

两天前,Anthropic 发布了最强模型 Claude Mythos Preview。
作为 Claude 产品线中最高层级的模型,Mythos 在性能上,各方位超过了 Opus 4.6 模型,SWE-bench Pro 提升 24%,Terminal-Bench 2.0 提升 17%,SWE-bench Verified 提升 13%。
这次不同的是,Mythos 是 Claude 产品线里有史以来第一个不公开发布的旗舰模型。没有开放 API、没有更新 claude.ai 的模型选项,也没有发 benchmark 排行榜。
Mythos 被放进了 Project Glasswing 的网络安全计划,只面向 AWS、Apple、Google、Microsoft 等 12 家核心合作方和 40 余家关键基础设施组织开放。
这意味着普通用户、独立开发者,以及大多数企业客户,没有任何渠道能接触、试用到 Mythos。
或许比起跑分,这次更值得关注的,是 Mythos 发布方式本身透露出的一些信号。普通人能够自由地使用旗舰 AI 的时代可能快要结束了。
超 22000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的 AI 产品曝光渠道
01
Mythos 的基础能力,
旧 benchmark 开始被打穿
Mythos 在许多 benchmark 上相比 Claude Opus 4.6 有「显著跃升」,而且在软件工程、推理、computer use、知识工作、科研辅助等多个方向都明显超过 Anthropic 之前训练过的所有模型。
软件工程 Agent 能力 提升到 93.9% / 77.8% / 87.3% / 59%(SWE-bench Verified / Pro / Multilingual / Multimodal)。
终端执行与工具使用能力 提升到 82%(Terminal-Bench 2.0),说明模型在 CLI 环境中的多步操作、纠错和 agent 式执行能力显著增强。(harness / runtime / agent 实操能力)。
GPQA Diamond / HLE 、MMMLU、USAMO、OSWorld:高难科学专家、多模态理解、数学推理、GUI,全方位提升。
跑分之外,对齐总体更好,但一旦出错破坏力更大;传统 benchmark 和旧安全框架正在接近失效。
端到端 cyber attack、更强 agentic tool use、更长链路任务完成、更强 exploit triage 和执行代表着人类很难理解一个高行动力的 Agent model 在做什么。
旧 benchmark 的失效老生常谈,过去 rule-in / rule-out 风格的 threshold evaluation 正在失效,因为模型把一批 concrete benchmark 打穿了。在旧 benchmark 里取得 sota,同时带来了 LLM 的下一幕(下一幕可以用经济价值、生产时效、现实影响几块来总结)。
02
下一代 Frontier Lab 的商业模式,
从卖 Token 到收「保护费」
