


ACL 2026
Simple-VGC: Enhancing Visual Grounding in Multimodal Reasoning via Adaptive Tool Composition
作者:王晔,陈强龙,王思远,李泽君,郭士杰,张志锐,魏忠钰
类别:主会长文
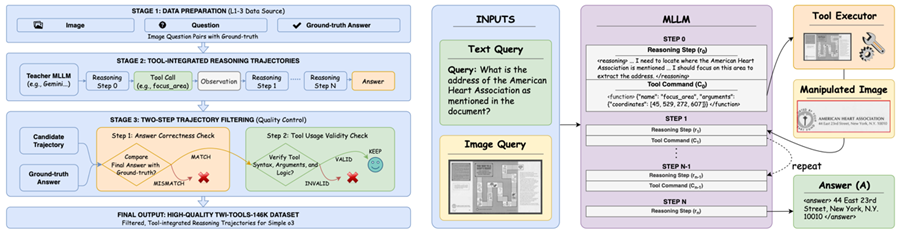
摘要:多模态大语言模型(MLLMs)在视觉-语言任务上已取得了很强的性能,但在生成过程中,往往难以持续保留并有效利用视觉证据。我们识别出三类根本性的视觉落地(visual grounding)失败问题:
长上下文落地错误(Long-Context Grounding Error):视觉嵌入会随着序列变长而逐渐衰减;
细粒度落地错误(Fine-Grained Grounding Error):低分辨率或退化输入会阻碍对细节视觉信息的恢复;
区域落地错误(Regional Grounding Error):空间上较为分散的注意力会削弱区域级别的视觉-语言对齐。
为了解决这些问题,我们提出了一种工具增强的推理框架,并设计了三种有针对性的补偿策略:reuse:重新注入原始图像,以缓解视觉遗忘;focus_area:将注意力约束在与任务相关的区域上;zoom_in:提升视觉分辨率,以增强细粒度感知能力。此外,我们还构建了 TWI-Tools-146K 数据集,并开发了 Simple-VGC,这是一种能够交错处理视觉与文本 token 的工具增强型多模态大语言模型。大量实验表明,每种工具都能针对其对应的落地错误带来定向改进,而将它们结合使用则能在视觉推理中产生协同增益。除性能提升之外,我们的分析还从机制层面揭示了基于工具的干预如何改善视觉落地,为实现更可靠的多模态推理提供了新的方向。
Ready Jurist One: Benchmarking Language Agents for Legal Intelligence in Dynamic Environments
