
DRUGONE
蛋白语言模型在变异效应预测中展现出巨大潜力,但当前高性能方法通常需要结合结构、同源序列或群体遗传信息,导致模型复杂度增加且适用性受限。研究人员提出一种高效的协同蒸馏策略,使仅基于序列的蛋白语言模型能够在不依赖额外信息的情况下达到高精度预测。该方法通过在同一模型家族内部共享最具置信度的预测信号,使多个模型相互学习,从而提升整体性能。结果表明,对ESM模型进行协同蒸馏即可在多个基准测试中达到甚至超过当前最先进方法的表现。此外,该方法还能够精确量化变异对连续临床表型的影响,为大规模人群数据分析提供了新的工具。

预测遗传变异的功能后果是生物医学中的核心问题,广泛应用于人类遗传学、药物开发和蛋白工程。近年来,蛋白语言模型通过在大规模序列数据上的预训练,能够捕获蛋白序列中的进化规律,在变异效应预测等任务中取得显著进展。
为了进一步提升性能,现有方法通常采用混合策略,将蛋白语言模型与多序列比对、结构信息或群体遗传数据结合使用。这类方法虽然有效,但引入了更高的计算复杂度,并且在缺乏额外数据时难以应用,同时也可能带来偏差和泛化问题。相比之下,仅依赖序列的模型具有更强的通用性,但其性能长期被认为低于多模态方法。
研究人员指出,不同ESM模型虽然结构相似,但在识别进化信号方面存在互补性,这意味着通过整合这些模型的优势,有可能在不引入额外信息的情况下显著提升预测能力。
方法
研究人员首先提出“最大置信度”策略,即在多个模型中选择对每个突变最有信心的预测结果,从而增强进化信号。随后进一步发展为协同蒸馏框架,在该框架中,不同模型根据其预测置信度轮流充当教师与学生,通过共享最可靠的预测信号进行训练更新。最终,通过多轮蒸馏与模型压缩,将多个模型的集体知识整合进单一蛋白语言模型中。
