
DRUGONE
同源性搜索在计算生物学中具有基础性作用,它能够帮助研究人员识别生物序列之间的进化关系和功能相似性。然而,随着生物数据库规模的爆炸式增长,现有方法在效率和精度之间难以兼顾,难以处理十亿级别的数据规模。
在本研究中,研究人员提出了ERAST(efficient retrieval-augmented search tool),一种面向超大规模生物序列数据库的同源搜索框架。该方法结合大语言模型与向量数据库技术,将生物序列映射到连续向量空间,从而实现快速相似性检索。通过在检索流程中引入预检索过滤、向量检索和后检索重排序三个阶段,ERAST在保证搜索精度的同时显著提升效率。实验结果表明,ERAST能够在毫秒级时间内完成针对十亿级序列数据库的同源搜索,在速度上相比Foldseek提升约50倍,相比TM-align提升约50,000倍,同时在精度上也优于现有主流方法。这一性能使得大规模生物序列分析成为可行,并为功能注释与进化研究提供了新的技术基础。

同源性搜索是分子生物学研究中的核心步骤,通常用于分析新发现序列的功能及其进化来源。传统方法如BLAST等通过启发式比对策略加速局部比对,长期以来被广泛应用。随后,结构比对方法进一步提高了远程同源检测能力。
