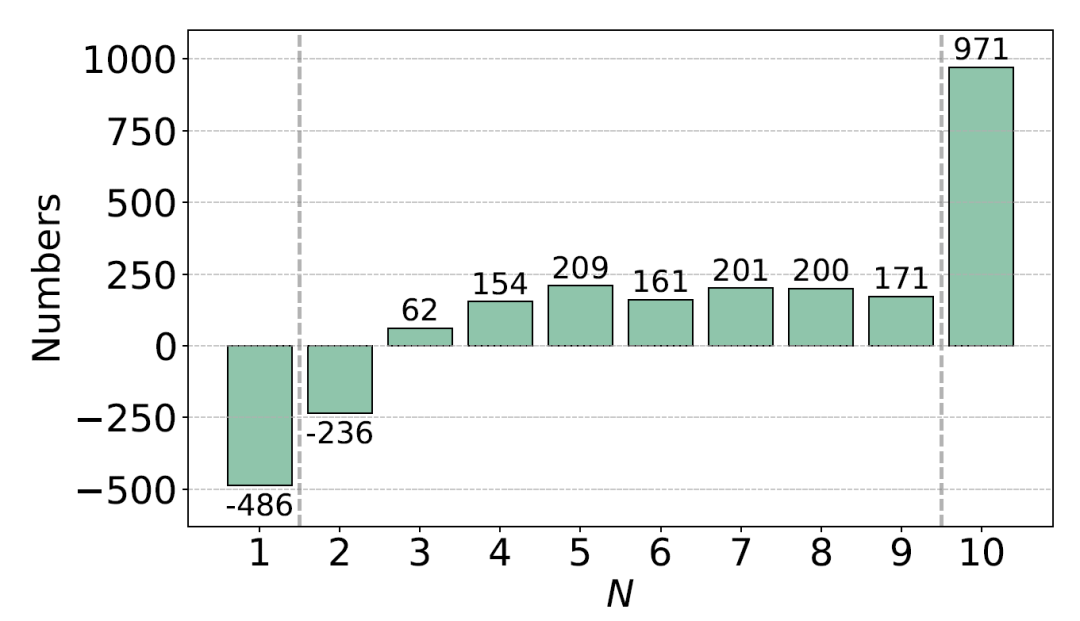
在此基础上,我们取语言数量 N=10,根据神经元激活概率超过阈值的语言数量完成最终分类:
仅在 1 种语言上高激活 → 语言特定
在 2–9 种语言上高激活 → 语言相关
在全部 10 种语言上高激活 → 通用
需要强调的是,我们在多语言数学推理数据集(MGSM、MSVAMP)的模型回答生成过程中统计激活,而非在一般多语言文本上,确保识别到的神经元确实与多语言推理能力相关。
03
实验设置
为在可控成本下系统分析多语言对齐前后的神经元变化,我们选择两种 7B 规模的开源数学推理模型作为研究对象:
MistralMathOctopus-7B
MetaMathOctopus-7B
两者均在多步数学推理数据上进行过微调,适合作为研究多语言推理能力及其内部结构变化的基座模型。
在任务设置方面,我们使用两个具有代表性的多语言数学推理基准:
MGSM:经典的多语言数学推理评测集,用于主要实验结果以及神经元激活统计;
MSVAMP:分布与 MGSM 不同的 out-of-domain 数据集,用于验证分析结论的泛化能力。
覆盖十种语言:英语(en)、中文(zh)、俄语(ru)、德语(de)、法语(fr)、西班牙语(es)、日语(ja)、斯瓦希里语(sw)、泰语(th)和孟加拉语(bn)。其中英语作为中枢语言,用于构造对齐信号。
在对齐方法上,我们采用 MAPO 框架 (Multilingual-Alignment-as-Preference Optimization) 中基于 DPO 的变体来实现多语言对齐,具体包括:
利用多语言算术推理数据构造偏好对;
使用多语言翻译模型将非英语回答翻译回英语,并计算其与英语回答之间的一致性;
将该一致性作为偏好优化中的奖励信号,对模型进行对齐训练。
对齐前后,我们分别统计模型在多语言推理生成过程中的神经元激活概率分布,比较三类神经元对齐前后的数量变化及其在不同层的分布差异,以分析对齐对模型内部结构的影响。
04
主要发现:多语言对齐如何改变模型内部结构
4.1 神经元失活实验
基于前述识别方法,我们在 base 模型中识别三类神经元,并通过 Accuracy 和 Perplexity 消融实验检验它们在多语言推理中的作用,如图所示:
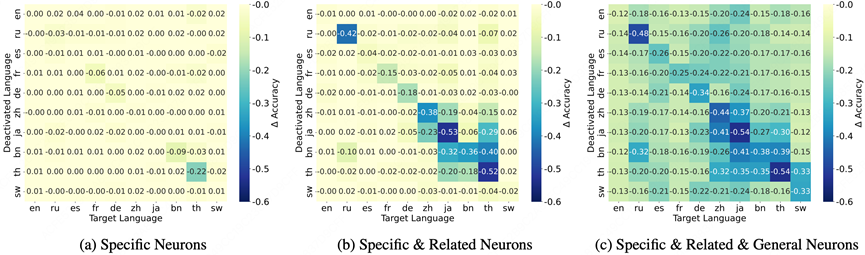
图2:失活基于MistralMathOctopus及MGSM得到的不同种类神经元后的模型准确率
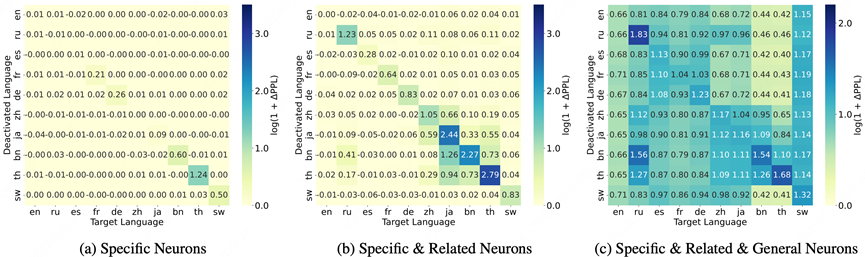
