
《追AI的人》之AI科普系列短视频,将持续用简单清晰的语言向公众解释对于人工智能的普遍疑问,推动社会就人工智能的发展和治理达成共识。
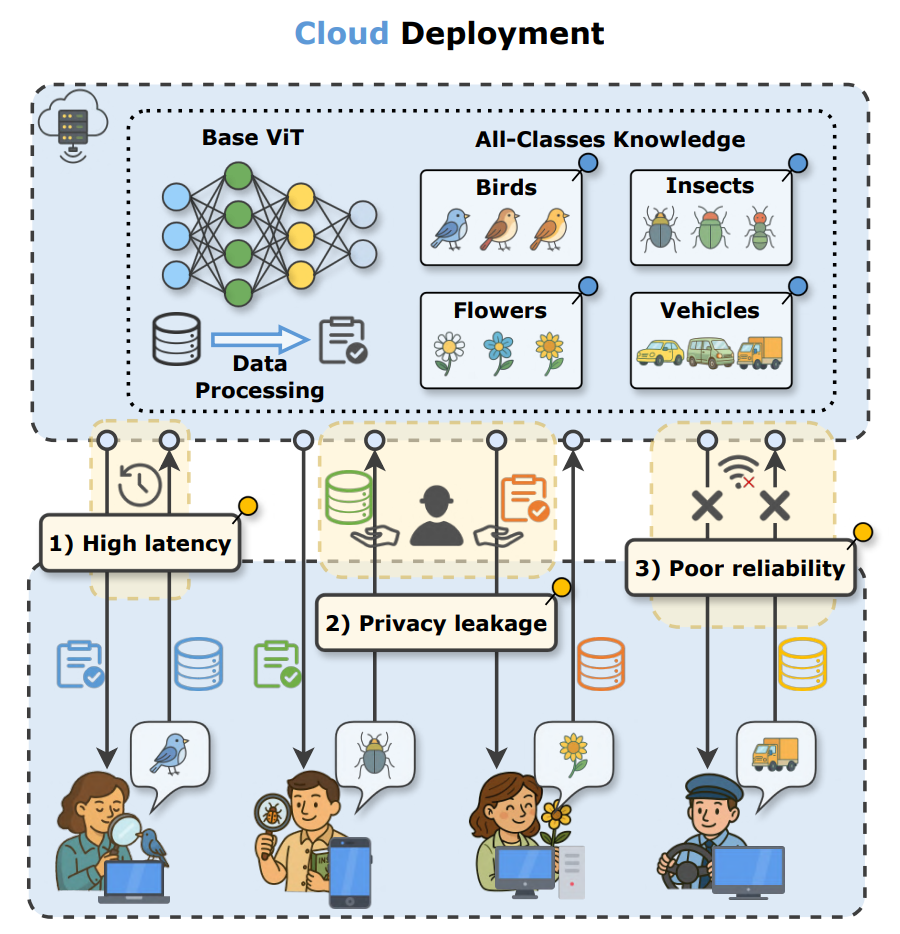
车载摄像头的视角,但是AI总是注意力不集中,不识别车辆,反而把路边的花,天上的鸟框起来识别,司机在画面外焦急得说“我只想识别行人和车辆啊!!!”
