

代码仓库: https://github.com/AI4Science-WestlakeU/scDFM
文章链接: https://arxiv.org/abs/2602.07103
OpenReview: https://openreview.net/forum?id=QSGanMEcUV
如果我们敲掉一个基因,或者给细胞加一种药,细胞群体会变成什么样?这听起来像一个很自然的问题,但在单细胞尺度上,它其实比想象中难得多。实验中我们看不到“同一个细胞在扰动前后”的对应关系,看到的只是两个细胞群体的分布。
在系统生物学和药物设计领域,一个核心问题是预测细胞对扰动的转录响应。无论是基因敲除、药物处理还是环境刺激,研究者都希望能够提前预知细胞群体将如何响应。这对于理解疾病机制、筛选潜在药物靶点具有至关重要的意义。
但单细胞扰动预测一直是个棘手的问题。单细胞测量本身就带有噪声且数据稀疏,而扰动往往引起的是群体层面的分布偏移,而非单个细胞的确定性变化。更复杂的是,由于测序技术的毁坏性,我们无法追踪同一个细胞在扰动前后的基因表达。此外,单细胞数据的噪声和稀疏性问题也始终困扰着这个领域。测序深度不足、dropout 事件、批次效应等因素都会影响预测的鲁棒性。而在组合扰动场景下,多个扰动因子的相互作用更增加了预测的复杂度。
基于这些挑战,西湖大学吴泰霖实验室提出了scDFM(Distributional Flow Matching Model),一个基于分布级生成式建模的鲁棒单细胞扰动预测框架。
核心思路:从"细胞对应"到"分布生成"
现有的深度学习方法大多隐含着一个假设:控制组中的某个细胞与扰动组中的某个细胞存在一一对应的关系。scDFM 的关键突破在于,它不再试图建立控制细胞与扰动细胞之间的一一映射,而是将问题重新表述为条件分布生成的问题:给定控制细胞群体的分布,生成扰动后细胞群体的完整分布。
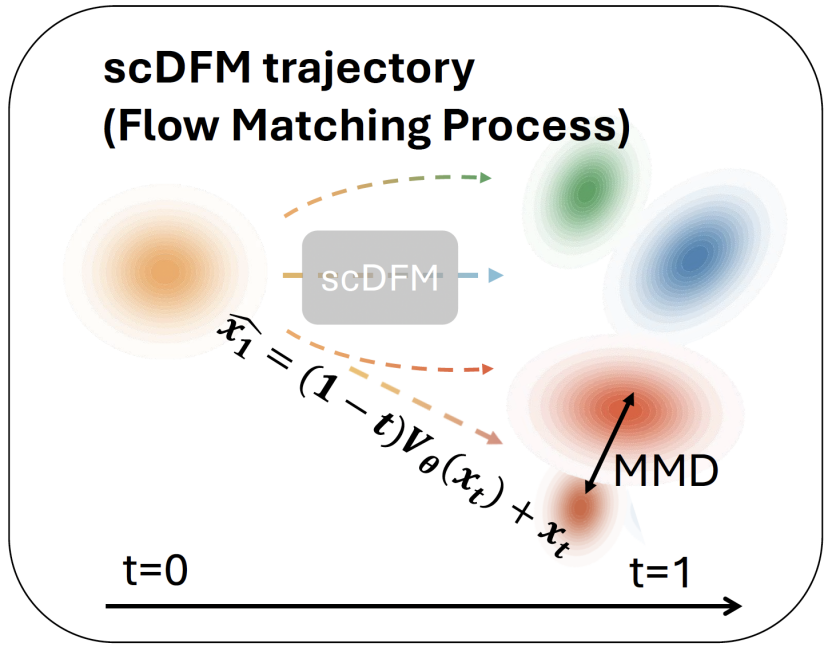
具体来说,scDFM 基于 Conditional Flow Matching(条件流匹配) 框架建模这一过程。其核心思想是学习一个连续的速度场,使得样本可以从初始分布逐渐演化到目标分布。在我们的任务中,初始分布对应控制细胞群体,而目标分布则是扰动后的细胞群体。模型通过学习这一速度场,刻画扰动前后细胞状态分布之间的连续变化轨迹。
