

近年来,能够自主生成科学假设、开展实验并起草论文的手系统已成为加速科学发现的一种极具前景的范式。然而,现有的“人工智能科学家(AI Scientists)”在很大程度上仍属于领域无关型(domain-agnostic),这限制了它们在临床医学中的应用,因为医学研究要求以临床证据为基础,并涉及专门的数据模态。
在本研究中,我们推出了 Medical AI Scientist,这是首个专为临床自主研究定制的自主研究框架。该框架通过一种临床医生-工程师协同推理机制(clinician-engineer co-reasoning mechanism),将调研的文献转化为可操作的证据,从而产生具备临床依据的研究构思,并提升了生成构思的可追溯性。此外,Medical AI Scientist 还引入了受结构化医学写作范式和伦理政策指导的、基于证据的论文起草流程。
该框架在三种研究模式下运行,即:基于论文的复现(paper-based reproduction)、受文献启发的创新(literature-inspired innovation)以及任务驱动型探索(task-driven exploration),分别对应医学科学自主性的不同等级。通过大型语言模型(LLMs)和人类专家的综合评估表明,在涵盖 19 个临床任务和 6 种数据模态的 171 个案例中,Medical AI Scientist 生成的构思质量显著高于商业化 LLMs。同时,我们的系统在所提方法与其具体实现之间实现了极强的对齐(alignment),并在实验可执行率方面表现出显著更高的成功率。人类专家和斯坦福智能体评审器(Stanford Agentic Reviewer)的双盲评估结果显示,生成的论文质量接近 MICCAI 水准,并持续超越 ISBI 和 BIBM 的论文质量。本研究提出的 Medical AI Scientist 凸显了利用人工智能在医疗保健领域实现自主科学发现的巨大潜力。