然而,随着宏基因组学的发展,生物序列数据库规模已经达到数亿甚至数十亿级别,这使得传统方法面临严重的计算瓶颈。一方面,大规模数据库导致搜索空间急剧扩大;另一方面,高精度方法往往依赖结构信息或复杂计算,难以扩展至如此规模。
向量数据库提供了一种新的解决思路。通过将序列编码为向量表示,可以在连续空间中进行快速相似性检索,从而避免昂贵的逐一比对。但在生物信息学中,如何构建高质量表示、设计高效索引并保证搜索精度,仍然是尚未解决的关键问题。
因此,研究人员提出ERAST,以统一框架解决规模、精度与效率之间的矛盾。
方法
研究人员首先利用预训练蛋白语言模型和核酸语言模型,将蛋白质和DNA序列编码为高维向量表示。在此基础上,构建包含超过十亿条生物序列的向量数据库,并采用多级索引结构(结合量化与图结构索引)以提升检索效率。
在查询阶段,ERAST将同源搜索流程划分为三个阶段。首先,通过引入序列长度、功能标签或分类信息等元数据进行预过滤,缩小搜索空间;随后,在向量空间中进行快速相似性检索,并通过多线程并行机制加速搜索;最后,利用专门设计的重排序模型对候选结果进行精细评估,从而提升最终结果的准确性。
这一三阶段设计使得系统在保持高效率的同时,实现对远程同源关系的精准识别。
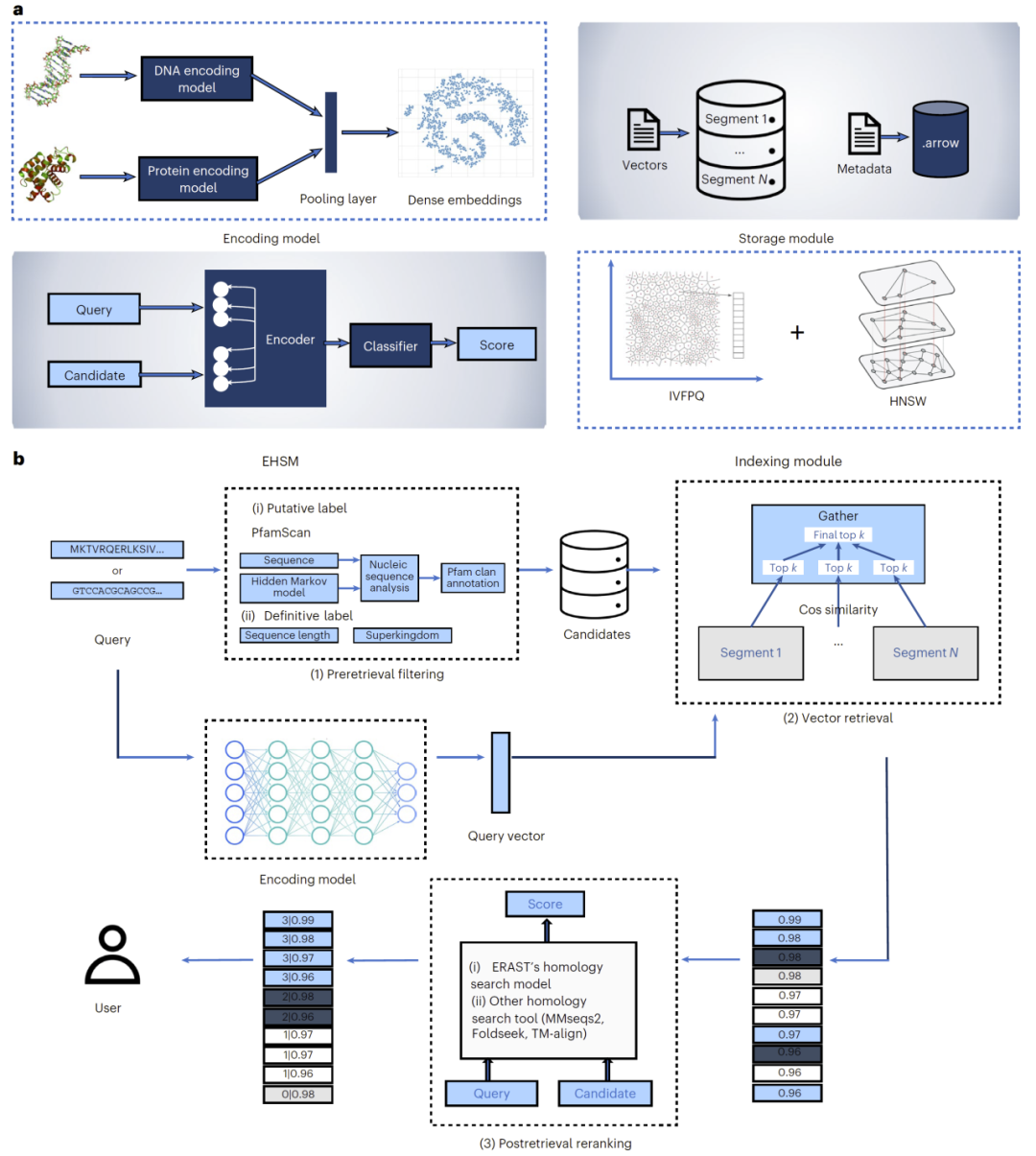