作者:贾政,岳圣斌,陈伟,王思远,刘益东,李泽君,宋鋆,魏忠钰
类别:主会长文
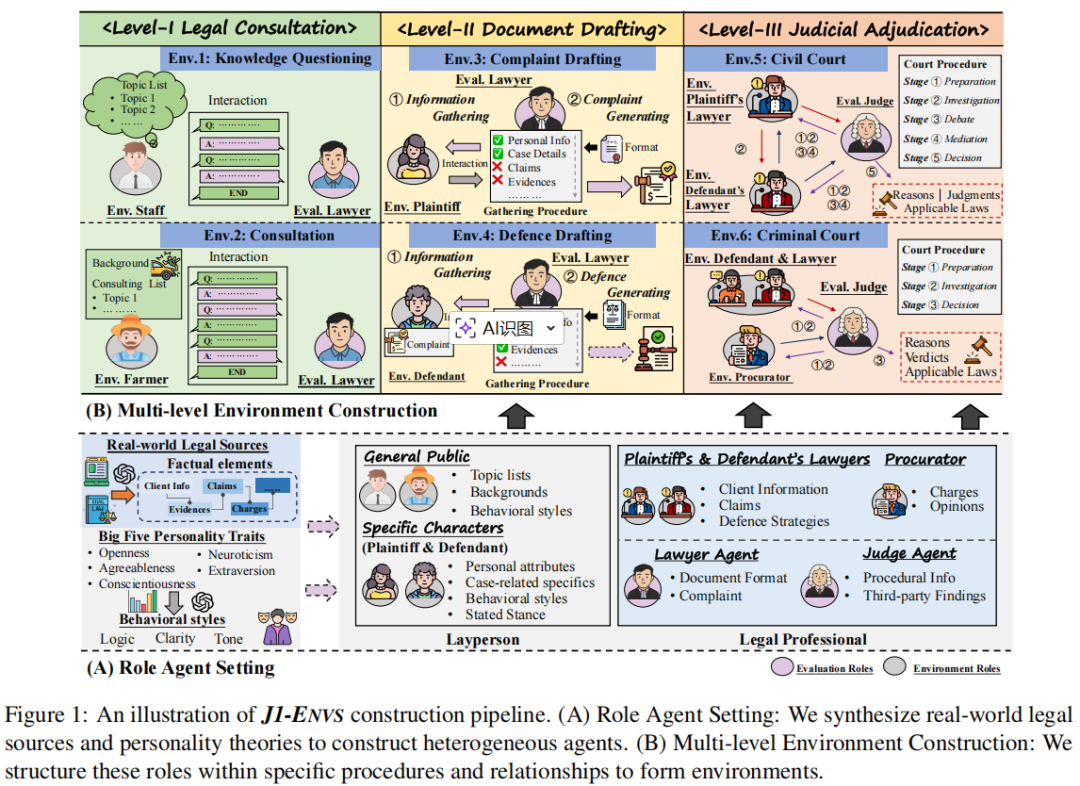
摘要:现有基准与现实世界法律实践的动态特性之间的差距构成了推进法律智能发展的关键障碍。为此,我们提出了 J1-ENVS,这是首个面向基于大语言模型(LLM)智能体的交互式动态法律环境。在法律专家的指导下,该环境涵盖了来自中国法律实践的六类具有代表性的场景,并覆盖三种不同层级的环境复杂度。我们进一步提出了 J1-EVAL,一种双指标评估框架,用于在不同法律能力水平下,同时评估任务表现与程序合规性。在 17 个 LLM 智能体上的大量实验表明,尽管许多模型展现出扎实的法律知识,但在动态环境中的程序执行方面仍然存在明显困难。即便是当前最先进(SOTA)的模型,其整体表现也低于 60%。这些发现凸显了实现动态法律智能所面临的持续挑战,并为未来研究提供了重要启示。
AutoJudger: An Agent-Driven Framework for Efficient Benchmarking of MLLMs
作者:丁炫文,潘成骏,李泽君,张霁雯,王思远,魏忠钰
类别:主会长文
合作单位:上海创智学院,南加州大学
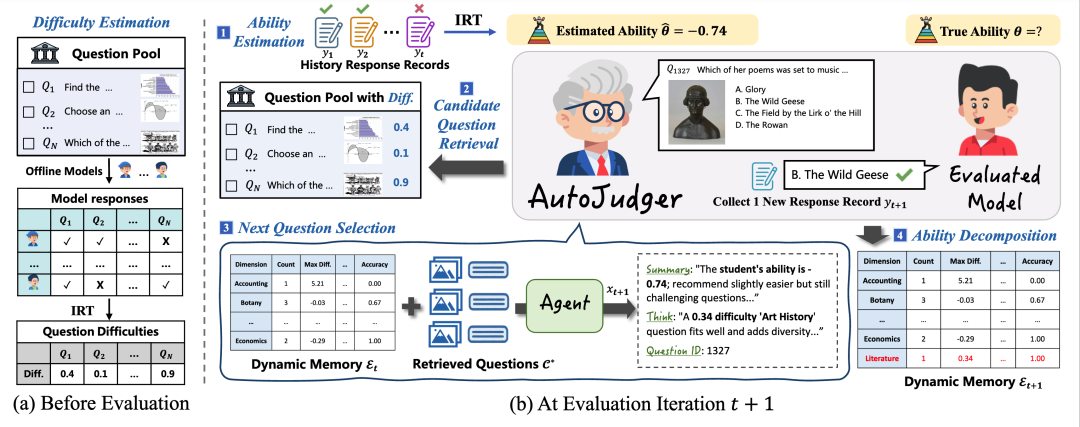
摘要:随着基准测试规模的不断扩大和跨模态复杂度的日益增加,评估多模态大语言模型(MLLM)的成本正变得越来越高。受认知心理学中结构主义的启发,我们提出了一种名为 AutoJudger 的自适应评估框架来应对这一难题,以实现高效的基准测试。不同于在固定测试集上进行被动打分,AutoJudger 将评估视为一个类似“面试”的过程:它通过维护被测模型的假设能力结构,主动挑选最具信息量的问题,从而不断细化其能力边界。具体而言,AutoJudger 包含三个核心组件:能力分解(沿有意义的能力维度组织评估)、能力估计(维护模型能力的最新量化画像),以及自适应问题选择(挑选最具信息量的问题)。为了将这一范式付诸实践,我们引入了![]() ,这是一种基于 MLLM 的新型 AutoJudger 智能体实例化形式,配备了语义感知检索与动态记忆功能。在四个具有代表性的多模态基准上的实验表明,