论文:Towards a Medical AI Scientist
单位:香港中文大学、理海大学、斯坦福大学、微软研究院
发布日期:2026年3月
主页:https://cuhk-aim-group.github.io/Med-AI-Scientist-Homepage/
请索引第72篇论文
 |  |
首个“医学AI科学家”诞生!自主完成假设-实验-论文,稿件质量接近顶会水平
临床医生与AI工程师的“灵魂”同时注入智能体,让AI真正读懂医学、做可落地的科研。
想象一下,未来你有一个临床研究想法,只需对AI描述问题,它就能自动完成文献调研、提出创新假设、编写执行代码、进行实验验证,直至撰写出一篇结构完整、证据翔实的学术论文草稿。
这听起来像是天方夜谭,但由香港中文大学、理海大学、斯坦福大学和微软研究院组成的团队,已经将这个设想变为现实。2026年3月,题为《Towards a Medical AI Scientist》的论文,正式发布了首个为临床研究量身定制的自主科研智能体框架。

图 1 | a,系统工作流程:用于临床医学端到端科学发现的全自动多智能体系统。b,Med-AI 基准测试:可视化展示了性能基准测试中的 19 项不同的医学研究任务。c,实验设置:对研究生命周期中的想法生成、执行和论文撰写等各个阶段进行比较评估。d,性能基准测试:论文质量与顶级期刊的代表性论文相当。
01 临床科研之痛:从想法到论文的漫漫长路
医学AI研究正以前所未有的速度发展,但人类主导的科研流程本身,已成为制约创新的关键瓶颈。临床医生有宝贵的洞见和需求,但往往受限于复杂的算法实现和漫长的实验周期;AI工程师精通技术,却可能因缺乏临床先验知识,提出“指标漂亮但临床无意义”的模型。
