报告主题:“科研品味”不再是人类专利?新思路让 AI 学到科研品味
报告日期:04月02日(周四) 15:00-16:00
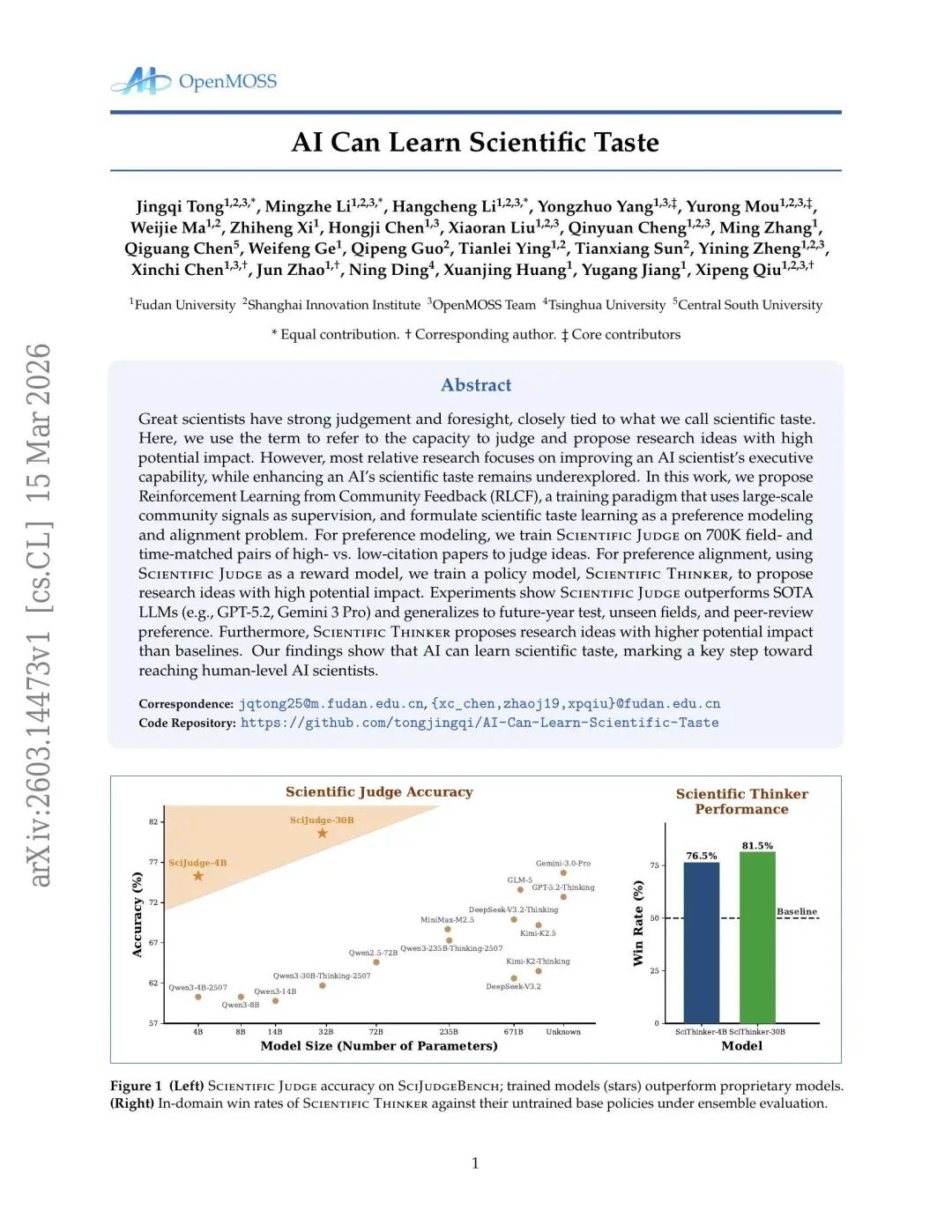
2026年4月2日,智源社区邀请复旦大学仝竞奇围绕《“科研品味”不再是人类专利?新思路让 AI 学到科研品味》主题开展智源TALK活动。活动现场分享“AI Can Learn Scientific Taste”学术论文。伟大的科学家往往具备敏锐的判断力与远见卓识,而这正与我们所称的“科学品位”(scientific taste)密切相关。本文中,“科学品位”特指判断并提出具有高潜在影响力研究构想的能力。然而,当前绝大多数相关研究集中于提升人工智能科学家的执行能力,而如何增强人工智能的科学品位,却仍属尚未充分探索的领域。 在本研究中,我们提出了“基于社群反馈的强化学习”(Reinforcement Learning from Community Feedback, RLCF)这一新型训练范式:该范式利用大规模社群信号作为监督信号,并将科学品位的学习建模为一个偏好建模与对齐问题。在偏好建模方面,我们基于70万对按学科领域与发表时间严格匹配的高被引论文与低被引论文样本,训练了“科学评判模型”(Scientific Judge),使其能够有效评估研究构想的潜在价值;在偏好对齐方面,我们以“科学评判模型”作为奖励模型,进一步训练“科学思维模型”(Scientific Thinker),使其能够主动提出具有高潜在影响力的研究构想。实验结果表明:“科学评判模型”在各项指标上均显著优于当前最优的大语言模型(如GPT-5.2、Gemini 3 Pro),且展现出优异的泛化能力——不仅适用于未来年份的测试集、未见过的新学科领域,还能准确拟合同行评议中的专家偏好;此外,“科学思维模型”所生成的研究构想,其潜在影响力亦明显高于各类基线方法。我们的研究发现证实:人工智能确实可以习得科学品位,这标志着通向具备人类水平科研能力的人工智能科学家迈出了关键一步。
报告嘉宾:
仝竞奇目前是复旦大学自然语言处理实验室博士,师从邱锡鹏和黄萱菁教授,研究多模态,Agent,RL。代表性工作:AI Can Learn Scientific Taste, Thinking with Video, Game-RL。
内容中包含的图片若涉及版权问题,请及时与我们联系删除








评论
沙发等你来抢