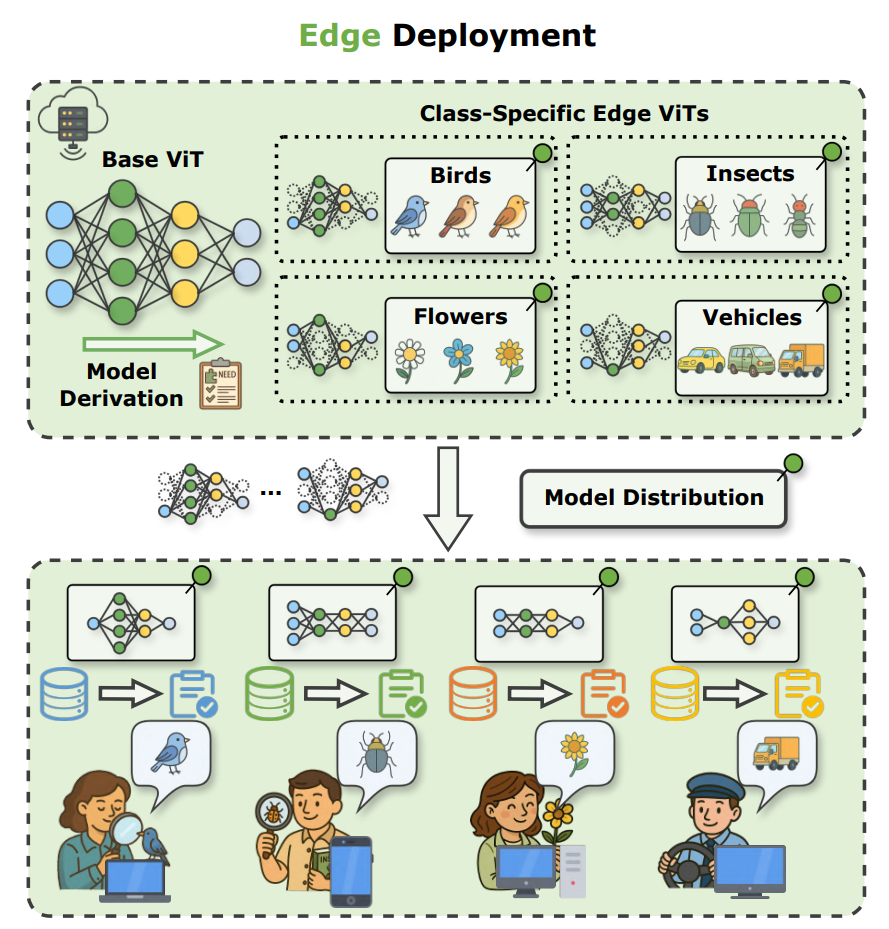
现实中的边缘设备,其实只需要模型的一小部分类别知识来解决应用场景中的特定任务,此时一个“大而全”的通用模型反而不如“小而专”的定制化模型,以保留模型通用能力为目标的轻量化方法自然是不合理的。
“大而全”的通用模型
| “小而专”的定制化模型
|
为了从预训练的通用ViT中派生出聚焦目标类别的定制化小模型,最直接的方法就是将现有剪枝技术依赖的校准数据替换为目标类别数据,通过数据驱动模型关注到我们想让它关注的类别。
但是现有剪枝策略“先剪枝再训练”的范式面临着不可逆的知识损失。
模型轻量化好比一个整理行李箱的过程,而一个预训练的模型由于缺乏合理的知识分布就像一个大包小包塞满杂乱物品的行李箱,此时若是为了轻便丢掉一些包裹,我们只能保证这个包裹看起来不太重要,但无法保证里面没有装着必要的物品。