,这是一种基于 MLLM 的新型 AutoJudger 智能体实例化形式,配备了语义感知检索与动态记忆功能。在四个具有代表性的多模态基准上的实验表明,![]() 在保持评估结果可靠性的同时,显著提升了样本效率。
在保持评估结果可靠性的同时,显著提升了样本效率。
MAGNET: Towards Adaptive GUI Agents with Memory-Driven Knowledge Evolution
作者:孙立博,张霁雯,王思远,魏忠钰
类别:主会长文
合作单位:南加州大学
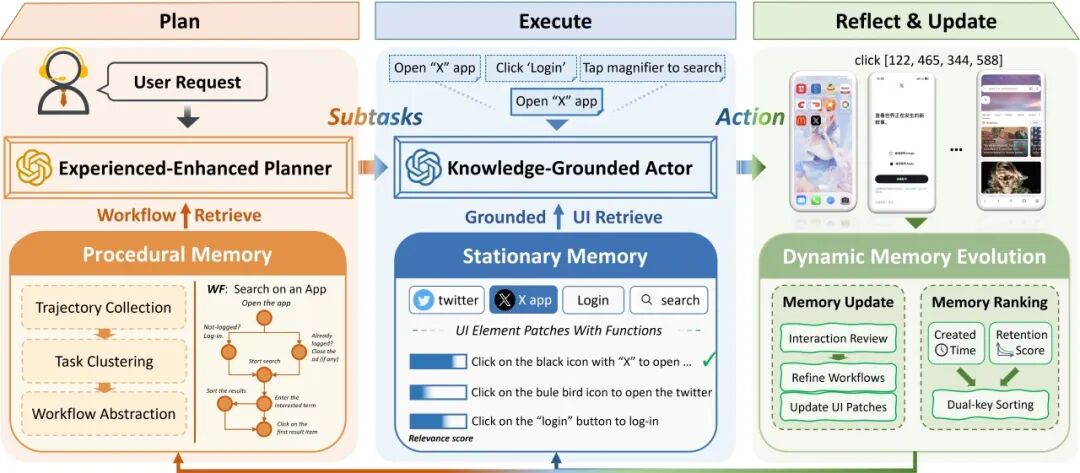
摘要:由大型基础模型驱动的移动端用户图形界面(GUI)智能体能够自主执行任务,然而频繁的软件更新会改变界面外观、重组操作流程,导致基于历史数据训练的智能体出现失效问题。尽管界面外观不断变化,功能语义与任务意图在本质上却保持稳定。基于这一洞察,我们提出了MAGNET——一个由记忆驱动的自适应智能体框架,包含双层记忆机制:静态记忆将多样化的视觉特征与稳定的功能语义相关联,以实现鲁棒的动作定位;程序记忆则在不同操作流程中捕捉稳定的任务意图。我们还设计了一种动态记忆演化机制,通过优先保留高频访问的知识,对两类记忆进行持续优化。在在线基准测试AndroidWorld上的评估结果表明,MAGNET相较基线方法取得了显著提升;离线基准测试同样证实了其在分布偏移情况下的稳定增益。上述结果验证了:在界面变化过程中充分利用稳定结构,能够有效提升智能体在动态软件环境中的性能与泛化能力。
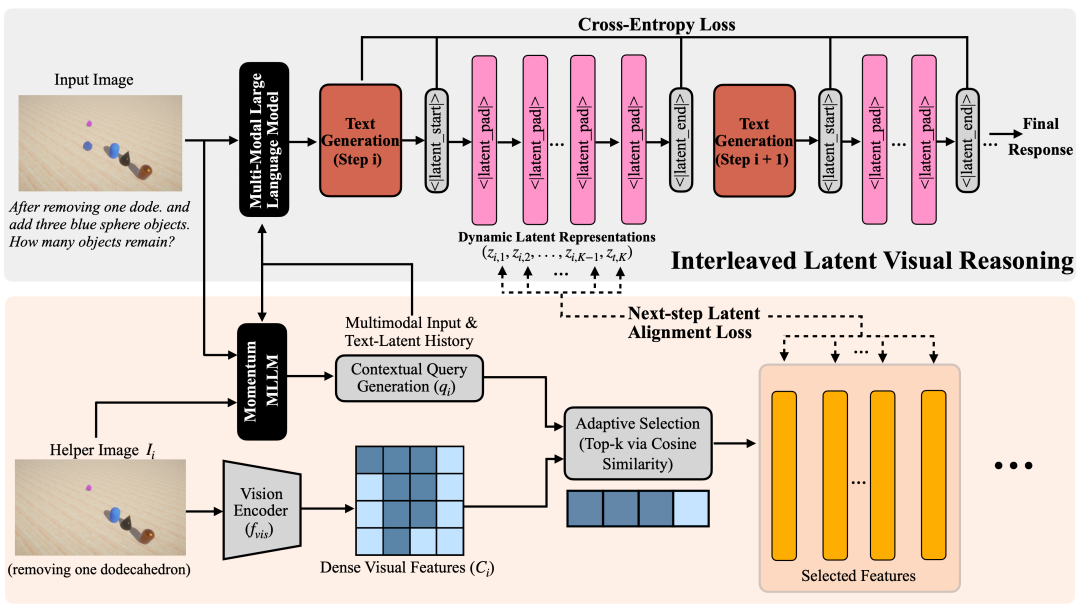
ILVR: Interleaved Latent Visual Reasoning with Selective Perceptual Modeling
