

从3分钟的Vibe Coding(氛围编程)到30分钟的Agentic Engineering(智能体工程),再到本次我们带来的8小时Long-Horizon Task(长程任务),GLM-5.1再次取得突破。
GLM-5.1是我们迄今最智能的旗舰模型,也是目前全球最强的开源模型。GLM-5.1大大提高了代码能力,在完成长程任务方面提升尤为显著。和此前分钟级交互的模型不同,它能够在一次任务中独立、持续工作超过8小时,期间自主规划、执行、自我进化,最终交付完整的工程级成果。
代码能力是模型智能水平进一步提升的关键。下图是业内最具代表性的三个代码评测基准的平均结果,包括衡量模型专业软件开发工作的SWE-Bench Pro、操作命令行解决问题的Terminal-Bench 2.0、从零构建完整代码仓库的NL2Repo,GLM-5.1取得全球模型第三、国产模型第一、开源模型第一。
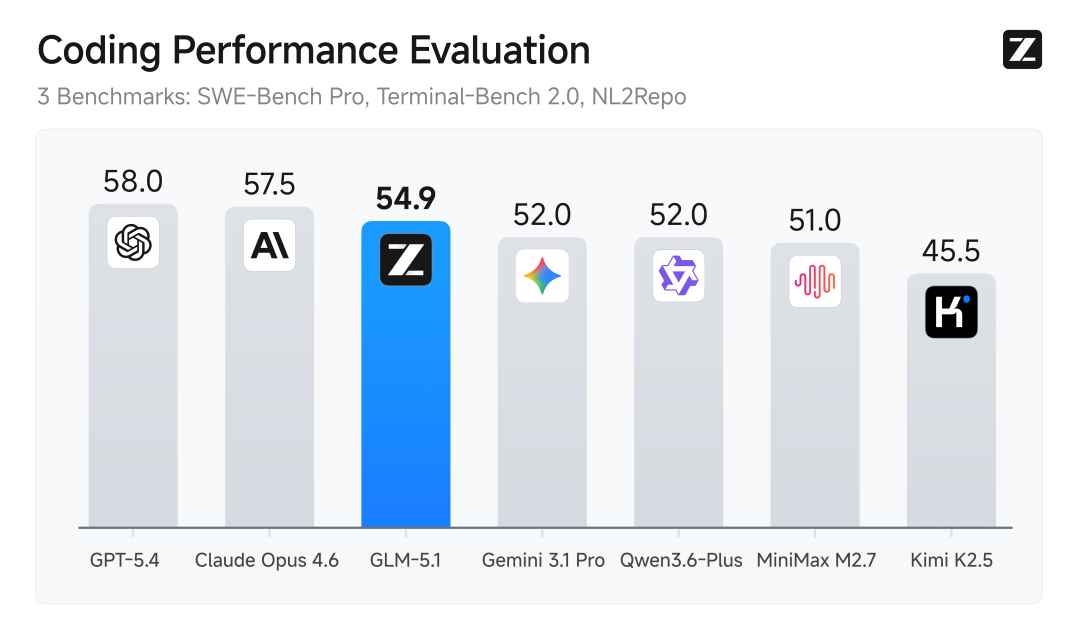
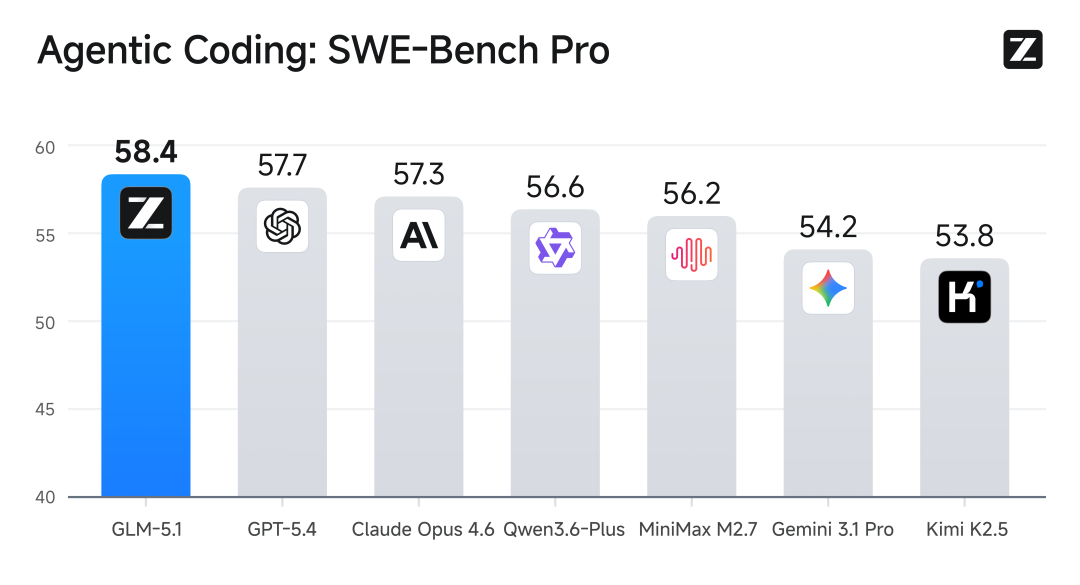
在最接近真实软件开发的SWE-bench Pro基准测试中,GLM-5.1刷新全球最佳成绩,超过GPT-5.4、Claude Opus 4.6。SWE-Bench Pro要求模型在真实GitHub仓库中定位并修复高难度工程Bug,是衡量模型能否胜任专业软件开发的最硬指标。
你睡觉的8小时,是模型上班的8小时
过去两年,行业用Benchmark衡量模型有多智能。我们认为,下一阶段的衡量标准应该是“能工作多久”,即模型在Long-Horizon Task中的表现,能独立完成多长时间的人类任务。
在长程任务中保持稳定输出,模型面对的不只是更大代码量,而是一连串复杂的工程决策点:主动跑benchmark、定位瓶颈、修改方案、再跑测试。这对模型提出更高的要求,需要像人类工程师一样,形成“实验→分析→优化”的完整闭环,而不是写完代码停下来等人打分。
在METR榜单的同等评估标准下,GLM-5.1是唯一达到8小时级持续工作的开源模型,也是全球范围内除Claude Opus 4.6外少数具备这一能力的模型。我们的终极目标是全自治智能体(Autonomous Agent),模型7×24小时不间断地分解目标、执行交付、自我评价与纠正、自我进化,从此无需人类介入。
看看模型的一天8小时工作,都能做些什么。
场景一:8小时从零构建Linux桌面
白天画好架构草图,睡前交给GLM-5.1,早上醒来已产出完整系统。历时8小时整,执行1200多步,20分钟时产生第一个有意义的成果,8小时产出了一套功能完善的Linux桌面系统,包括:完整的桌面、窗口管理器、状态栏、应用程序、VPN管理器、中文字体支持、游戏库等,4.8MB的配套文件,这相当于一个4人团队一周的开发工作量。