为了解决这种范式的缺陷并有效提取模型中和目标类别相关的知识,我们提出了基于“先训练再剪枝”范式的模型派生方法Vulcan。
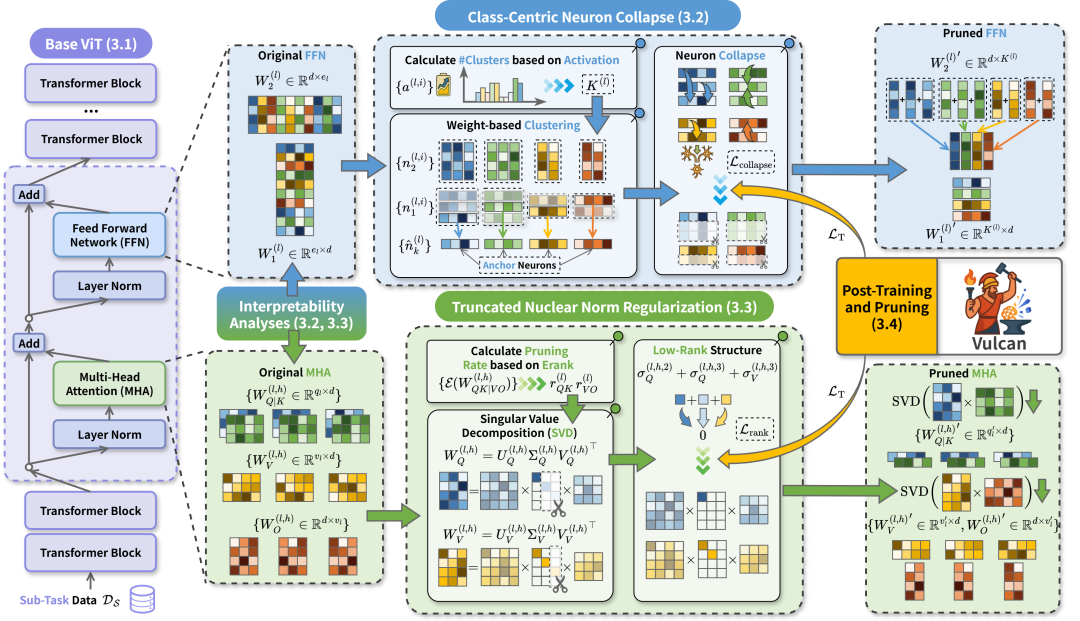
它的核心思想是在剪枝前主动为模型引入“结构化参数冗余”。就像整理行李箱时,先根据重要程度把物品归类到不同包裹中,再把装着无用物品的包裹直接丢掉。
为了实现这个想法,我们先分析了模型里的知识是怎么分布的,就像看看行李箱每个包里都装着什么。
结果发现:FFN主要存放和具体类别相关的知识,而MHA更多存储通用信息。

基于该观察,我们做了两件关键事情:一是把FFN里和目标类别相关的知识集中保留在少量关键神经元上;二是将MHA中的通用知识挤压到部分维度中。
通过这种方式,我们重新整理了模型里的知识结构,让大模型能够近乎无损地转换为一个更小、更专注的模型。
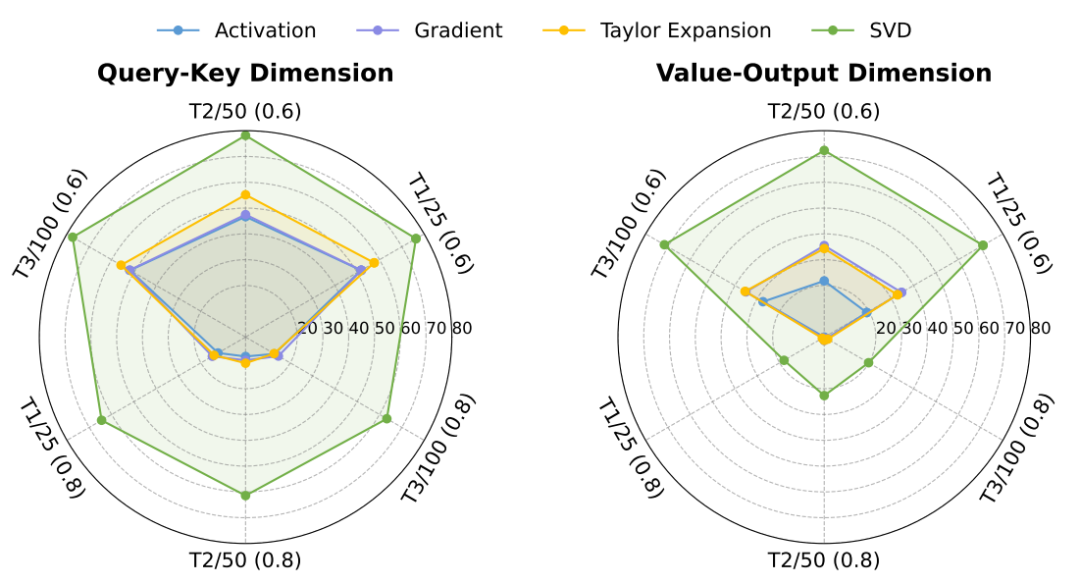