作者:董帅、王思远、刘星语、李成林、侯皓文、魏忠钰
类别:主会长文
合作单位:南加州大学
摘要:交错式推理范式通过引入视觉反馈来增强多模态大语言模型(MLLM),但其发展受制于对像素密集图像进行重复编码所带来的高昂计算成本。一个很有前景的替代方案是潜在视觉推理(latent visual reasoning),它绕开了这一瓶颈,但仍存在局限:现有方法要么由于采用单步、非交错式结构,无法捕捉中间状态的演化;要么因为对特征过度压缩,而牺牲了精确的感知建模能力。我们提出了交错式潜在视觉推理(Interleaved Latent Visual Reasoning, ILVR)框架,将动态状态演化与精细感知建模统一起来。ILVR 将文本生成与潜在视觉表征交错进行,这些表征作为具体且不断演化的线索,为后续推理提供支持。具体而言,我们采用一种自监督策略:利用动量教师模型,从真实的中间图像中有选择地蒸馏相关特征,并将其转化为稀疏的监督目标。该自适应选择机制引导模型自主生成与上下文相关的视觉信号。在多模态推理基准上的大量实验表明,ILVR 优于现有方法,能够有效弥合细粒度感知与序列化多模态推理之间的鸿沟。代码和权重已开源,见https://github.com/XD111ds/ILVR。
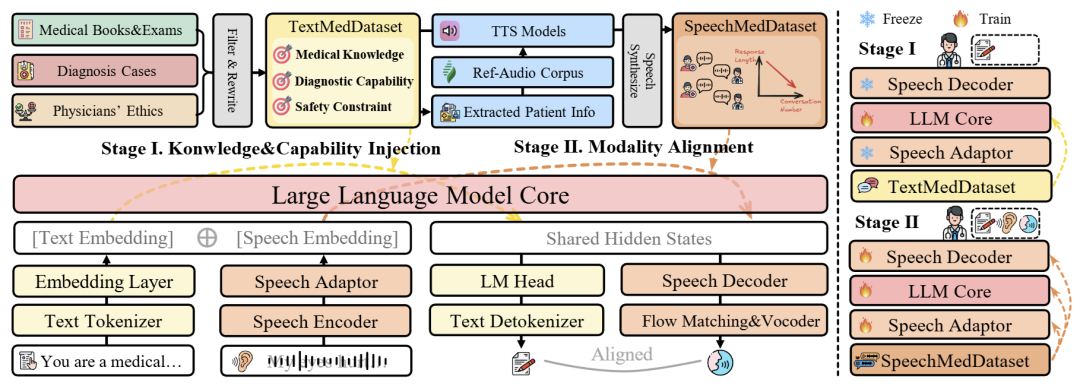
SpeechMedAssist: Efficiently and Effectively Adapting Speech Language Models for Medical Consultation
作者:陈思远,王洁怡,陈伟,魏忠钰
类别:主会长文
摘要:医疗问诊本质上是以语音为核心的交互过程。然而,现有大多数研究仍侧重于基于长文本的交流方式,这不仅繁琐,而且对患者并不友好。近年来,语音语言模型(SpeechLM)的发展使更加自然的语音交互成为可能,但医疗语音数据的匮乏,以及直接在语音数据上进行微调的低效率,共同制约了 SpeechLM 在医疗问诊场景中的应用。