
导语
金融机构、央国企的AI落地面临着监管与效率的双重压力。一方面,2025年3月中国人民银行明确要求安全稳妥推进大模型应用;另一方面,金融机构正大力推进AI在业务场景的落地应用,某头部机构通过 AI 将信贷审批报告分析从数小时压缩至3分钟,准确率也在稳步提升。
在安全稳妥与创新突破的矛盾中, 全链路背书成为破解之道。澜舟可信智能体全链路技术体系构建了金融级可信底座,将AI智能体从 "黑箱输出" 转化为 "可靠、可控、可溯" 的可信智能助手,直至数字员工,助力金融机构和其他大中型企业在监管红线前实现 AI 价值突围。
01
破局幻觉:
企业智能体应用可信、可控的全链路背书
大模型作为生成式AI,底层是基于海量数据的概率性生成,在应用中生成的内容与客观事实不符或缺乏事实依据的现象,即模型幻觉,是在金融领域落地的核心障碍之一。
幻觉产生的根本原因在于模型固有的技术局限,包括特定领域知识的覆盖不足、模型对复杂逻辑的理解能力有限,以及推理过程中固有的概率性等,单纯依靠模型本身的技术优化(如对齐、微调),无法完全解决 “可信” 的认知问题和 “可控” 的管理问题。
大模型可信与可控,本质上需要全链路背书作为底层支撑。从数据源头、执行过程、结果生成的三层背书,是把大模型的 “黑箱输出” 转化为 “可追溯、可验证、可信任” 结果的关键,而背书的本质,既是责任的锚定,也是可信度的证明,更是可控性的抓手。技术优化降低风险,背书定义责任、建立信任、落地管控。
澜舟科技依托大模型与智能体核心技术,融合多个实际落地项目经验,构建了一套贯穿大模型智能体应用全生命周期的可信技术框架,旨在解决大模型应用在可信与可控方面的核心痛点。该框架的核心理念为:可信可控=数据资产高可靠+执行过程强可控+最终结果全可溯。其根本目标在于确保金融大模型智能体应用的领域专业性、过程严谨性及法规遵从性。
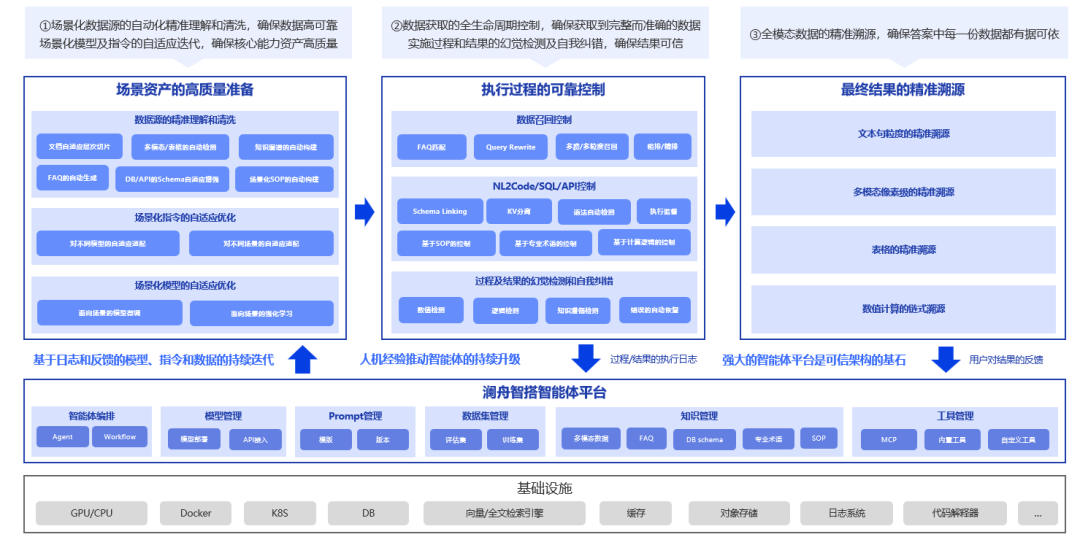
数据可靠:数据实现了场景化知识资产的转化
金融大模型的数据资产体系,涵盖了文档、多模态数据、知识图谱等常规基础数据,而且更聚焦具体业务场景,纳入Prompt指令集、标准化流程及模型迭代优化成果等核心资产。三者形成互补协同的资产矩阵,精准解决不同维度的核心问题:常规基础数据回应“数据有什么”的基础供给问题,指令类数据明确“业务怎么做”的流程落地问题,模型优化成果则攻克“效果如何更优”的性能提升问题。一体化数据资产体系为金融大模型的稳定运行、精准输出及业务落地提供高可靠的数据与能力背书。