结果
多模型协同增强进化信号识别能力
研究人员发现,不同ESM模型在识别蛋白功能区域方面具有明显互补性。例如,一些模型能够识别特定结构域,而另一些模型则对这些区域缺乏敏感性。通过在多个模型之间选择最有置信度的预测,可以显著增强对进化保守区域的识别能力,从而提升变异效应预测性能。
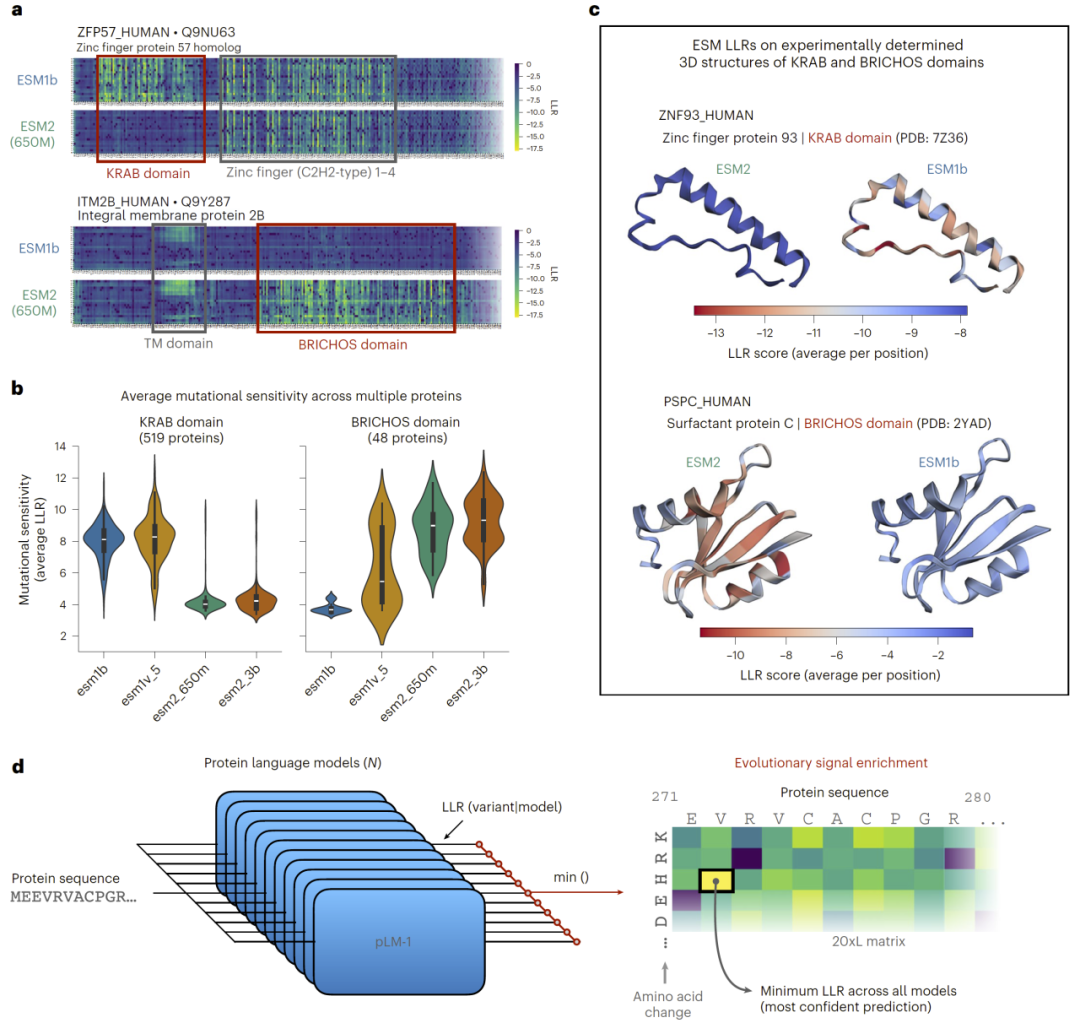
图1: 通过跨多个蛋白语言模型搜索增强进化信号。
协同蒸馏显著提升模型性能
在协同蒸馏框架下,所有ESM模型均表现出显著性能提升,尤其是参数较小的模型获得了意想不到的大幅改进。在多个基准测试中,蒸馏后的模型不仅优于原始模型,还在部分情况下超过了多模型集成方法,表现出类似“学生超越教师”的现象。
