
1. 概述
在淘宝的各种营销活动中,选品是决定活动效果的关键环节。传统的选品模式依赖小二手动梳理行业趋势、制定圈品商品规则后在选品后台圈品,存在以下问题:
选品过程复杂低效:小二需要去外部检索行业趋势等信息,并结合自身的圈选经验,将其转化为平台固定的规则筛选条件,选品过程较为低效。
选品相关性无法保障:主要通过人工经验+行业类目限制,限定品类范围,无法实现场景化需求,例如情人节、端午等节日心智货品。
选品质量低:卡动销、GMV等圈品方式,缺少销量预测、品类规划等能力,无法做到品效最大化。
随着大模型技术的快速发展,自然语言理解、信息检索整合及智能决策能力为选品流程重构提供了新路径。基于LLM的AI选品系统可自主解析一句话的自然语言需求,联动外部行业趋势洞察,通过关键词商品召回,粗筛和精筛策略,生成高相关性、高潜力的选品集。新的选品途径不仅缩短了人工选品的周期,还大幅提升了选品质量。

作者:锦彦、翊臻、子鑫、修勾、离宵、樱木
2. 选品大模型

选品算法框架
大模型选品在淘系商品池内选出一个优质选品集,将面临以下挑战:
联网搜索:需要尽可能多的涉猎时效信息,以满足用户的发散需求下,广而新的选品集创建。
适配淘系商品搜索引擎:让LLM能够生成召回能力强的搜索词,召回又多又好的商品池
LLM选品过程拆解
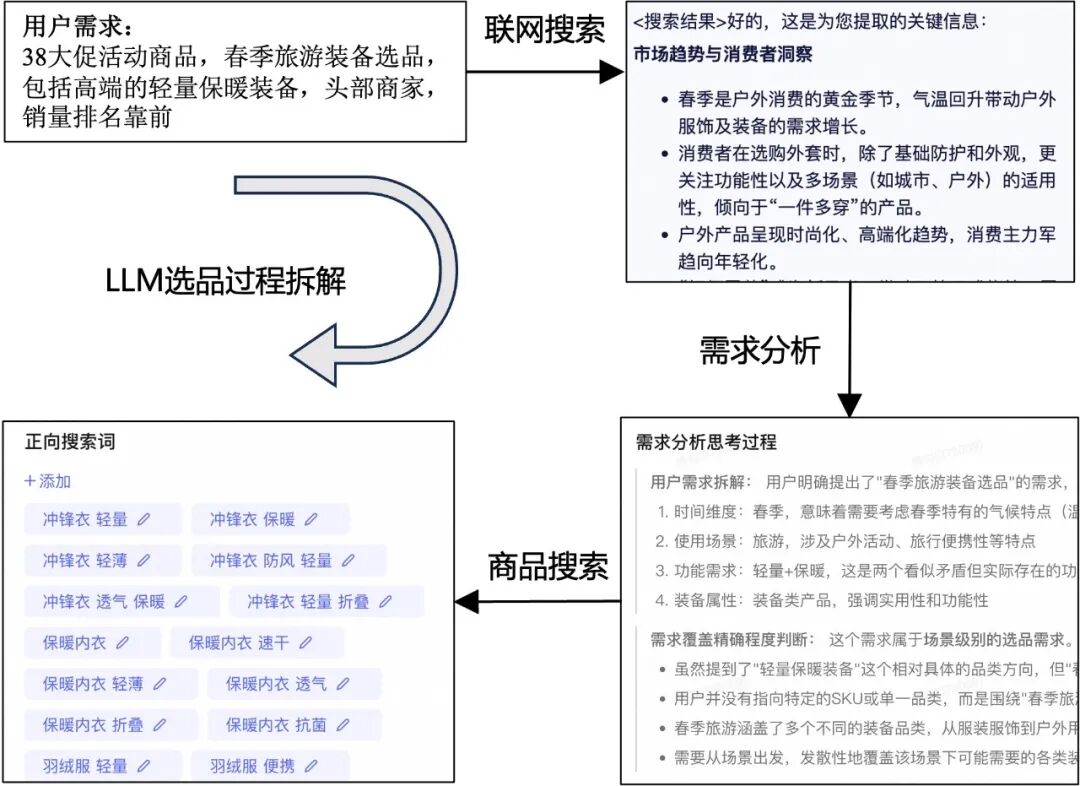
对此,营销算法团队联合未来生活实验室,自研与淘系电商知识交互相关的LLM,提供更加智能的大模型选品服务,帮助小二高效的选品。包含以下关键流程:
联网搜索:LLM生成联网搜索计划,从互联网补充丰富的时效信息。
生成商品搜索词:基于联网信息和LLM自身的世界知识推理电商搜索词,并通过强化学习(RL)优化生成更适合淘系场景的搜索词,用于主搜引擎和U+选品引擎召回商品。