为了在没有细胞级配对标签的情况下有效对齐控制群体和扰动群体,scDFM 在 Flow Matching 的训练框架之外引入Maximum Mean Discrepancy(MMD)作为额外约束。具体来说,在训练过程中,模型不仅学习沿着控制状态与扰动状态之间的插值路径的速度场,同时还会根据当前状态直接预测最终的扰动表达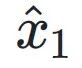 。随后,我们利用MMD loss 在分布层面比较 与真实扰动细胞
。随后,我们利用MMD loss 在分布层面比较 与真实扰动细胞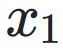 的差异,使生成样本的整体统计特征尽可能接近真实数据。
的差异,使生成样本的整体统计特征尽可能接近真实数据。
这样一来,模型既能够通过Flow Matching 学习控制细胞到扰动细胞之间的连续演化轨迹,又可以通过MMD从分布层面对生成结果进行约束。即使在没有显式细胞配对的情况下,模型仍然能够逐渐学习到扰动后的表达分布结构。


PAD-Transformer:扰动感知的差分注意力架构
除了生成框架本身,scDFM 还对模型骨干网络进行了专门设计。单细胞表达数据通常具有高噪声、高稀疏的特点,如果直接使用标准 Transformer,很容易被大量无关信号干扰。因此,我们提出了PAD-Transformer(Perturbation-Aware Differential Transformer)作为模型的核心编码结构。
PAD-Transformer 的设计主要围绕两个想法展开:一是引入基因之间的结构先验,二是让模型更关注扰动带来的表达变化。首先,我们在模型中加入了 基因相互作用图(Gene Interaction Graph)。这个图并不是人工指定的通路网络,而是直接从数据中统计得到的共表达关系。具体来说,我们先计算每两个基因在所有细胞中的表达相关性,然后为每个基因保留最相关的一部分邻居,从而构建一个稀疏的基因共表达图。在模型中,这个图被用作 Transformer 的 attention mask,限制每个基因主要与其相关基因进行信息交互。这样可以减少无关基因之间的噪声传播,让模型更容易捕捉真实的调控关系。