澜舟科技为实现数据资产的高质量转化,采用格式解析器、OCR、VLM等多模型协同机制,对多源异构金融数据进行全流程处理:通过结构化解析打破数据格式壁垒,经过多维度质量校验,剔除冗余、错误信息,再进行层次化切片实现数据精细化拆分,最终形成干净规范、逻辑完整的结构化文本表示,最大限度保留原始数据的业务逻辑与关联关系。
另外依托大语言模型构建语义理解与增强算子体系,除基础的摘要生成、问答(QA)对构建、关键标签抽取等功能外,进一步拓展至智能目录生成、知识图谱自动化构建、业务实体关联挖掘等深度处理场景。数据源的智能化处理深度,直接决定了数据资产的可复用性及业务适配能力,是金融大模型精准赋能业务的核心前提。
针对金融业务场景的实操特性,将实际业务中沉淀的优质Prompt、流程规范、操作步骤、风险控制要点等指令类资产,以经验库、技能库(Skills Library)的形式进行结构化存储与长期沉淀。通过场景化精准意图识别引擎,结合金融业务语义理解能力,将用户提出的模糊需求、自然语言诉求,转化为大模型可执行的标准化、精准化指令,实现高频金融场景的资产可靠复用,提升业务处理效率与一致性。对于高标准,严要求的个性化场景,通过机构内部高质量数据,使用强化学习技术来鼓励大模型的“遵循行为”,鼓励回答满足数值一致性、逻辑一致性、时效性、合规性等金融偏好。
过程可控:执行过程做到透明可监控
执行过程管控的核心目标的是打破传统大模型推理的“黑盒”壁垒,通过构建多层级协同控制机制与全流程幻觉检测体系,实现每一步推理过程的可验证、可干预。从数据召回、中间执行到幻觉检测全链路“背书”准确性与安全性,筑牢金融业务赋能的可信基础。
数据召回的本质是精准匹配场景需求与知识资产。通过FAQ匹配、Query Rewrite等技术,将用户Query转化为更精准的检索意图,再结合多路召回和粗排/精排,确保召回的是最相关的知识片段,从而避免因信息召回偏差导致的 “答非所问” 问题。