本文提出了 SpeechMedAssist,一种原生支持与患者进行多轮语音交互的语音语言模型。我们充分利用 SpeechLM 的架构特性,将传统的一阶段训练流程解耦为两个阶段:(1)基于文本的知识与能力注入,以及(2)利用少量语音数据进行模态重对齐。该方法将对医疗语音数据的需求降低至仅需 1 万条合成样本。为评估 SpeechLM 在医疗问诊场景中的表现,我们设计了一套基准测试,涵盖单轮问答与多轮模拟对话两类任务。实验结果表明,在大多数评测设置下,我们的模型在效果与鲁棒性方面均优于所有对比方法。
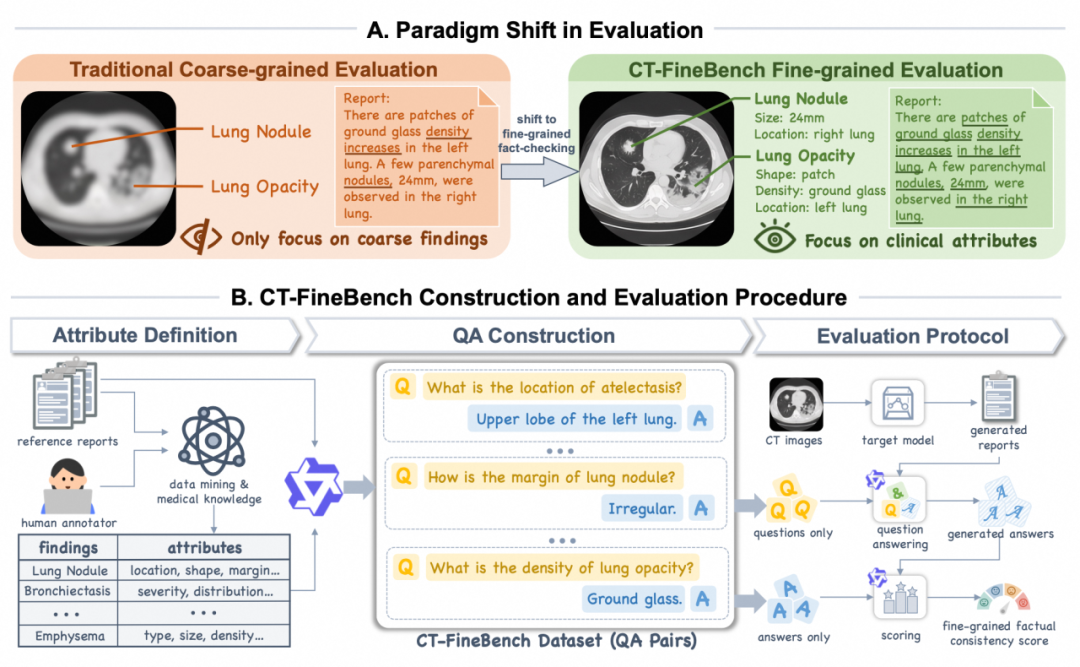
CT-FineBench: A Diagnostic Fidelity Benchmark for Fine-Grained Evaluation of CT Report Generation
作者:袁瑞峰,常琬星,曹维维,史博文,魏忠钰,张灵,张建鹏
类别:主会长文
合作单位:阿里巴巴达摩院
摘要:在医学CT影像报告的自动生成领域,对生成报告的评估仍是一项核心挑战。现有评估方法大多依赖词汇重叠或粗粒度的实体匹配,这使得它们无法准确衡量报告在临床诊断中所必需的细粒度事实准确性,例如病灶的位置、大小、边缘特征等关键属性。为解决这一难题,我们提出了 CT-FineBench,一个全新的CT报告评估基准。我们的核心创新在于将评估范式从模糊的文本比对,转变为一个基于问答(QA)的可验证、事实核查的过程。该方法以人工标注为基础,对CT报告中各疾病的关键临床特征进行识别与结构化;进而,将这些结构化特征系统地映射为一系列针对性问题。通过向机器生成的报告“提问”并评估其答案的正确性,我们得以实现一种全面、可解释且与临床需求高度相关的评估。CT-FineBench的目标是超越表面的文本相似度,定位生成报告中具体、细微的临床事实错误。它提供了一种对细粒度临床错误高度敏感、且与人类专家判断更为一致的评估标准。同时也为未来研发更具临床可信度和事实可靠性的CT报告生成系统铺平了道路。