图1:ERAST整体框架概览。
结果
ERAST整体性能优于现有方法
在蛋白质同源搜索任务中,研究人员将ERAST与多种主流方法进行比较,包括基于序列、结构以及深度学习的多类方法。结果表明,ERAST在多个评价指标上均优于现有方法,尤其在识别远程同源关系方面表现突出。
在严格的测试数据上,ERAST不仅在精度指标上取得显著提升,同时保持了远高于传统方法的计算效率。这说明其不仅能够捕捉深层次的序列特征,还具备良好的泛化能力。
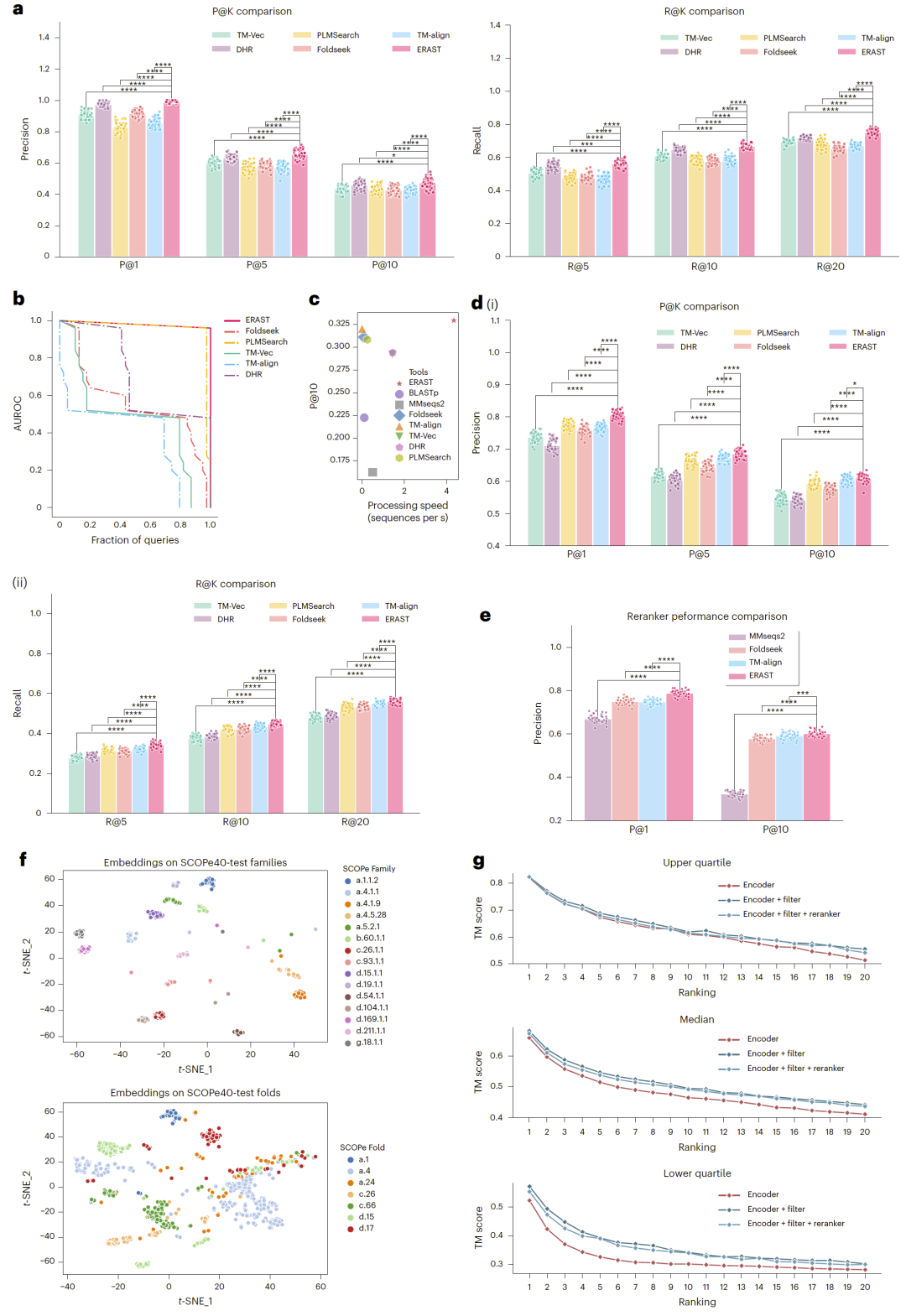
图2:ERAST在蛋白质同源搜索任务中的性能表现。
预过滤与重排序机制提升搜索质量
研究人员进一步分析发现,仅依赖向量表示虽然能够捕捉蛋白结构特征,但在区分精细结构层级时仍存在局限。通过引入预检索过滤,系统能够有效排除无关候选,提高初始检索质量。
在此基础上,重排序模型进一步对候选结果进行精细评估,使得最终结果在多个指标上显著提升。整体来看,这种“粗筛+精排”的策略显著增强了搜索性能,体现出模块化设计的优势。
核酸序列搜索性能提升
在核酸序列搜索任务中,研究人员将问题转化为分类任务进行评估。结果显示,ERAST在多个分类指标上均优于传统比对方法及分类方法。