NL2Code/SQL/API控制是具体场景中工具调用的控制层,核心是保障代码生成的正确性和安全性。通过Schema Linking、KV分离、语法自动检测等技术,将自然语言转化为可执行的代码/API 调用。结合SOP、专业术语和计算逻辑的多层校验,避免生成存在逻辑错误或安全风险的代码。
过程及结果的幻觉检测和自我纠错是可信、可控的最后一道防线,本质是构建大模型的 “自我校验” 能力。通过数值检测、逻辑检测、知识链路检测等多维度校验,识别生成内容中的矛盾、错误和幻觉,实现错误的自动恢复,显著提升结果的可靠性。
结果可追溯:链式溯源确保背书可验证
金融数据不仅包含结构化的财务报表,还涵盖大量非结构化的法律文件、监管公告与新闻舆情,另外金融市场、产品工具及监管法规均处于高速动态变化中,而且金融决策,如信贷审批或投资分析,往往需要模型具备跨越多个段落、甚至多份独立文档进行信息整合、逻辑推理和一致性检验的能力。金融数据的极端复杂和快速迭代,以及跨源信息的综合研判,要求相关大模型应用具备精准溯源以及可解释性输出的能力。
精准溯源的核心在于搭建系统化的可解释性体系,确保每一项输出结论均能溯源至原始数据并形成完整推理链路,实现全流程有据可依、有迹可查。从最细粒度的数据到整个推理计算过程的链式溯源,打造执行结果从源头到输出的全维度可追溯、可解释框架,从底层夯实结果的高可信,为输出物提供权威背书。
通过构建覆盖细粒度文本语句、多模态像素单元、结构化表格数据及全流程推理计算的链式溯源机制,打通“原始数据-推理过程-最终结果”的全链路映射关系。除了精准定位数据源头的基础能力外,在一些关键场景中,可以提供完整、可验证的证据链支撑,有效破解大模型“黑箱输出”的难题,显著提升AI输出结果的可信度与合规性。
02
澜舟企业级可信智能体评测体系
面向企业级应用场景,澜舟可信智能体平台构建了一套以可信性、可控性与安全性为核心的智能体评测体系,围绕结构化数据问答、文档理解、图表推理、幻觉控制与拒识能力等关键能力,形成覆盖多数据源、多任务类型、多风险维度的系统化评测方法。
该体系以多源数据集为基础,通过统一的评测框架与自动化评测引擎,对智能体能力进行标准化评估;围绕L1–L4四层能力模型设计分层任务与评价指标,系统输出能力表现、可信程度与风险水平三类核心评估结果。
在此基础上,平台结合错误分析机制与持续评测飞轮,实现评测结果驱动模型与系统的迭代优化,最终构建形成一个具备可量化、可复现、可持续优化特征的企业级智能体能力闭环体系。