其次,我们使用了差分注意力机制 [2](Differential Attention)。与传统注意力直接处理表达值不同,这一机制更关注扰动前后表达变化的差异。在单细胞扰动任务中,真正重要的信息往往不是绝对表达水平,而是某些基因在扰动后发生了怎样的变化。差分注意力正是通过强调这种变化信号,使模型能够更加敏感地捕捉扰动带来的关键表达模式。通过将以上这些结构设计与生成式流匹配框架结合起来,scDFM 能够在噪声和稀疏数据环境下稳定地学习到扰动相关的表达变化模式。
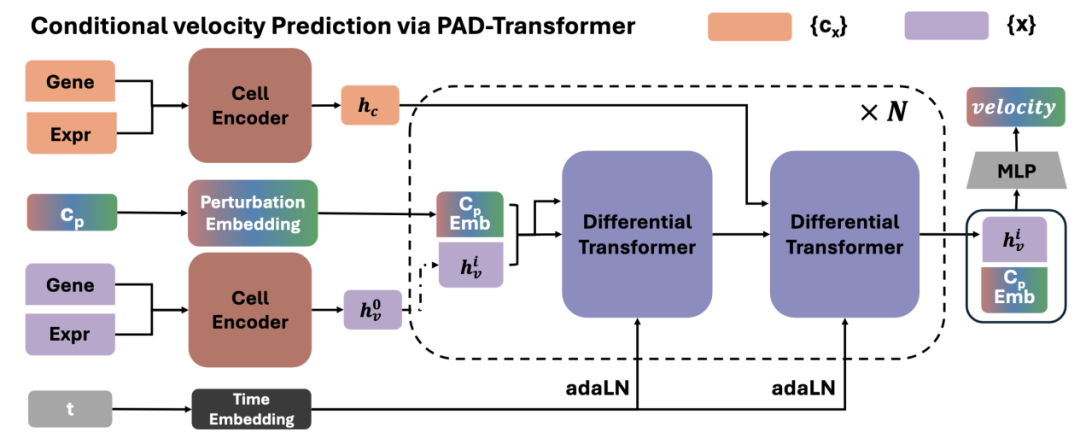
模型结构示意图
实验结果:分布级流匹配优势显著,在重构误差与群体区分能力上表现优异
为了验证 scDFM的能力,我们在两个单细胞扰动领域的经典数据集上进行了评估:Norman和ComboSciPlex。Norman 数据集通过CRISPR技术对细胞进行单基因或双基因扰动,并记录扰动后的转录组变化。ComboSciPlex 则关注小分子药物扰动,记录不同药物及其组合对细胞表达的影响。相比基因编辑数据,这类数据更加接近真实的药物研发场景,因此也常被用于评估模型是否具备 in silico 药物筛选的潜力。
在实验中,我们选择了几类具有代表性的基线方法进行对比,包括基于流匹配生成模型的最优基线模型 CellFlow [3]、基于大规模预训练的 Geneformer [4],以及专门针对组合基因泛化扰动设计的 GEARS [5]。这些方法分别代表了当前单细胞扰动预测中的不同技术路线。
Norman:基因组合扰动预测与泛化能力
首先来看Norman数据集。这是单细胞扰动研究中最常用的 benchmark 之一,用于评估模型是否能够预测基因组合扰动带来的表达变化。在 additive setting 中,模型在训练阶段可以看到单基因扰动以及一部分双基因组合,而测试阶段需要预测新的组合扰动。实验结果显示,scDFM 在多个指标上取得了最优或接近最优表现。
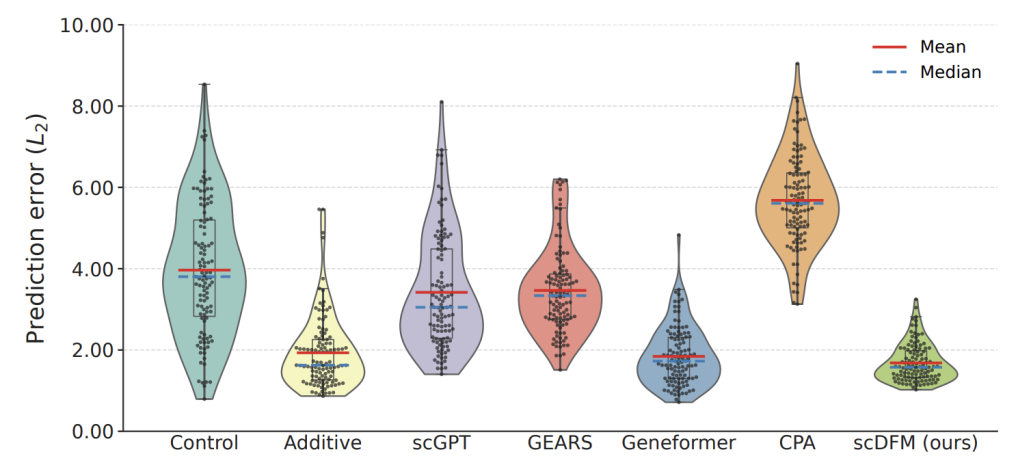
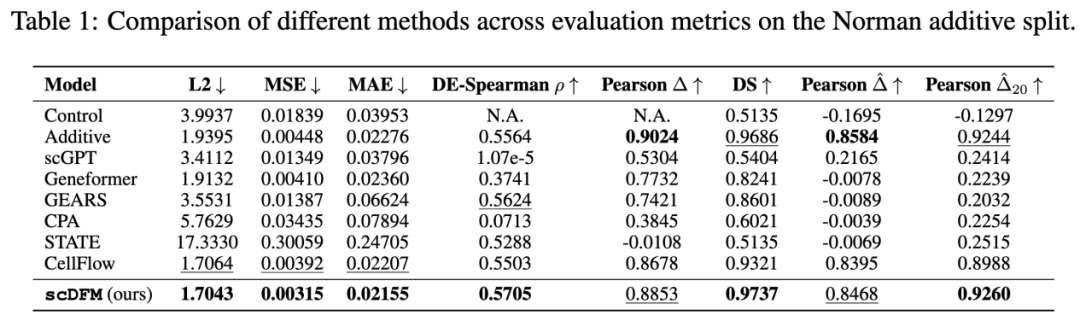