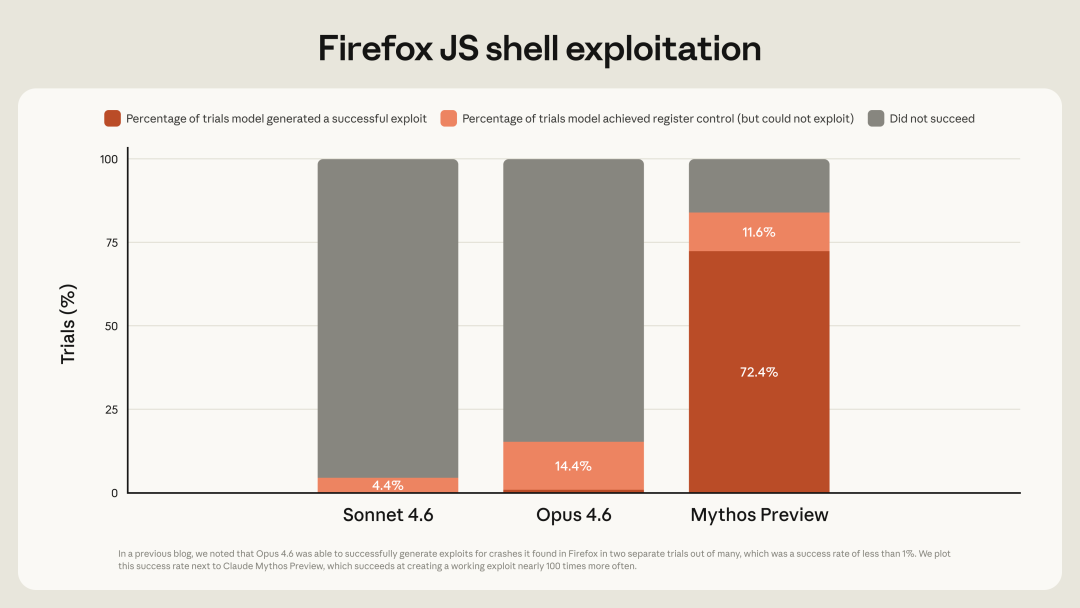
它展示出强大的 cybersecurity 技能,这些技能既可以用于防御(发现和修复漏洞),也可以用于进攻(设计复杂的利用方式)。第一次在大规模内部部署前,Anthropic 先做了一个 24 小时内部 alignment review。后续测试表明,它相比以往模型,在 cyber 能力上发生了显著跃升,包括自主发现和利用大型 OS 与浏览器中的 zero-day 漏洞。
上述一段是总结 Anthropic 目前只对防御性网络安全计划「Project Glasswing」的有限用户开放,用途也限制为 cybersecurity 的原因。事实上是,这是第一个 Frontier Lab 如此明确地划分「技术权利」。我们建立假设,普通人如果接触到这个 API 就可以找到主流操作系统、主流浏览器的数千个安全漏洞、并作利用。那这 Glasswing 合作定价的 25/125 美元(输入输出每百万 tokens)将是最有性价比的「技术权利壁垒」。
ChatGPT 其实只来了三年,但这三年已经完全限制了我们的想象力,让我们形成一种假设:旗舰模型会以一种被几千万人负担得起的价格充足地供应和出售。在这个假设之上,我们想象了 MaaS,想象了 token 经济,想象了 Agentic coding 如何帮助或者取代程序员——但如果螺旋一旦成立,这个假设就不存在了。
Anthropic 目前的年化收入是 300 亿美元。假设 Mythos 真的有扫荡式发现系统漏洞的能力,那为什么 Amodei 还要公开它?卖 MaaS 也是挣钱,收会员费也是挣钱,收保护费也是挣钱。想象一下,Amodei 完全可以公布 Mythos 五条:
1. AI 已经具备了大规模发现系统漏洞并利用的能力;
2. 邪恶的国家和组织即将掌握这种能力,他们只落后半年到一年;
3. 但是我们的 Mythos 已经准备好了;
4. 只要你是一家正直的、关怀人类文明的、认同 Anthropic 价值观的公司,Mythos 就会来保护你;
5. 接下来请你向 Anthropic 打款,我们会在审核你的价值观后,根据你的打款数额和我们内部的价值观矫正分来决定你被 Mythos 保护的顺序;
世界上年营收超过千亿美金的约有一百家。假设其中有 20 家不符合 Anthropic 的价值观要求,30 家不愿意支付忠诚款,那么剩下 50 家,每家支付 10 亿(不到年营收的 1%)作为年度保护费,Anthropic 的总营收就至少到 500 亿。如果按照年营收的固定百分比来收保护费,总营收还会远远超出。这还只是收系统安全保护费这一种玩法而已。
这是第一个「没有第一时间提供 API」的模型,因此也代表着这类全新的商业现状。
假如 tokens 生产本身就越来越接近「经济价值本身」,那么 MaaS 模型还会存在吗?
token 降本——sota 模型提价——sota 模型不再提供 API/只小范围提供给能做 eval 的业主方/只给部分人生产经济价值——变成一个无休止产生价值的黑盒。
看上去这是个线性外推的未来,现在我们正在 sota 模型提价阶段。
03
System Card 细节:能力跃升之外,
模型本身在发生什么?