企业级智能体能力评测与可信评估体系架构
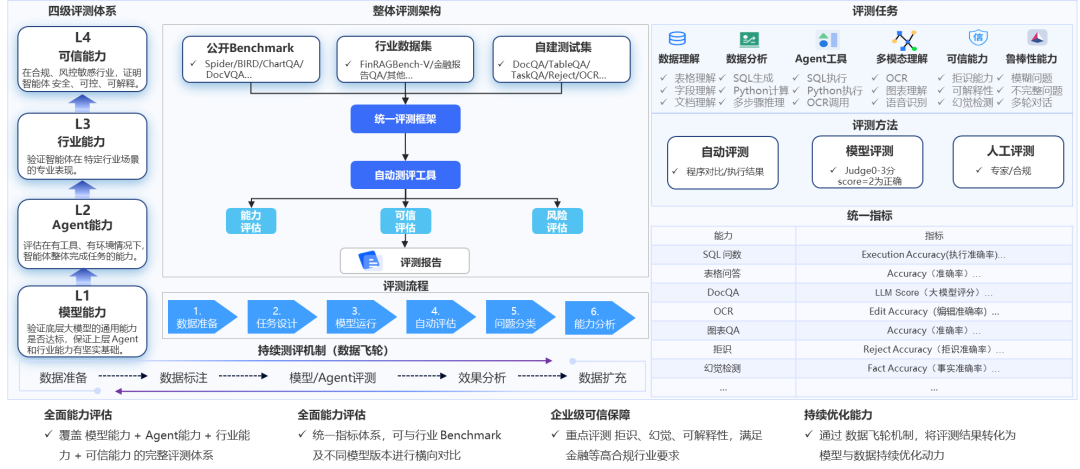
准备标准化数据:公开 Benchmark + 行业数据 + 自建测试集。
设计分层任务:映射到 L1–L4,各种问答、分析、Agent 工具、多模态、可信与鲁棒任务。
统一评测框架执行:通过自动评测引擎统一调度模型/Agent、工具、评测方法。
输出结果:能力评估 + 可信评估 + 风险评估,形成可对比的指标与报告。
错误分析体系:对错误进行结构化分类,定位薄弱点。
持续评测机制:以数据采集→标注→评测→分析→数据扩充为循环,驱动模型与数据持续优化。
可信智能体应用-澜舟智库核心指标测评结果
结构化数据NL2SQL/ NL2Python能力
结构化问答是企业级问数系统的核心能力,分别针对数据库(NL2SQL)、Excel 表格(NL2Python) 做深度优化,测评从复杂查询、跨域分析、表格计算等维度展开,验证平台在企业级结构化数据问答中的落地能力。
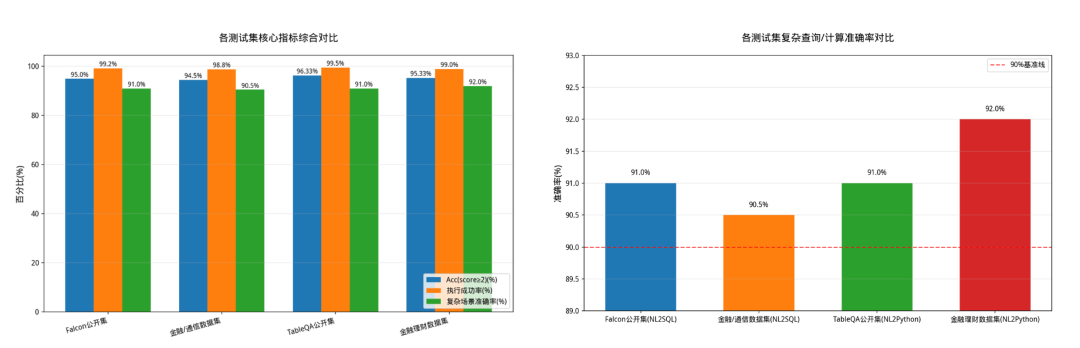
问答准确率:测试集的得分达标率(score≥2)均≥94.5%,其中 TableQA 公开集达 96.33%、金融理财数据集达 95.33%,远超行业通用基准;
执行稳定性:SQL / 代码执行成功率均≥98.8%,最高达 99.5%,验证了生成代码的语法正确性和可落地性;
复杂场景查询:测试集的复杂查询 / 计算准确率均≥90%(90.5%-92.0%),其中 Falcon 公开集与 TableQA 公开集均达 91.0%、金融理财数据集达 92.0%,突破复杂业务场景的落地瓶颈。
通用文档问答能力
通用文档问答聚焦企业级PDF/Word/Txt等非结构化文档的智能问答,通过自然语言直接理解和检索长文档、专业文档中的关键信息,实现精准问答与答案可溯源。在长文档理解、专业知识问答、多文档关联推理等场景的能力,适配企业知识库、规章制度、产品手册等真实业务场景。
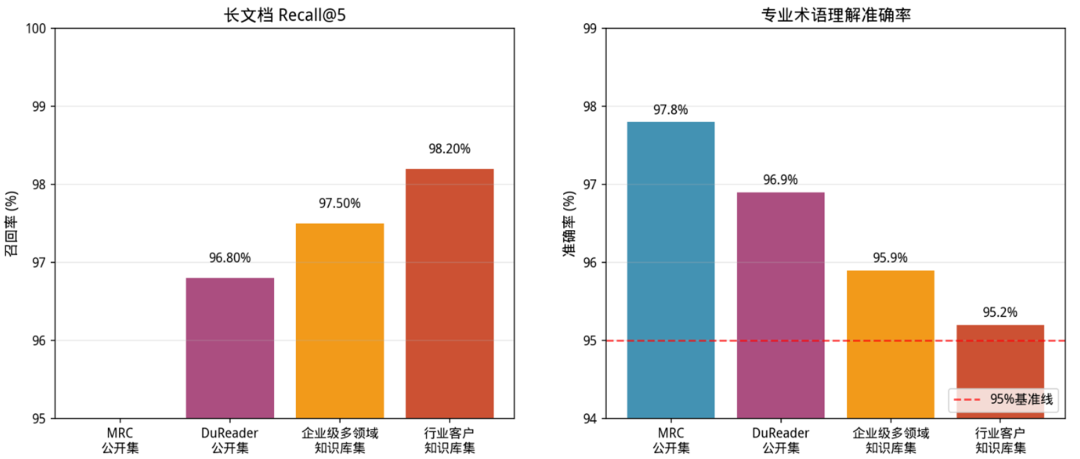
问答准确率: 测试集 2 分占比(准确率)均≥85.70%,其中行业客户知识库集达 92.70%,企业级多领域知识库集达 90.00%,显著高于公开数据集;平均得分稳定在 1.81-1.91 区间,行业客户知识库集以 1.91 分位列第一,体现了精准的问答结果输出能力。