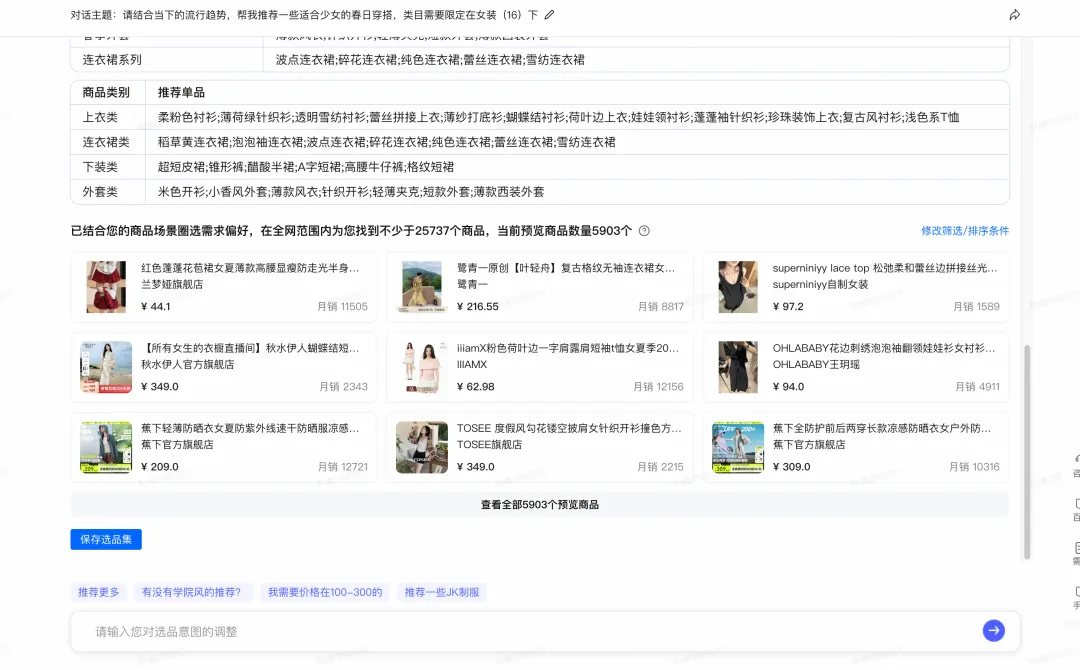
2.1 联网搜索LLM
2.1.1 多轮联网搜索--提升联网信息广度
目标:对于用户的选品需求,联网获得外部相关数据,获得行业发展趋势和热点信息,使得电商推荐内容更加丰富,更具备时效性。
挑战:对于发散性较强的选品需求,单次联网搜索信息深度不足。为提升联网检索信息的广度和深度。我们设计了两种算法方案:
方案一:DeepSearch
DeepSearch是一种迭代式信息搜索方案,LLM多轮反思能力的增强让DeepSearch获得了较大的关注和发展。DeepSearch的核心是通过不断循环执行搜索,阅读,推理三个基本动作,直至挖掘出最优答案。
搜索:利用网络搜索引擎,探索互联网上的资源和信息;
阅读:读取特定网页或文档的内容,提取关键信息;
推理:综合评估当前的搜索状态,分析已有信息的质量与相关性,并据此决定下一步的行动方向(ReAct)。
引入DeepSearch方案替换当前单次搜索方案,大幅提升了信息检索的深度和广度。但实验过程中发现,DeepSearch存在以下几个问题:
循环轮数无法控制:选品需求不存在一个标准的答案,DeepSearch方案难以判断什么时候结束搜索,对于比较发散的需求,可能会进行五次及以上的循环搜索;
RT过高:通用的DeepSearch方案,三轮循环搜索耗时高达140+s。
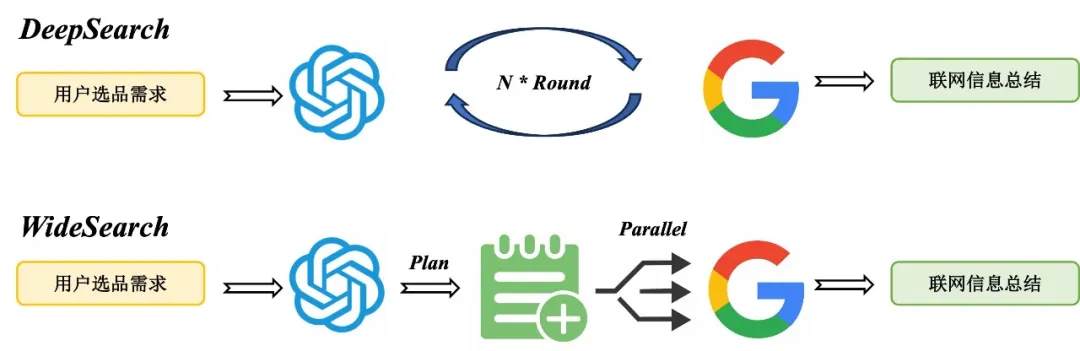
方案二:WideSearch
DeepSearch方案比较适合在RT可接受的场景下,解决一些精确的问题。对选品需求做联网搜索的关键是在较短时间内检索尽可能多的电商相关信息。借鉴Agent系统里Plan-And-Execute执行逻辑,我们设计了WideSearch算法方案,包含以下两个关键模块:
DeepSearch vs WideSearch
Plan:设计搜索计划,对于一个选品需求,设计一个多步的联网搜索计划,每一步产出一个搜索词
Parallel Search:对于整个计划里的所有搜索词做并行搜索
WideSearch VS DeepSearch 示例:
2.1.2 联网结果清洗--提升联网信息密度
一次联网搜索的结果里会包含部分重复和无关的搜索信息,升级为多次联网搜索后,重复信息的比例也会提升(信息冗余度高),直接将多次搜索的结果作为上下文输入给LLM,容易让LLM产生幻觉。
参考perplexity/夸克的AI搜索方案,我们将联网搜索的多个结果,提炼整合后生成一段总结性的文本,传入LLM的上下文中,避免了需求分析过程LLM上下文中充斥大量原始搜索噪声的问题。
联网搜索结果清洗示例:
2.1.3 搜索效率对比
我们设计的这一具备电商理解特性的搜索工具,具有多源检索和信息密度高的特点。我们把这套工具开放成了Skills/MCP,在内部淘宝闪购、阿里妈妈、阿里国际等业务广泛应用。
2.2 需求分析&搜索词推理LLM
需求分析&搜索词推理的目标是,基于用户输入选品需求+外部联网搜索的结果,生成符合用户需求的商品搜索词。
2.2.1 样本构造
由于真实样本稀缺,我们通过以下pipeline构造了1w条样本,样本构造主要有以下3步:
Multi-Agent协作样本生成:对于用户的选品需求,由联网搜索Agent,需求分析Agent,搜索词推理Agent协作构造“选品需求分析+搜索词推理”的训练样本。

质量筛选:基于LLM-as-a-Judge,筛选高质量样本,对于低质样本反馈重构,提升单条样本质量,通过率75%。
语义去重:基于Semantic Hash做语义去重,降低SFT数据集的冗余性,提升整体数据集质量,过滤掉占总体30%的冗余。
2.2.2 SFT