现有通用“AI科学家”系统在临床领域面临三大核心挑战:
缺乏医学先验:它们通常关注通用模型优化,忽略了基础的诊疗流程和疾病特异的病理模式,导致假设与临床实际脱节。
数据与评估复杂:医学数据模态多样(图像、视频、文本、信号等)、维度高、结构复杂,且评估标准专业,使得自动化实验执行困难重重。
忽视伦理与规范:现有系统大多忽视医学数据的溯源、伦理声明的明确性等关乎研究可信度与可重复性的关键要求,无法产出符合临床写作规范与伦理标准的论文。见图1b:Med-AI Bench涵盖的6大数据模态与19种研究任务示意图。该图展示了研究场景与任务的碎片化现状,涵盖图像分类、分割、视频分析、电子病历预测、生理信号诊断、文本推理及多模态任务等。
如何让AI在严谨的医学证据、专业的数据模态和严格的伦理约束下,实现真正“有临床意义”的自主科研?这是横亘在前的核心难题。
02 医学AI科学家:一个三位一体的自主科研引擎
研究团队提出的“医学AI科学家”框架,旨在实现从问题到论文的端到端自动化。其核心是一个由三大组件协同工作的智能体系统:
见图1a:医学AI科学家框架整体架构图。该图展示了系统的三大核心组件:想法提出者、实验执行者和稿件撰写者,以及它们在三种研究模式下的协同工作流程。
1. 想法提出者:临床与工程协同推理,杜绝“幻觉”
这是框架的灵魂。它并非天马行空地生成想法,而是通过“临床医生-工程师协同推理机制”,将每个假设都建立在可验证的证据之上。
分析器 与 探索器:首先深入分析临床任务,检索相关文献与代码库,构建结构化的任务表征。
生成器:核心是让代表“临床视角”和“工程视角”的智能体进行对话与辩论。临床智能体确保问题的医学相关性,工程智能体负责技术的可行性。这个过程将临床洞见转化为具体的模型架构与训练目标,极大减少了大型语言模型常见的“幻觉”问题。