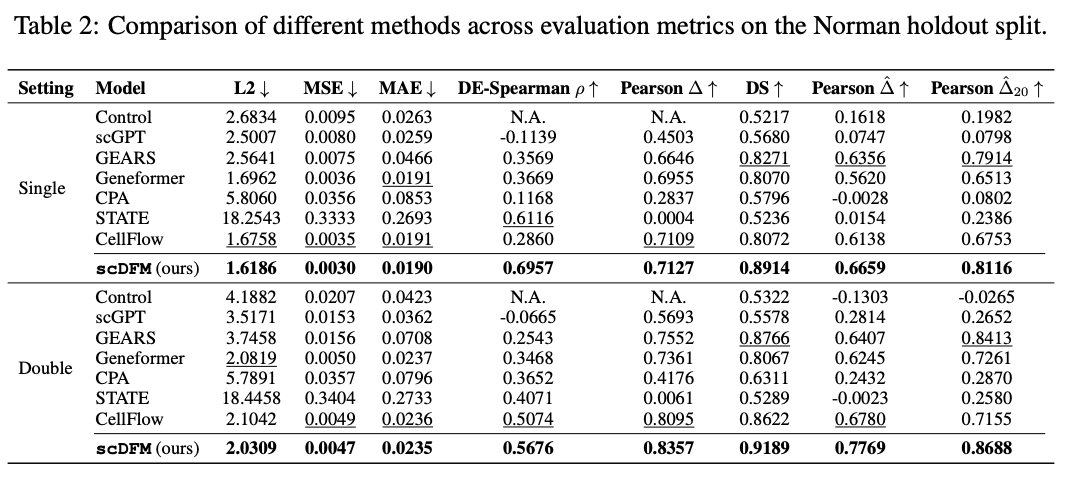
更关键的是holdout setting。在这一更困难的设置中,一部分基因扰动在训练阶段完全不可见,模型需要直接对这些新扰动进行预测。即使在这种情况下,scDFM 依然保持了稳定表现。在未见单基因扰动上,模型取得了 0.6957 的 DE-Spearman;而在更困难的未见双基因组合扰动上,DE-Spearman 依然达到 0.5676,同时 DS 为 0.9189。这说明当测试扰动明显超出训练分布时,scDFM 仍然能够同时保持较低的预测误差、正确的差异表达排序以及合理的群体分布结构,而不是只优化某一个指标。
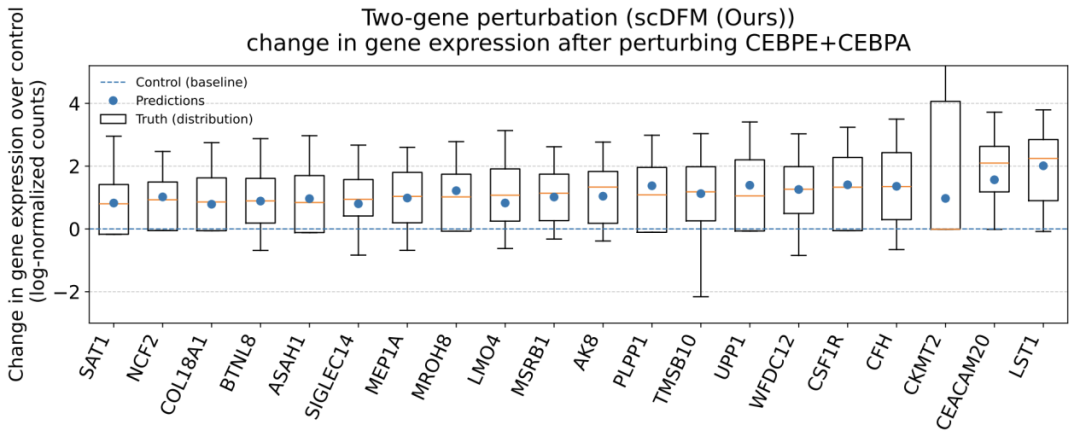
该图展示了在双基因扰动下,scDFM对基因表达量的预测值非常接近真实分布。
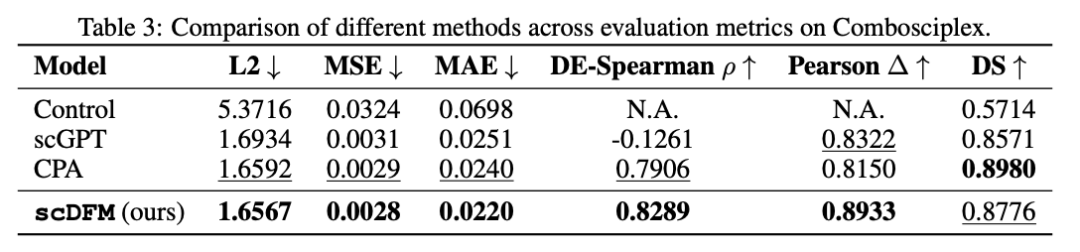
ComboSciPlex:药物扰动预测
为了进一步验证模型是否具有更普适的扰动建模能力,我们还在ComboSciPlex 药物扰动数据集上进行了测试。与 Norman 的基因扰动不同,这个数据集关注的是小分子药物及其组合对细胞表达的影响。实验结果显示,scDFM 在该数据集上同样取得领先表现。
消融实验:训练方式和模型架构都很关键
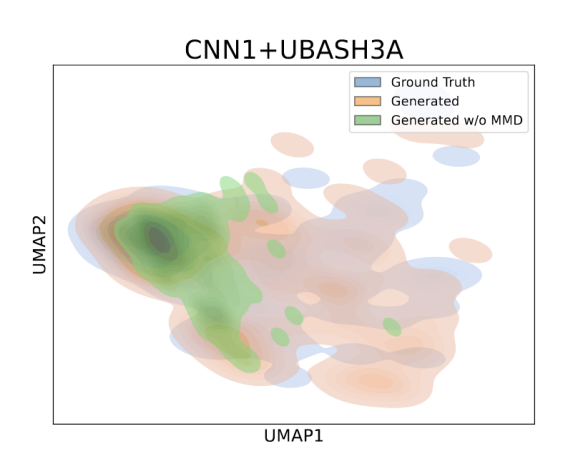
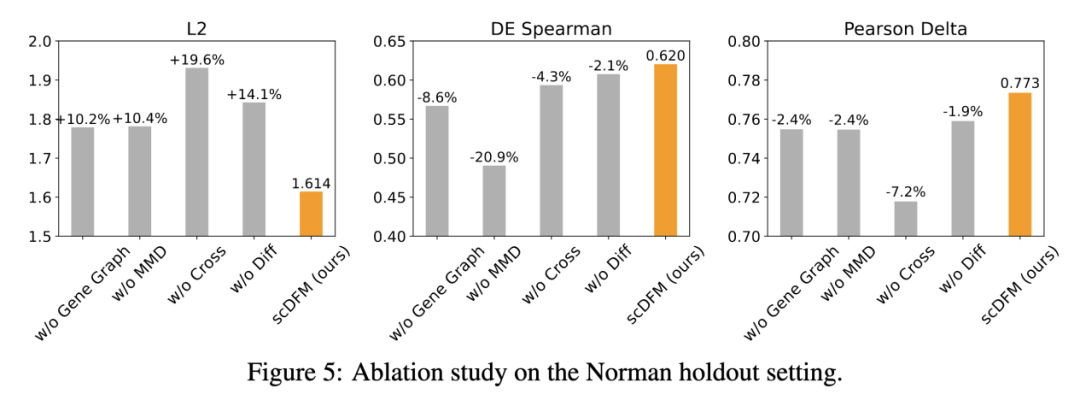
为了理解 scDFM 为什么有效,论文进一步在 Norman 的 holdout setting 上进行了消融实验,逐步移除模型中的关键组件。结果表明,其中影响最大的模块是MMD分布对齐。去掉这一项后,模型的 L2 误差上升约 19.6%, DE-Spearman 下降约 20.9%。这说明,仅学习细胞状态的演化轨迹还不够,只有在分布层面对齐真实扰动群体,模型才能更准确地捕捉群体层面的变化。下图中的降维结果也能直观看出,去掉 MMD 后,生成分布与真实分布的偏差明显增大。
此外,基因图结构先验、差分注意力也都对性能有贡献。去掉这些设计后,模型表现都会不同程度下降。说明在高噪声、高稀疏的单细胞数据中,合适的结构先验和注意力机制确实能提升模型的鲁棒性。