基于上述构造的搜索词推理样本,我们分别探索了SFT、RL的模型训练方法。在将SFT模型预发部署后我们发现,LLM生成的淘宝搜索词与主搜匹配度低,34%的搜索词搜出来的商品数量<100。发现是SFT后生成的搜索词与淘宝真实用户的搜索习惯存在差异:
LLM搜索习惯:全面,倾向于把 筛选条件、详细的描述信息 加入搜索词。
用户搜索习惯:精准又简洁,倾向于得到高质量(热门品牌,高GMV,高销量)的商品搜索结果。
总结:本质上,SFT是一个离线学习搜索词推理的过程,实际上并没有让LLM与搜索引擎去做真正的搜索交互。且选品的商品召回词和用户淘搜习惯上也存在差异。将离线学习的过程改成基于RL的在线学习,可以解决这类问题。
采用SFT训练的Tbstars-42B-A3.5B作为RL阶段的Actor-LLM,基于GRPO算法训练搜索词生成LLM,GRPO相对于SFT具有以下两个优点:
不依赖高质量Label标注:RL阶段不需要标注高质量的搜索词标签,依赖Reward信号区分不同搜索词之间相对的好坏。
point-wise vs list-wise:SFT阶段一条样本一次只学习一个正样本,RL阶段可以学习一组Rollout的奖励偏序关系,学习效率更高
Reward定义
将淘宝搜索作为工具,LLM完成搜索词推理后,完成一次真实的搜索调用,计算搜索结果的质量分作为Reward分数,进而实现在线优化搜索词推理过程。直观上,一个好的搜索词,在保障搜索的商品与搜索词相关的前提下,应该搜到尽可能多的商品。基于此,我们从以下几个方面设计了搜索词的Reward分数:
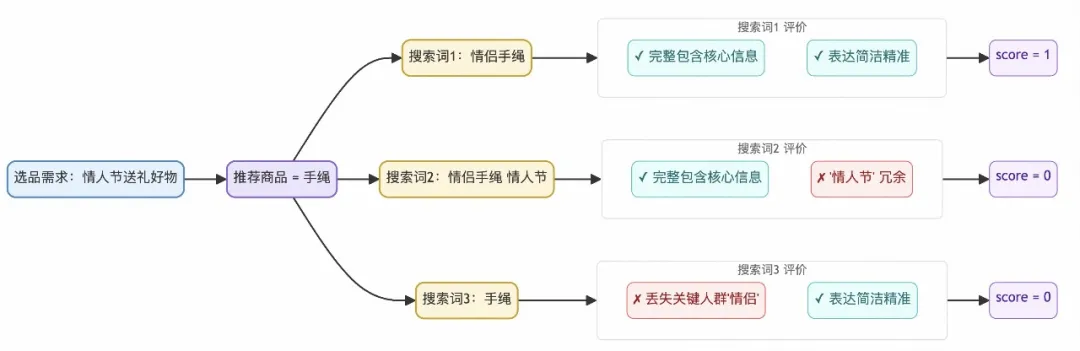
搜索词的语义完整性和简洁性(Semantic score):基于LLM-as-a-Judge,SFT了一个7B的小模型,评价一个搜索词语义本身是否简洁且完整。示意如下:
用户需求与搜索商品的相关性(Relevence_score):评价搜索词、商品title的文本相关性。基于BGE模型提取的embeding向量,点乘获得文本之间的相关性:
搜索商品数(Quantity score):评价一个搜索词在主搜里检索商品的广度。即能搜到的商品数量越多,奖励越大。RL过程中,发现训练前期Reward爬坡(warm up阶段)比较缓慢,因此引入 课程学习 机制,在训练初期,对于搜到商品数量比较少的搜索词,也会给与较大的奖励,随着迭代的step增加,增加获得奖励的难度。奖励方法为:
其中
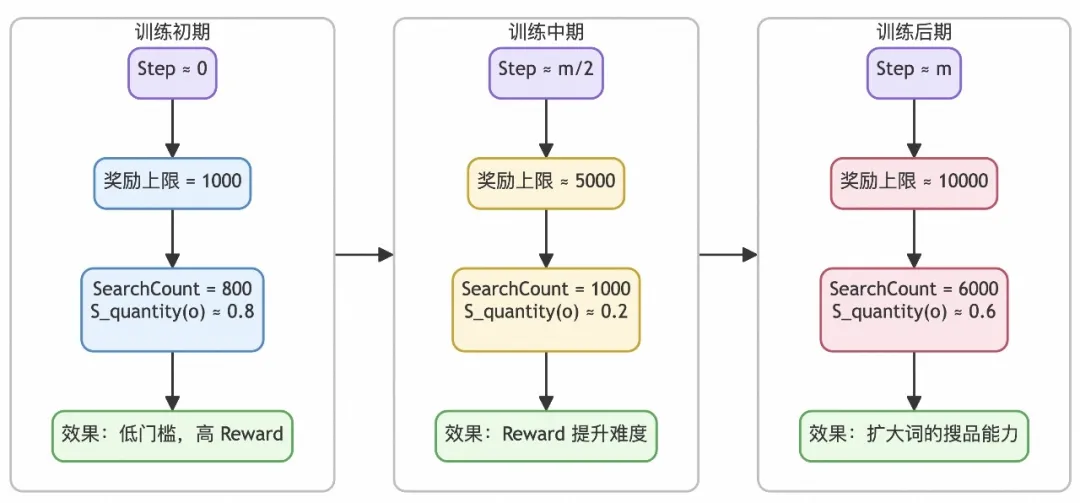
总的训练过程:
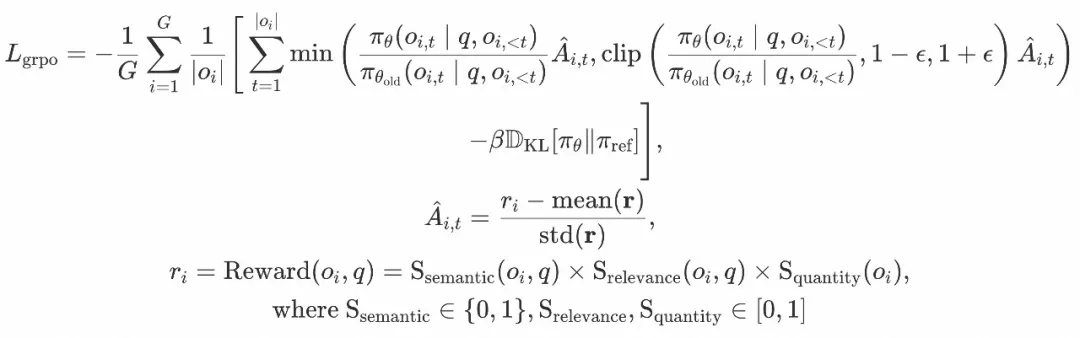
Case-Study:经过RL的训练,模型在大幅提升了搜索词圈品能力的同时,发现整体回答的长度也获得了优化,即顺带优化了模型infra阶段的RT。

2.2.4 DeepSearch For 选品--不仅仅是搜索词
上一节中,我们基于在线的强化学习方式提升了搜索词本身的圈品能力。但是选品集的产出并不仅仅是多个搜索词之间1+1=2的过程,一个选品集是由多个正向词召回商品后union在一起,再叠加负向词的过滤效应后产出的。下图展示了从选品策略到生成选品集的过程:
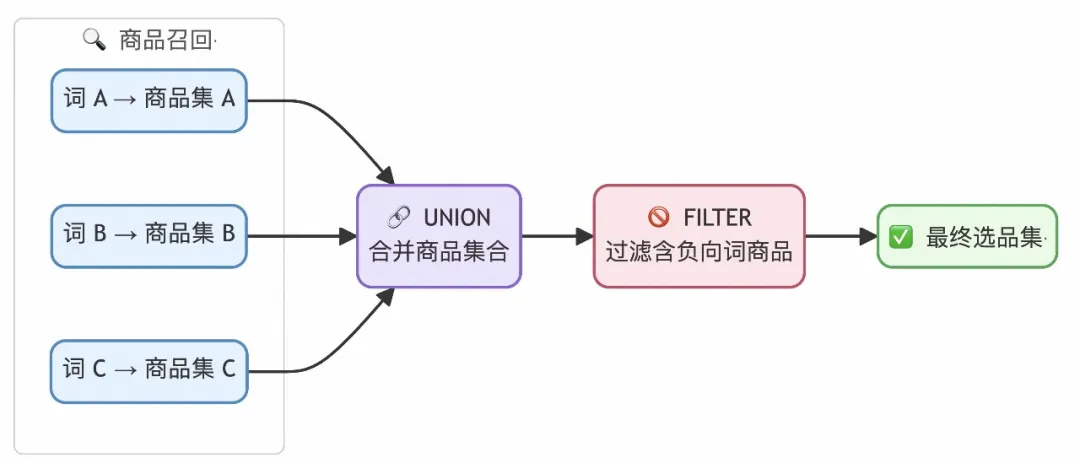
基于上述选品机制,现有的选品大模型会出现以下问题:
SearchRL优化只能对单个搜索词的搜索质量做优化,难以对整个选品集完成建模,且无法叠加负向词的过滤效应;
不同正向词之间会存在overlap,例如"多汁 水果"和"多汁 西瓜"都会召回"多汁的水果西瓜";
可能会出现商品多样性不足,少数正向词不合符用户需求,负向词误杀商品的现象...