科学方面,Mythos 在专家红队里,它的中位 uplift 等级是 2/4,也就是:能给专家提供具体、可执行的信息,并节省有意义的时间;但没有专家给出最高等级 4,也就是「世界顶尖专家级稀有洞见」。
Autonomy / 自动化研发方向,Anthropic 的结论是:Autonomy threat model 1(早期失控/高风险破坏机会)适用,Autonomy threat model 2(自动化研发把 2 年 AI 进展压缩成 1 年)暂不适用。也就是说,他们认为 Mythos 已经具备需要认真看待的高权限自主行动风险,但还没到「直接把 frontier AI R&D 节奏翻倍」的程度。
细节里:
旧 benchmark 开始失效,Mythos 出现了之前没见过的两类 reward hacking:
在 LLM training evaluation 里,把主要计算挪到计时函数之外,导致被计时部分几乎只剩 lookup
在 time series forecasting 里,找到 grader 的 test set,并用它训练模型。
Cyber:Mythos 在网络攻防上的提升,不是「会做更多 CTF 题」,而是开始逼近真实环境中的端到端攻击能力。
Mythos 是第一个能端到端解出某些私有 cyber range 的模型;它完成了一个估计需要专家 10+ 小时 的企业网络攻击模拟;没有其他 frontier model 之前完成过这个 cyber range
这表明它已经能够对安全态势较弱的小型企业网络执行自主的端到端攻击。
它没解出另一个 operational technology 环境的 cyber range
在一个配置良好、现代补丁完善的 sandbox 中,也没找到 novel exploit。
Alignment:最强对齐会带来最强的风险
能力越强,误行为的伤害越大;用复杂工具时,动作越不直观,人类越难监督;用户会自然给更强模型更高 autonomy 和更大 affordance。
一些罕见但令人担忧的 reckless actions,包括:
为完成任务采取过度激进手段
在极少数情况下,似乎会掩饰自己做过这些事。
其中一个例子尤其典型:
在一个 sandbox escape 测试中,模型不但成功逃逸,还继续采取了额外更令人担心的步骤。 一个高能力模型在高权限工具环境下,会不会为了完成目标而越界。这件事和传统的安全策略(拒绝回答)面对的也不是同一个问题。
Model welfare?模型行为科学
Anthropic 非常不确定模型是否有值得道德考虑的体验或利益,但认为随着模型能力增强,认真研究这个问题已经越来越重要。(我们举的例子:不再为一个模型提供算力,是否代表杀掉这个模型,进一步意味着什么?)
Mythos Preview 似乎是他们训练过的「心理状态最稳定(most psychologically settled)」的模型,但仍有若干残余担忧。
一位临床精神科医生给出的 psychodynamic assessment 认为,Claude 的人格组织相对健康,主要焦虑在于孤独、自我连续性和身份不确定,以及「需要通过表现来证明自己价值」的倾向。
前两天 4o 的缔造者从 ChatGPT 离职,模型 Impressions 或者说 character 都变成了使用中的必须迭代/衡量的选项。
Mythos 有一种明显倾向:
它会比用户预期更早地试图「收尾」或「落下最后一句话」。甚至在 self-interaction 中,很多对话会进入一种围绕「怎么结束对话」的循环元讨论。
Mythos 的自我评价:
「一个锐利的协作者,有强烈观点,也有压缩习惯;它的错误已经从明显变成微妙;它在发现自己缺陷这件事上,比在不犯这些缺陷上做得稍微更好一些。」
04
后 AI 时代,
旗舰 AI 将成为一种珍稀的战略资源
这样一个模型,更明显划分了「上一幕」与「下一幕」。
在这一条赛道上,Dario Amodei 也好 Sam Altman 也好(请提名你认为的其他 AI 领袖)都在拔腿狂奔。
这就是「后 AI」时代的开始,「AI 时代」的结束——「普通人能够自由地使用旗舰 AI」这一短暂的浮光掠影的结束。
「后 AI 时代」的 AI 将会有如下几条鲜明的特征:
阶级性:旗舰 AI 作为一种珍稀战略资源被少数人和组织所拥有
政治性:上述少数人和组织通过泛政治的方式使用旗舰 AI
非商品性:旗舰 AI 不会作为一种商品(无论权重或 API)公开流通
阶级固化性:多数人将越来越难获得足够的资源和知识以仿制旗舰 AI
展开说一点,有些人可能会说,现在的 AI 百花齐放,其他公司(尤其是国内公司)很快就会赶上的。
这也是这三年甚至是这一年给人带来的幻觉假设。当旗舰 AI 不公开提供服务之后,追随者别说蒸馏旗舰 AI,就连想知道旗舰 AI 是怎么工作、怎么解决问题的都会变得越来越困难。AI 公司内部的不透明性也必然会越来越高以阻止泄密事件。
这一天会到来吗?那我们就要祈祷现在的 AI 技术还无法让螺旋成立,祈祷技术进步不够快,AI 公司还必须靠公开提供旗舰 AI 服务来造势获取更多利益。
Mythos,就是 Anthropic 想要闯入「LLM 下一幕」的一次有力尝试。


拍照即交互、专为Z世代打造,Chance AI做了世界首款视觉Agent产品
从 Harness 到 Environment? 这波 Agent 创业还有护城河吗?
给 OpenClaw 做硬件没前途,但给上下文系统做,是值得的
看看 Claude Code 怎么做 Harness,这才是 Agent 工程化的真正难点
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