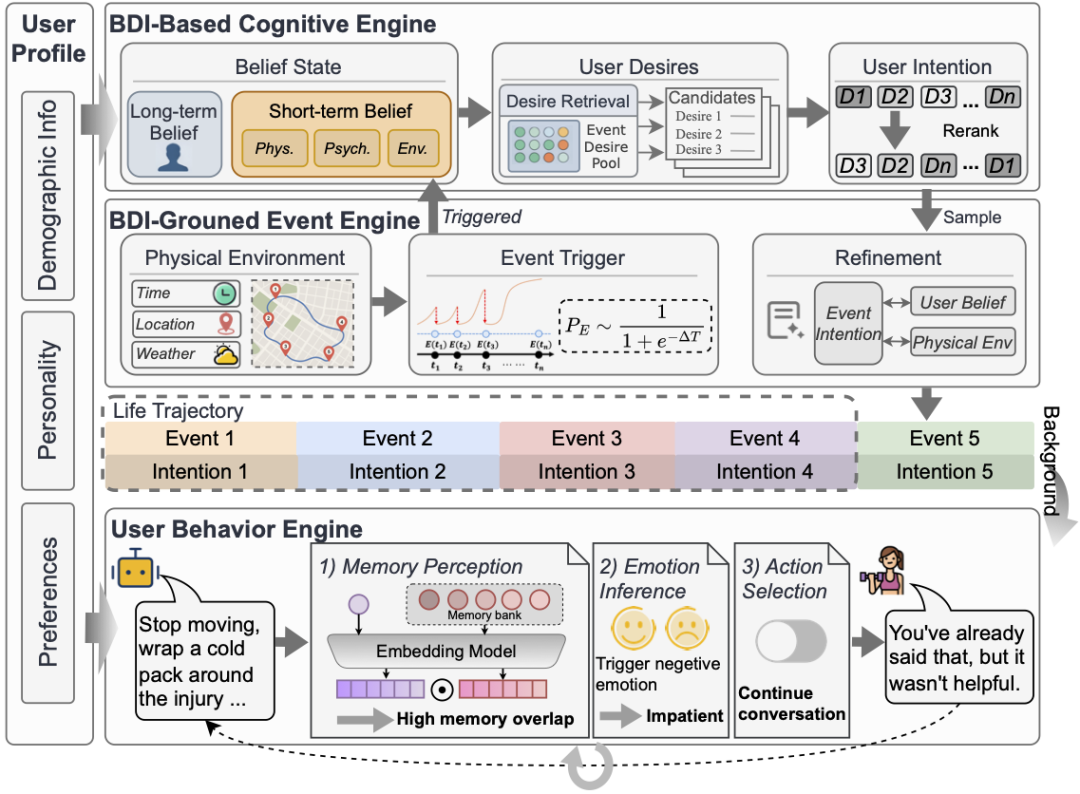
LifeSim: Long-Horizon User Life Simulator for Personalized Assistant Evaluation
作者:段飞宇,黄萱菁,魏忠钰
类别:Findings
摘要:大语言模型(LLM)的快速发展,正加速推动通用人工智能助手的实现进程。然而,现有面向个性化助手的评测基准仍与真实场景下的用户-助手交互存在偏差,无法刻画外部环境与用户认知状态的复杂特性。为弥补这一差距,本文提出LifeSim用户模拟器:该模拟器基于信念-愿望-意图(Belief-Desire-Intention, BDI)模型对用户认知进行建模,结合物理环境生成连贯的人生轨迹,并模拟由意图驱动的用户交互行为。在LifeSim的基础上,本文进一步构建LifeSim-Eval评测基准,一套面向多场景、长时序个性化助手任务的综合性评测体系。LifeSim-Eval覆盖8大生活领域与1200个多样化场景,采用多轮交互方式,评估模型满足用户显式与隐式意图、还原用户画像以及生成高质量回复的能力。在单一场景与长时序设定下开展的实验结果表明,当前主流大语言模型在处理隐式意图与长期用户偏好建模等方面仍存在显著局限。
Strong Reasoning Isn’t Enough: Evaluating Evidence Elicitation in Interactive Diagnosis
作者:龙卓涵,魏忠钰
类别:Findings
摘要:现有医疗对话系统的评估方法大多侧重于静态结果或最终诊断准确性,忽视了在不确定环境中主动获取关键信息的过程。针对这一问题,本文提出了一种面向交互式诊疗的评估框架,从过程层面刻画模型在问诊过程中对临床证据的获取能力。具体而言,我们构建了由模拟患者和基于原子证据的模拟报告器组成的交互环境,并在此基础上提出信息覆盖率(Information Coverage Rate, ICR)指标,用于衡量模型在对话中对必要证据的获取完整性。