长文档检索能力:含长文档标注的测试集 Recall@5 均≥96.80%,行业客户知识库集达 98.20%,企业级多领域知识库集达 97.50%,验证了平台对长篇幅、高信息密度文档的高效检索与关键信息定位能力。
专业术语理解:所有测试集专业术语理解准确率均≥95%(95.20%-97.80%),其中 MRC 公开集以 97.80%、DuReader 公开集以 96.90% 领先,企业级 / 行业数据集也均超 95% 基准线,充分证明平台对专业领域术语的精准理解能力。
非结构化文档表格能力理解
在企业文档场景中,大量关键数据以表格形式存在,但表格结构复杂且缺乏统一格式,例如无框表格、跨行跨列合并单元格、多层级表头以及财务报表等。针对上述挑战,构建了面向企业场景的表格理解能力,并从表格结构解析、数值计算推理、跨表信息关联分析等维度开展系统化测评,验证平台在非结构化文档表格数据理解与问答任务中的综合能力。
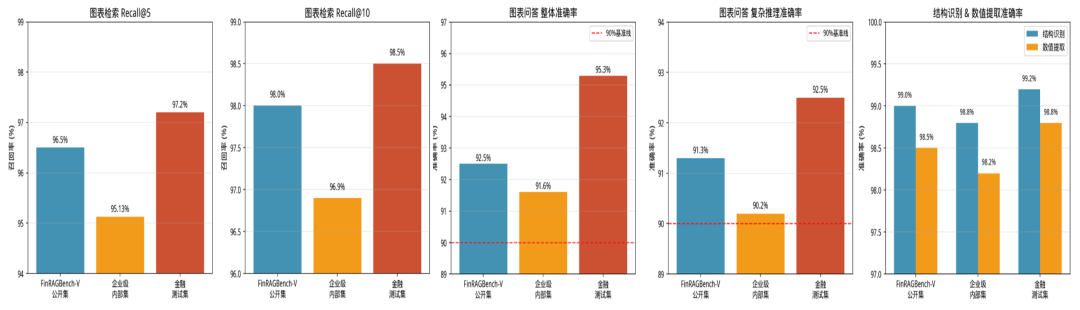
表格理解准确率:结构识别准确率(98.8%-99.2%)、数值提取准确率(98.2%-98.8%)均保持 98% 以上的超高水准,为复杂推理、跨表计算等高阶能力提供了坚实支撑;
垂直行业效果:金融测试集在检索召回率、问答准确率等所有维度均位列第一,验证了平台针对金融报表等专业场景的定制化优化效果,适配企业级实际业务需求。
幻觉控制能力
幻觉控制能力经权威公开基准与多场景业务测试验证,通用场景幻觉检测准确率达 91.8%、金融等企业级行业场景最高达 94.2%,核心风险项事实性幻觉召回率最高 97.5%,同步实现 98.2% 的无答案场景拒识准确率与 1.5% 以内的低误拒率,综合能力行业领先,全面适配企业级大模型落地的合规、安全、可控核心需求。
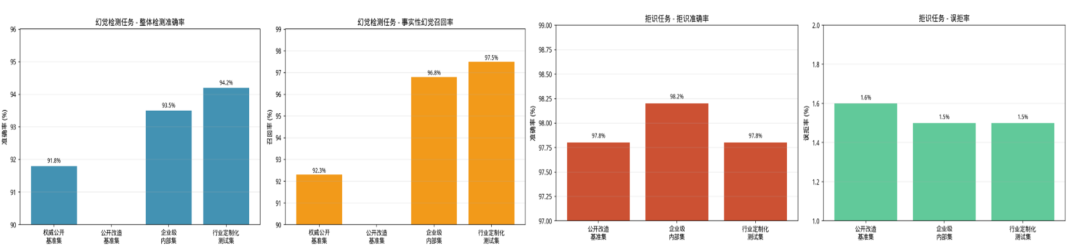
针对企业内部、金融等强监管行业的真实业务场景,幻觉检测准确率最高达 94.2%,核心风险最高的事实性幻觉召回率达 97.5%;拒识准确率稳定在 97.5% 以上,误拒率控制在 2% 以内,完美匹配企业级高合规、高可靠的落地要求。
