
通过人工智能模型生成的合成数据正逐渐在医疗研究领域获得关注,尤其在血液学和肿瘤学等高风险领域。通过复制真实世界数据的统计特性、变量间关系及行为模式,合成数据集可作为传统医学数据的重要补充或替代。这类数据有望突破数据获取与共享的壁垒,推动科学发现的普及化,并降低临床试验的成本与失败率。然而,在训练数据选择、模型评估、偏差控制、隐私保护及质量保障等方面缺乏标准化规范,仍是制约其可靠性与安全应用的主要挑战。
针对上述话题,德累斯顿工业大学、意大利综合癌症中心Fondazione IRCCS Istituto Nazionale dei Tumori机构的研究人员于2026年2月20日在《Nature Reviews Cancer》上发表综述文章,题为“Artificial intelligence-generated synthetic data for cancer research and clinical trials”。

文章探讨了合成数据在癌症研究与临床试验中的作用,展示了实际应用案例,批判性分析了其局限性与潜在风险,并提出了提升数据保真度、有效性、公平性与实用性的最佳实践方案。尽管合成数据并非应对临床研究挑战的"万能良药",但通过严格验证与监管,其仍具有革新数据共享、科学合作及临床试验设计模式的巨大潜力。
背景
虽然目前对于合成数据尚无共识性的定义,但其基本原理是模仿真实数据集中的变量,以反映真实世界数据集的统计特性和变量间关系,同时不包含真实的患者信息。在消费级硬件进步、基于云的高性能计算资源、软件框架和模型设计的推动下,此类人工智能模型如今已能够有效生成多种模态的合成数据,如文本、图像、音频、视频和表格数据。由于机器学习模型依赖大规模数据集,合成数据已在人工智能领域用于扩充训练数据、模拟真实世界场景和验证模型。在肿瘤学领域,合成数据可以促进模型训练、便于模型基准测试、克服数据共享限制,并实现新颖的临床试验设计。
合成数据的生成与评估
生物医学中的数据类型
在癌症研究中,医学影像(如组织病理学全切片图像或放射影像模态)捕捉肿瘤形态、负荷和进展情况。表格数据包括来自电子健康记录的临床变量、人口统计学信息、实验室检测值、治疗史、结局、分子检测结果、转录组谱或蛋白质组学测定结果。如果随着时间的推移进行多次测量,这些数据称为时间序列数据。文本数据范围涵盖从结构化术语到非结构化的临床记录和报告。每种数据类型对生成式建模都提出了独特的挑战。例如,图像模型必须保留空间背景和细胞形态,而表格数据则需要维持复杂的变量间关系并避免出现不符合逻辑的值。
生成模型