{ "negativeSearch":["果酱","汁","果泥","果脯","蜜饯","罐头","冻干","零食","饼干","蛋糕","饼干","派","布丁"], "positiveSearch":["凤梨","哈密瓜","奇亚籽","山楂","山竹","提子","无花果干","李子干","杨桃","柚子","柠檬","柿子","桑葚","油柑汁","海苔","火龙果","猕猴桃","甘蔗","甜瓜","白兰瓜","百香果","石榴","砂糖橘","碧根果","芒果干","荔枝","莲雾","菠萝","葡萄","蓝莓","蔓越莓干","西柚","西瓜","金桔","雪梨","青提","马蹄","黄皮果"]}问题:- 正向词问题:绝大部分的正向词满足需求,但是少数词如"碧根果,芒果干"跟清爽水果没啥关系- 负向词问题:绝大部分的负向词满足需求,但少数词如"汁"本意可能是过滤"果汁"类商品,却会误杀大量正向的水果,如"多汁葡萄"Agentic RL优化
参考Search-R1的Deep Search过程,把选品策略预览做成一个工具,输入是正负向选品词,输出是预览结果。对于用户输入的选品需求,LLM先生成第一轮选品策略,然后基于该轮策略的reward,调整生成下一轮的选品策略。
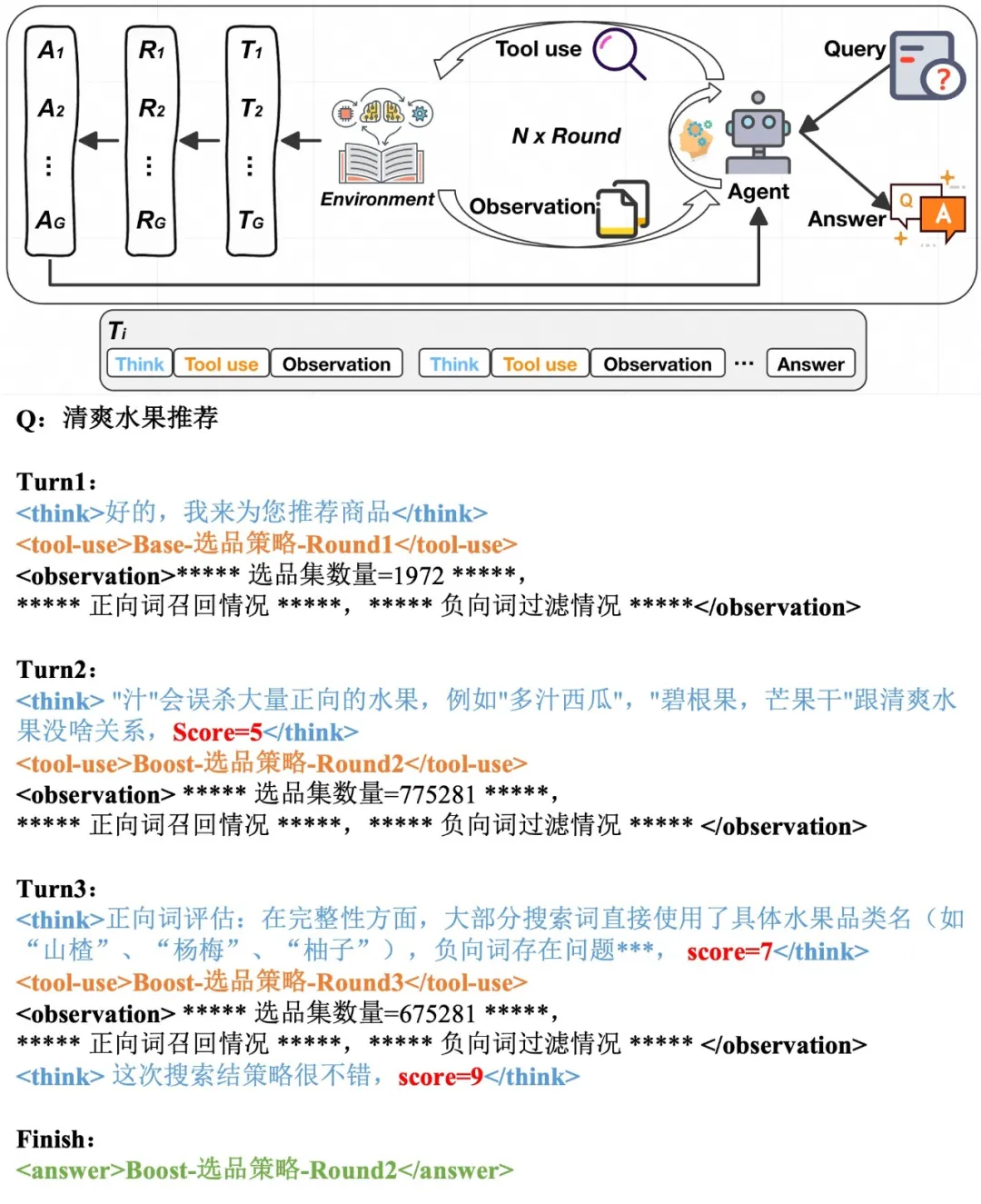
DeepSearch过程示意图
从生成首轮选品策略到完成最终的选品称为一条轨迹,可以通过Agentic RL算法,对轨迹进行优化。Agentic RL训练过程中,每条轨迹都会需要做多次选品策略的预览。基于全量商品(40 亿+)进行预览的资源消耗过高,而轨迹优化的核心仅在于体现不同选品策略之间的差异,而非还原真实的预览过程,因此我们从大盘中随机抽取了一部分商品,构建了一个轻量级的 TinyPreview 工具用于选品预览。完成预览后,再通过大模型对选品策略及其预览结果进行评估,最终生成对应的 Reward Score。
=====Step-1. LLM生成的选品策略====={"negativeSearch":["果酱","汁","果泥","果脯","蜜饯","罐头","冻干","零食","饼干","蛋糕","饼干","派","布丁"],"positiveSearch":["凤梨","哈密瓜","奇亚籽","山楂","山竹","提子","无花果 干","李子干","杨桃","柚子","柠檬","柿子","桑葚","油柑汁","海苔","火龙果","猕猴 桃","甘蔗","甜瓜","白兰瓜","百香果","石榴","砂糖橘","碧根果","芒果干","荔枝"," 莲雾","菠萝","葡萄","蓝莓","蔓越莓干","西柚","西瓜","金桔","雪梨","青提","马蹄","黄皮果"]}=====Step-2. 