
在过去几年里,大规模稠密语言模型的扩展推动了大语言模型 (LLMs) 的主要进展。从早期的模型,比如最初的
ULMFiT https://nlp.fast.ai/classification/2018/05/15/introducing-ulmfit.html
缩放定律 (Scaling laws) https://hf.co/papers/2001.08361
训练成本越来越高 推理延迟不断增加 部署需要大量内存和硬件资源
这正是专家混合模型 (MoE) 发挥作用的地方。
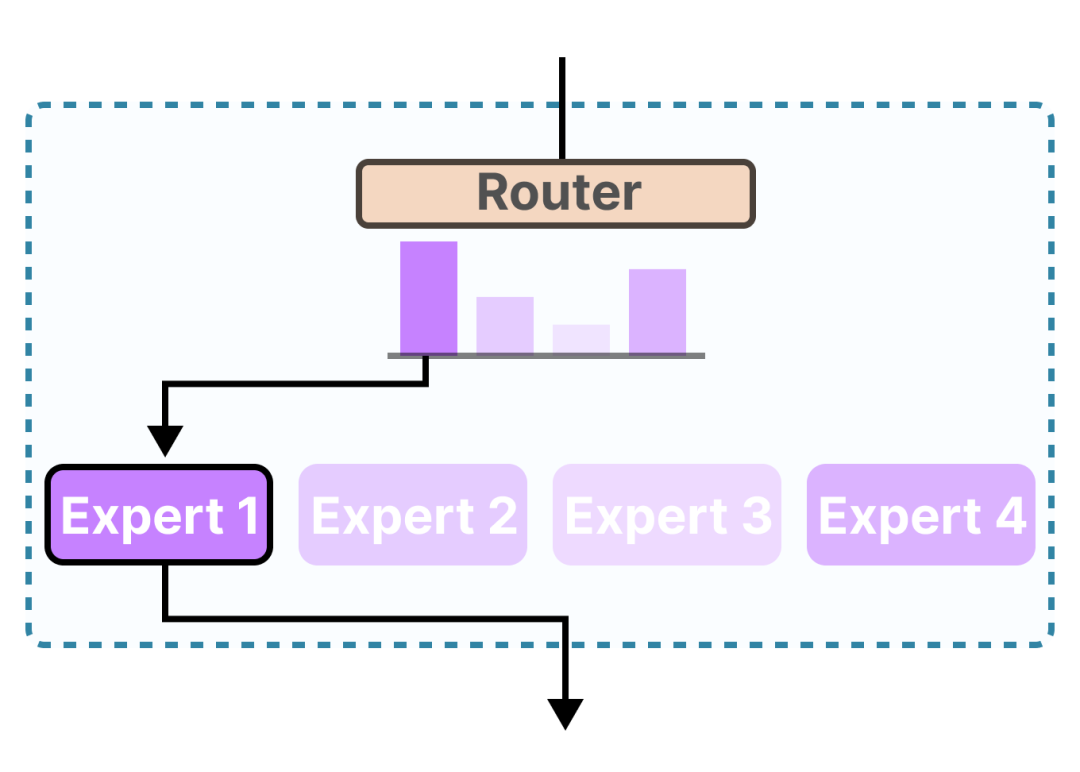
MoE 模型保留了 Transformer 的主体结构,但会将部分稠密的前馈层替换为一组 专家(experts) 。这里的“专家”并不是指某种特定领域 (比如“数学专家”或“代码专家”) ,而只是一个可学习的子网络。对于每个 token,会由一个 路由器(router) 选择少数几个专家来处理。
 |
|---|
MoE routing diagram https://hf.co/datasets/huggingface/documentation-images/resolve/main/blog/moe-transformers/moe_routing.png Maarten Grootendorst https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
不同的 token 会根据其隐藏表示激活不同的专家。
这是核心思想。
例如
gpt-oss-20b https://hf.co/openai/gpt-oss-20b
800 / (3.6 × 2) (bfloat16,每个参数 2 字节)
结果约为 111 tokens/s,而实际测得约为 115 tokens/s,与估算非常接近。
这说明模型在运行时的计算量类似一个 36 亿参数模型,但性能却接近 210 亿参数模型。
(注:如果使用该模型原生的 mxfp4 量化内核,速度还会更快。)