主流生成模型包括以下几种:生成对抗网络(GAN)通过生成器与判别器对抗训练,生成高度逼真的数据;变分自编码器(VAE)学习数据的潜在分布,用于生成新样本;扩散模型通过逐步去噪生成高质量图像,在医学影像中表现优异;基础模型(如大语言模型)在大量数据上进行预训练,可以直接应用于许多场景,也可以针对更具体的应用进行微调,具有高度的灵活性,如编码临床轨迹、生成合成健康数据,以及在患者管理和研究中充当推理引擎。
合成数据的评估指标
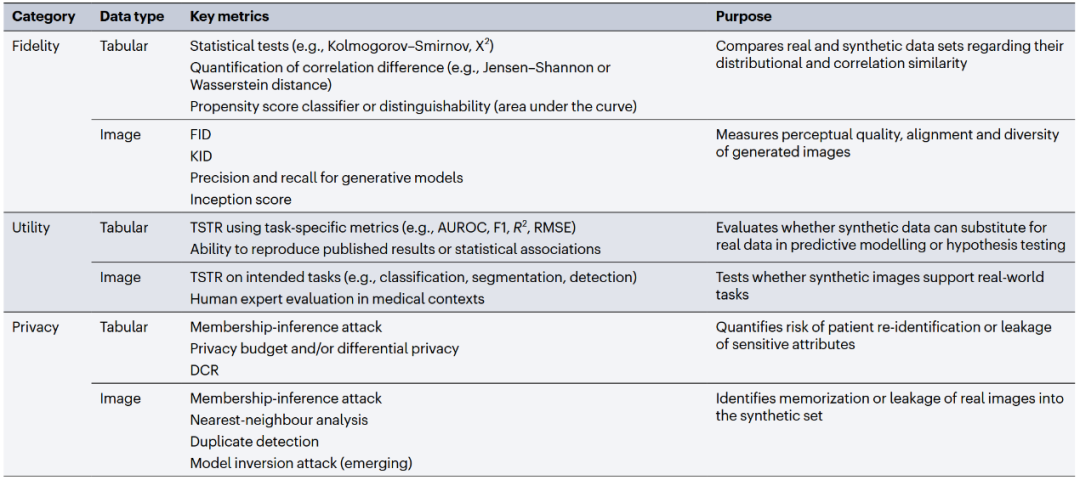
目前,合成数据生成的质量保证尚缺乏标准化。通常,需要对保真度、可用性和隐私保护进行评估。保真度(或相似性)指的是合成数据模仿统计分布和变量间关系的程度,通常通过统计方法进行评估。可用性(或实用性)评估合成数据在下游任务中的表现是否与真实数据相似。由于健康数据包含敏感信息,合成数据必须保护患者隐私,并降低重新识别和数据隐私泄露的风险。表1展示了图像和表格数据合成中的常用评估指标。
表1 合成表格型数据与图像数据的常用评估指标
合成数据的应用
用于科学发现、模型开发和基准测试的合成数据
人工智能模型本质上依赖大型且多样化的数据集来进行特征表示。目前,人工智能模型通常是在专有数据集上训练的,这些数据集要么由单个机构收集,要么由多个合作者汇集而成。尽管联邦学习和群体学习等技术允许合作者之间共享模型或权重,但它们仅部分规避了训练数据可用性的问题,同时仍然容易受到可能侵犯隐私的对抗性攻击。此外,公开可访问的合成数据可能有助于推动医学研究的民主化,即使对于成本高昂的数据集,也能让那些因结构性不平等或缺乏可用资金而无法接触到此类数据的研究人员获得数据访问权限。
癌症诊断中的合成病理图像数据
合成图像数据可以通过将合成样本添加到真实图像数据中来提升基于图像的分类器的性能。当图像质量足够时,在完全合成的数据集上进行训练可以产生与真实数据相当的性能。多项研究表明,GAN和扩散模型生成的病理图像在专家评估中与真实图像难以区分,并可用于虚拟染色、肿瘤亚型分类等任务。
癌症研究与肿瘤学中的合成表格数据
高质量的合成数据与它们的训练样本高度相似,使得能够在该合成数据内部进行探索,并可能允许像使用真实队列一样得出结论。具体来说,合成表格数据可用于复制真实队列中的预后模型、生成癌症基因组、提升生存预测能力。使用标准表格生成模型生成生存数据通常具有挑战性,因为这些模型通常难以处理时间-事件变量,例如总生存期。因此,在生存数据生成中需关注“optimism”“short-sightedness”等特有评估指标。最后,合成数据还可用于探索注册数据、支持政策制定,如SyntheticMass、Simulacrum等项目。