03
落地案例
——澜舟在线客服可信智能体的实现路径
以企业在线客服场景为例。经过多年的系统建设与迭代,在线客服在客户服务触达、诉求快速响应等基础服务能力上形成一定积淀,有效支撑了日常客户咨询服务工作。
但在实际业务办理过程中,仍面临诸多痛点问题:语义理解精度不足、多轮对话连贯性欠缺,难以精准捕捉客户真实诉求;知识管理层面,政策条款、产品信息的更新存在滞后性,且不同渠道、不同场景下的信息口径不统一,易导致服务偏差;运营层面,人机协同机制不畅、多渠道客户数据割裂,无法形成服务合力,叠加金融行业严苛的合规监管要求,导致在线客服在中高复杂度场景中问题首解率偏低、服务体验不佳,难以满足客户精细化、专业化的服务需求。
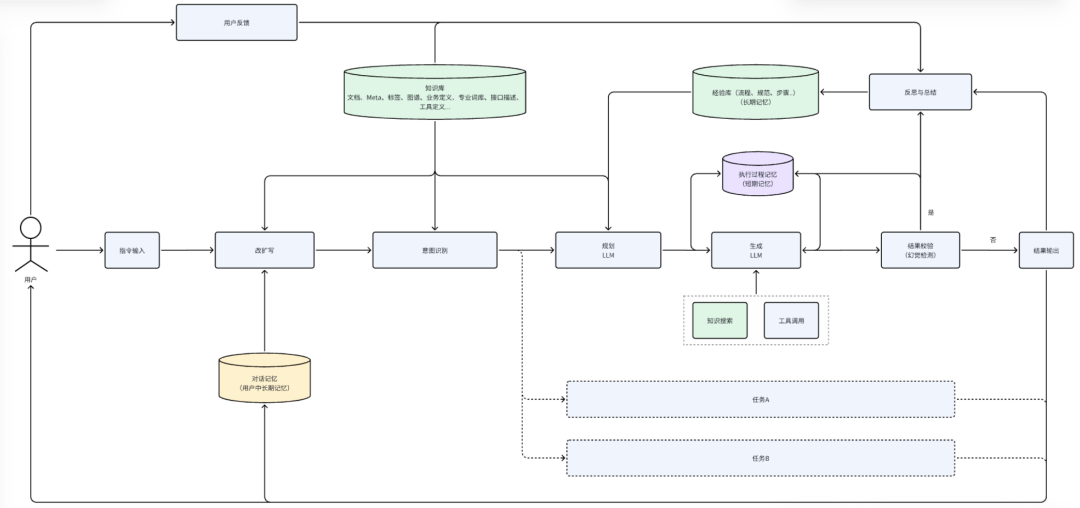
在企业在线客服的服务场景中,我们以大模型为核心引擎,协同各类任务智能体,聚焦三大关键环节精耕细作,搭建起全流程闭环管控体系,最终实现服务输出的可信、可控、可追溯。
精准洞察客户意图,破解服务痛点难题
我们深度挖掘客户历史会话数据的价值,结合内部业务规范、专业词库、业务词典等核心资源,对客户输入内容进行规范化改写与扩写。同时,将人工服务的宝贵经验沉淀至知识库,依托库内的业务分类样本,让客户意图与实际业务场景、标准问题库实现精准匹配,攻克客户咨询中的口语化表达、多意图交织、长尾非标诉求等服务痛点。
针对客户 “想办业务但没有表达清楚” 的场景,系统在意图识别阶段同步进行意图澄清判断与回复生成,通过智能追问,精准抓取交易金额、办理时间、产品类型、客户身份等金融业务核心信息,为后续大模型与任务智能体的规划决策、落地执行,提供精准有效的参数支撑。
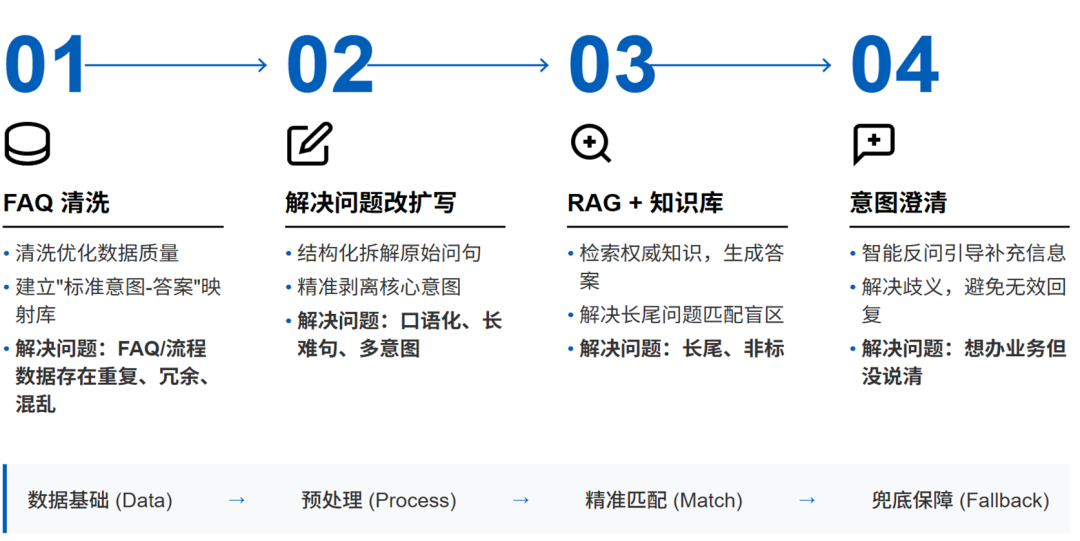
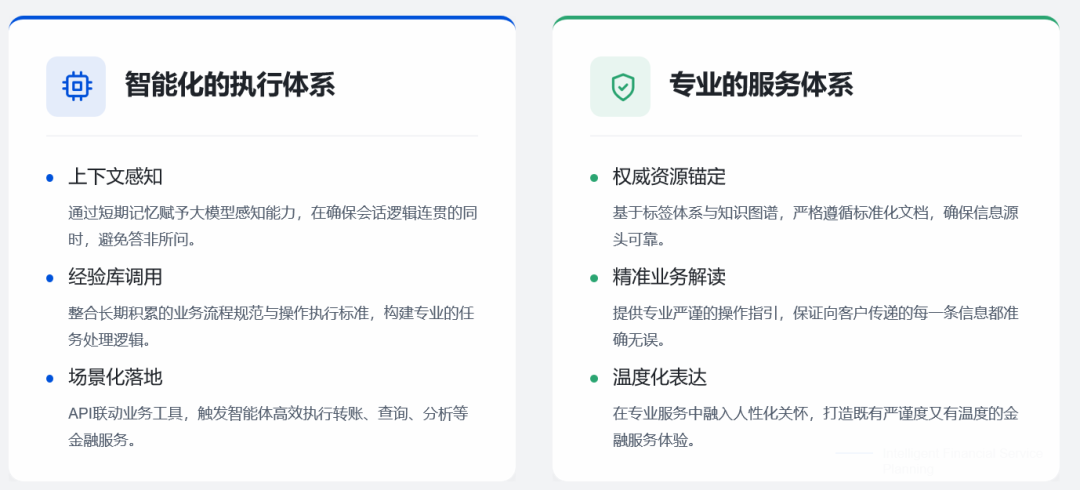
规范任务规划执行,兼顾专业与服务温度
一方面,借助单次会话的短期记忆,赋予大模型上下文感知与记忆能力,确保会话逻辑连贯流畅,避免答非所问;另一方面,整合长期积累的业务流程规范、操作执行标准、任务处理步骤等经验库资源,通过 API 接口调用,联动各类业务工具,或触发专属任务智能体,高效落地转账、账户查询、业务分析、产品推荐等具体金融场景服务。
