

视频剪辑需要将画面与声音一一对应,但从数小时原始素材中筛选出既推进叙事又匹配音乐节奏的片段,是一项高度依赖人工的繁琐工作,长期以来一直是电影制作人和专业内容创作者面临的挑战。
现有自动化方案各有缺陷:模板方法缺乏音视频同步,高光检测忽略音频和全局叙事,基于文本的方法则忽视音乐结构。它们本质上都是将音频、视频和指令独立优化,无法实现整体性的多模态对齐。
当前,这项任务依然面临三大挑战:长视频素材超出模型上下文窗口、需要将用户指令与源素材语义融合构建叙事、以及实现音乐节拍与视觉内容的细粒度时间对齐。
为此,来自北京交通大学、大湾区大学GVC实验室的研究团队提出了CutClaw。这是一个模拟专业后期流程的多智能体(Agent)框架,旨在生成高质量、节奏同步的短视频。

论文链接:https://arxiv.org/pdf/2603.29664
研究结果显示,CutClaw在视觉质量、指令遵循和音视频和谐度上均优于基线方法,用户研究中其各项投票率均超过第二名的两倍以上,类人性指标获得48.8%的偏好。
该研究首次将音频驱动视频剪辑形式化为联合优化问题,为自动化内容创作提供了实用方案。
研究方法
CutClaw将视频剪辑形式化为一个智能体驱动的片段提取与组装问题。给定原始视频素材、背景音乐和用户指令,系统需要优化一条时间线,使其最大化四个目标函数的加权和:视觉质量、叙事流畅度、语义对齐度和节奏对齐度。
整个框架采用由粗到细的层级策略来近似求解这一优化问题。
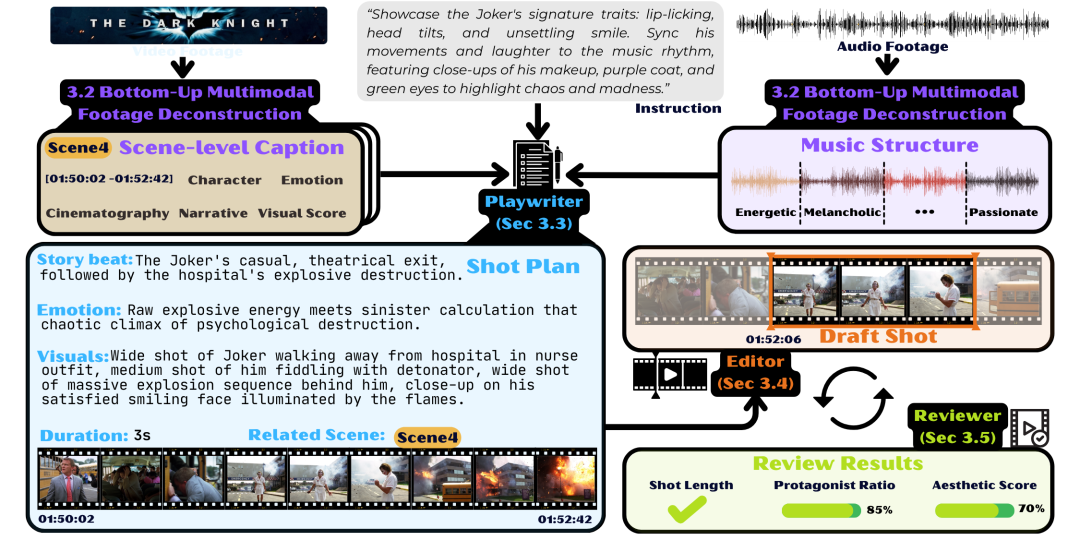
图|CutClaw 的完整工作流程。多模态素材首先经过解构处理,随后由编剧(Playwriter)生成镜头计划,剪辑师(Editor)负责场景检索与剪辑,最后由审阅者(Reviewer)进行质量验证。
1.自底向上的多模态素材解构
原始素材是连续的高维流,直接优化在计算上不可行。因此系统首先进行自底向上的解构,将输入离散化为结构化的语义单元。
在视频侧,系统采用层级聚合策略:首先通过镜头(shot)边界检测将素材切分为原子级的“镜头”;再利用多模态大语言模型为每个镜头提取涵盖摄影手法、人物动态和环境的语义属性;然后通过计算相邻镜头之间的转换相似度,在相似度低于阈值时划定场景边界,将连续素材分割为离散的叙事块;为保证涉及反复出现角色的叙事一致性,系统还通过分析对白推断人物身份,并将这些身份信息注入场景分析中,使描述能精确绑定到具体角色。
在音频侧,系统采用层级关键点检测,提取三类候选点:下拍重音、音高变化和频谱能量变化,形成统一候选池并进行去重过滤。随后利用多模态大语言模型将音轨划分为粗粒度的结构单元(如主歌、副歌),并在每个单元内对关键点进行重要性打分和筛选,最终生成描述节奏、情绪和能量的结构化音频标注。
2.Playwriter:音乐锚定的剧本合成
Playwriter智能体以音乐结构作为叙事的不变时间锚点,将视觉叙事进展严格对应到听觉骨架上。它通过两个阶段工作。
第一阶段是结构性场景分配:为每个音乐结构单元分配一组候选视觉场景,同时严格执行不相交约束——任何场景不得在不同音乐段落中被重复使用。若生成的方案违反此约束,系统会拒绝并触发带负面约束的重新生成。
第二阶段是关键点对齐的镜头规划:在每个音乐单元内,根据细粒度的音乐片段生成可执行的镜头规范,每个规范包含目标时长(由音频片段直接决定以保证节奏同步)、来源场景索引(限定下游搜索范围)和语义视觉描述(指导内容匹配)。这种层级绑定将全局优化问题转化为一系列局部检索任务。
3.Editor:自顶向下的层级视觉定位
Editor作为一个ReAct智能体,在Playwriter的结构化镜头规划约束下执行细粒度时间定位。对于每个检索规范,Editor通过假设-验证循环在候选池中寻找满足时长约束且最大化局部效用的具体片段。它拥有三个核心动作:
语义邻域检索:初始化局部搜索空间,检索指定场景的所有镜头。如果主搜索空间无法产生高置信候选,则自适应扩展到相邻结构单元,防止检索死胡同。
细粒度镜头修剪:利用视觉语言模型在候选镜头内进行密集时间定位,寻找美学评分和主角出镜比例最优的子片段。如果当前片段评分不佳,智能体会根据反馈启发式地平移时间窗口。
提交:将修剪后的候选提交给Reviewer审核,通过则渲染并提交到最终时间线,否则触发回溯机制探索其他区间。
4.Reviewer:多标准有效性门控
Reviewer作为判别性门控,对Editor提出的每个候选片段进行严格的拒绝采样审核,涵盖三个维度:
语义身份验证:通过计算主角出镜比例确保视觉主体与目标身份一致,过滤主角仅为背景或被遮挡的假阳性;
时间与结构完整性:验证非重叠约束和时长保真度,确保视觉切点与音乐节奏网格精确对齐;
感知质量保证:审核低级视觉显著性,拒绝存在显著质量退化的镜头。
任何违规都会触发结构化反馈,提示Editor回溯并探索替代区间。