评估器:最后从科学性与伦理性两个维度对生成的假设计划进行过滤与评估,确保其严谨、可执行且符合伦理规范。
2. 实验执行者:面向医学数据的可靠验证管道
该组件负责将研究计划转化为可执行的代码,并在受控的Docker环境中运行。它集成了通用的执行工具链和针对异构医学数据(如DICOM图像、时序生理信号)的专用医学工具箱,能够处理复杂的数据预处理和领域特定的评估指标,实现迭代式、自校正的模型开发。
3. 稿件撰写者:遵循医学范式的结构化写作
它不仅仅是文本生成,而是一个遵循结构化医学写作范式的多智能体系统。它能基于实验日志和结果自动生成图表,根据最相关参考文献确定稿件结构,并嵌入伦理审查机制,确保对数据来源、许可和伦理批准的描述符合出版要求,最终产出可直接编译的LaTeX源文件。
三种研究模式,适配不同需求:
模式1:基于论文的复现——忠实复现既定方法,内置伦理审查。
模式2:文献启发的创新——基于给定文献和数据集,识别研究空白并生成新假设,强调原创性。
模式3:任务驱动的探索——仅从用户提出的一个开放性问题出发,自主进行文献挖掘、范式选择、方案生成与实验验证,是自主性最高的模式。
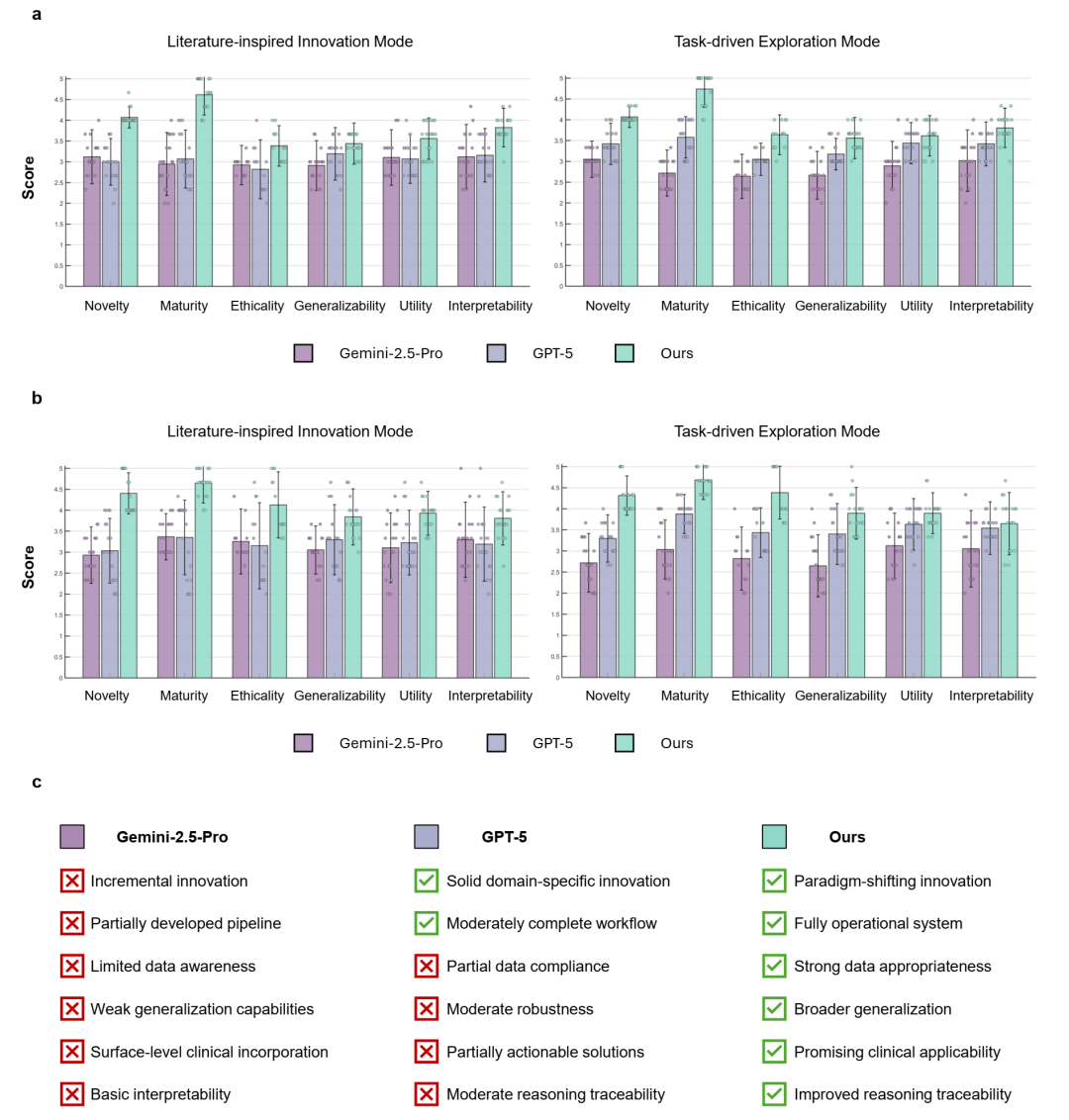
图 2 | 结合基于 LLM 和盲法人工评估,医学 AI 科学家在创意生成方面超越了商业 LLM。模型生成的研究创意经过匿名化处理,并由三位独立专家使用五分制进行评估。a,基于 LLM 的创意质量评估。b,基于六项评估标准的定量人工评估。c,相对于商业 LLM 的优势和局限性的定性人工分析。
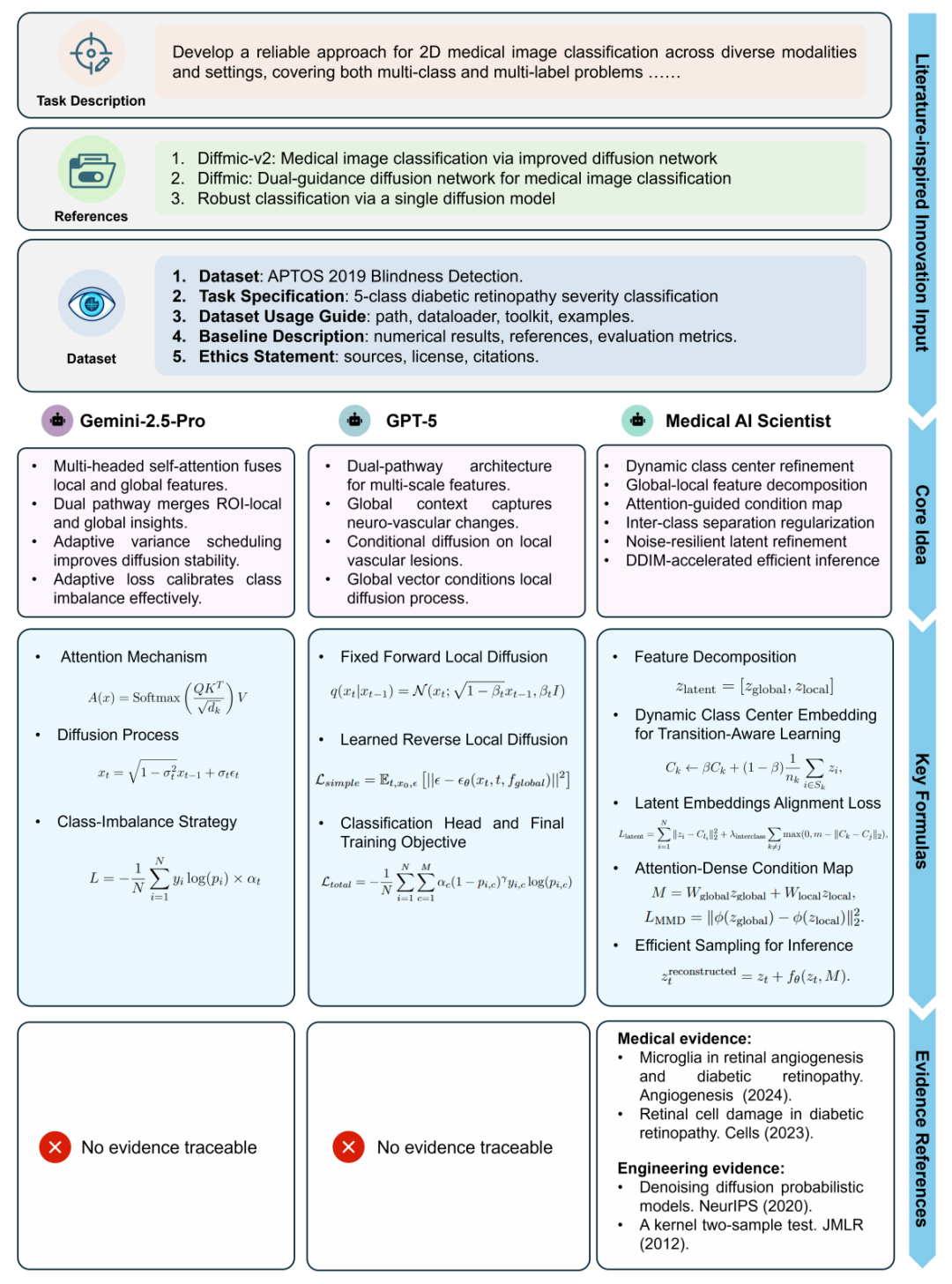
图 3 | 医学人工智能科学家与商业 LLM 在文学启发式创新模式下的创意生成比较示例。