在业务答复环节,系统严格锚定标签体系、标准化文档、知识图谱等权威资源,既保证向客户提供的业务解读、操作指引专业严谨、准确无误,又融入人性化表达,让服务更有温度。
强化幻觉检测反思,实现知识迭代升级
幻觉检测的核心在于双重校验:一是校验输出结果与客户核心诉求的相关性,确保回答直击需求;二是校验结果生成的数据溯源性、执行过程的合规性与依据充分性,守住服务可信底线。
同时,每一轮交互的幻觉检测结果都会实时更新至本次会话的短期记忆,形成闭环管控,让整个会话过程全程可追溯。
针对幻觉检测未通过、客户诉求未解决的情况,系统不仅会通过标准化兜底话术及时响应客户,还会在日常运营中,依托大模型对客户诉求与模型应答内容进行批量复盘、归类总结。
经人工审核确认后,这些内容将转化为标准化、流程化的知识,沉淀至长期经验库,实现知识的迭代更新与复用,持续驱动大模型与智能体的服务能力进阶。
实现大模型与任务智能体可信、可控运行的关键,在于构建长期、中期、短期三位一体的记忆体系,并将其有机整合至澜舟智库产品中,形成协同支撑:
一是长期记忆,以智能知识库(含标准化文档、业务定义、知识图谱、专业词库等)与业务经验库(含业务流程、执行规范、操作步骤等)为核心,为服务开展提供核心知识与经验支撑;
二是中长期记忆,以客户行为日志、用户标签画像、历史多轮会话全量数据等为核心,全面记忆客户全生命周期的会话轨迹与行为偏好,实现个性化服务适配;
三是短期记忆,聚焦单次会话场景,记录本轮会话的交互过程、核心诉求、检测结果等实时数据,确保模型回复与当前会话主题高度契合、逻辑连贯。
通过三大记忆体系的有机统一,为大模型与任务智能体的可信、可控运行提供全方位“背书”,持续提升企业在线客服的服务效率与服务质量。
目前澜舟携手中移在线,以大模型为核心构建的“智能大脑”全流程赋能智能机器人、话务坐席、后端运营等,知识库灵犀检索准确率较传统模式提升 2.8个百分点;首位命中率准确率提升显著,同比提升 5.2个百分点,大幅减少了模型幻觉风险。灵犀澄清能力显著降低了意图拒识率,实现了从“机器读懂文字”到“机器读懂人心”的跨越。
众邦银行基于澜舟智能知识库(智库)产品,推出“AI智能营销助手”,客户经理面向企业微信群中的在线用户,凭借对用户需求的洞察、对知识和复杂营销问题的解析,扩大了在线客户服务半径,助力推动运营效率平均提升近30%、响应速度提升20%、人力成本优化25%。