以下视频是GLM-5.1在8小时内的代码提交结果:这些不是四五行的小patch,每一次提交都是具有实质意义的系统级演进,而且全程没有人参与测试、审查代码。模型甚至给自己的代码写了一些回归测试,而且跑过了。
场景二:655次迭代打破向量数据库优化瓶颈
向量数据库是AI搜索和推荐系统背后的核心引擎,而近似最近邻检索则是其中非常关键、也非常考验算法与工程能力的一环。这个过程既要求模型掌握IVF、HNSW、向量量化等底层算法知识,也要求它具备真实的工程判断力,能够在一条优化路径碰壁时主动识别瓶颈、切换策略,而不是盲目重复同一个方向。
GLM-5.1不是只会微调参数,而是一路自己完成了从全库扫描切到IVF分桶召回、引入半精度压缩、加入量化粗排、做两级路由,再到提前剪枝的整套优化链条。在655轮迭代里,它持续自主跑Benchmark、定位瓶颈、调整方案,最终把向量数据库的查询吞吐从初次交付的3108 QPS一路推到21472 QPS,提升到初始正式版本的6.9倍。
场景三:1000轮工具调用优化真实机器学习模型负载
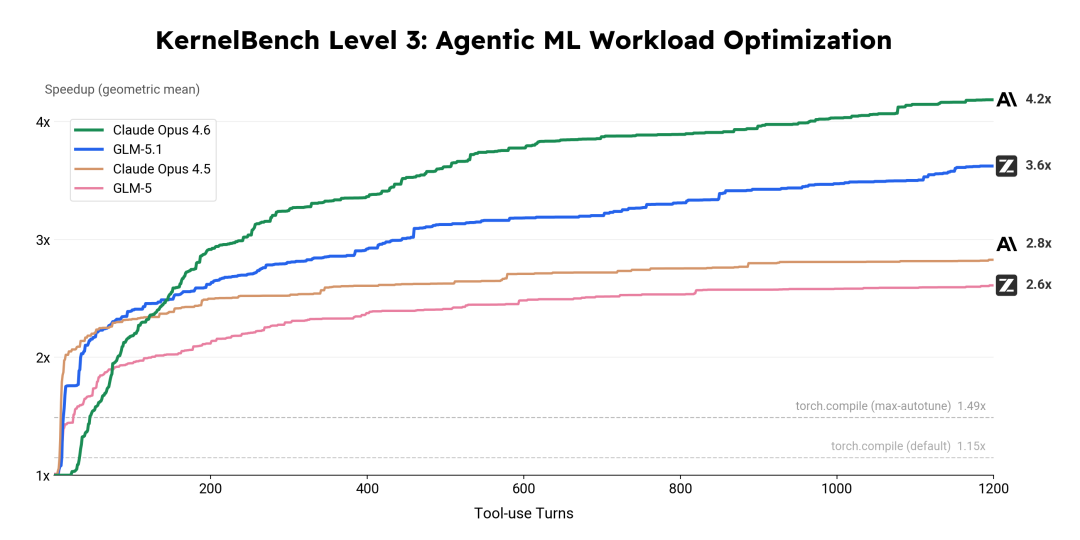
GLM-5.1展现的长时间工作和自进化能力,让其从单纯的“代码生成器”进化为“主动的系统优化器”。我们在涵盖50个真实机器学习计算负载的KernelBench Level 3优化基准上,让GLM-5.1对每个负载独立进行持续优化。在超过24小时的不间断迭代中,GLM-5.1自主完成了多轮编译—测试—分析—重写循环,最终取得3.6倍的几何平均加速比,显著高于torch.compile max-autotune模式的1.49倍。
模型展现出的优化深度与创造力尤其值得关注。GLM-5.1能够自主编写定制Triton Kernel和CUDA Kernel,运用cuBLASLt epilogue融合并实施shared memory tiling与CUDA Graph优化。这些优化策略覆盖了从高层算子融合到微架构级调优的完整技术栈,每一步都是模型的自主决策。
这一结果表明,在GPU内核优化这一传统上高度依赖专家经验的领域,AI模型已经展现出从问题分析、方案设计到迭代调优的端到端自主工作能力。在GPU以及更广泛的高性能计算领域,长期制约工程效率的优化瓶颈正在被AI逐步打破。
Behind the 8h
让模型跑8小时并不难,真正难的是让第8小时的工作仍然有效。
此前包括GLM-5在内的模型,在面对复杂优化任务时,往往在早期快速取得收益后就进入瓶颈期。它们会反复尝试已知的优化手段,但无法在一条路走不通时主动切换策略。