MoE 的优势主要体现在:
更高的计算效率
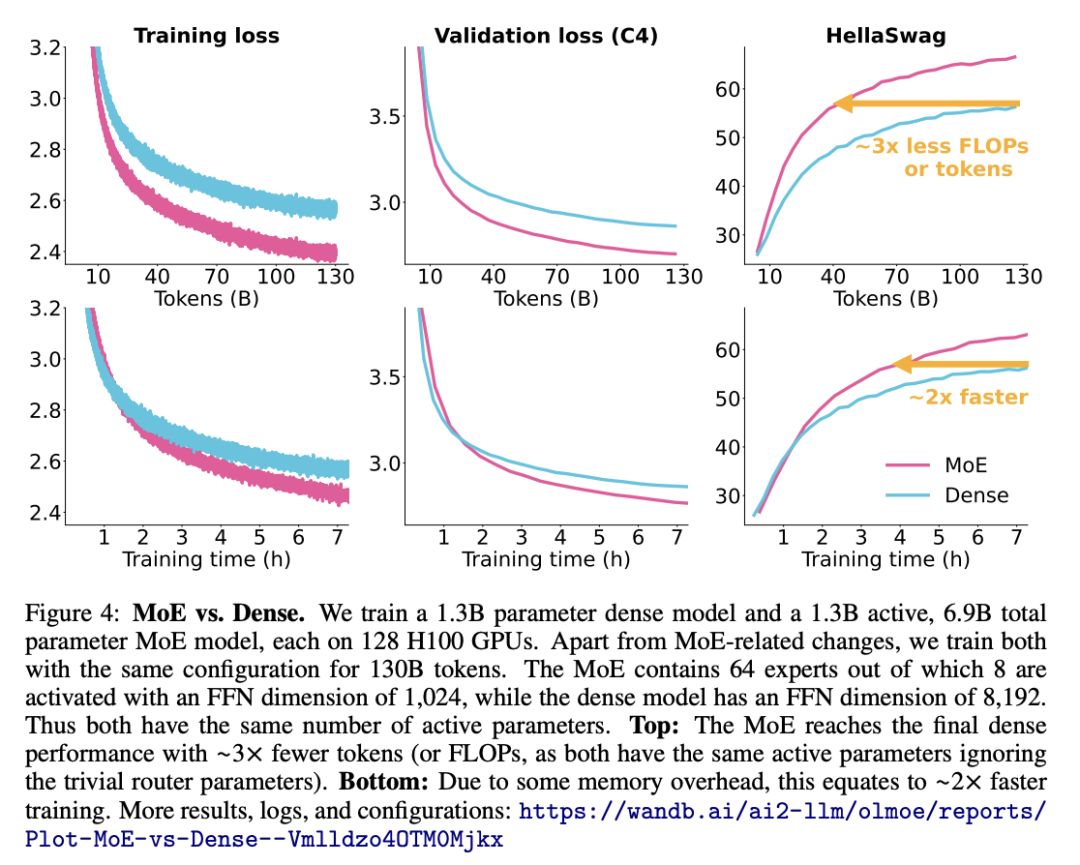
在相同的训练 FLOPs 预算下,MoE 通常优于稠密模型。
 |
|---|
MoE vs Dense training graphs https://hf.co/datasets/huggingface/documentation-images/resolve/main/blog/moe-transformers/faster_training.png OLMoE https://hf.co/papers/2409.02060
这意味着更快的迭代速度和更高的扩展效率。
天然适合并行计算
专家本身构成了计算图中的结构边界。由于不同 token 会使用不同专家,可以在专家维度上进行并行 (后文会介绍) 。
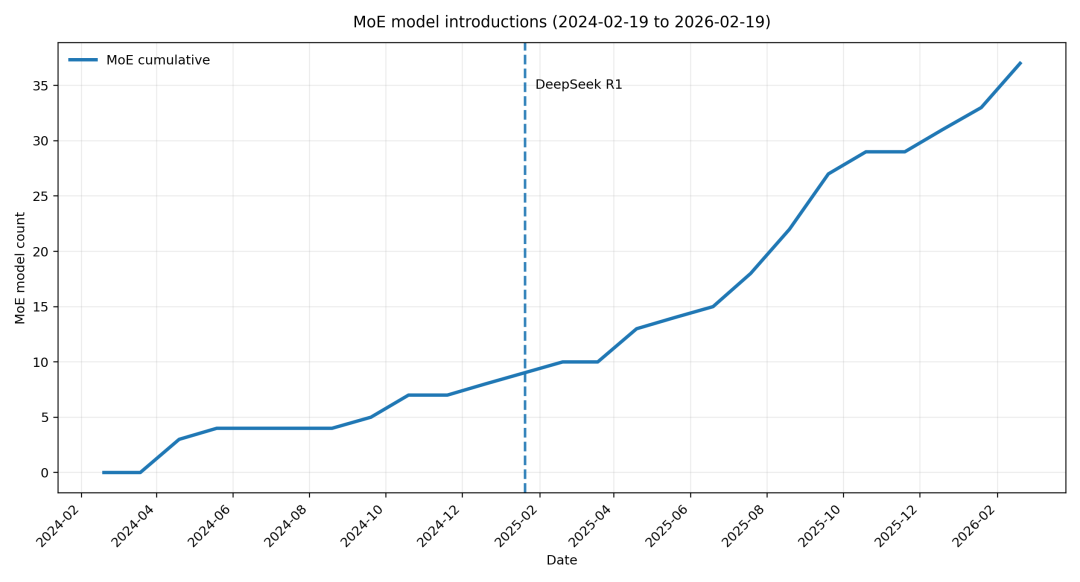
行业广泛采用
最近几周发布的 MoE 开源模型包括
Qwen 3.5 https://hf.co/collections/Qwen/qwen35 MiniMax M2 https://hf.co/collections/MiniMaxAI/minimax-m2 GLM-5 https://hf.co/collections/zai-org/glm-5 Kimi K2.5 https://hf.co/collections/moonshotai/kimi-k25
这一趋势在 2025 年 1 月
DeepSeek R1 https://hf.co/deepseek-ai/DeepSeek-R1 DeepSeek V2 https://hf.co/deepseek-ai/DeepSeek-V2 Mixtral-8x7B https://hf.co/mistralai/Mixtral-8x7B-v0.1
 |
|---|