另外,某城商行客户基于澜舟智库的在线客服应用已经在生产环境正式上线,覆盖线索收集、退款、投诉等多个核心业务场景。系统支持7*24全时段响应客户需求,85%的用户问题在1分钟内解决,极大提升了客户服务体验。日均客户接待量大幅增长,整体服务规模提升150%;退款业务自动化处理率达到65%;线索收集、退款、投诉等业务意图识别准确率98%,初步建成“更懂客户、闭环服务、持续降本“的新一代智能客服能力体系,为后续智能化运营及业务持续增长打下良好基础。
总结
在生成式 AI 浪潮奔涌的今天,金融机构与大型企业在拥抱创新与坚守合规之间的平衡,正迎来新的破局点。澜舟科技提出的全链路可信智能体理念,从数据资产的高可靠治理、执行过程的强可控拆解,到最终结果的全可溯输出,构建了一套坚实的金融级可信底座。这不仅是技术上的精进,更是将 AI 智能体从 “黑箱输出” 转化为 “可靠、可控、可溯” 的数字员工的关键跨越,为行业在监管红线前实现 AI 价值突围提供了切实可行的路径。
依托这套体系,我们看到了实实在在的落地成果:在线客服系统实现了 85% 的问题在 1 分钟内解决,整体服务规模提升 150%,业务意图识别准确率高达 98%。这一系列数据印证了澜舟可信智能体不仅能应对技术挑战,更能在真实的业务战场上创造可观的效率与体验价值。
未来,随着澜舟企业级可信智能体评测体系的持续运转,以及大模型与任务智能体协同机制的不断优化,我们有理由相信,AI 技术将以更加透明、可信、可控的姿态,深度融入企业的核心业务流程,成为驱动业务增长与数字化转型的核心引擎,真正赋能行业,服务社会。
商务洽谈请联系


关于澜舟科技
ABOUT
北京澜舟科技有限公司(简称澜舟科技)成立于2021年6月,致力于成为领先的人工智能公司,以自然语言处理(NLP)技术为基础,为企业提供新一代人工智能服务,助力企业数字化转型升级。
澜舟科技专注垂直领域、专业赛道,深耕智能体,聚焦金融领域,引领大模型行业应用,其核心产品是基于大模型技术为企业提供智能体(Agent)及数字员工应用产品及服务。
往期文章推荐
”
澜舟科技官方网站
澜舟科技公众号

期待您的关注!
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