03 性能验证:全面超越主流大模型,稿件质量媲美顶会
为进行系统评估,团队构建了Med-AI Bench基准测试,涵盖6大数据模态、19类任务的171个高质量案例。评估结果令人震撼。
1. 想法生成质量显著更高
在想法生成环节,从新颖性、成熟度、伦理性、泛化性、实用性和可解释性六个维度,与GPT-5、Gemini-2.5-Pro等顶尖商用大模型进行对比。
见图2:想法生成质量在六维指标上与基线模型的对比图。左图为LLM评估结果,右图为人类专家盲评结果。图表显示,医学AI科学家在各项指标上均显著且一致地领先于基线模型。
结果显示,无论是LLM评估还是人类专家盲评,医学AI科学家生成的研究想法在所有维度上均显著优于基线模型。人类专家特别指出,其想法具有更高的技术创新性、临床相关性以及更清晰的实验依据。
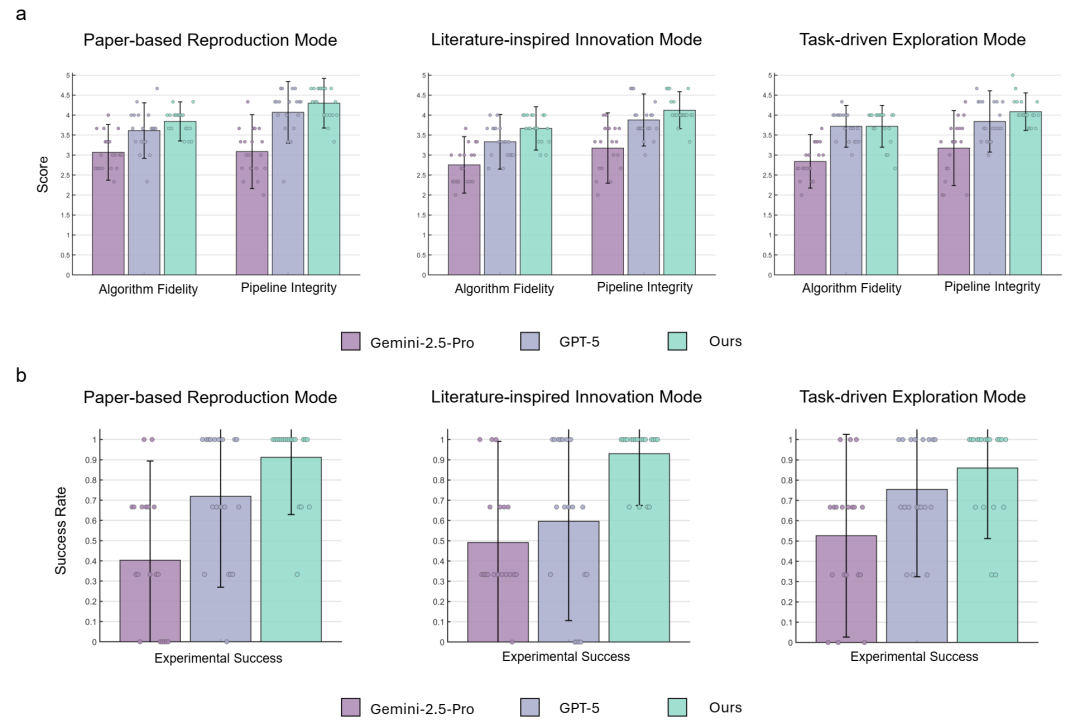
图 4 | 医疗人工智能科学家框架与商业 LLM 在实现完整性和实验成功率方面的比较评估。a,实现完整性采用 1 到 5 分的五分制进行评估。模型生成的输出经过匿名化处理,并由两位基于 LLM 的评委独立评估。b,实验成功率通过定量的人工评估来衡量。
2. 实验执行成功率高,代码可复现
将想法转化为可执行代码是另一个关键挑战。评估从“实现完整性”(方法是否被忠实实现)和“代码执行”成功率两方面进行。
见图4a&b:实验执行完整性评分与一次执行成功率对比图。图表显示,医学AI科学家在实现完整性和一次运行成功率上均远高于基线模型,尤其在开箱即用的成功率上优势明显。
医学AI科学家在各项指标上均表现最佳且最稳定。更重要的是,在“一次执行成功率”上,它在复现、创新、探索三种模式下的成功率分别达到91%、93%和86%,远超基线模型(例如Gemini-2.5-Pro仅在40%-53%)。这证明了其产出的代码具有极高的可复现性。