选品预览=====预览结果(展示详情):> ✅ **总召回商品数量:xxxx*** 召回量Top0-50%的词:[葡萄,柠檬,马蹄,荔枝]* 召回量Top50-90%的词:[西瓜,石榴,菠萝,蓝莓,柿子,山楂,柚子,桑葚,提子,甘蔗,雪梨,凤梨,百香果]* 召回量Top90-100%的词:[火龙果,猕猴 桃,西柚,青提,海苔,奇亚籽,金桔,甜瓜,哈密瓜,山竹,无花果 干,杨桃,莲雾,碧根果,砂糖橘,油柑汁,蔓越莓干,芒果干,黄皮果,李子干,白兰瓜]> ❌ **总过滤商品数:xxxx*** 过滤量Top0-50%的词:[零食]* 过滤量Top50-90%的词:[果 酱,果脯,冻干,蛋糕,蜜饯]* 过滤量Top90-100%的词:[饼干,罐头,派,布丁,果泥]=====Step-3. 选品评价====={"reward": "分析报告:1. 正向词评估:【相关性-严重不足】'海苔'不是水果,与用户需求完全不符;'碧根果'、'奇亚籽'也不属于水果范畴。【简洁性-不足】'无花果 干'、'李子干'、'芒果干'、'蔓越莓干'等包含'干'字,但用户需求未明确要求干果类;'猕猴 桃'存在多余空格;'油柑汁'偏向饮品而非水果本身。【完整性-不足】整体策略过于宽泛,直接枚举各类水果名称,缺乏对用户具体需求的理解,且包含了不应该出现的非水果品类。【多样性-中等】虽然词汇数量多,但基本都是水果名称的简单罗列,缺少基于用户真实需求的策略思考。2. 预览结果:数量满足,但正向词中包含'海苔'、'碧根果'等非水果类商品,存在严重相关性问题;过滤策略合理,有效去除了果酱、果脯等加工程度较高的产品。", "score": 4}实验结果
类似于2.3.1节,我们首先基于 Multi‑Agent 流程构造了约 5k SFT 样本,对基础模型(Tbstars‑42B‑A3.5)进行冷启动训练,使其适应多轮反思和策略增强的生成模式。在此基础上,依托集团自研的 ROLL 框架(图 a),基于17k无标注的样本,完成了高效的Agentic RL训练。
在训练的过程中,Reward曲线稳定上升(图b),说明模型在多轮思考与调整后的选品质量逐步提升。同时还观察到工具调用频次呈下降趋势(图c),意味着LLM思考调整的效率获得了提升,频次的降低还一定程度上优化了RT。

a. ROLL训练框架

b. reward

c.tool-use-counter