timeline https://hf.co/datasets/huggingface/documentation-images/resolve/main/blog/moe-transformers/moe_2y_timeline.png
闭源模型同样在使用 MoE。ChatGPT 长期被
猜测 https://x.com/soumithchintala/status/1671267150101721090 gpt-oss https://hf.co/collections/openai/gpt-oss
这篇博客 https://hf.co/blog/moe 关于路由机制的 YouTube 视频。 https://youtu.be/CDnkFbW-uEQ
当前生态中的大多数工具 (如模型加载、设备分配、量化和执行后端) 最初都是为 稠密 模型设计的,而 MoE 对这些假设提出了挑战。
要让 MoE 在 transformers 中成为 一等公民(first-class citizens) ,意味着不仅仅是添加新的模型类,还需要对模型加载流程、执行机制以及分布式抽象进行重新设计。接下来我们将重点介绍 transformers 库是如何逐步演进,以支持稀疏架构的:
[权重加载重构] [专家执行后端] [专家并行] [使用 transformers 训练 MoE]
AutoModelForCausalLM.from_pretrained("model_id") https://hf.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForCausalLM.from_pretrained
但对于 MoE,情况会更复杂。在大多数 MoE 的 checkpoint 中,每个专家都是单独序列化保存的。如果你查看
DeepSeek-V3 的 checkpoint 索引 https://hf.co/deepseek-ai/DeepSeek-V3/raw/main/model.safetensors.index.json
model.layers.3.mlp.experts.0.gate_proj.weight
...