图3:失活基于MistralMathOctopus及MGSM得到的不同种类神经元后的模型困惑度
禁用某语言的语言特定神经元会降低该语言的回答准确率,并提升该语言 PPL,表明模型在该语言上依赖其语言特定神经元;
在此基础上,若进一步禁用该语言的语言相关神经元(即同时禁用 language-specific 与 language-related),模型性能进一步下降,且 PPL 上升幅度更大,说明语言相关神经元在多语言推理中同样起到关键作用;
禁用某语言的语言相关神经元对其他语言的性能影响相对较小,表明这些神经元在多个语言之间呈“分散共享”结构,而非被单一语言强依赖;
当同时禁用某语言对应的语言特定、语言相关及通用神经元时,不仅该语言性能显著下降,其他语言性能亦受到明显影响,说明通用神经元承载跨语言共享的推理能力。
这些结果表明:某语言的推理能力同时依赖语言特定与语言相关神经元,而语言相关神经元在多语言之间形成“局部共享”的支撑结构,是连接多种语言的重要桥梁。
4.2 四阶段多语言推理流程
在识别出语言特定、语言相关和通用三类神经元后,我们进一步分析了它们在模型各层的数量分布情况。结果显示,这三类神经元在深度方向上呈现出结构化的变化模式,如图所示,据此可将大模型的多语言推理过程概括为以下四个阶段:
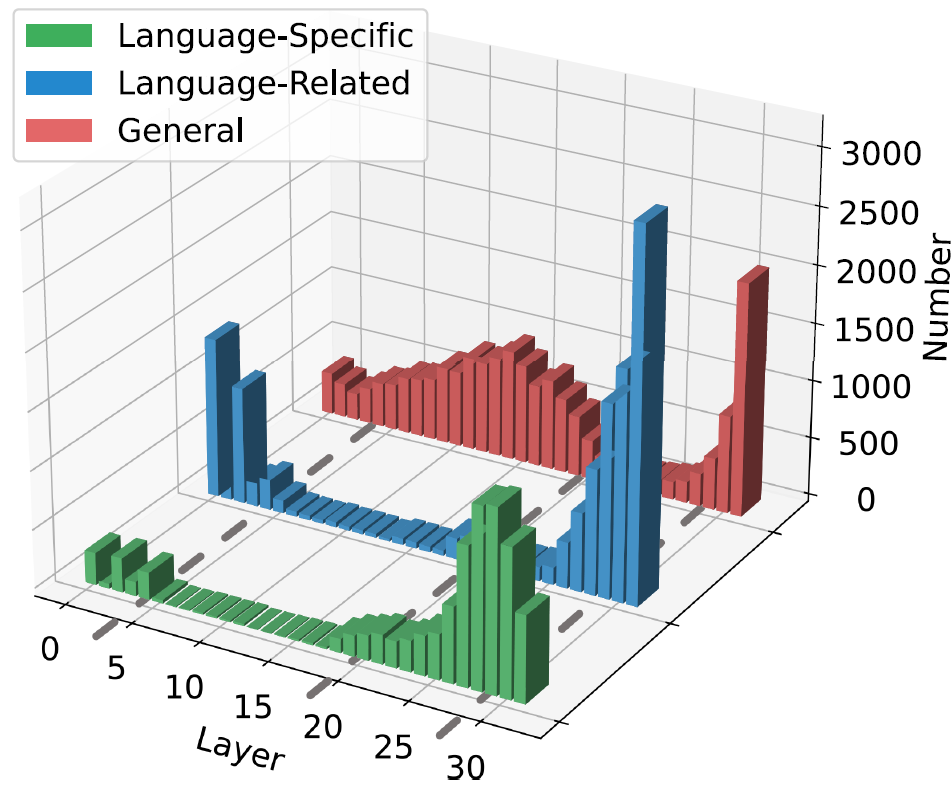
图4:不同种类神经元的层级别分布
(1)多语言理解
在模型的底部若干层中,语言特定与语言相关神经元数量同时处于较高水平,而通用神经元相对较少。该阶段主要负责将不同语言的输入映射到统一或相近的语义空间,为后续的语言无关推理奠定基础。
(2)共享语义空间推理
在中间层区域,通用神经元占据主要位置,而语言特定 与语言相关神经元的数量显著减少。模型在此阶段主要执行与语言无关的推理与计算,不同语言共用相同的推理结构。
(3)多语言输出空间转换
接近输出端的若干层中,语言特定与语言相关神经元数量再次明显上升,而通用神经元数量下降至较低水平。该阶段的功能是将共享语义表示重新投射到各目标语言的输出空间中,恢复语言间的结构差异。
(4)词汇空间输出
在最终输出层,三类神经元的数量分布再次出现特征性变化:
语言特定神经元在该层达到数量峰值,强调其在目标语言词汇选择中的重要作用;
语言相关神经元数量则呈下降趋势,与上一阶段形成对比,表明跨语言共享结构在词汇级生成中的作用相对减弱;
通用神经元数量重新回升,与输入层的分布较为一致,可能与模型依赖共享词表和通用知识来完成最终输出有关。