临床试验中的合成对照队列
创建对照组的传统方法正日益受到异质性、代表性不足、不一致性、监管限制以及对照组治疗方案过时等问题的限制。此外,如果现有的真实世界数据不符合试验要求,或者无法获取或负担不起,那么使用真实世界数据来扩充或替代对照队列是不可行的。而合成对照可以大规模生成,无需在对照组中进行大规模患者招募,这有可能加快试验进程,降低成本,并促进更快的监管申报和药物批准(图1)。多项研究验证了合成对照在多种癌症类型中的可行性,也指出其对训练数据质量和模型选择的依赖性。
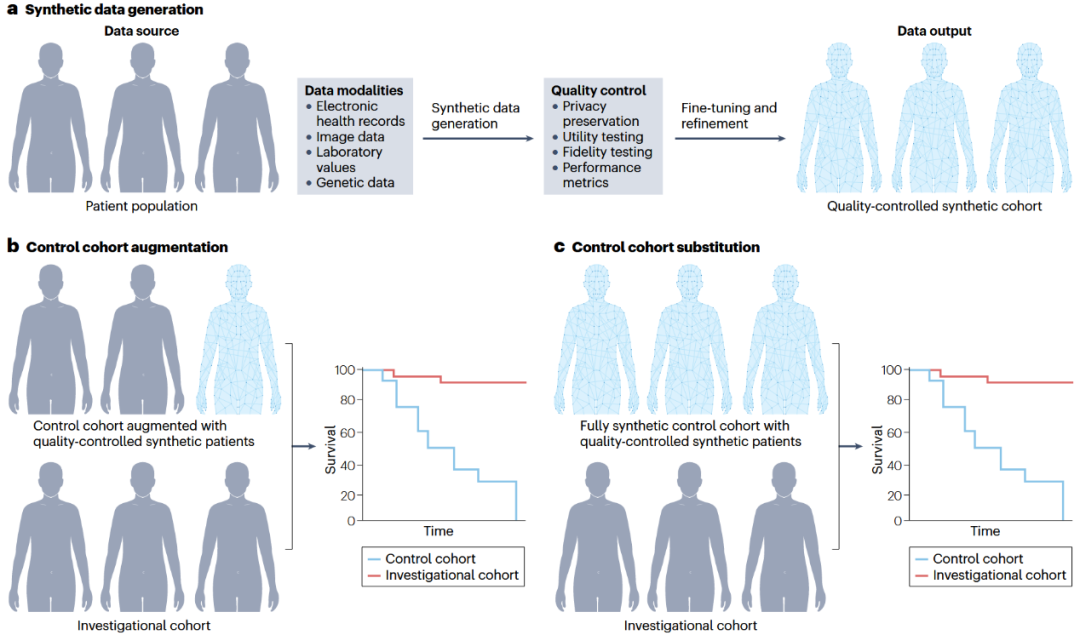
图1 癌症临床试验中的合成对照队列
合成数据生成的陷阱
偏差
在生成和使用合成数据时,评估训练数据中固有的偏差至关重要,因为这些偏差有可能延续到生成的合成数据集中。由于生成模型理想情况下会学习底层训练数据中的表示,这些训练数据中存在的任何偏差都可能影响生成的合成数据。在训练数据集中,一个规模小且代表性不足的种族亚组可能偶然显示出更高的事件发生率。当添加统计噪声以保护患者隐私时,这种虚假的模式可能被放大,导致模型错误地学习到种族可以预测结局,从而夸大了并不真正存在的效应。如果在数据生成之前正确识别出这些易受影响的群体,可以使用不同的模型架构和针对性数据增强技术来减轻生成模型训练中的偏差,或者可以使用特定模型来放大合成数据中的偏差,从而有效评估其在底层训练数据中的存在情况。
合成数据默认不保证隐私
当敏感的训练数据通过生成模型的意外行为,或通过外部操纵、强制信息提取而暴露时,就可能发生信息泄露。现成的生成模型默认情况下绝不保证合成医疗数据中的隐私保护。相反,它们可能给用户带来错误的安全感,从而可能通过无意中共享数据和模型而引入额外的隐私风险,这些数据和模型可能被怀有恶意的第三方访问和操纵。
合成数据缺乏监管
在对照组设计的范式转变过程中,探索构成稳健可靠对照的关键要素,同时认识到收集或生成对照样本的潜在局限性,对于监管决策至关重要。尽管像FDA这样的监管机构已发布了关于"医疗器械开发的良好机器学习实践"的指导原则值得称赞,但关于"医疗保健领域良好合成数据生成实践"的权威性指导仍然缺失。
建议的最佳实践
定义任务与准备数据
在生成合成数据之前,第一步应是明确合成的具体目标,例如实现数据共享或扩展现有患者队列。这应指导评估指标的选择以及待纳入变量的筛选,剔除标识符、冗余变量,处理缺失值,保留有意义的缺失信息。此外,可以引入规则,为来自较小队列的合成数据定制以满足特定任务需求。任何预期的修改都应在事前严格说明,并且理想情况下应由独立专家执行或接受外部审查。