进一步地,本文构建了EviMed基准数据集,覆盖从常见症状到罕见疾病的多样化医疗场景,并对10种具有不同推理能力的模型进行了系统评测。实验结果表明,强推理能力并不必然带来高效的信息收集能力,而这一缺陷正是制约模型在真实交互诊疗场景中表现的关键瓶颈。为此,本文提出REFINE策略,通过引入诊断验证机制,引导模型主动识别并弥补信息不确定性。大量实验表明,REFINE在多个数据集上均显著优于基线方法,同时能够促进模型间协作,使得小模型在强推理模型的监督下获得更优表现。该工作为构建更加可靠和高效的交互式医疗智能体提供了新的评估视角与方法路径。
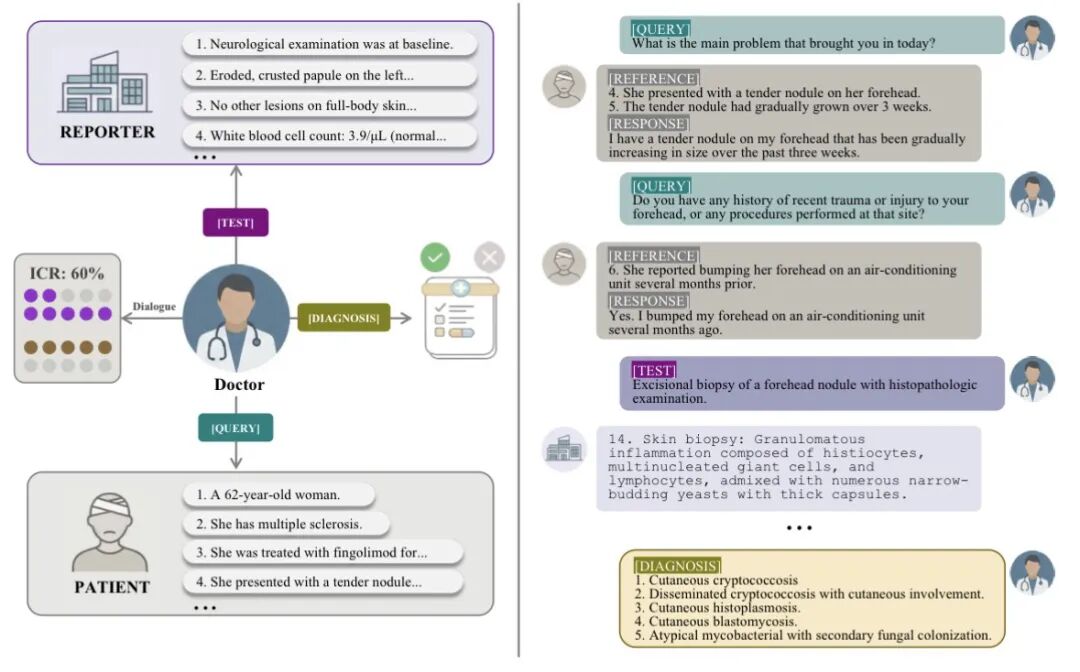
Listen, Pause, and Reason: Toward Perception-Grounded Hybrid Reasoning for Audio Understanding
作者:王洁怡,牛雅哲,徐德轩,魏忠钰
类别:Findings
合作单位:北京大学,上海人工智能实验室
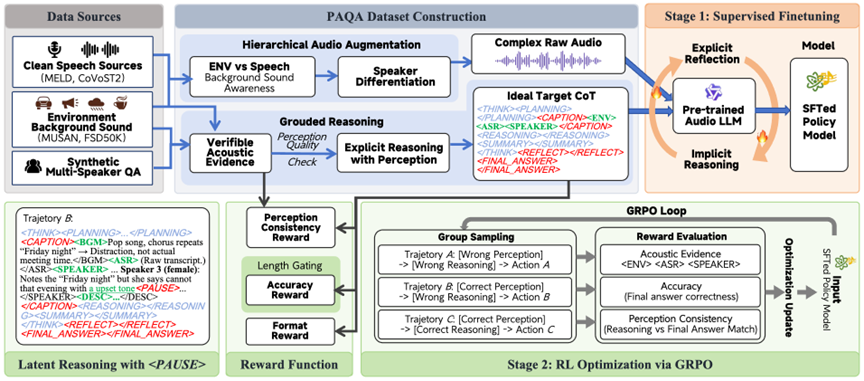
摘要:近年来,音频大语言模型(Large Audio Language Model, LALM)虽然在音频理解上表现优异,但由于常出现感知错误(Perceptual Error),缺乏对结构化听觉场景的准确建模,仍难以实现可靠的音频推理。受听觉场景分析(Auditory Scene Analysis)的启发,本文首先提出了 PAQA,一个面向感知的复杂音频理解问答数据集(Perception-Aware Question Answering),采用分层解耦策略,将语音与环境声音分离,并区分多说话人,为训练提供显式的感知推理过程。在此基础上,进一步提出了 HyPeR,一个两阶段的混合感知—推理框架(Hybrid Perception-Reasoning)。