此外,消融实验表明,该方法在极少量训练数据下仍能保持高性能,说明其具有良好的数据效率与泛化能力。
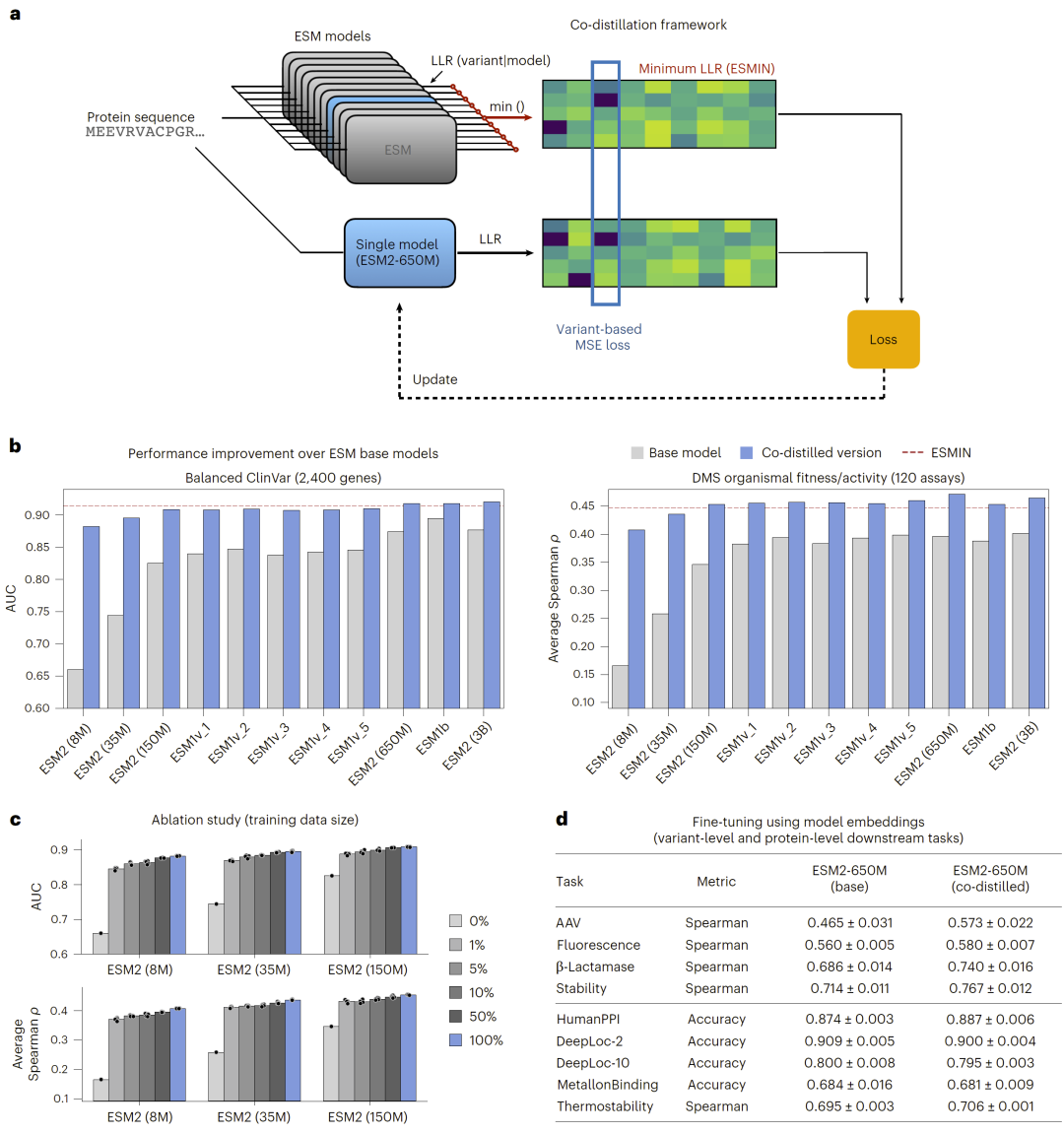
图2: 最大置信度协同蒸馏显著提升ESM家族中各模型的性能。
多轮蒸馏实现单模型性能收敛
尽管初始蒸馏已经显著提升性能,但研究人员发现进一步迭代蒸馏仍可带来额外收益。通过多轮协同蒸馏,并结合模型集成策略,最终得到一个单一模型,其性能可以匹配甚至超过整个模型集群。
该模型不仅显著降低了参数规模,还保留了集体知识的优势,实现了性能与效率的统一。
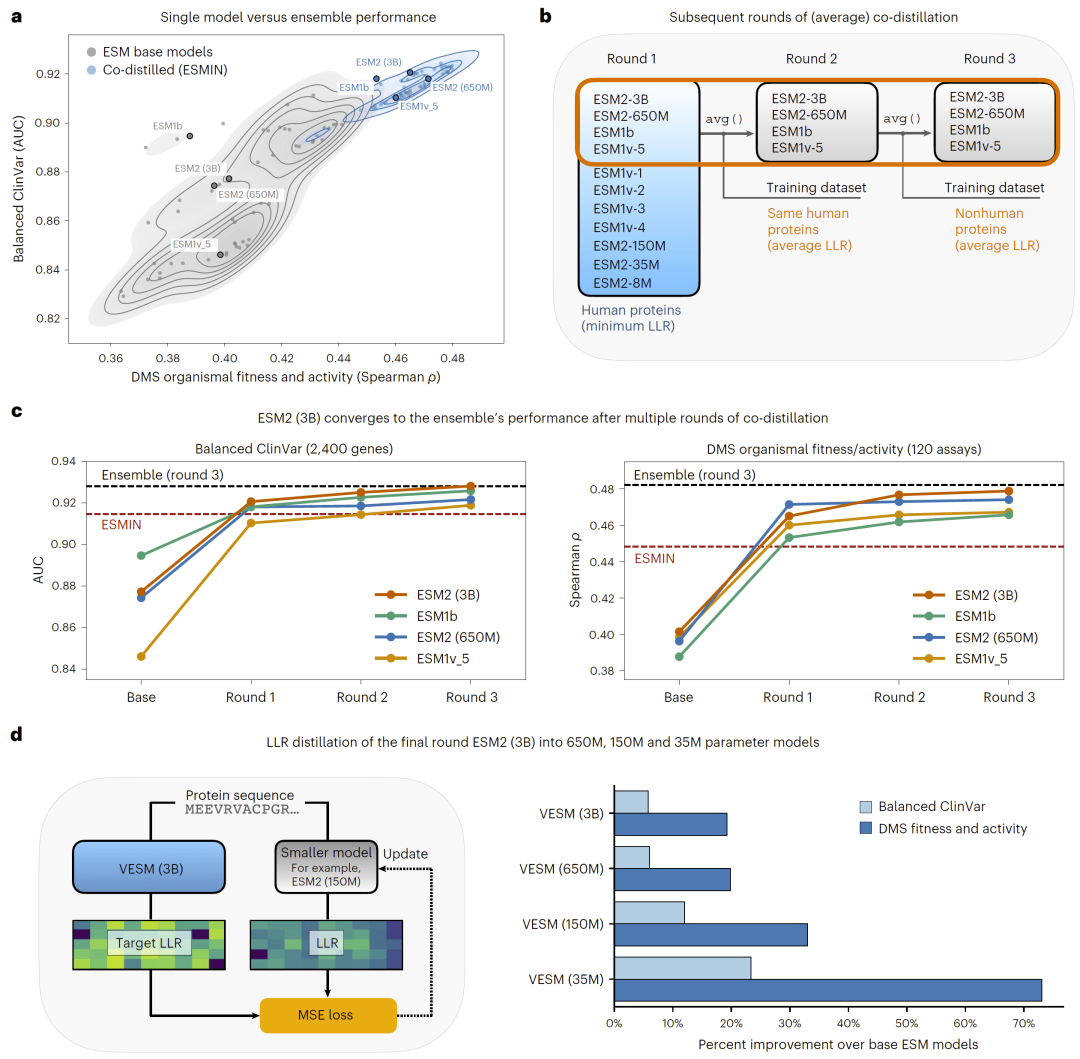
图3: 迭代平均协同蒸馏将ESM模型家族有效压缩为单一蛋白语言模型。