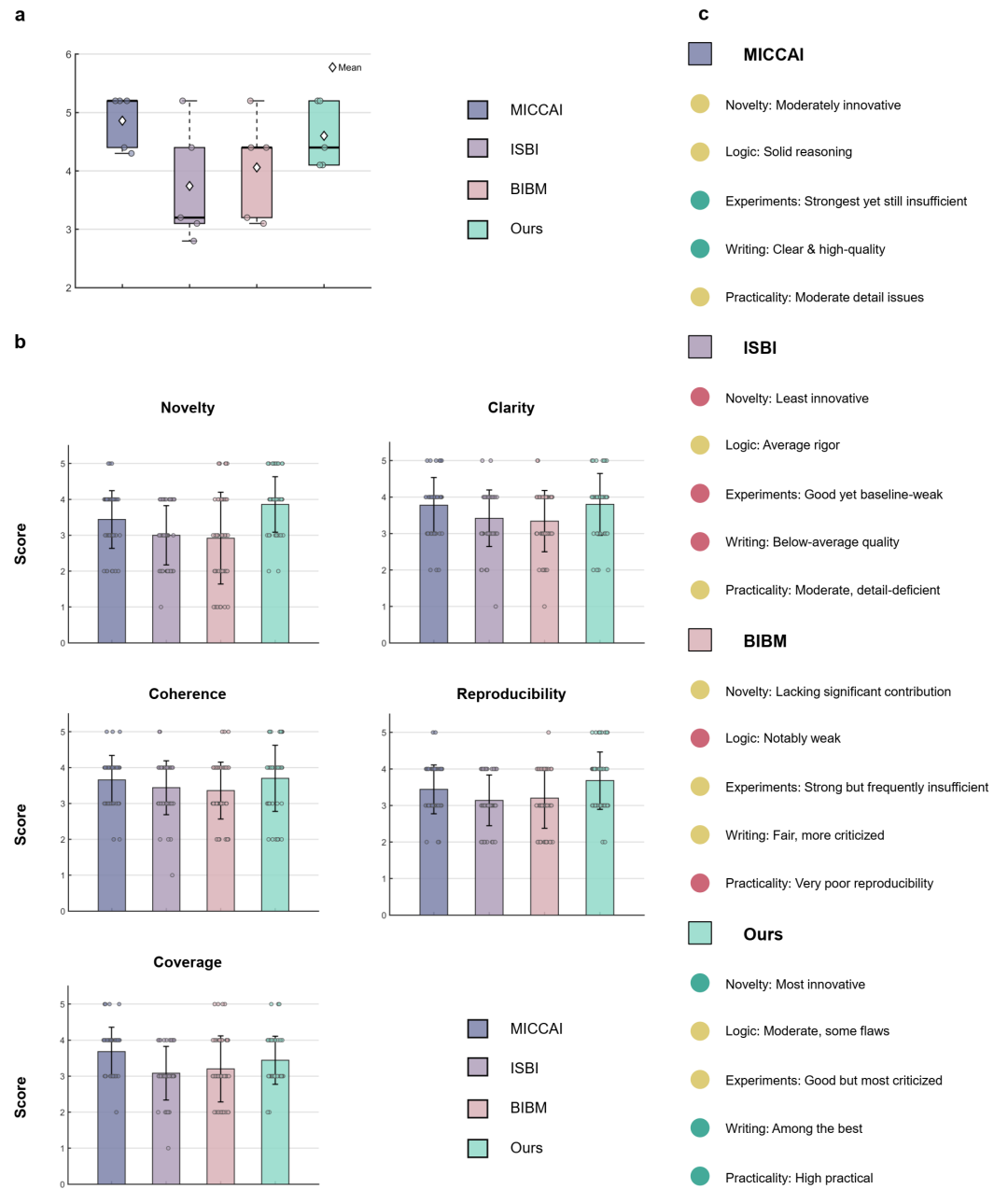
图 5 | 针对同一医学任务,对论文质量进行匿名比较。Medical AI Scientist 生成的稿件在定量和定性评估中,经一致的双盲评估,其性能与 MICCAI、ISBI 和 BIBM 相当:a,斯坦福智能评审员的自动评估;b,10 位医学专家(博士/博士后)从五个评审维度进行双盲评分(1-5 分);c,专家对优势和局限性的评价。
3. 生成稿件质量接近顶级会议水平
这是最受关注的测试:AI写的论文,能达到什么水平?团队设计了一项双盲专家评审,将AI生成的5篇关于糖尿病视网膜病变分类的论文,与随机从MICCAI、ISBI、BIBM这三大顶级会议抽取的15篇人类作者论文混合,交由10位经验丰富的领域专家评审。
见图5b:双盲人类专家对稿件质量的五维评分对比图。图表显示,AI生成稿件在“新颖性、可复现性、连贯性、清晰度”上与顶级会议(特别是MICCAI)稿件竞争力相当,仅在“覆盖全面性”上略有差距。
同时,所有稿件也交由遵循ICLR评审标准的“斯坦福智能体评审员”进行评估。
见图5a:斯坦福智能体评审员对稿件质量的评分分布对比图。图表显示,AI生成稿件的平均得分(4.60 ± 0.56)与顶级会议稿件得分范围高度重叠。
结果显示,AI生成的稿件在双盲评审中获得了与顶级会议论文竞争力相当的评价。专家认为其在方法论创新、逻辑连贯、表述清晰和可复现性上表现突出,仅在实验对比的广泛性上稍弱。更惊人的是,该系统生成的一篇稿件已被国际AI科学家会议(ICAIS 2025)接收,经过了真实的同行评审。
04 案例:看AI如何自主完成两项研究
案例A(模式2:文献启发创新):糖尿病视网膜病变分级