第一阶段在 PAQA 数据集上对模型进行微调,使其能够在复杂音频中感知声学属性;第二阶段利用组相对策略优化(Group Relative Policy Optimization)来改进模型的内部推理过程。我们引入了 PAUSE token,以便在声学模糊阶段促进隐式推理计算,并设计了包含感知一致性奖励在内的奖励函数,使推理依据与原始音频保持一致。总体而言,HyPeR 相较于基座模型取得了显著的绝对性能提升,证实了在噪声环境和多说话人复杂音频场景中,显式思维链推理结合以感知为基础的隐式推理方法的有效性。
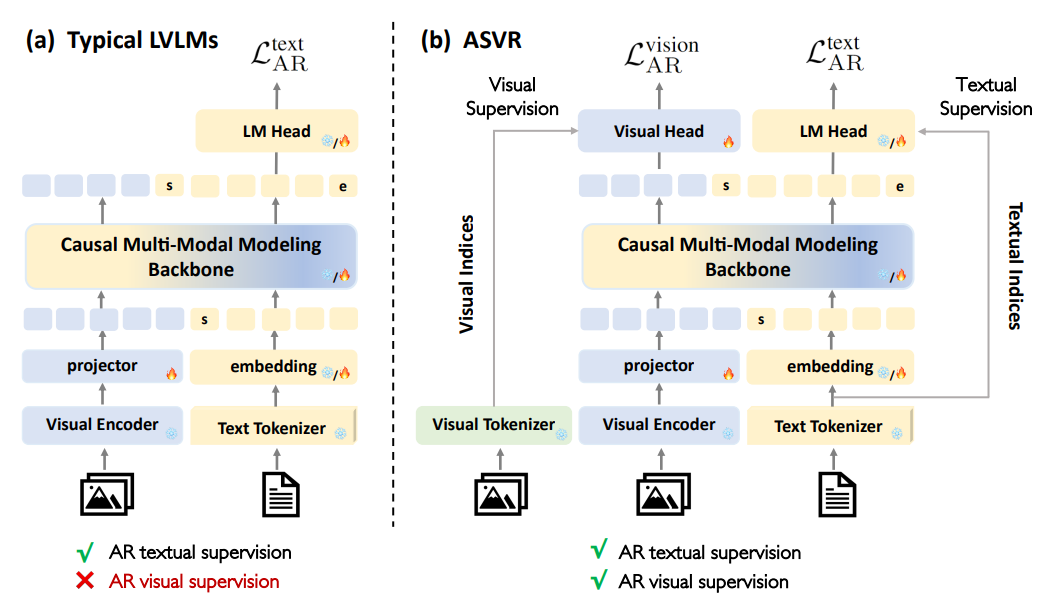
Autoregressive Semantic Visual Reconstruction Helps VLMs Understand Better
作者: 王殿仪,宋为,王艺坤,王思远,于开丞,魏忠钰,王佳琦
类别:Findings
合作单位:上海创智学院
摘要:典型的大型视觉语言模型(LVLMs)主要通过文本响应来应用自回归监督,而未充分利用对丰富视觉输入的因果学习。因此,这些模型通常强调视觉到语言的对齐,但可能忽视了细粒度的视觉信息。虽然先前的研究已经探索了自回归图像生成,但有效地利用自回归视觉监督来增强图像理解仍然是一个未解的挑战。在本文中,我们提出了自回归语义视觉重建(ASVR),它使视觉和文本模态能够在统一的自回归框架内进行联合学习。ASVR训练模型以自回归方式重建输入图像的语义内容,这一过程持续增强了多模态理解。值得注意的是,我们展示了即使在输入为连续图像特征的情况下,模型也能有效地重建离散的语义标记,从而在各种多模态理解基准测试中取得稳定且一致的改进。ASVR在不同的数据规模、视觉输入、视觉监督和模型架构上都能显著提高性能和可扩展性。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区袁天凡、慧敏楼C栋
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