model.layers.3.mlp.experts.255.gate_proj.weight
每个专家都有自己的一组权重矩阵。本质上来说,以 DeepSeek-V3 为例,就是把 256 个 (编号从 0 到 255) 小型前馈网络并排保存下来。 但在运行时,GPU 执行的是优化过的内核。现代 MoE 内核,比如
grouped GEMM 和融合式 MoE 实现 https://hf.co/kernels-community/megablocks
为了高效做到这一点,就需要把所有专家的权重打包成一个连续张量 (contiguous tensor) 。
这就产生了不匹配:
Checkpoint: 256 个独立张量 运行时: 1 个打包后的张量
weight loading refactor https://github.com/huggingface/transformers/pull/41580
通过引入通用的
WeightConverter https://hf.co/docs/transformers/main/en/weightconverter
转变为:
这次重构引入的核心抽象,是通过
WeightConverter https://hf.co/docs/transformers/main/en/internal/weight_converter
WeightConverter 允许我们定义如下映射关系:
source key patterns → target key(s) + operations
基础操作 (如切分、拼接等) 可以灵活组合。其中,有两个操作在 MoE 场景中特别常用:
MergeModulelist https://github.com/huggingface/transformers/blob/main/src/transformers/core_model_loading.py :用于将一组张量合并为一个张量。例如,可以将MergeModulelist和Concatenate组合使用,把 MoE 中多个专家的权重堆叠起来,并打包成一个统一的张量。
WeightConverter(
["block_sparse_moe.experts.*.w1.weight", "block_sparse_moe.experts.*.w3.weight"],
"mlp.experts.gate_up_proj",
operations=[
MergeModulelist(dim=0),
Concatenate(dim=1),
],
)
SplitModulelist https://github.com/huggingface/transformers/blob/b71de73468429eb02da18caa50e9b5200400a4ed/src/transformers/core_model_loading.py#L208 :用于将一个张量拆分回一组张量。例如,可以把已经堆叠在一起的专家权重重新拆分成各个独立的专家。
WeightConverter(
"mlp.experts.down_proj",
"block_sparse_moe.experts.*.w2.weight",
operations=[SplitModulelist(dim=0)],
)
这次重构不仅改进了“可以做 哪些 转换”,还优化了“这些转换 如何 被调度执行”。
加载器会先扫描一次 checkpoint 的所有 key,并将其与转换规则进行匹配,然后按每个 converter 对张量进行分组。一旦某个 key 被确定需要使用,就会被注册为一个 “future”,并通过线程池进行实际加载。只有当所需依赖全部准备就绪后,对应的转换操作才会执行。例如,MergeModulelist 必须等某一层的所有专家权重都加载完成后,才会开始合并。
这样可以减少重复扫描和内存峰值。
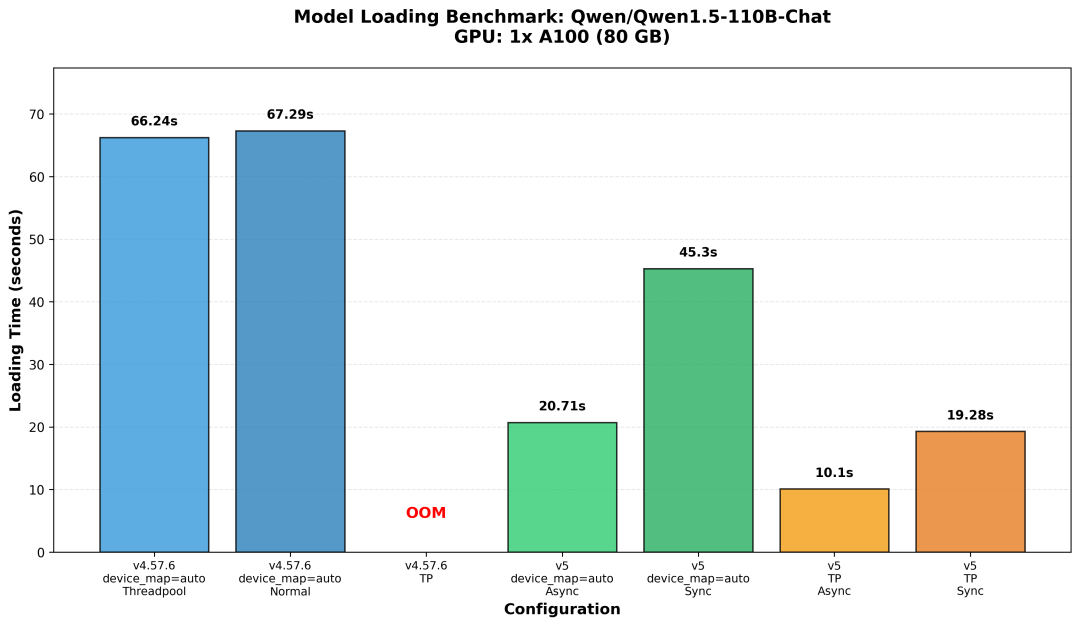
为了评估新的权重加载流程带来的提升,我们对 transformers 的 v4 和 v5 版本进行了基准测试。重点关注的是大型 MoE 模型的加载速度,因为这通常是训练和推理中的一个瓶颈。
测试所用代码分支如下:
v4 分支: https://github.com/ariG23498/transformers/tree/bench-v4 v5 分支: https://github.com/ariG23498/transformers/tree/bench-v5
https://github.com/ariG23498/transformers/tree/bench-v4 https://github.com/ariG23498/transformers/tree/bench-v4 https://github.com/ariG23498/transformers/tree/bench-v5 https://github.com/ariG23498/transformers/tree/bench-v5
示例代码:
from transformers import AutoModelForCausalLM
model_id = "Qwen/Qwen1.5-110B-Chat"
model = AutoModelForCausalLM.from_pretrained(model_id)
两个相关的环境变量:
HF_ENABLE_PARALLEL_LOADING:启用基于线程的分片并行加载HF_DEACTIVATE_ASYNC_LOAD:关闭新的异步加载流程 (v5 的回退选项)
模型:Qwen/Qwen1.5-110B-ChatGPU: 1× A100 (80GB)
 |
|---|
benchmark https://hf.co/datasets/huggingface/documentation-images/resolve/main/blog/moe-transformers/loading_benchmark.png
这种加速并不仅仅来自“增加线程数量”。
而是由 单次扫描路由(Single-pass routing) 、异步实例化(Async materialization) 和 感知转换的调度 (Conversion-aware scheduling) 共同作用的结果。这些机制一起避免了不必要的中间张量创建和内存峰值,同时还能在加载阶段完成专家打包和投影融合。
通过这次重构,我们现在可以先构建好运行时的模型结构,然后再将权重转换并填充到这个结构中。同时,也可以选择在这个转换流程中加入量化步骤,使量化成为权重加载流程的一部分。 这一点非常关键,因为只有当专家已经以统一且可预测的打包结构存在时,“按专家进行量化”才有实际意义。
这种端到端的处理流程在此前是无法实现的,而现在已经作为一个对用户开放的 API 提供出来。
当专家权重被打包后,接下来问题是:
在专家混合 (MoE) 模型中,每个 token 会被路由到不同的专家。这意味着在运行时需要完成一系列操作:将 token 分发到对应的专家权重、以高效方式执行投影计算、应用路由权重,然后再对结果进行汇总和重排。
这些问题正是
Experts Backend system https://hf.co/docs/transformers/experts_interface PR #42697 https://github.com/huggingface/transformers/pull/42697
这一机制是通过装饰器模式实现的:
@use_experts_implementation
该装饰器会对专家类进行封装,并自动将计算分发到所选择的后端执行。
目前提供了三种后端实现:
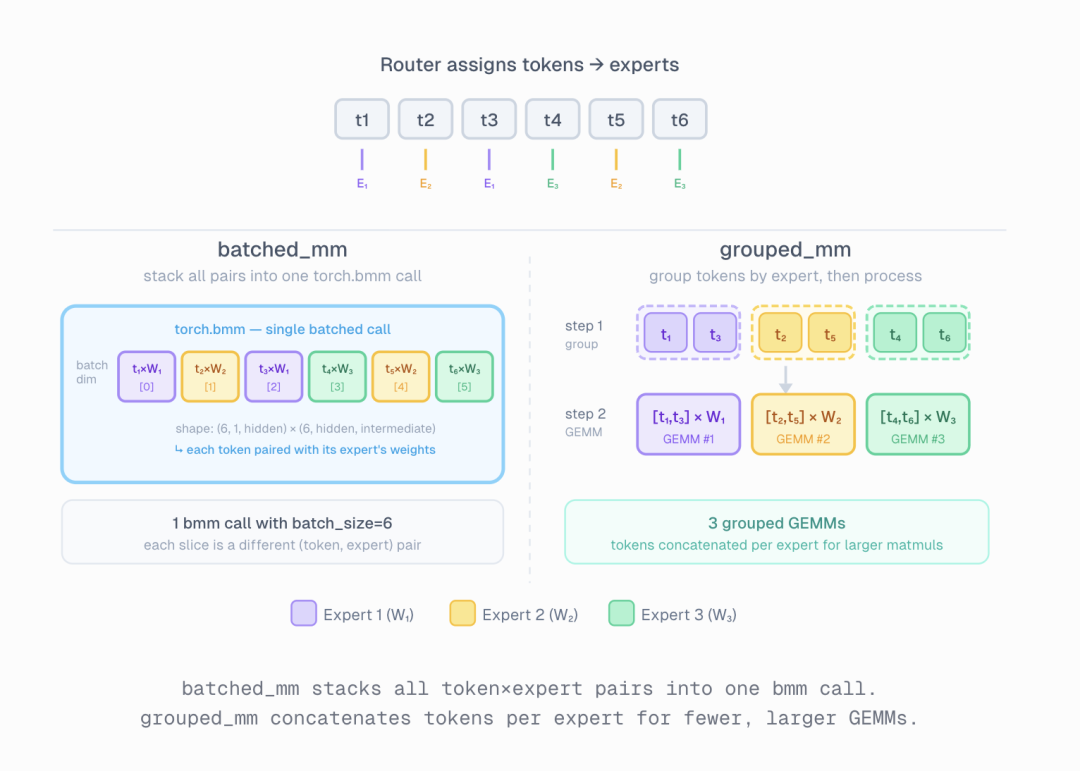
eager逐个遍历被选中的专家,并分别执行投影计算。主要用于结果验证和调试。batched_mm基于torch.bmm 实现。它会为每个 token 复制对应专家的权重,然后通过一次批量矩阵乘法 (batched GEMM) 完成计算。适用于 batch 较小、GPU 计算能力强且显存充足的场景。
torch.bmm https://docs.pytorch.org/docs/stable/generated/torch.bmm.html
grouped_mm基于torch._grouped_mm 实现。它会先按照专家 ID 对 token 进行排序和分组,然后通过一次 grouped GEMM 完成计算。这种方式在大 batch 或显存受限的情况下表现更好。