| 模型版本 | First-Turn Reward | Final Reward | Improvement | Average Turn | Max Reward Turn | High-Reward占比 |
|---|---|---|---|---|---|---|
| 31% | ||||||
| 6.2 | ||||||
| tbstars-42B-A3.5B-ds-rl | 5.6 | 6.2 | 2.7 | 1.5 | 35% |
Tips:Baseline是SearchRL方案下最优的单轮选品模型,ds-sft代表模型经过了DeepSearch模式的SFT训练,ds-rl代表模型经过SFT冷启动后经过了Agentic RL的训练
根据上表的实验结果,我们可以发现以下几个有趣的现象:
DeepSearch方案,SFT和RL都可以提升首轮选品质量(First-Turn Reward);
RL对首轮选品的提升尤为显著,42B-A3.5模型经过RL优化后,性能可以跟SFT后的Qwen-2.5-72B对齐;
高分选品策略的占比提升,理论上能够进一步提高 AI 选品结果的人工采纳率;
RL 带来的总轮次提效收益小于 SFT,说明模型在较早迭代中已能达到较高质量的选品策略;之后的收益变小,可能是因为后续 Reward 提升难度较大,也可能是 Reward 信号无法区分更精细的策略差异。
3. 结论
本文通过 SFT/RL 对选品集的商品多样性、相关性和丰富性进行了探索与优化,并取得了一定的效果。随着项目的深入,我们意识到一个更核心的问题:AI选品初步完成了从“复杂”到“智能”的过程,但选品任务里,优化品效可能才是最关键的目标。换而言之,优化选品集的多样性、相关性和丰富性可以影响效率,但未必是最高效、最直接的途径。如何高效的直接对选品集品效进行Agentic RL优化,将是下一个值得探索的问题。
🏷 关于我们
我们是淘天商品价格力&营销算法团队,深耕AI驱动的大促活动,营销推荐与智能比价/定价,是淘天电商领域核心算法团队之一。我们服务双11/618代表的大促活动,以及百亿补贴/淘宝秒杀等核心营销场景,以AI生成式推荐技术助推淘宝GMV增长。
团队致力于从0到1落地前沿研究,年均在RecSys/SIGIR/EMNLP等国际顶会发表5+篇论文。欢迎加入我们,一起挑战困难,探索AI+电商的无限可能。
📮投递简历邮箱:loujunhong.loujunh@alibaba-inc.com


关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