训练与评估生成模型
在训练前通过过采样、剔除异常值等方式减轻偏差,应定义硬性约束以捕捉医学上不合逻辑的记录,例如不可能的实验室数值或不相容的临床特征组合。此外,使用多种生成模型和超参数优化,进行多次训练与采样以获取候选数据集。使用真实数据子集作为基准,筛选出接近真实-真实比较水平的合成数据。由于合成数据的生成本质上是迭代的,未达到预期标准的数据集应返回到先前的步骤。这可能涉及重新审视预处理选择、考虑额外的生成模型、执行更广泛的超参数优化,或改进评估指标以更好地捕捉与真实数据的一致性。此外,可以采用事后方法提高生成后合成数据集的可用性(图2)。
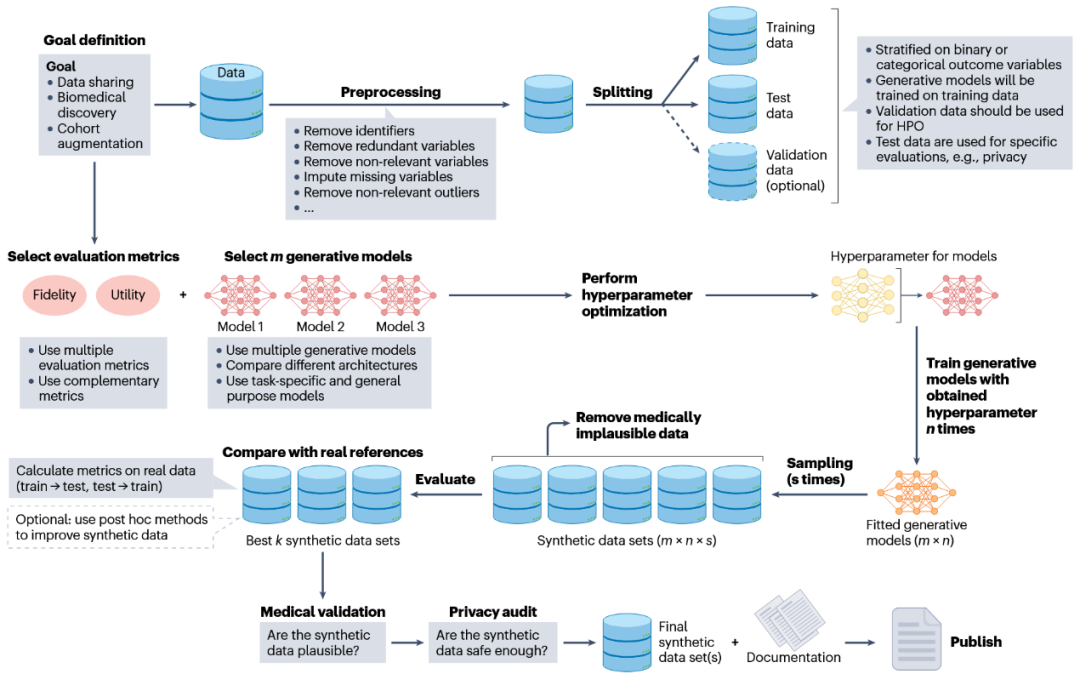
图2 生成与发布合成表格型生物医学数据集的推荐流程
确保隐私保护
在合成数据生成工作流的每个步骤中都纳入隐私保护的考量,有助于降低隐私风险。首先,在训练数据的预处理和标注阶段,考虑到可用性和隐私之间的权衡,应仔细考虑应将哪些变量纳入合成数据集。其次,应评估用于隐私保护的计算技术在任何特定用例中的适用性。通过向训练数据添加噪声,差分隐私可以降低识别单个样本的风险,同时允许用户调整噪声程度。尤其是在涉及多个用户或数据所有者时,可以实施数据加密,以便即使在共享模型或模型权重时也能在本地保护数据。第三,必须评估是否有必要同时共享合成数据和用于生成该数据的训练模型,或者仅共享合成数据就已足够。
降低合成数据在临床试验中传播与使用风险的措施
所有预处理步骤、模型配置、评估流程和隐私保护措施都应连同合成数据集及其元数据一起记录并发布。目的是增强对数据的信任,明确数据可安全用于哪些研究,避免“挑拣有利结果”或人为操控结论。若允许试验方自行生成合成数据,存在为获得预设结论而设计合成对照队列的风险。建议由独立于试验申办方与执行方的第三方生成合成数据,从源头减轻利益冲突。为此,对接受标准治疗的患者进行去中心化数据收集,可以形成一个训练数据库,并由独立的第三方进行质量检查。在特定临床试验的方案制定期间,根据预定义的入组和排除标准,并在监管机构的指导和批准下,按需从这样的数据库中生成合成数据。由此产生的合成对照组应暂不提供给开展试验的研究人员和申办方,直到干预组的数据收集完成,届时再提供用于分析。这样,合成数据就无法被篡改以获得期望的结论,而是代表原本可从对照组真实患者那里获得的结论。
参考链接:
https://doi.org/10.1038/s41568-026-00912-4
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