GLM-5.1的训练目标是突破这个瓶颈。在向量数据库优化任务中,我们观察到一个典型的"阶梯型"优化轨迹:模型在一个固定策略内进行增量调优,当收益趋于停滞时,主动分析Benchmark日志、定位当前瓶颈,然后跳转到结构性不同的方案——从全库扫描到IVF分桶,从单精度到量化粗排,从单层路由到两级剪枝。每一次跳跃都伴随着短暂的Recall下降,因为模型在探索新方向时会暂时打破约束,随后再调回来。这个"打破-修复"的循环本身就是有效优化的标志。
在KernelBench上,我们通过对比多个模型的优化曲线,更直接地看到了这个差异。GLM-5在前期上升较快,但很早就趋于平坦;GLM-5.1在同样的时间窗口内持续上升得更久,最终达到了GLM-5的1.4倍。关键在于模型能把"有效优化"的窗口延伸多远。
在Linux桌面构建任务中,挑战又不一样了。前两个场景都有明确的数值指标(QPS、加速比)可以用来衡量每一步是否有效,但构建一个完整的桌面系统没有单一指标,什么算"好"取决于功能完整度、视觉一致性、交互质量的综合判断。这要求模型具备初步的自我评估能力:在每一轮执行后审视自己的产出,判断哪里需要改进、继续优化。这是三个场景中反馈信号最弱的一个,也是当前最需要突破的方向。
我们认为,延长模型的"有效工作时长"是提升智能体能力的一个基础维度。在这条路上仍然有显著的技术挑战:如何克服模型面对复杂任务的上下文焦虑、如何在数千次工具调用后保持执行的一致性、如何更早地跳出局部最优,以及更重要的是如何在没有确定数值指标的任务上建立可靠的自我评估机制。GLM-5.1是我们在这个方向上迈出的一步,我们会持续推进。
GLM-5.1不只是一个更强的模型,而是一种新的技术范式的开启。此刻,尝试给它一个指令,然后离开8小时。
开源与使用方式
1.官方API接入
- BigModel开放平台:https://docs.bigmodel.cn/cn/guide/models/text/glm-5.1
- Z.ai:https://docs.z.ai/guides/llm/glm-5.1
2.产品体验
- GLM-5.1即将登陆Z.ai:https://chat.z.ai
GLM-5.1已纳入GLM Coding Plan(Max/Pro/Lite),支持Claude Code、OpenCode等主流开发工具。
3.开源链接
- GitHub:https://github.com/zai-org/GLM-5
- Hugging Face:https://huggingface.co/zai-org/GLM-5.1
- ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-5.1

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