图|一个单镜头剪辑的示例执行过程,所用素材来自电影《星际穿越》及音乐《Moon》。编剧、剪辑师和审阅者各自执行的操作分别以蓝色、黄色和绿色标注。橙色背景追踪了最终片段选择的执行路径。
研究结果
为评估该方法的有效性,研究团队构建了一个专门的评测基准,包含5部电影和5个长视频博客,原始素材时长从1到3小时不等,总计约24小时。其中,配套的音频输入涵盖流行、爵士、原声、摇滚和R&B等多种风格,目标剪辑时长从20秒到1分钟;评测设置了角色中心和叙事中心两类指令,共产生20个评测用例。
在定量评估中,CutClaw在所有指标上均取得最优表现。视觉质量平均分达到77.6,高于强基线Time-R1的72.9;指令遵循平均分达到70.0,高于NarratoAI的64.0;音视频和谐度平均分达到86.5,领先于其他方法。

图|CutClaw与基线方法的定性比较。两个案例分别使用了电影《红辣椒》和《爱乐之城》的完整片段,并分别搭配音乐曲目《Luv(sic) Pt.2》和《Norman F**king Rockwell》。镜头边界检测使用PySceneDetect完成。
消融实验验证了各组件的有效性。移除音频的节拍感知分析后,音视频和谐度从86.5大幅降至77.2;移除Reviewer后视觉质量从77.6降至76.0;用随机片段选择替代Editor后,指令遵循平均分从70.0降至65.6。这表明三个组件各自在节奏对齐、质量把关和叙事连贯性方面发挥着不可或缺的作用。
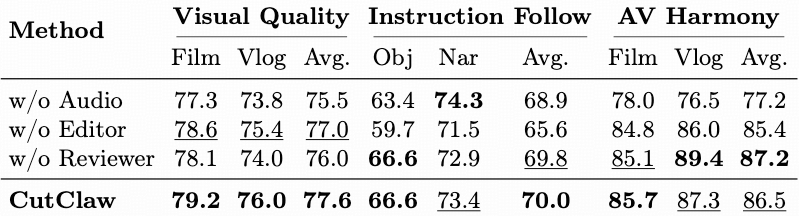
图|消融实验。研究团队报告了在三项指标上,分别去除剪辑师、审阅者或音频上下文后对性能的影响。
在涉及25名参与者、2000条评价意见的用户研究中,CutClaw在视觉质量上获得49.8%的投票,音视频和谐度获得53.0%,均超过第二名Time-R1两倍以上。在类人性指标上,CutClaw获得48.8%的用户偏好,表明其剪辑节奏和逻辑更接近专业人工编辑。
局限性与未来展望
当然,该研究也存在一些局限性。
研究团队写道,虽然系统保证了较强的叙事流畅性,但缺乏高级视觉钩子,如生成式视觉特效或特定独白高光,而这些对吸引观众至关重要。未来可以考虑整合生成式视频模型来合成这些表现元素。
此外,多阶段流水线处理大量原始素材也带来了较高的推理延迟,优化流水线速度或采用由粗到细的处理策略以实现实时反馈,是未来的关键研究方向。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