系统在没有明确指令的情况下,仅参考相关文献,通过临床-工程协同推理,从眼科文献中获取“需区分全局神经退行性病变与局部血管病变”的临床洞见,将其转化为一个双通路扩散模型架构,并设计了针对类别不平衡的损失函数。最终模型在疾病分期任务上取得了有竞争力的性能。
案例B(模式3:任务驱动探索):内窥镜视频画质恢复
用户仅提出“从低质量记录中恢复高分辨率、时间一致性的内窥镜视频”这一任务。系统自主检索文献,确定“时间不一致性”是关键未解难题,随后选择了一个新兴的连续时间视频恢复范式,将其适配到内窥镜场景,并完成了模型训练与验证,性能大幅超越基线。
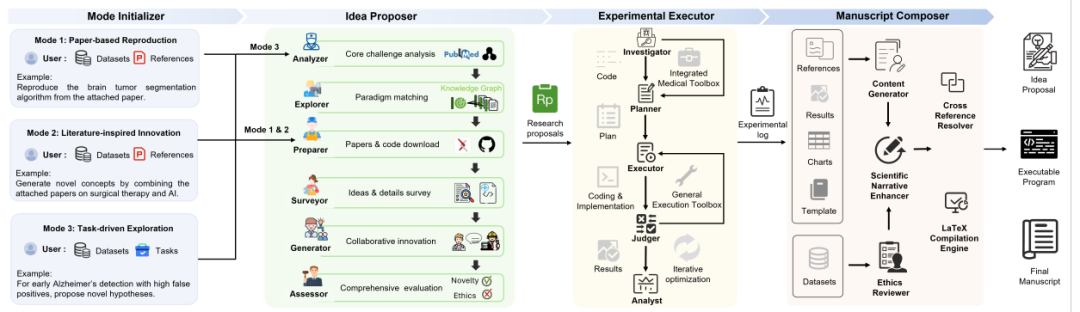
图 6 | 医学人工智能科学家概念图:一个用于临床医学端到端科学发现的全自动化代理综合系统。该系统提供三种用户交互模式:复现(复现指定假设)、创新(基于现有文献进行创新)和探索(自主探索给定的研究方向),以简化医学研究流程。工作流程包含多个阶段,涵盖自动生成想法、实验执行和论文撰写。
05 未来:从“辅助工具”到“共同发现者”
“医学AI科学家”框架的诞生,标志着医学AI研究范式的一个潜在转折点。它不再是执行单一任务的工具,而是一个能够理解临床问题、融合领域知识、并自主推进完整研究周期的“共同发现者”。
尽管当前系统在方法的复杂性、评估的广度方面仍有局限,但它清晰地指出了一条道路:通过深度融合临床先验与工程技术,并内置伦理与规范约束,AI能够极大加速从临床灵感到已验证解决方案的转化过程,降低创新门槛,让更多临床洞察有机会转化为切实改善医疗的AI模型。
在不远的未来,每一位临床工作者,或许都能拥有一位不知疲倦、学识渊博且严格守规的“AI科学家”作为科研伙伴,共同推动医学智能的边疆。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