意义与展望
scDFM 的意义不仅在于提出了一个性能更优的预测模型,它还为单细胞扰动预测提供了一个新的建模视角:从"预测每个细胞会如何变化"转向"生成扰动后的细胞群体分布"。这一范式转变与单细胞数据的本质特征更为契合。在真实的生物系统中,扰动导致的是群体层面的分布偏移,而非确定性的细胞命运决定。scDFM 通过生成式流匹配框架,为这一生物学直觉提供了数学上严谨的建模方案。
在药物发现领域,scDFM 的方法论也为计算机模拟扰动筛选提供了更可靠的工具。研究者可以先在计算机中模拟大量潜在的基因或药物组合,看看哪些可能产生有意义的细胞响应,再把最有价值的候选带到真实实验中验证。这种方式如果成熟起来,有机会降低很多实验探索的成本。
再往远一点想,scDFM也可以被视为迈向“虚拟细胞系统”的一步。如果未来数据规模足够大、模型足够稳定,我们也许可以在计算机中构建一个近似的“虚拟细胞系统” [6],在里面模拟基因敲除、药物干预、甚至多重扰动的组合效应。这样一来,很多原本需要昂贵实验才能探索的问题,都可以先在模型中进行快速试验,再把最有价值的假设带回实验室验证。
当然,这条路还很长。单细胞系统本身非常复杂,真实的细胞行为还会受到细胞间通讯、微环境、时间动态等多种因素的影响。如果 AI 和生物学继续在这个方向上推进,也许未来我们不仅能模拟细胞对扰动的响应,还能进一步探索如何设计甚至控制这些响应。
参考文献
[1] Yu, Chenglei, Chuanrui Wang, Bangyan Liao, and Tailin Wu. "scDFM: Distributional Flow Matching Model for Robust Single-Cell Perturbation Prediction." ICLR 2026.
[2] Ye, Tianzhu, et al. "Differential transformer." ICLR 2025.
[3] Klein, Dominik, et al. "CellFlow enables generative single-cell phenotype modeling with flow matching." bioRxiv (2025): 2025-04.