torch._grouped_mm https://docs.pytorch.org/docs/stable/generated/torch.nn.functional.grouped_mm.html
 |
专家混合 (MoE) 模型的参数规模可以达到数千亿级别 (远远超出单张 GPU 的承载能力) 。专家并行 (Expert Parallelism,EP) 通过将专家分布到多个设备上来解决这一问题。每个设备只加载分配给自己的那部分专家,负责对应的计算,并在最后参与结果的汇总。
由于每个 token 实际只会激活少数几个专家,这种方式可以在不增加计算成本的前提下,将模型扩展到更大的参数规模。
专家并行可以通过 enable_expert_parallel 来启用:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.distributed.configuration_utils import DistributedConfig
distributed_config = DistributedConfig(enable_expert_parallel=True)
model = AutoModelForCausalLM.from_pretrained(
"openai/gpt-oss-120b",
dtype="auto",
distributed_config=distributed_config,
)
启动:
torchrun --nproc-per-node N script.py
其中 N 应能整除专家数量,通常也对应 GPU 数量。
当 enable_expert_parallel=True 时,模型会从标准的张量并行 (Tensor Parallel, TP) 策略切换为专家并行 (Expert Parallel, EP) 策略,并采用专门的切分 (sharding) 方式。
EP 的核心组件包括:
GroupedGemmParallel https://github.com/huggingface/transformers/blob/b71de73468429eb02da18caa50e9b5200400a4ed/src/transformers/integrations/tensor_parallel.py#L934 沿着专家维度 (dim=0) 对权重进行切分,使每个设备只加载num_experts / num_devices的专家权重。RouterParallel https://github.com/huggingface/transformers/blob/b71de73468429eb02da18caa50e9b5200400a4ed/src/transformers/integrations/tensor_parallel.py#L977 将全局专家索引映射为本地索引,屏蔽不属于当前设备的专家,确保每个设备只使用本地专家进行计算,并通过 all-reduce 在设备之间汇总部分计算结果。
MoE 在推理扩展方面表现出色,但在训练阶段要复杂得多。
主要挑战包括:参数规模极其庞大、专家之间的分布式通信复杂,以及需要处理路由过程中的不稳定性。为了解决这些问题,我们与 Unsloth 合作,实现了更高效的 MoE 训练方案:
训练速度提升约 12 倍 显存占用降低超过 35% 支持约 6 倍更长的上下文 相比 v4,总体加速达到 12–30 倍
在实现上,我们利用了 Expert Backend 抽象,统一采用 PyTorch 的 torch._grouped_mm API,并结合自定义的 Triton grouped-GEMM 和 LoRA 内核。Unsloth 在 Transformers (以及 TRL) 的优化基础上进一步提升了整体性能。
Unsloth 官方指南 https://unsloth.ai/docs/new/faster-moe
随着稀疏架构的不断发展,我们也希望 transformers 库能够持续演进,与之保持同步。如果你正在使用 MoE,或尝试新的稀疏模型思路,我们非常欢迎你的反馈。欢迎告诉我们你希望在 transformers 中看到哪些新的抽象、算子 (kernel) 或工作流程。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