这一四阶段框架体现了不同类型神经元在模型内部的分层组织关系,相比现有对多语言推理的粗粒度描述,更系统地揭示了模型内部表征从输入到最终输出的转换机制。
4.3 多语言对齐的影响
在明确 base 模型的层级结构后,我们进一步比较了对齐前后三类神经元在不同层次的数量变化,如图所示。
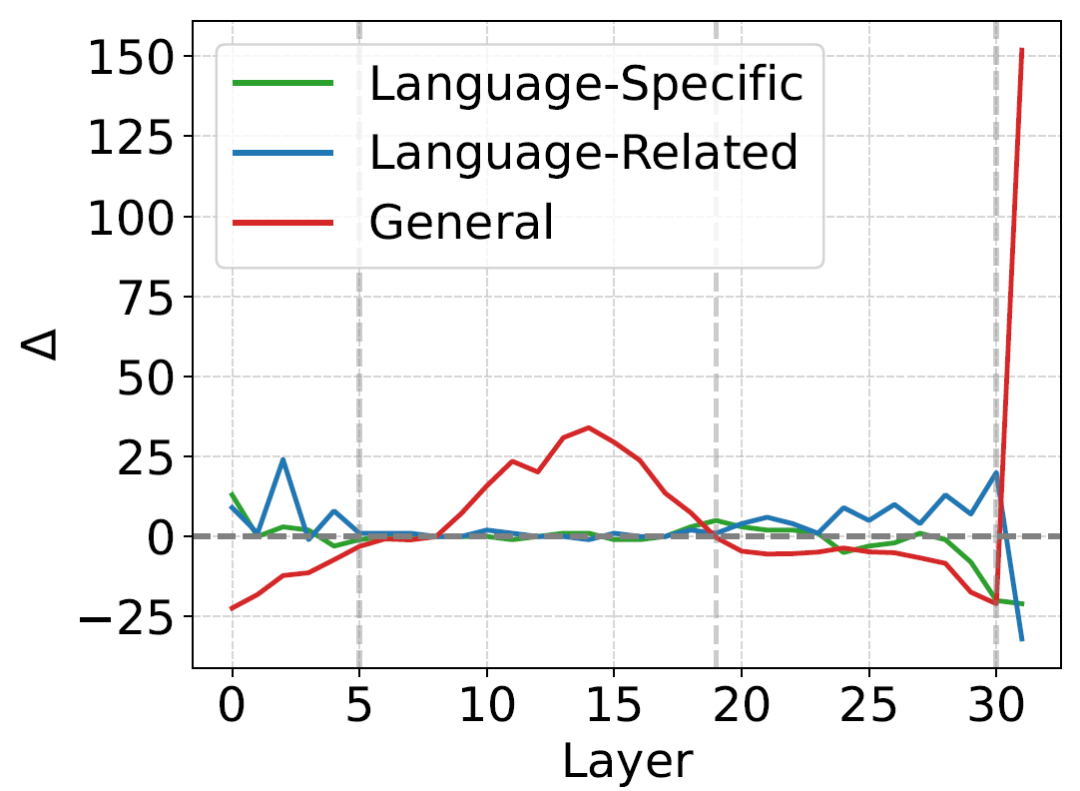
图5:对齐后不同种类神经元的层级别变化
分析显示,多语言对齐并不仅是对输出分布的调整,而是在模型内部引发了系统性的结构重组,主要体现在以下方面:
(1)输入阶段:更依赖语言敏感结构
在多语言理解阶段,语言特定与语言相关神经元数量均有所上升,而通用神经元数量相应下降。这表明模型在输入侧更依赖语言相关结构来建立跨语言间的映射,为后续推理的对齐提供基础。
(2)输出阶段:从“单语言特化”转向“跨语言共享”
在多语言输出空间转换阶段,语言相关神经元的数量显著增加,而语言特定 神经元有所减少。这一反向变化说明,对齐后的模型在生成目标语言输出时,会更多利用跨语言共享的结构,而减少对高度语言特化神经元的依赖。
(3)整体趋势:由“单语言依赖”转向“多语言共享”
跨层统计如图所示,这进一步显示对齐后:
语言特定神经元整体减少,
语言相关神经元显著增加,
通用神经元数量也呈现上升趋势。
结合多语言激活模式进一步观察可以发现:部分原本仅在少数语言中活跃的神经元,在对齐后会在更多语言间被共同激活,其语言覆盖范围呈扩大趋势。这一现象在不同模型与数据集上均具有一定一致性,提示多语言对齐可能使模型更倾向于使用在多语言间具有更高共享度的神经元结构。
4.4 自发多语言对齐现象
此前研究提出了自发多语言对齐(Spontaneous Multilingual Alignment)现象:即使对齐训练仅涉及少数语言,其他未参与对齐的语言也会同步受益。本文在 MAPO 框架下验证了这一现象:
表1:MistralMathOctopus对齐前后模型在MGSM上的准确率。“X/Y ⇒ T“表示多语言对齐中语言X和Y向语言T进行对齐

例如仅在中文与德语上执行对齐训练(zh/de ⇒ en),模型在 MGSM 上的平均准确率由 57.8 提升至 63.6;
多种未直接参与对齐的语言(如西班牙语、法语、泰语等)也出现了不同程度的性能提升。
为了理解这一现象背后的内部机制,我们进一步统计了对齐前后,不同语言对应的神经元数量变化。结果显示:
表2:自发多语言对齐实验中训练和未经训练语言上不同种类神经元数量变化的平均结果
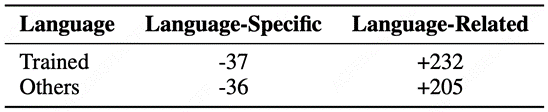