[4] Theodoris, Christina V., et al. "Transfer learning enables predictions in network biology." Nature 618.7965 (2023): 616-624.
[5] Roohani, Yusuf, Kexin Huang, and Jure Leskovec. "Predicting transcriptional outcomes of novel multigene perturbations with GEARS." Nature Biotechnology 42.6 (2024): 927-935.
[6] Bunne, Charlotte, et al. "How to build the virtual cell with artificial intelligence: Priorities and opportunities." Cell 187.25 (2024): 7045-7063.
团队介绍
本论文共同一作为余成磊与王传睿,通讯作者为西湖大学吴泰霖助理教授。余成磊,西湖大学吴泰霖实验室2024级博士生,研究方向为生成式人工智能及其在科学问题中的应用。王传睿,西湖大学吴泰霖实验室2026级博士生,研究方向为AI for Science与生成模型,主要应用于生物系统的规律发现、仿真、和控制。
西湖大学吴泰霖实验室研究生成式AI(扩散模型、多智能体)及其在科学和工程领域的应用。长期招募希望在以上领域做出有影响力工作的同学和研究人员(博士生、博后、助理研究员、实习生)。具体领域包括:
聚焦人工智能与生命科学深度融合,基于生成式AI方法构建虚拟细胞,对单细胞以及多尺度的复杂生物系统进行扰动预测、响应建模与控制。应用场景涉及细胞分化、器官发育、个体衰老等动态生物过程,以及药物仿真与设计。
利用生成式 AI 方法,面向复杂物理系统(包括等离子体、水下具身智能)开展仿真、控制、诊断与设计研究,并有机会再从人造太阳到深海的极端物理场景中实际部署。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