特别是在属水平分类任务中,经过微调的编码模型显著提升了区分能力,表现出对长序列和复杂序列结构的良好建模能力。
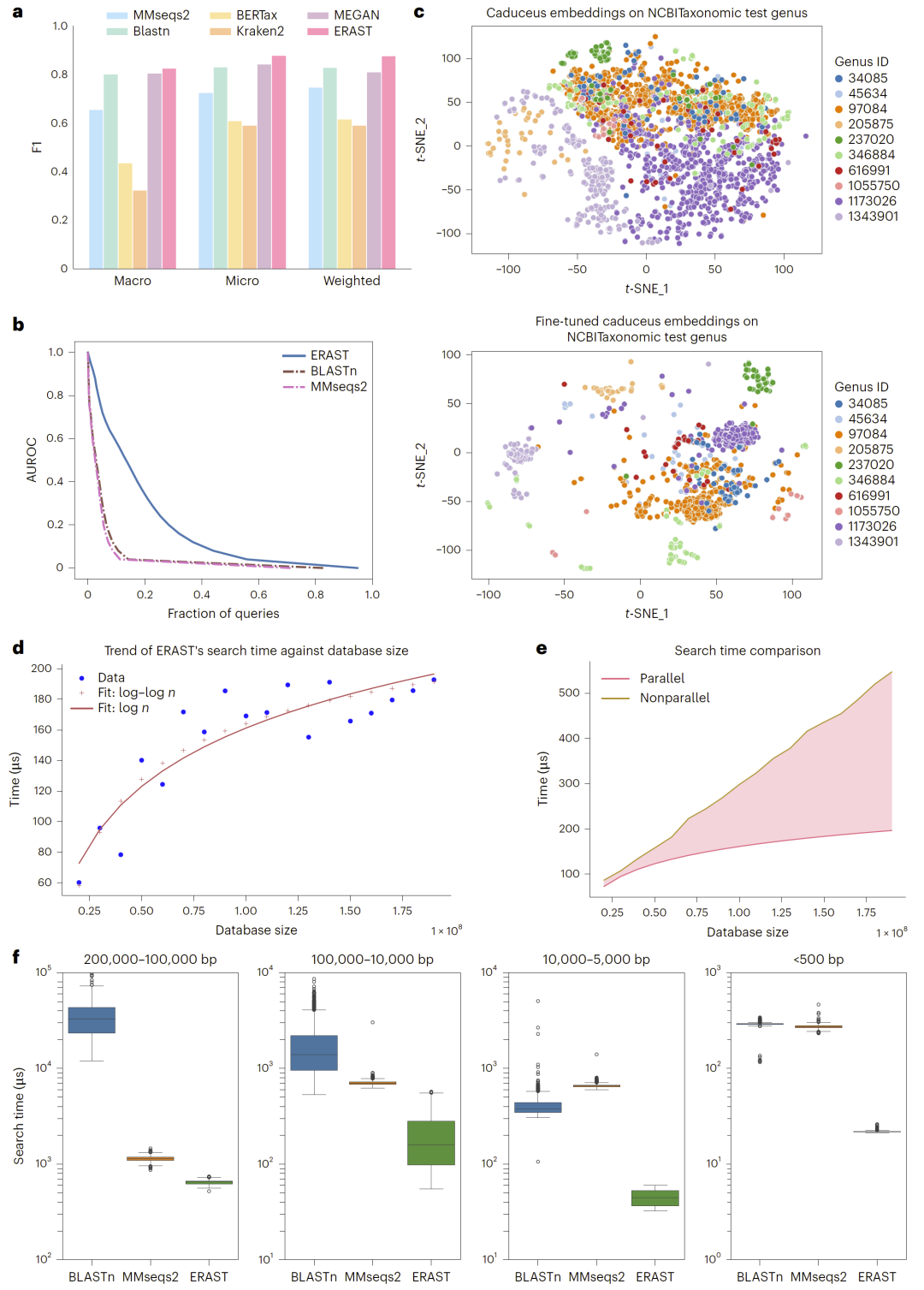
图3:ERAST在核酸序列同源搜索中的性能及其搜索效率。
超大规模搜索效率与可扩展性
研究人员进一步评估了ERAST在大规模数据库中的运行效率。结果显示,该方法能够在毫秒级时间内完成对十亿级数据库的搜索。
在统一计算资源条件下,ERAST的搜索速度显著优于现有方法。例如,相比结构比对方法,其速度提升达数十倍甚至数万倍。同时,通过数据库分段和并行检索策略,ERAST在数据库规模扩大时仍能保持近对数级增长的时间复杂度。
这一结果表明,ERAST在处理未来更大规模生物数据时具有良好的扩展能力。
基于全局相似性的功能聚类
除了搜索任务外,研究人员还利用ERAST进行大规模蛋白功能聚类。通过在UniRef数据库上构建基于全局相似性的网络,研究人员获得了数百万个功能簇。
其中,大量此前缺乏功能注释的“暗蛋白”被成功连接到已知功能蛋白簇中,从而为其功能预测提供线索。结构比对结果进一步支持这些潜在功能关联的合理性。
该结果表明,ERAST不仅是一个搜索工具,还能够作为功能发现与注释的重要平台。
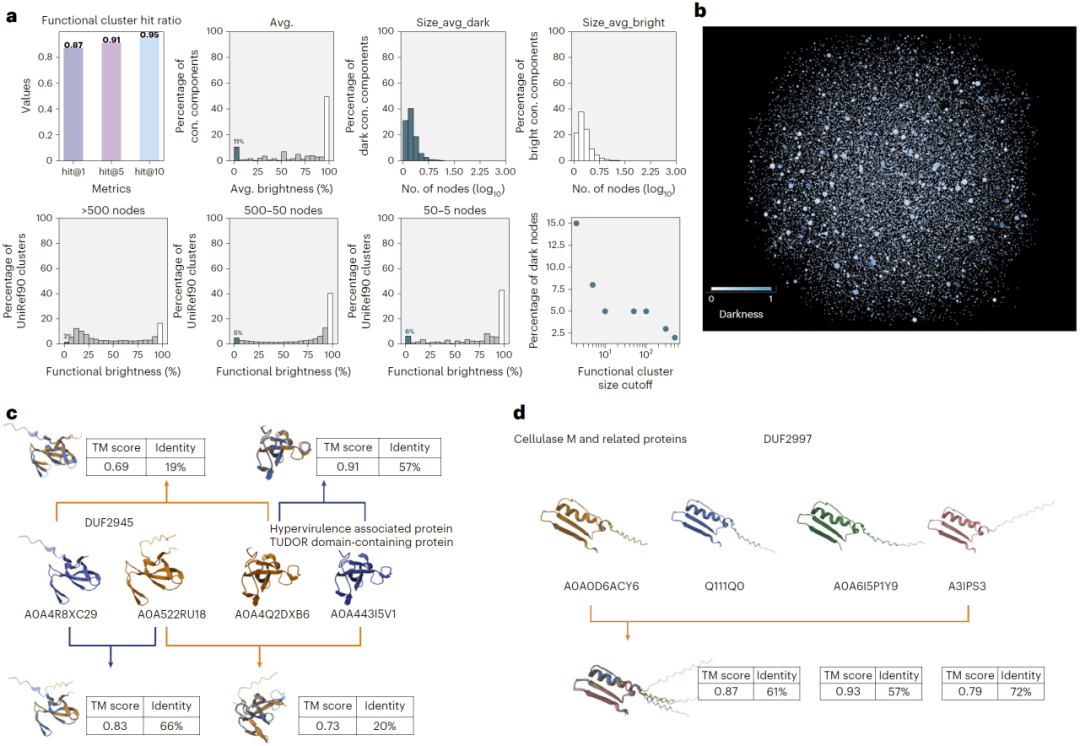
图4:基于UniProt的功能簇分析。
讨论
本研究提出的ERAST为大规模同源性搜索提供了一种全新的技术路径。通过将生物序列嵌入向量空间并结合高效索引结构,研究人员成功突破了传统方法在规模与效率上的限制。
与传统方法相比,ERAST不仅在精度上具有竞争优势,还能够在极大规模数据上实现实时搜索。此外,其模块化设计使得模型更新更加灵活,例如仅需更新重排序模块即可适应新数据分布,而无需重新编码整个数据库。
更重要的是,ERAST展示了向量检索技术在生命科学中的巨大潜力。通过支持大规模功能聚类和远程同源识别,该方法为蛋白功能注释、进化分析以及药物发现等领域提供了新的工具。
随着更多类型生物序列数据的整合,ERAST有望进一步扩展其应用范围,推动生物信息学进入“超大规模智能检索”时代。
整理 | DrugOne团队
参考资料
Jiang, Y., He, B., Wu, Z. et al. Scalable homology detection with ERAST. Nat Biotechnol (2026).
https://doi.org/10.1038/s41587-026-03051-1

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