小模型的高效蒸馏与扩展能力
研究人员进一步将高性能模型蒸馏到更小规模的模型中,发现这些轻量模型在保持极少参数的情况下,仍能接近大模型性能。这种能力使得模型可以在不同计算资源条件下灵活部署。
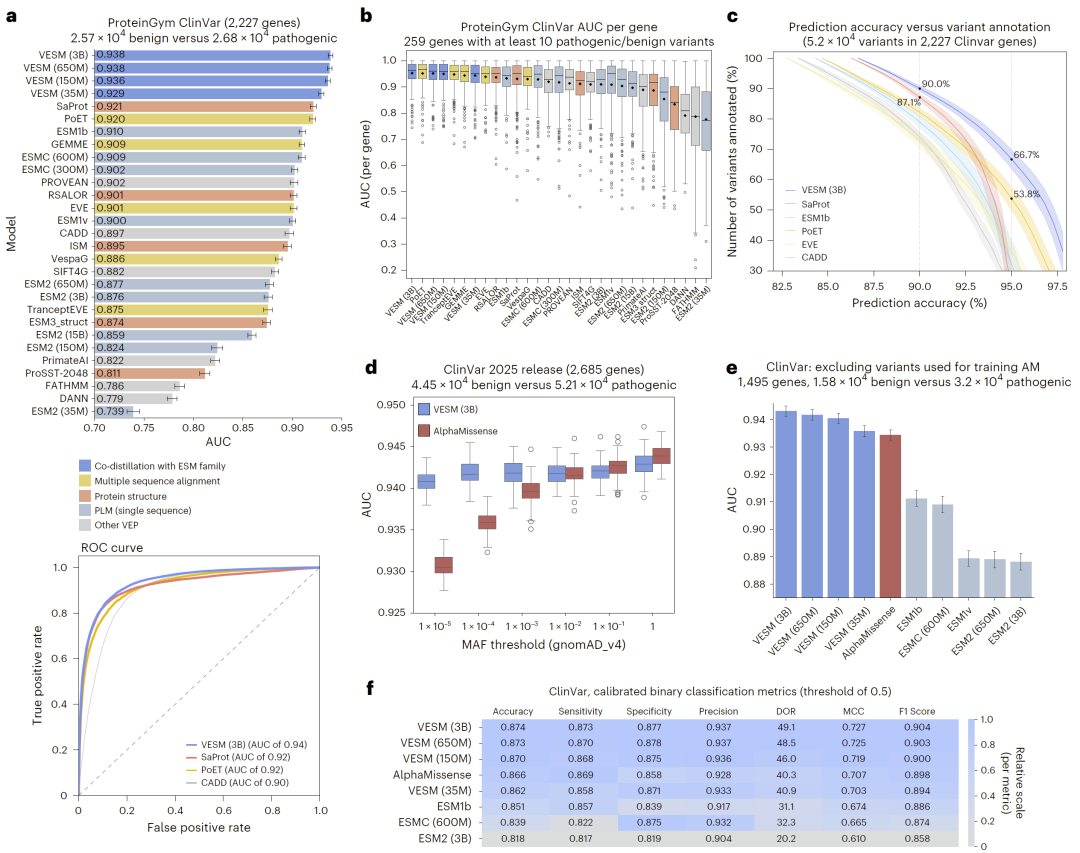
图4: 仅基于序列的VESM模型在临床变异效应预测中的性能评估。
在临床与实验数据中的表现
在临床变异数据与高通量突变实验数据中,协同蒸馏模型均表现出优于现有方法的预测能力。特别是在不依赖结构或进化对齐信息的情况下,模型依然能够达到甚至超过最先进方法的水平。
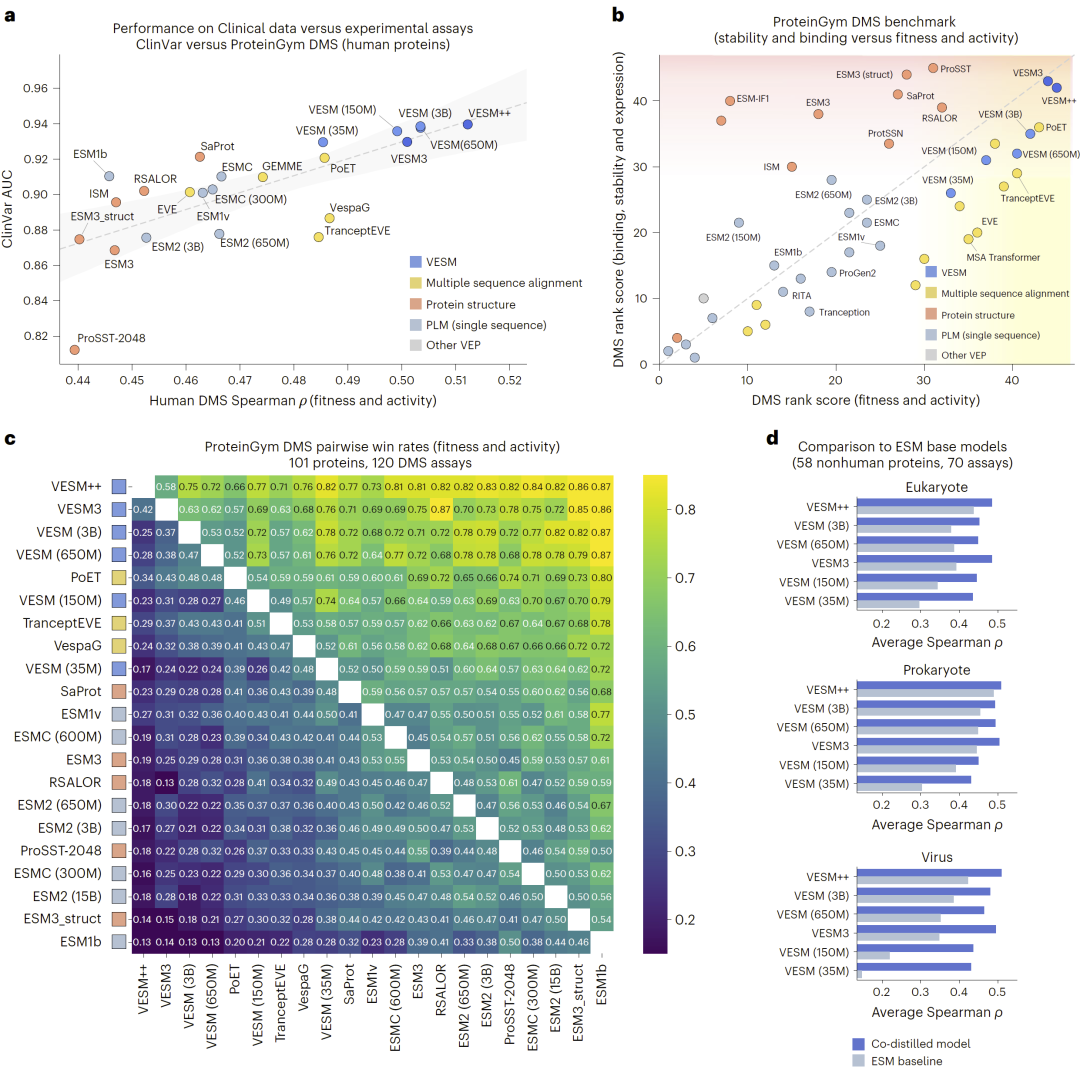
图5: VESM在临床与DMS基准测试中实现最先进的变异效应预测性能。
从分类到连续表型预测的扩展