对齐语言中:语言特定神经元数量减少,而语言相关神经元数量显著上升;
未对齐语言中:同样观察到语言相关神经元数量上升的趋势,尽管幅度较小。
这一结果说明,对齐训练不仅改变了对齐语言内部的神经元参与模式,也在一定程度上影响了其他语言的神经元结构:与多种语言共同相关的语言相关神经元在更多语言间得到使用,其共享范围有所扩大。
因此,自发多语言对齐不仅体现在性能提升上,也在神经元层面呈现出一致的结构变化,为这一现象提供了进一步的证据支持。
05
总结
本文从神经元粒度系统分析了多语言对齐对大型语言模型内部结构的影响。通过提出更精细的三元神经元分类体系,并构建结合特异性与有效性的统一识别方法,我们揭示了语言相关神经元在多语言能力中的关键作用,并据此刻画了模型在多语言推理中经历的四阶段内部流程。进一步的对齐前后对比显示,多语言对齐会重塑模型内部的神经元参与模式,使模型更倾向于依赖在多种语言间共享的表征结构。这一视角同时为“自发多语言对齐”等现象提供了神经元层面的支持。
总体来看,本文为理解多语言对齐的内部机制提供了更具结构化与可验证性的解释路径,也为后续改进多语言模型的训练方法和对齐策略提供了新的分析依据。
参考文献
[1] She, S.; Zou, W.; Huang, S.; Zhu, W.; Liu, X.; Geng, X.; and Chen, J. 2024. MAPO: Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization. In Ku, L.-W.; Martins, A.; and Srikumar, V., eds., Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 10015–10027. Bangkok, Thailand: Association for Computational Linguistics.
[2] Tang, T.; Luo, W.; Huang, H.; Zhang, D.; Wang, X.; Zhao, X.; Wei, F.; and Wen, J.-R. 2024. Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models. In Ku, L.-W.; Martins, A.; and Srikumar, V., eds., Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 5701–5715. Bangkok, Thailand: Association for Computational Linguistics.
[3] Wendler, C.; Veselovsky, V.; Monea, G.; and West, R. 2024. Do llamas work in english? on the latent language of multilingual transformers. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 15366–15394.
[4] Zhao, Y.; Zhang, W.; Chen, G.; Kawaguchi, K.; and Bing, L. 2024b. How do large language models handle multilingualism? arXiv preprint arXiv:2402.18815.
[5] Zhang, S.; Gao, C.; Zhu, W.; Chen, J.; Huang, X.; Han, X.; Feng, J.; Deng, C.; and Huang, S. 2024. Getting More from Less: Large Language Models are Good Spontaneous Multilingual Learners. In Al-Onaizan, Y.; Bansal, M.; and Chen, Y.-N., eds., Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 8037–8051. Miami, Florida, USA: Association for Computational Linguistics.
[6] Huang, H.; Tang, T.; Zhang, D.; Zhao, W. X.; Song, T.; Xia, Y.; and Wei, F. 2023. Not all languages are created equal in llms: Improving multilingual capability by cross-lingual-thought prompting. arXiv preprint arXiv:2305.07004.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