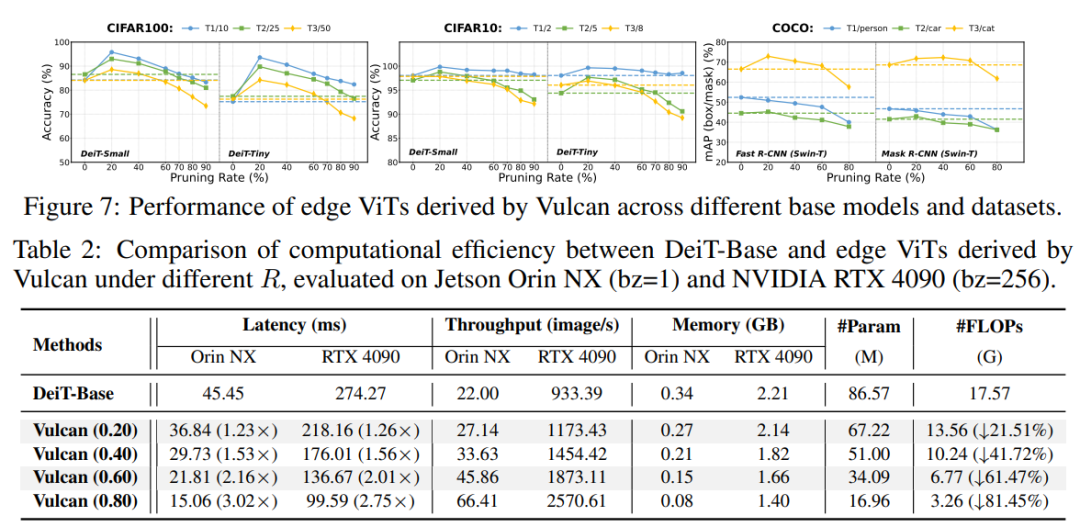
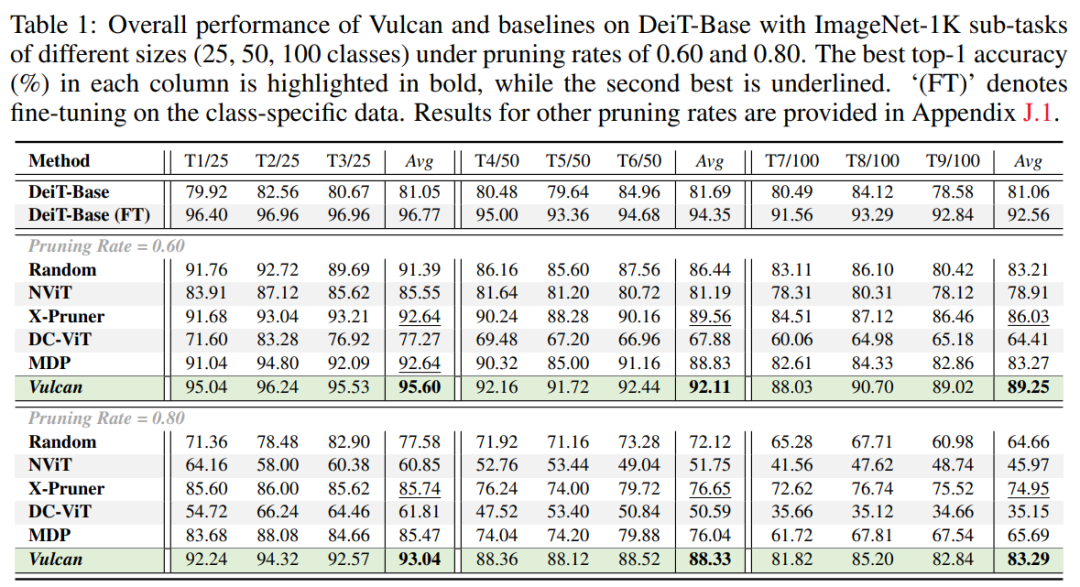
模型砍掉一大半,准确率反升15%!Vulcan派生的模型在ImageNet子任务上的准确率最高可提升15.12%,而模型规模仅为原模型的20%–40%。同时其始终优于当前最先进的结构化剪枝方法,在类特定准确率方面最高可提升13.92%。
🔴 只有深入理解模型内部知识结构,才能实现稳定可靠的轻量化部署。
🔴 揭示ViT中类相关与类无关知识的解耦分布
🔴 通过后训练主动塑造可控冗余结构,实现了近乎无损的类特定模型派生
🔴 为视觉大模型从“通用泛化”走向“精准服务”提供了切实可行的新思路
更多关于的Vulcan分享,点击阅读👇











关注公众号发现更多干货❤️



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