除了传统的致病性分类任务,该模型还能够准确预测变异对连续表型的影响,如生物化学活性或临床指标。这表明其不仅适用于分类问题,还具备更广泛的定量预测能力。
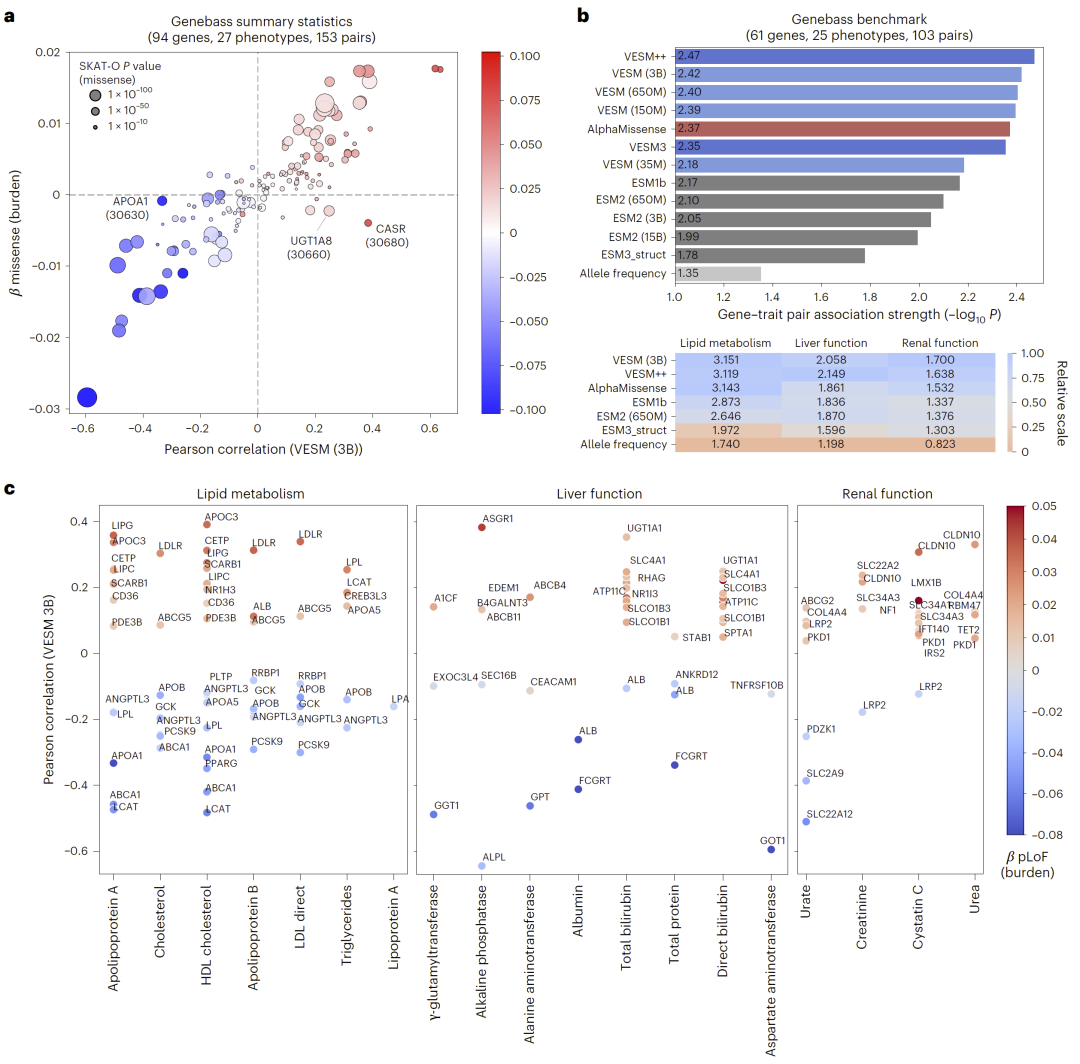
图6: VESM模型可准确量化UK Biobank中错义突变对连续临床表型的影响。
讨论
研究人员提出的协同蒸馏方法证明,仅基于序列的蛋白语言模型并不存在性能上的根本限制。通过有效整合模型家族中的进化信息,可以在无需额外数据的情况下实现高精度预测。
该方法的核心优势在于:既避免了多模型集成带来的计算开销,又保留了模型间互补信息带来的性能提升。同时,多轮蒸馏机制使模型逐步收敛到单一高性能表示,实现了知识压缩与性能提升的统一。
未来研究方向包括进一步提升模型对复杂进化信号的捕获能力,以及探索其在蛋白设计、疾病机制解析等更多任务中的应用潜力。总体而言,该工作为蛋白语言模型的发展提供了一种重要范式,即通过知识蒸馏实现“从模型集合到单一模型”的跃迁。
整理 | DrugOne团队
参考资料
Dinh, T., Jang, SK., Zaitlen, N. et al. Compressing the collective knowledge of ESM into a single protein language model. Nat Methods (2026).
https://doi.org/10.1038/s41592-026-03050-9

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